Optimieren der Leistung von Azure Data Lake Storage Gen1
Data Lake Storage Gen1 unterstützt hohe Durchsätze für E/A-intensive Analysen und Datenverschiebungen. In Data Lake Storage Gen1 ist der verfügbare Durchsatz entscheidend, um höchste Leistung zu erzielen. Der verfügbare Durchsatz bezieht sich hierbei auf die Menge der Daten, die pro Sekunde gelesen oder geschrieben werden können. Dies wird erreicht, indem möglichst viele Lese- und Schreibvorgänge parallel ausgeführt werden.
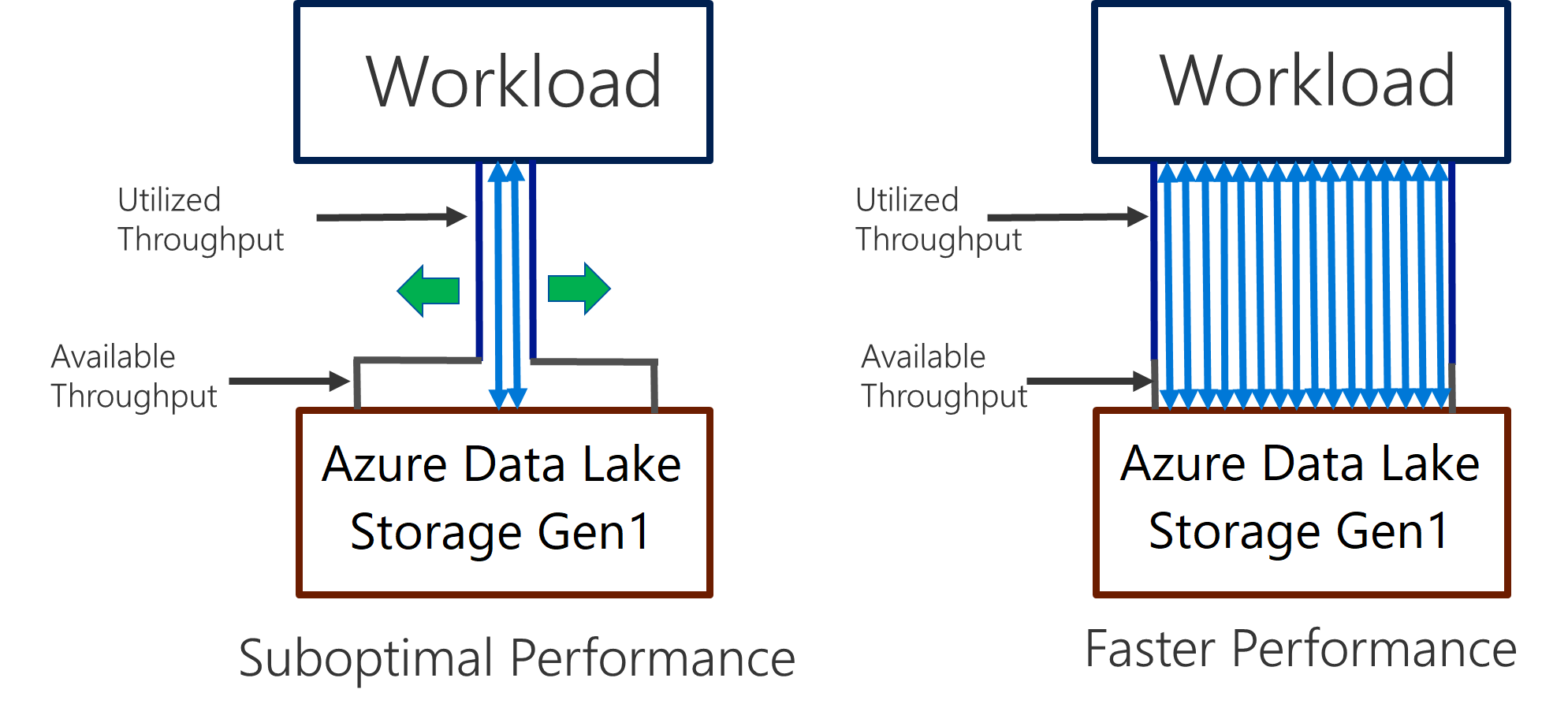
Data Lake Storage Gen1 kann skaliert werden, um den erforderlichen Durchsatz für sämtliche Analyseszenarien bereitzustellen. Standardmäßig bietet ein Data Lake Storage Gen1-Konto automatisch genügend Durchsatz, um die Anforderungen von einer großen Palette an Anwendungsfällen zu erfüllen. Sollten Kunden das Standardlimit erreichen, kann das Data Lake Storage Gen1-Konto für die Bereitstellung eines höheren Durchsatzes konfiguriert werden. Wenden Sie sich hierfür an den Microsoft-Support.
