Inkrementelles Laden von Daten aus mehreren Tabellen in SQL Server in eine Datenbank in Azure SQL-Datenbank über das Azure-Portal
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial erstellen Sie eine Azure Data Factory mit einer Pipeline, bei der Deltadaten aus mehreren Tabellen einer SQL Server-Datenbank in eine Datenbank in Azure SQL-Datenbank geladen werden.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Vorbereiten von Quell- und Zieldatenspeichern
- Erstellen einer Data Factory.
- Erstellen Sie eine selbstgehostete Integration Runtime.
- Installieren der Integration Runtime
- Erstellen Sie verknüpfte Dienste.
- Erstellen des Quell-, Senken-, Grenzwertdatasets
- Erstellen, Ausführen und Überwachen einer Pipeline
- Überprüfen Sie die Ergebnisse.
- Hinzufügen oder Aktualisieren von Daten in Quelltabellen
- Erneutes Ausführen und Überwachen der Pipeline
- Überprüfen der Endergebnisse
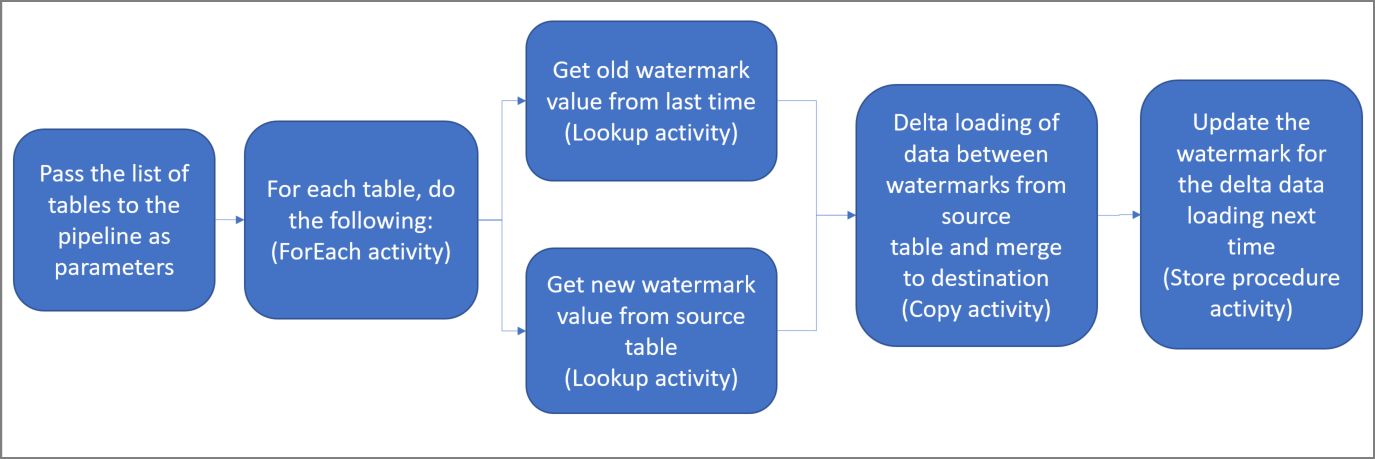
Hier sind die wesentlichen Schritte beim Erstellen dieser Lösung aufgeführt:
Select the watermark column (Wählen Sie die Grenzwert-Spalte aus) .
Wählen Sie für jede Tabelle im Quelldatenspeicher eine Spalte aus, die verwendet werden kann, um die neuen oder aktualisierten Datensätze für jede Ausführung zu identifizieren. Normalerweise steigen die Daten in dieser ausgewählten Spalte (z.B. Last_modify_time oder ID), wenn Zeilen erstellt oder aktualisiert werden. Der maximale Wert in dieser Spalte wird als Grenzwert verwendet.
Prepare a data store to store the watermark value (Vorbereiten eines Datenspeichers zum Speichern des Grenzwerts) .
In diesem Tutorial speichern Sie den Grenzwert in einer SQL-Datenbank.
Erstellen Sie eine Pipeline mit den folgenden Aktivitäten:
a. Erstellen Sie eine ForEach-Aktivität zum Durchlaufen einer Liste mit Namen von Quelltabellen, die als Parameter an die Pipeline übergeben wird. Für jede Quelltabelle werden die folgenden Aktivitäten aufgerufen, um den Deltaladevorgang für diese Tabelle durchzuführen:
b. Erstellen Sie zwei Lookup-Aktivitäten. Verwenden Sie die erste Lookup-Aktivität, um den letzten Grenzwert abzurufen. Verwenden Sie die zweite Lookup-Aktivität, um den neuen Grenzwert abzurufen. Diese Grenzwerte werden an die Copy-Aktivität übergeben.
c. Erstellen Sie eine Copy-Aktivität, die Zeilen aus dem Quelldatenspeicher kopiert, wobei der Wert der Grenzwertspalte größer als der alte Grenzwert und kleiner als der neue Grenzwert ist. Anschließend werden die Deltadaten aus dem Quelldatenspeicher als neue Datei in Azure Blob Storage kopiert.
d. Erstellen Sie eine StoredProcedure-Aktivität, die den Grenzwert für die Pipeline aktualisiert, die nächstes Mal ausgeführt wird.
Allgemeines Lösungsdiagramm:
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- SQL Server. In diesem Tutorial verwenden Sie eine SQL Server-Datenbank als Quelldatenspeicher.
- Azure SQL-Datenbank. Sie verwenden eine Datenbank in Azure SQL-Datenbank als Senkendatenspeicher. Wenn Sie in SQL-Datenbank noch keine Datenbank haben, lesen Sie Erstellen einer Datenbank in Azure SQL-Datenbank. Dort finden Sie die erforderlichen Schritte zum Erstellen einer solchen Datenbank.
Öffnen Sie SQL Server Management Studio, und stellen Sie eine Verbindung mit der SQL Server-Datenbank her.
Klicken Sie im Server-Explorer mit der rechten Maustaste auf die Datenbank, und wählen Sie Neue Abfrage.