Datenerfassung
Bei der Erfassung von Daten aus einem Quellsystem in Data Lake Storage Gen1 muss berücksichtigt werden, dass bei der Quellhardware, der Quellnetzwerkhardware und der Netzwerkkonnektivität mit Data Lake Storage Gen1 Engpässe auftreten können.
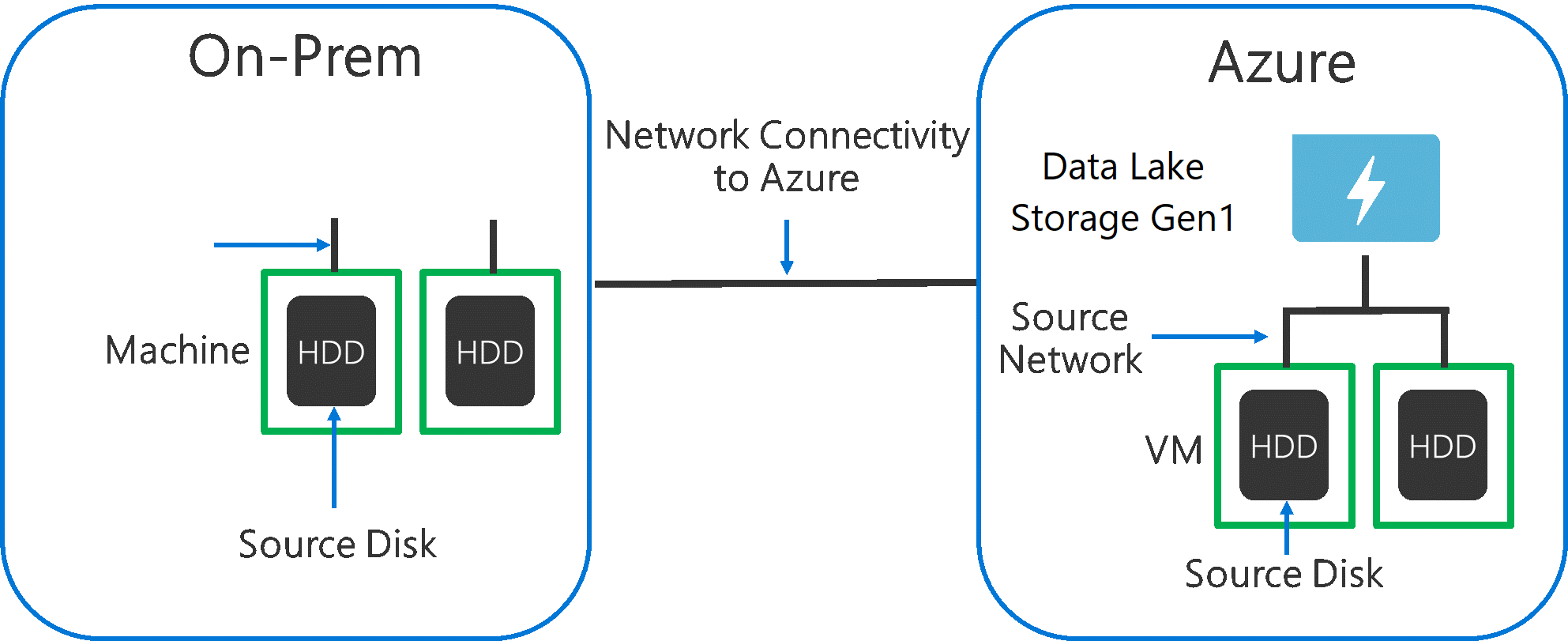
Es muss sichergestellt werden, dass die Datenverschiebung durch diese Faktoren nicht beeinträchtigt wird.
Quellhardware
Unabhängig davon, ob Sie mit lokalen Computern oder VMs in Azure arbeiten, sollten Sie die entsprechende Hardware sorgfältig auswählen. Bei Quelldatenträgerhardware wird empfohlen, SSDs gegenüber HDDs vorzuziehen und Datenträgerhardware mit schnelleren Spindeln zu wählen. Verwenden Sie für Quellnetzwerkhardware die schnellstmöglichen Netzwerkkarten. Für Azure werden Azure D14-VMs mit entsprechend leistungsstarker Datenträger- und Netzwerkhardware empfohlen.
Netzwerkkonnektivität mit Data Lake Storage Gen1
Bei der Netzwerkkonnektivität zwischen Ihren Quelldaten und Data Lake Storage Gen1 kann es gelegentlich zu Engpässen kommen. Wenn Ihre Quelldaten lokal gespeichert sind, ziehen Sie die Verwendung einer dedizierten Verknüpfung mit Azure ExpressRoute in Erwägung. Sind Ihre Quelldaten in Azure enthalten, wird eine optimale Leistung erzielt, wenn sich die Daten in derselben Azure-Region wie das Data Lake Storage Gen1-Konto befinden.
Konfigurieren von Datenerfassungstools für maximale Parallelisierung
Nachdem Sie die Engpässe bei der Quellhardware und der Netzwerkkonnektivität behoben haben, können Sie jetzt Ihre Erfassungstools konfigurieren. In der folgenden Tabelle werden wichtige Einstellungen für verschiedene gängige Erfassungstools zusammengefasst und ausführliche Artikel zu ihrer Leistungsoptimierung angegeben. Weitere Informationen darüber, welches Tool für Ihr Szenario geeignet ist, finden Sie in diesem Artikel.
| Tool | Einstellungen | Weitere Informationen |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Link |
| AdlCopy | Azure Data Lake Analytics-Einheiten | Link |
| DistCp | -m (Mapper) | Link |
| Azure Data Factory | parallelCopies | Link |
| Sqoop | fs.azure.block.size, -m (Mapper) | Link |
Strukturieren Ihres Datasets
Wenn Daten in Data Lake Storage Gen1 gespeichert sind, wird die Leistung durch die Dateigröße, die Anzahl der Dateien und die Ordnerstruktur beeinträchtigt. Im folgenden Abschnitt werden bewährte Methoden für diese Bereiche beschrieben.
Dateigröße
In der Regel erzeugen Analyse-Engines wie HDInsight und Azure Data Lake Analytics Overhead pro Datei. Wenn Sie Ihre Daten in zahlreichen kleinen Dateien speichern, kann sich dies negativ auf die Leistung auswirken.
Um eine bessere Leistung zu erzielen, organisieren Sie Ihre Daten grundsätzlich in größere Dateien. Als Faustregel gilt: Organisieren Sie Datasets in Dateien mit mindestens 256 MB. In einigen Fällen wie bei Bildern und binären Daten ist eine parallele Verarbeitung nicht möglich. Hier wird empfohlen, einzelne Dateien mit maximal 2 GB zu erstellen.
Manchmal können Datenpipelines Rohdaten mit vielen kleinen Dateien nur begrenzt nutzen. Es wird empfohlen, bei der Erstellung größere Dateien für die Verwendung bei Downstreamanwendungen zu generieren.
Organisieren von Zeitreihendaten in Ordnern
Bei Hive- und ADLA-Workloads kann durch Partitionsbereinigung von Zeitreihendaten bewirkt werden, dass einige Abfragen nur eine Teilmenge der Daten lesen. Dies führt zu einer Leistungsverbesserung.
Diese Pipelines, die Zeitreihendaten erfassen, versehen ihre Dateien oftmals mit einer strukturierten Benennung für Dateien und Ordner. Dieses gängige Beispiel zeigt Daten, die nach Datum strukturiert sind: \DataSet\JJJJ\MM\TT\datafile_JJJJ_MM_TT.tsv.
Beachten Sie, dass Informationen zu Datum/Uhrzeit sowohl im Ordnernamen als auch im Dateinamen angegeben werden.
Für Datums- und Zeitangaben ist folgendes Muster üblich: \DataSet\JJJJ\MM\TT\HH\mm\datafile_JJJJ_MM_TT_HH_mm.tsv.
Auch hier sollte die Wahl, die Sie bei der Ordner- und Dateiorganisation treffen, für größere Dateien und eine angemessene Anzahl von Dateien in den einzelnen Ordnern optimiert sein.
Optimieren von E/A-intensiven Aufträgen bei Hadoop- und Spark-Workloads für HDInsight
Aufträge lassen sich in einer der folgenden drei Kategorien unterteilen:
- CPU-intensive Aufträge: Diese Aufträge weisen lange Computezeiten mit minimalen E/A-Zeiten auf. Hierzu zählen beispielsweise Machine Learning-Aufträge und Aufträge für die Verarbeitung natürlicher Sprache.
- Speicherintensive Aufträge: Solche Aufträge belegen viel Speicher, z.B. PageRank- und Echtzeitanalyseaufträge.