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um Tabellen mit den Namen
customer_tableundproject_tablezu erstellen:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Öffnen Sie SQL Server Management Studio, und stellen Sie eine Verbindung mit Ihrer Datenbank in Azure SQL-Datenbank her.
Klicken Sie im Server-Explorer mit der rechten Maustaste auf die Datenbank, und wählen Sie Neue Abfrage.
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um Tabellen mit den Namen
customer_tableundproject_tablezu erstellen:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um eine Tabelle mit dem Namen
watermarktablezum Speichern des Grenzwerts zu erstellen:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Fügen Sie die anfänglichen Grenzwerte für beide Quelltabellen in die Tabelle mit den Grenzwerten ein.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Führen Sie den folgenden Befehl zum Erstellen einer gespeicherten Prozedur in Ihrer Datenbank aus. Mit dieser gespeicherten Prozedur wird der Grenzwert nach jeder Pipelineausführung aktualisiert.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Führen Sie die folgende Abfrage aus, um zwei gespeicherte Prozeduren und zwei Datentypen in Ihrer Datenbank zu erstellen. Sie werden zum Zusammenführen der Daten aus Quelltabellen in Zieltabellen verwendet.
Um den Einstieg zu erleichtern, verwenden wir diese gespeicherten Prozeduren direkt. Dabei übergeben wir die Deltadaten mithilfe einer Tabellenvariablen und führen sie anschließend im Zielspeicher zusammen. In der Tabellenvariablen sollten maximal 100 Deltazeilen gespeichert werden.
Falls Sie im Zielspeicher eine große Anzahl von Deltazeilen zusammenführen möchten, empfiehlt es sich, die Deltadaten zunächst mithilfe der Kopieraktivität in eine temporäre Stagingtabelle im Zielspeicher zu kopieren und anschließen eine eigene gespeicherte Prozedur ohne Tabellenvariable zu erstellen, um die Daten aus der Stagingtabelle in der finalen Tabelle zusammenzuführen.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Starten Sie den Webbrowser Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im Menü auf der linken Seite Ressource erstellen>Integration>Data Factory aus:
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFMultiIncCopyTutorialDF ein.
Der Name der Azure Data Factory-Instanz muss global eindeutig sein. Wenn ein rotes Ausrufezeichen mit dem folgenden Fehler angezeigt wird, können Sie den Namen der Data Factory ändern (z.B. in „
ADFIncCopyTutorialDF“) und dann versuchen, die Erstellung erneut durchzuführen. Benennungsregeln für Data Factory-Artefakte finden Sie im Artikel Azure Data Factory – Benennungsregeln. Data factory name "ADFIncCopyTutorialDF" is not availableWählen Sie Ihr Azure-Abonnement aus, in dem die Data Factory erstellt werden soll.
Führen Sie für die Ressourcengruppe einen der folgenden Schritte aus:
- Wählen Sie die Option Use existing(Vorhandene verwenden) und dann in der Dropdownliste eine vorhandene Ressourcengruppe.
- Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen über Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie V2 als Version aus.
Wählen Sie den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die von der Data Factory verwendeten Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computedienste (HDInsight usw.) können sich in anderen Regionen befinden.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird die Seite Data Factory wie in der Abbildung angezeigt.

Wählen Sie auf der Kachel Open Azure Data Factory Studio die Option Öffnen um das Data Factory Benutzerinterface (UI) in einem separaten Tab zu starten.
Wenn Sie Daten aus einem Datenspeicher in einem privaten Netzwerk (lokal) in einen Azure-Datenspeicher verschieben, installieren Sie eine selbstgehostete Integration Runtime (IR) in Ihrer lokalen Umgebung. Mit der selbstgehosteten IR werden Daten zwischen Ihrem privaten Netzwerk und Azure verschoben.
Wählen Sie auf der Homepage der Azure Data Factory-Benutzeroberfläche im Bereich ganz links die Registerkarte Verwalten aus.
Wählen Sie im linken Bereich Integration Runtime und dann +Neu aus.
Wählen Sie im Fenster Integration Runtime Setup (Integration Runtime-Setup) die Option Perform data movement and dispatch activities to external computes (Datenverschiebung und -verteilung an externe Computeressourcen ausführen), und klicken Sie auf Weiter.
Wählen Sie Selbstgehostet aus, und klicken Sie auf Weiter.
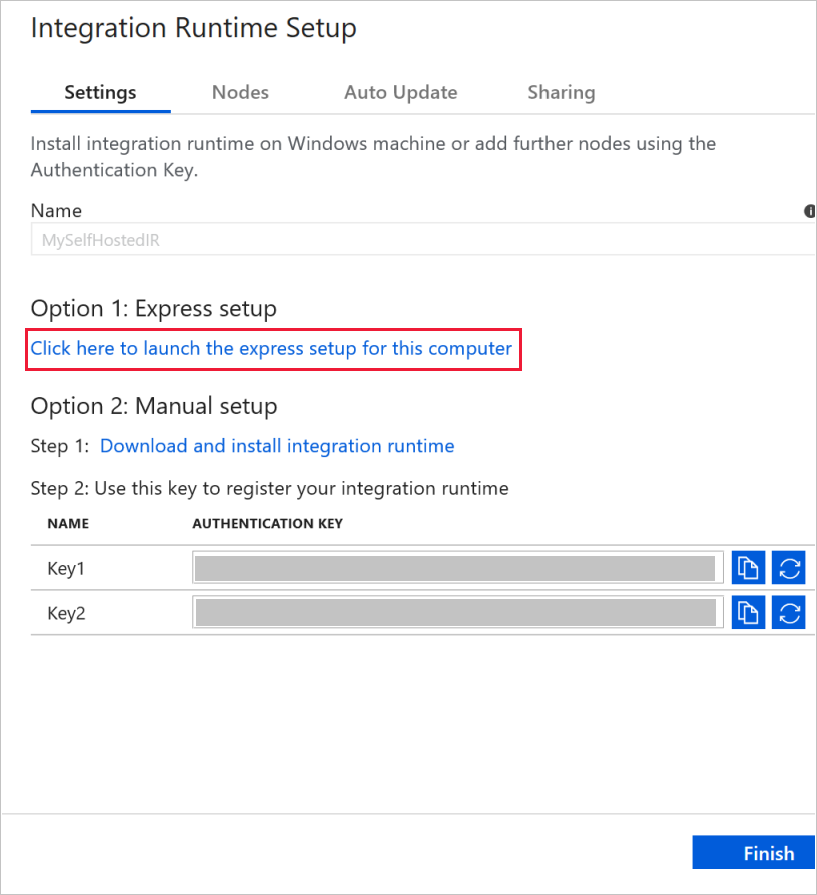
Geben Sie unter Name die Zeichenfolge MySelfHostedIR ein, und klicken Sie auf Erstellen.