- E/A-intensive Aufträge: Bei diesen Aufträgen wird der Großteil der Zeit für E/A-Vorgänge beansprucht. Ein gängiges Beispiel ist ein Kopierauftrag, bei dem nur Lese- und Schreibvorgänge durchgeführt werden. Ein weiteres Beispiel ist ein Datenvorbereitungsauftrag, der viele Daten liest, einige Datentransformationen durchführt und die Daten dann wieder in den Speicher schreibt.
Die folgende Anleitung gilt nur für E/A-intensive Aufträge.
Allgemeine Überlegungen zu HDInsight-Clustern
- HDInsight-Versionen: Um eine optimale Leistung zu erzielen, verwenden Sie die neueste Version von HDInsight.
- Regionen Platzieren Sie das Data Lake Storage Gen1-Konto in der gleichen Region wie den HDInsight-Cluster.
Ein HDInsight-Cluster besteht aus zwei Hauptknoten und einigen Workerknoten. Jeder Workerknoten stellt eine bestimmte Anzahl von Kernen und eine bestimmte Menge an Speicher bereit, die durch den VM-Typ festgelegt wird. Bei der Ausführung eines Auftrags ist YARN der Verhandlungspartner für Ressourcen, der den verfügbaren Speicher und die Kerne zur Erstellung von Containern zuordnet. Jeder Container führt die für den Auftrag erforderlichen Aufgaben durch. Zur schnellen Verarbeitung von Aufgaben werden Container parallel ausgeführt. Aus diesem Grund wird eine bessere Leistung erzielt, indem Sie so viele Container wie möglich parallel ausführen.
Es gibt drei Ebenen in einem HDInsight-Cluster, die sich optimieren lassen, um die Anzahl von Containern zu erhöhen und den gesamten verfügbaren Durchsatz zu nutzen.
- Physische Ebene
- YARN-Ebene
- Workloadebene
Physische Ebene
Führen Sie Cluster mit einer größeren Anzahl von Knoten und/oder größeren VMs aus. Bei einem größeren Cluster können Sie mehr YARN-Container ausführen, wie in der folgenden Abbildung gezeigt wird.

Verwenden Sie VMs mit mehr Netzwerkbandbreite. Die Menge der Netzwerkbandbreite kann zu einem Engpass führen, wenn die Netzwerkbandbreite geringer ist als der Data Lake Storage Gen1-Durchsatz. Die Menge der Netzwerkbandbreite variiert je nach VM. Wählen Sie einen VM-Typ, der die größtmögliche Netzwerkbandbreite aufweist.
YARN-Ebene
Verwenden Sie kleinere YARN-Container. Reduzieren Sie die Größe der einzelnen YARN-Container, um mit derselben Menge an Ressourcen mehr Container zu erstellen.
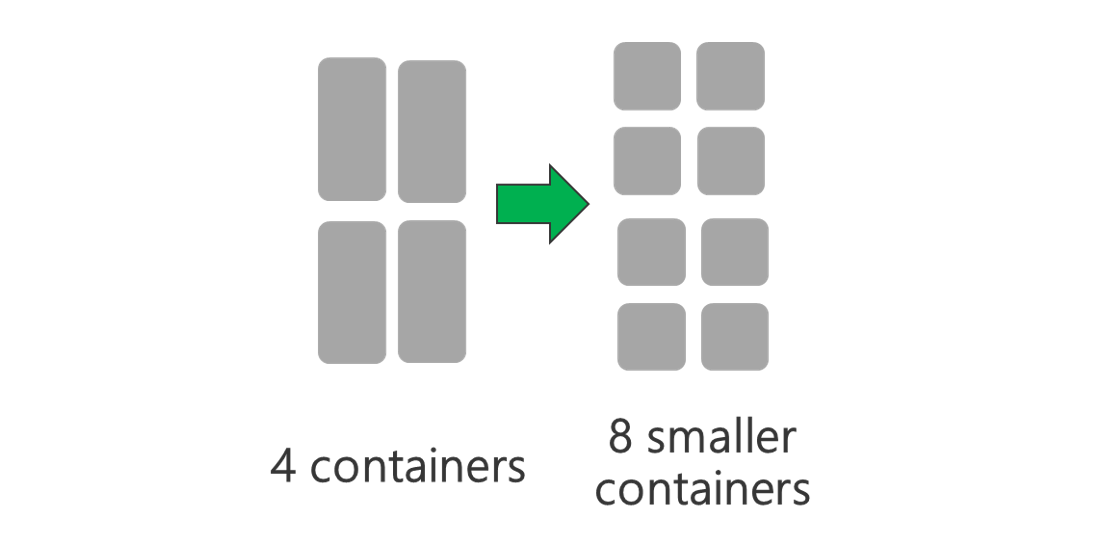
Abhängig von Ihrer Workload ist stets eine Mindestgröße für YARN-Container erforderlich. Wenn Sie einen zu kleinen Container auswählen, treten bei Ihren Aufträgen Probleme aufgrund von unzureichendem Speicherplatz auf. Normalerweise dürfen YARN-Container nicht kleiner als 1 GB sein. Üblich sind YARN-Container mit 3 GB. Für einige Workloads benötigen Sie möglicherweise größere YARN-Container.