Klicken Sie auf Klicken Sie hier, um das Express-Setup für diesen Computer zu starten im Abschnitt Option 1: Express-Setup.
Klicken Sie im Fenster Express-Setup von Integration Runtime (selbstgehostet) auf Schließen.
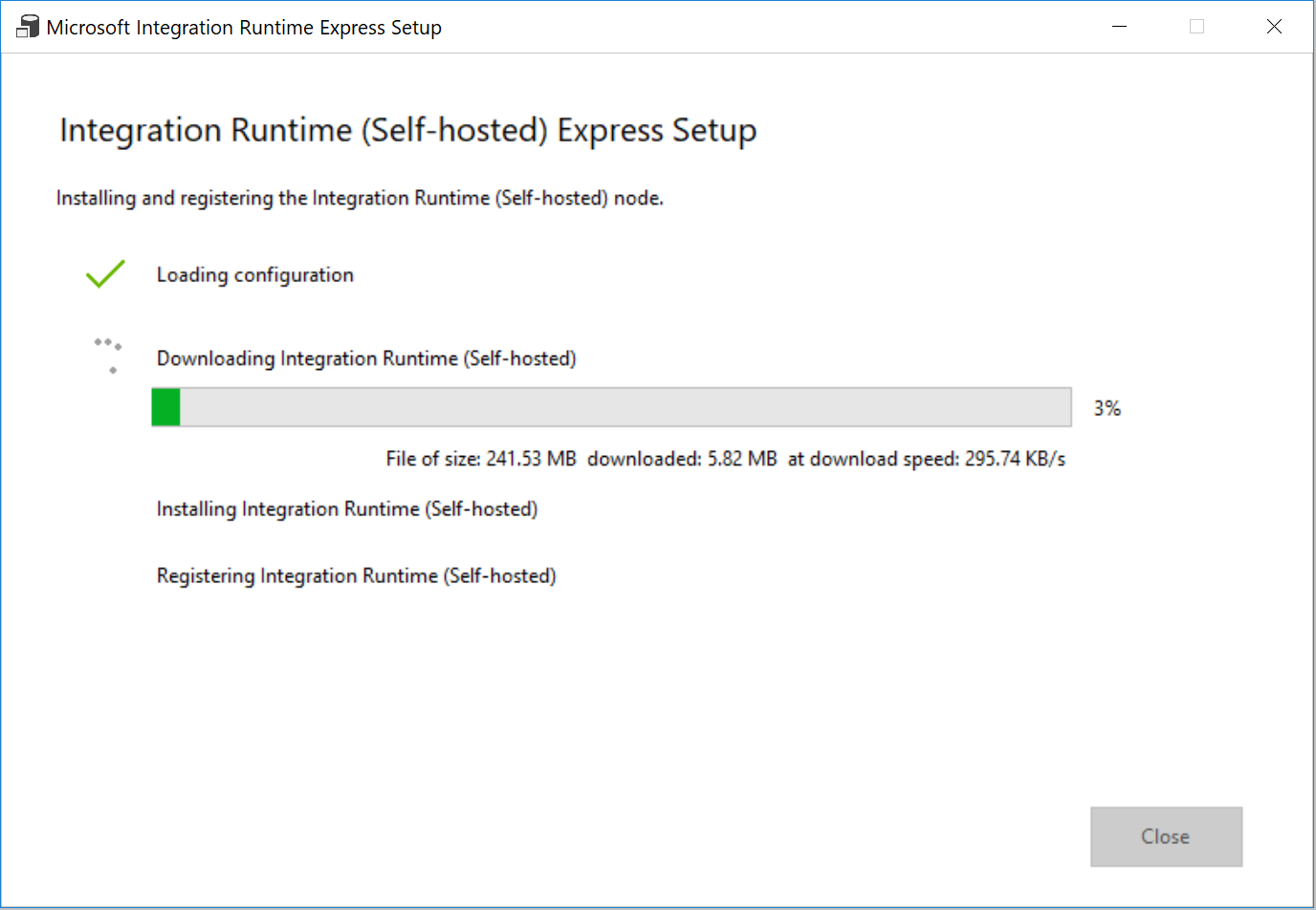
Klicken Sie im Webbrowser im Fenster Integration Runtime Setup (Integration Runtime-Setup) auf Fertig stellen.
Vergewissern Sie sich, dass MySelfHostedIR in der Liste mit den Integration Runtimes angezeigt wird.
Um Ihre Datenspeicher und Compute Services mit der Data Factory zu verknüpfen, können Sie verknüpfte Dienste in einer Data Factory erstellen. In diesem Abschnitt erstellen Sie verknüpfte Dienste für Ihre SQL Server-Datenbank und Ihre Datenbank in Azure SQL-Datenbank.
In diesem Schritt verknüpfen Sie Ihre SQL Server-Datenbank mit der Data Factory.
Wechseln Sie im Fenster Verbindungen von der Registerkarte Integration Runtimes zur Registerkarte Verknüpfte Dienste, und klicken Sie auf + Neu.
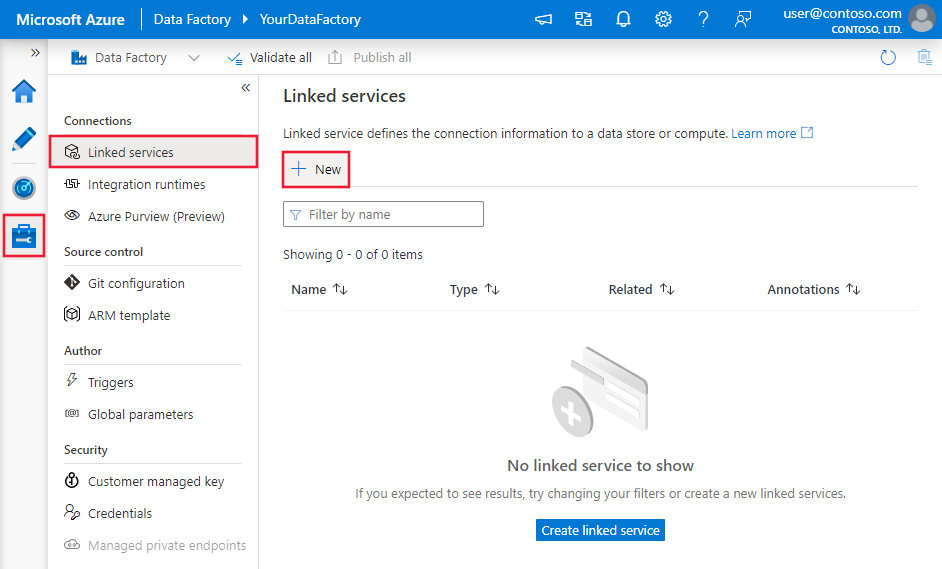
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option SQL Server, und klicken Sie auf Weiter.
Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
- Geben Sie unter Name die Zeichenfolge SqlServerLinkedService ein.
- Wählen Sie unter Connect via integration runtime (Verbindung per Integration Runtime herstellen) die Option MySelfHostedIR aus. Dies ist ein wichtiger Schritt. Mit der Standard-Integration Runtime kann keine Verbindung mit einem lokalen Datenspeicher hergestellt werden. Verwenden Sie die selbstgehostete Integration Runtime, die Sie weiter oben erstellt haben.
- Geben Sie unter Servername den Namen Ihres Computers ein, auf dem sich die SQL Server-Datenbank befindet.
- Geben Sie als Datenbankname den Namen der Datenbank Ihrer SQL Server-Instanz an, die über die Quelldaten verfügt. Während der Erfüllung der Voraussetzungen haben Sie eine Tabelle erstellt und Daten in diese Datenbank eingefügt.
- Wählen Sie unter Authentifizierungstyp den Typ der Authentifizierung aus, den Sie zum Herstellen der Verbindung mit der Datenbank verwenden möchten.
- Geben Sie unter Benutzername den Namen des Benutzers ein, der Zugriff auf die SQL Server-Datenbank hat. Wenn Sie im Benutzerkonto- oder Servernamen einen Schrägstrich (
\) verwenden müssen, verwenden Sie das Escapezeichen (\). z. B.mydomain\\myuser. - Geben Sie unter Kennwort das Kennwort für den Benutzer ein.
- Klicken Sie auf Verbindung testen, um zu testen, ob für die Data Factory eine Verbindung mit Ihrer SQL Server-Datenbank hergestellt werden kann. Beheben Sie alle Fehler, bis die Verbindung erfolgreich hergestellt wird.
- Klicken Sie auf Fertig stellen, um den verknüpften Dienst zu speichern.
Im letzten Schritt erstellen Sie einen verknüpften Dienst, um Ihre SQL Server-Quelldatenbank mit der Data Factory zu verknüpfen. In diesem Schritt verknüpfen Sie Ihre Ziel-/Senkendatenbank mit der Data Factory.
Wechseln Sie im Fenster Verbindungen von der Registerkarte Integration Runtimes zur Registerkarte Verknüpfte Dienste, und klicken Sie auf + Neu.
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Azure SQL-Datenbank, und klicken Sie auf Weiter.
Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
- Geben Sie unter Name den Namen AzureSqlDatabaseLinkedService ein.
- Wählen Sie unter Servername in der Dropdownliste den Namen Ihres Servers aus.
- Wählen Sie unter Datenbankname die Datenbank aus, in der Sie im Rahmen der Schritte zur Erfüllung der Voraussetzungen die Elemente „customer_table“ und „project_table“ erstellt haben.
- Geben Sie unter Benutzername den Namen des Benutzers ein, der Zugriff auf die Datenbank hat.
- Geben Sie unter Kennwort das Kennwort für den Benutzer ein.
- Klicken Sie auf Verbindung testen, um zu testen, ob für die Data Factory eine Verbindung mit Ihrer SQL Server-Datenbank hergestellt werden kann. Beheben Sie alle Fehler, bis die Verbindung erfolgreich hergestellt wird.
- Klicken Sie auf Fertig stellen, um den verknüpften Dienst zu speichern.
Vergewissern Sie sich, dass in der Liste zwei verknüpfte Dienste angezeigt werden.
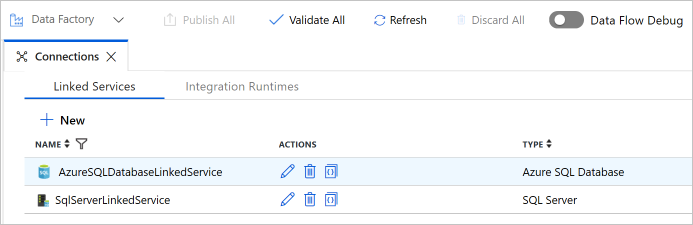
In diesem Schritt erstellen Sie Datasets zur Darstellung der Datenquelle, des Datenziels und des Speicherorts des Grenzwerts.
Klicken Sie im linken Bereich auf + (Pluszeichen) und dann auf Dataset.
Wählen Sie im Fenster Neues Dataset die Option SQL Server aus, und klicken Sie auf Weiter.