Erhöhen Sie die Anzahl der Kerne pro YARN-Container. Erhöhen Sie die Anzahl der Kerne pro Container, um die Anzahl der Aufgaben, die in den einzelnen Containern parallel ausgeführt werden, zu erhöhen. Dies gilt für Anwendungen wie Spark, die mehrere Aufgaben pro Container ausführen. Bei Anwendungen wie Hive, die einen einzelnen Thread in jedem Container ausführen, empfiehlt es sich, die Anzahl der Container statt der Anzahl der Kerne pro Container zu erhöhen.
Workloadebene
Verwenden Sie alle verfügbaren Container. Legen Sie die Anzahl von Aufgaben auf dieselbe oder eine höhere Anzahl der verfügbaren Container fest, damit alle Ressourcen verwendet werden.
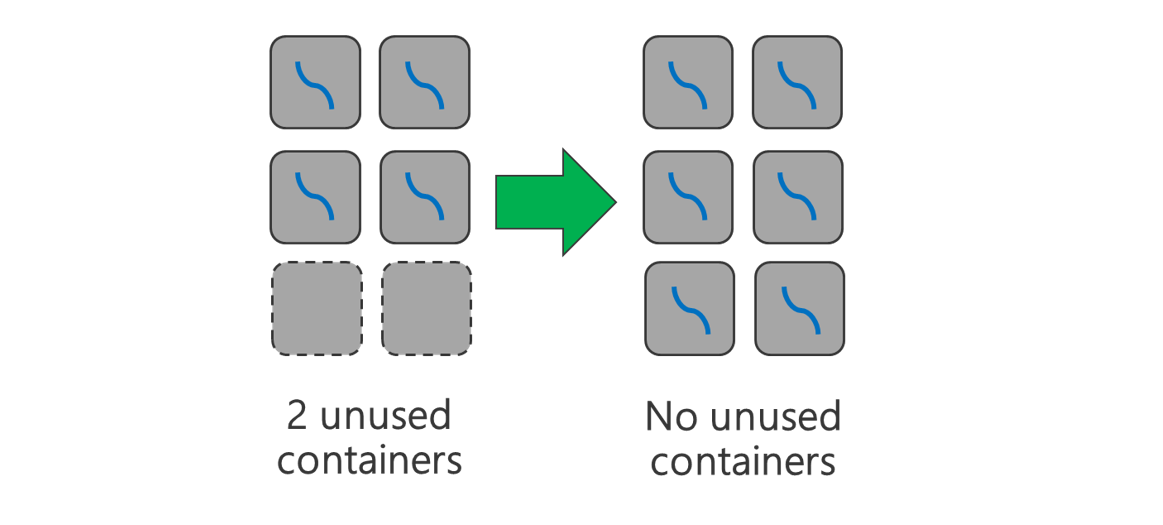
Aufgaben, die mit Fehlern beendet werden, sind kostspielig. Sind bei jeder Aufgabe große Mengen an Daten zu verarbeiten, führen fehlerhafte Aufgaben zu einer kostenintensiven Wiederholung. Aus diesem Grund empfiehlt es sich, mehr Aufgaben zu erstellen, bei denen jeweils eine kleine Datenmenge verarbeitet wird.
Neben den oben genannten allgemeinen Richtlinien stehen in jeder Anwendung verschiedene Parameter zur Verfügung, die sich für die jeweilige Anwendung optimieren lassen. In der folgenden Tabelle werden einige dieser Parameter und Links aufgeführt, um sich mit der Leistungsoptimierung der einzelnen Anwendungen vertraut zu machen.
| Workload | Parameter zum Festlegen von Aufgaben |
|---|---|
| Spark in HDInsight |
|
| Hive in HDInsight |
|
| MapReduce in HDInsight |
|
| Storm in HDInsight |
|