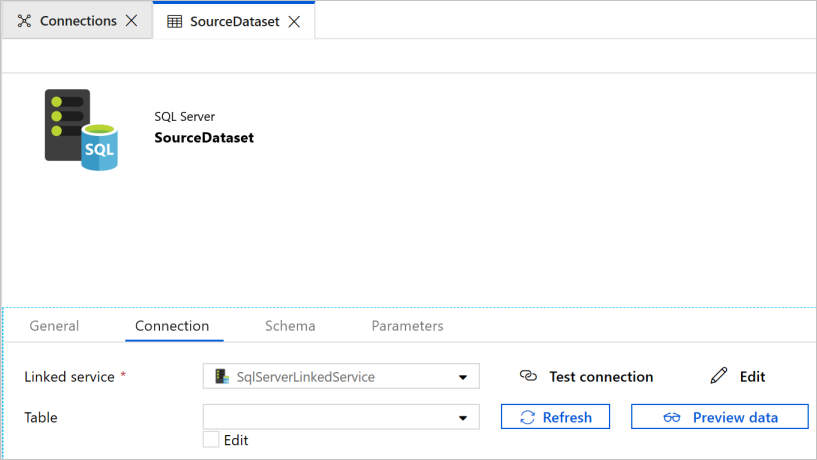
Im Webbrowser wird eine neue Registerkarte für die Konfiguration des Datasets geöffnet. Außerdem wird in der Strukturansicht ein Dataset angezeigt. Geben Sie im Eigenschaftenfenster auf der Registerkarte Allgemein unten für Name den Namen SourceDataset ein.
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Verbindung, und wählen Sie unter Verknüpfter Dienst die Option SqlServerLinkedService. Hier wählen Sie keine Tabelle aus. Für die Copy-Aktivität in der Pipeline wird eine SQL-Abfrage zum Laden der Daten anstelle der gesamten Tabelle verwendet.
Klicken Sie im linken Bereich auf + (Pluszeichen) und dann auf Dataset.
Wählen Sie im Fenster Neues Dataset die Option Azure SQL-Datenbank aus, und klicken Sie auf Weiter.
Im Webbrowser wird eine neue Registerkarte für die Konfiguration des Datasets geöffnet. Außerdem wird in der Strukturansicht ein Dataset angezeigt. Geben Sie im Eigenschaftenfenster auf der Registerkarte Allgemein unter Name den Namen SinkDataset ein.
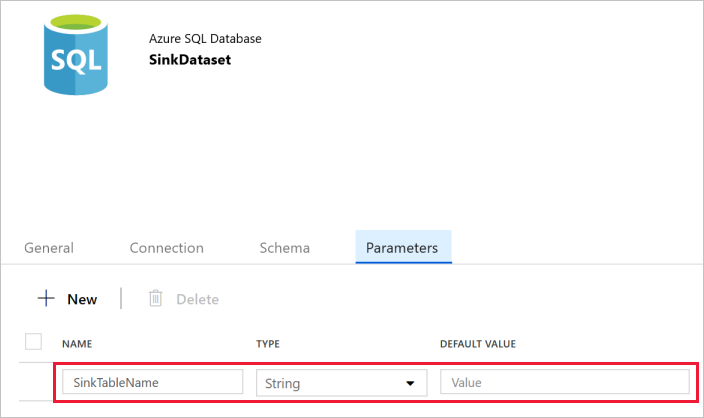
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Parameter, und führen Sie die folgenden Schritte aus:
Klicken Sie im Abschnitt Parameter erstellen/aktualisieren die Option Neu.
Geben Sie SinkTableName als Namen und Zeichenfolge als Typ ein. Für dieses Dataset wird SinkTableName als Parameter verwendet. Der Parameter SinkTableName wird von der Pipeline zur Laufzeit dynamisch festgelegt. Die ForEach-Aktivität in der Pipeline durchläuft eine Liste mit Tabellennamen und übergibt den Tabellennamen bei jedem Durchlauf an dieses Dataset.
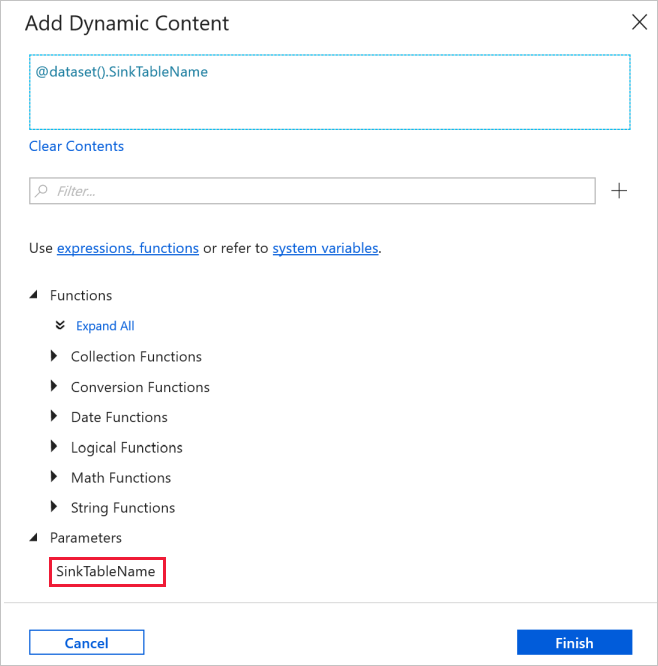
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Verbindung, und wählen Sie unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService aus. Klicken Sie für die Table-Eigenschaft auf Dynamischen Inhalt hinzufügen.
Wählen Sie im Fenster Dynamischen Inhalt hinzufügen im Abschnitt Parameter die Option SinkTableName aus.
Nachdem Sie auf Fertig stellen geklickt haben, wird „@dataset().SinkTableName“ als Tabellenname angezeigt.
In diesem Schritt erstellen Sie ein Dataset zum Speichern eines hohen Grenzwerts.
Klicken Sie im linken Bereich auf + (Pluszeichen) und dann auf Dataset.
Wählen Sie im Fenster Neues Dataset die Option Azure SQL-Datenbank aus, und klicken Sie auf Weiter.
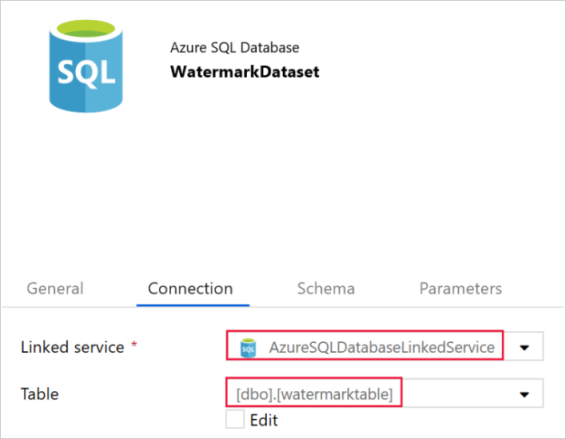
Geben Sie im Eigenschaftenfenster auf der Registerkarte Allgemein unten für Name den Namen WatermarkDataset ein.
Wechseln Sie zur Registerkarte Verbindung, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService.
Wählen Sie unter Tabelle die Option [dbo].[watermarktable] .
Die Pipeline verwendet die Liste mit den Tabellennamen als Parameter. Die ForEach-Aktivität durchläuft die Liste mit den Tabellennamen und führt die folgenden Vorgänge aus:
Verwenden Sie die Lookup-Aktivität, um den alten Grenzwert abzurufen (anfänglicher Wert oder der im letzten Durchlauf verwendete Wert).
Verwenden Sie die Lookup-Aktivität, um den neuen Grenzwert abzurufen (Höchstwert der Grenzwertspalte in der Quelltabelle).
Verwenden Sie die Copy-Aktivität, um Daten zwischen diesen beiden Grenzwerten aus der Quelldatenbank in die Zieldatenbank zu kopieren.
Verwenden Sie die StoredProcedure-Aktivität, um den alten Grenzwert zu aktualisieren, damit er im ersten Schritt des nächsten Durchlaufs verwendet werden kann.
Klicken Sie im linken Bereich auf + (Pluszeichen) und dann auf Pipeline.
Geben Sie im Bereich „Allgemein“ unter Eigenschaften die Eigenschaft IncrementalCopyPipeline für Name an. Reduzieren Sie dann den Bereich, indem Sie in der oberen rechten Ecke auf das Symbol „Eigenschaften“ klicken.
Führen Sie auf der Registerkarte Parameter die folgenden Schritte aus:
- Klicken Sie auf + NEU.
- Geben Sie tableList für den Parameter name ein.
- Wählen Sie für den Parameter type die Option Array aus.
Erweitern Sie in der Toolbox Aktivitäten die Option Iteration & Conditionals (Iteration und konditionelle Abschnitte), und ziehen Sie die ForEach-Aktivität auf die Oberfläche des Pipeline-Designers. Geben Sie im Eigenschaftenfenster auf der Registerkarte Allgemein den Text IterateSQLTables ein.
Wechseln Sie zur Registerkarte Einstellungen, und geben Sie unter Elemente die Zeichenfolge
@pipeline().parameters.tableListein. Die ForEach-Aktivität durchläuft eine Liste mit Tabellen und führt den inkrementellen Kopiervorgang durch.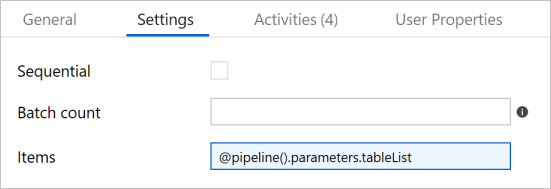
Wählen Sie die ForEach-Aktivität in der Pipeline, falls sie nicht bereits ausgewählt wurde. Klicken Sie auf die Schaltfläche Bearbeiten (Stiftsymbol).
Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, ziehen Sie die Lookup-Aktivität auf die Oberfläche des Pipeline-Designers, und geben Sie unter Name den Namen LookupOldWaterMarkActivity ein.
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Einstellungen , und führen Sie die folgenden Schritte aus:
Wählen Sie WatermarkDataset für Source Dataset.
Wählen Sie unter Abfrage verwenden die Option Abfrage.
Geben Sie unter Abfrage die folgende SQL-Abfrage ein:
select * from watermarktable where TableName = '@{item().TABLE_NAME}'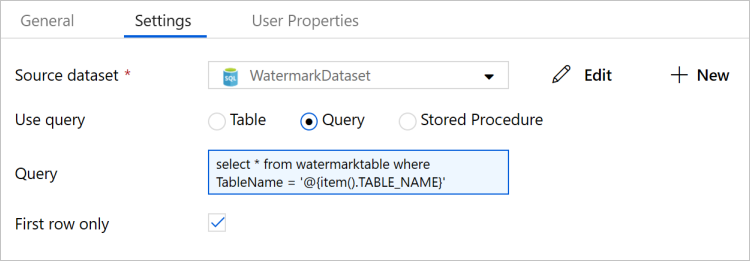
Ziehen Sie die Lookup-Aktivität aus der Toolbox Aktivitäten, und geben Sie unter Name den Namen LookupNewWaterMarkActivity ein.
Wechseln Sie zur Registerkarte Einstellungen.
Wählen Sie unter Source Dataset (Quelldataset) die Option SourceDataset.
Wählen Sie unter Abfrage verwenden die Option Abfrage.
Geben Sie unter Abfrage die folgende SQL-Abfrage ein:
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}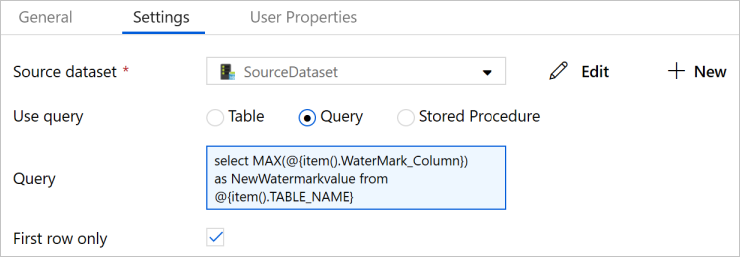
Ziehen Sie die Copy-Aktivität aus der Toolbox Aktivitäten, und geben Sie unter Name den Namen IncrementalCopyActivity ein.
Verbinden Sie die einzelnen Lookup-Aktivitäten jeweils mit der Copy-Aktivität. Ziehen Sie das grüne Feld, das an die Lookup-Aktivität angefügt ist, auf die Copy-Aktivität, um die Verbindung herzustellen. Lassen Sie die Maustaste los, wenn sich die Rahmenfarbe der Copy-Aktivität in Blau ändert.
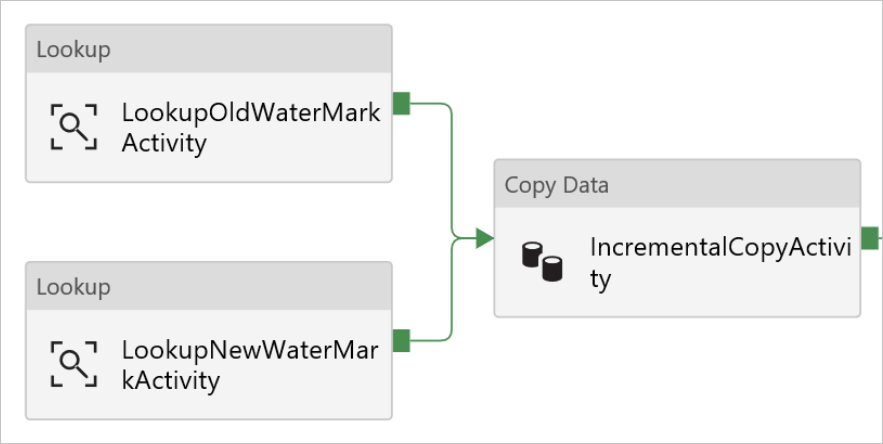
Wählen Sie die Copy-Aktivität in der Pipeline aus. Wechseln Sie im Eigenschaftenfenster zur Registerkarte Quelle.
Wählen Sie unter Source Dataset (Quelldataset) die Option SourceDataset.
Wählen Sie unter Abfrage verwenden die Option Abfrage.
Geben Sie unter Abfrage die folgende SQL-Abfrage ein:
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'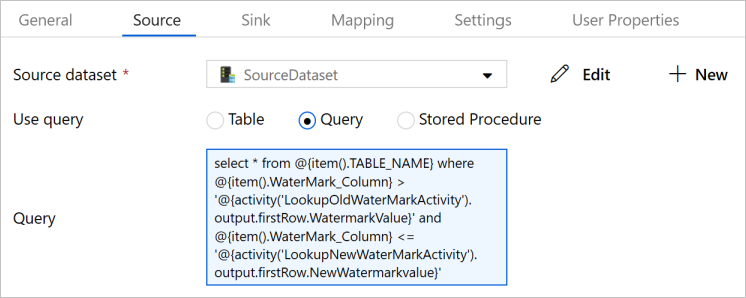
Wechseln Sie zur Registerkarte Senke, und wählen Sie unter Sink Dataset (Senkendataset) die Option SinkDataset.
Führen Sie die folgenden Schritte aus:
Geben Sie in den Dataseteigenschaften für den Parameter SinkTableName Folgendes ein:
@{item().TABLE_NAME}.Geben Sie für die Eigenschaft Stored Procedure Name die Zeichenfolge
@{item().StoredProcedureNameForMergeOperation}ein.Geben Sie für die Eigenschaft Tabellentyp die Zeichenfolge
@{item().TableType}ein.Geben Sie unter Table type parameter name (Parametername des Tabellentyps) die Zeichenfolge
@{item().TABLE_NAME}ein.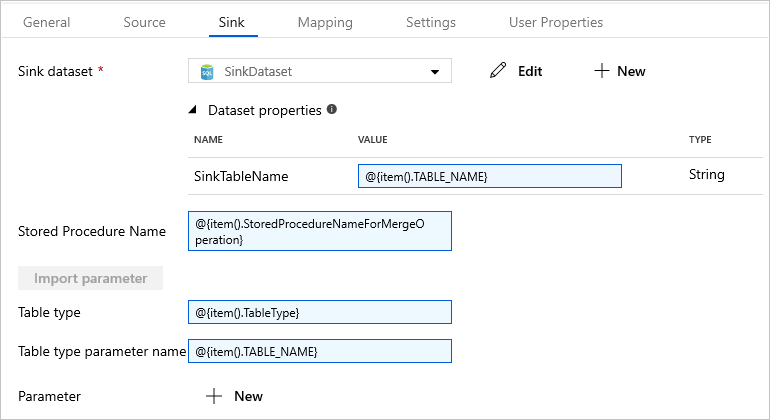
Ziehen Sie die Stored Procedure-Aktivität aus der Toolbox Aktivitäten in die Oberfläche des Pipeline-Designers. Verbinden Sie die Copy-Aktivität mit der Stored Procedure-Aktivität.
Wählen Sie die Stored Procedure-Aktivität in der Pipeline aus, und geben Sie im Eigenschaftenfenster auf der Registerkarte Allgemein unter Name den Namen StoredProceduretoWriteWatermarkActivity ein.
Wechseln Sie zur Registerkarte SQL-Konto, und wählen Sie unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService.

Wechseln Sie zur Registerkarte Gespeicherte Prozedur, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Name der gespeicherten Prozedur den Namen
[dbo].[usp_write_watermark]aus.Wählen Sie die Option Import parameter (Importparameter).
Geben Sie die folgenden Werte für die Parameter an:
Name type Wert LastModifiedtime Datetime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}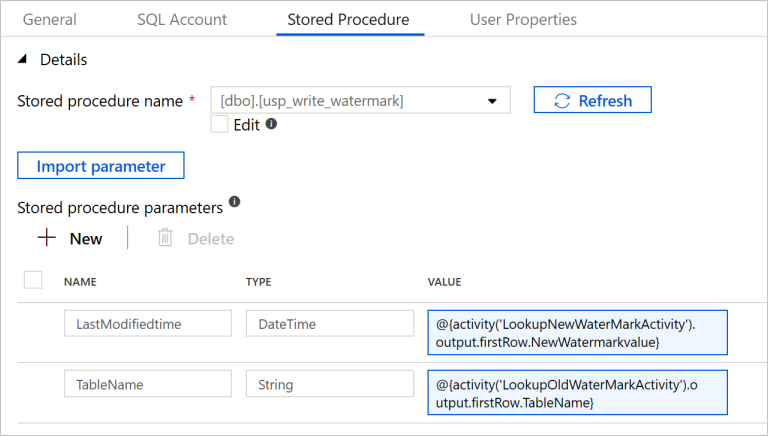
Wählen Sie zum Veröffentlichen der erstellten Entitäten im Data Factory-Dienst Alle veröffentlichen aus.
Warten Sie, bis die Meldung Erfolgreich veröffentlicht angezeigt wird. Klicken Sie zum Anzeigen der Benachrichtigungen auf den Link Benachrichtigungen anzeigen. Schließen Sie das Benachrichtigungsfenster, indem Sie auf das X klicken.
Klicken Sie auf der Symbolleiste der Pipeline auf Trigger hinzufügen und dann auf Trigger Now (Jetzt auslösen).
Geben Sie im Fenster Pipelineausführung für den Parameter tableList den folgenden Wert ein, und klicken Sie auf Fertig stellen.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]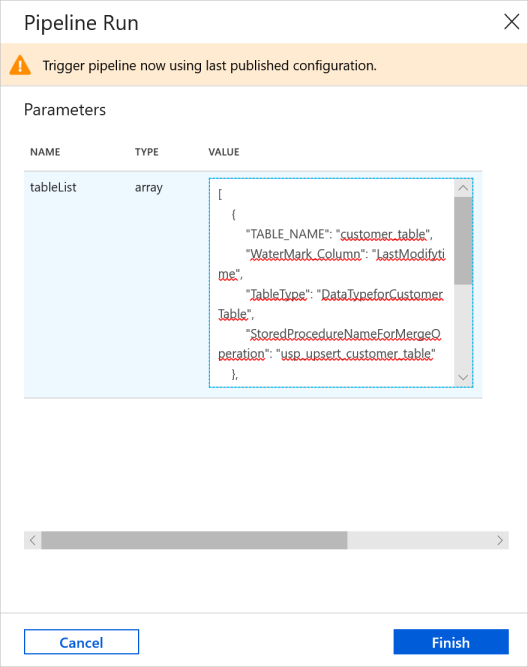
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. Sie können die Pipelineausführung anzeigen, die vom manuellen Trigger ausgelöst wird. Über die Links unter der Spalte PIPELINENAME können Sie Aktivitätsdetails anzeigen und die Pipeline erneut ausführen.
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie den Link unter der Spalte PIPELINENAME aus. Wenn Sie Details zu den Aktivitätsausführungen anzeigen möchten, wählen Sie unter der Spalte AKTIVITÄTSNAME den Link Details (das Brillensymbol) aus.
Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.
Führen Sie in SQL Server Management Studio die folgenden Abfragen für die SQL-Zieldatenbank aus, um sicherzustellen, dass die Daten aus den Quelltabellen in die Zieltabellen kopiert wurden:
Abfrage
select * from customer_table
Ausgabe
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Abfrage
select * from project_table
Ausgabe
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Abfrage
select * from watermarktable
Ausgabe
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Beachten Sie, dass die Grenzwerte für beide Tabellen aktualisiert wurden.
Führen Sie die folgende Abfrage für die SQL Server-Quelldatenbank aus, um in der Kundentabelle (customer_table) eine vorhandene Zeile zu aktualisieren. Fügen Sie eine neue Zeile in die Projekttabelle (project_table) ein.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Wechseln Sie im Webbrowserfenster zur Registerkarte Bearbeiten auf der linken Seite.
Klicken Sie auf der Symbolleiste der Pipeline auf Trigger hinzufügen und dann auf Trigger Now (Jetzt auslösen).
Geben Sie im Fenster Pipelineausführung für den Parameter tableList den folgenden Wert ein, und klicken Sie auf Fertig stellen.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. Sie können die Pipelineausführung anzeigen, die vom manuellen Trigger ausgelöst wird. Über die Links unter der Spalte PIPELINENAME können Sie Aktivitätsdetails anzeigen und die Pipeline erneut ausführen.
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie den Link unter der Spalte PIPELINENAME aus. Wenn Sie Details zu den Aktivitätsausführungen anzeigen möchten, wählen Sie unter der Spalte AKTIVITÄTSNAME den Link Details (das Brillensymbol) aus.
Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.
Führen Sie in SQL Server Management Studio die folgenden Abfragen für die SQL-Zieldatenbank aus, um sicherzustellen, dass die aktualisierten bzw. neuen Daten aus den Quelltabellen in die Zieltabellen kopiert wurden.
Abfrage
select * from customer_table
Ausgabe
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Beachten Sie die neuen Werte in Name und LastModifytime für PersonID für Nummer 3.
Abfrage
select * from project_table
Ausgabe
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Beachten Sie, dass der Projekttabelle (project_table) der Eintrag NewProject hinzugefügt wurde.
Abfrage
select * from watermarktable
Ausgabe
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Beachten Sie, dass die Grenzwerte für beide Tabellen aktualisiert wurden.
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Vorbereiten von Quell- und Zieldatenspeichern
- Erstellen einer Data Factory.
- Erstellen einer selbstgehosteten Integration Runtime (IR)
- Installieren der Integration Runtime
- Erstellen Sie verknüpfte Dienste.
- Erstellen des Quell-, Senken-, Grenzwertdatasets
- Erstellen, Ausführen und Überwachen einer Pipeline
- Überprüfen Sie die Ergebnisse.
- Hinzufügen oder Aktualisieren von Daten in Quelltabellen
- Erneutes Ausführen und Überwachen der Pipeline
- Überprüfen der Endergebnisse
Fahren Sie mit dem nächsten Tutorial fort, um zu erfahren, wie Sie mithilfe eines Spark-Clusters in Azure Daten transformieren: