Bereitstellen einer IoT Edge-Workload mit gemeinsamer GPU-Nutzung auf Azure Stack Edge Pro
In diesem Artikel wird beschrieben, wie containerisierte Workloads die GPUs auf Ihrem Azure Stack Edge Pro-GPU-Gerät gemeinsam nutzen können. Der Ansatz umfasst das Aktivieren des Multiprozessdiensts und die Angabe der GPU-Workloads über eine IoT Edge-Bereitstellung.
Voraussetzungen
Stellen Sie Folgendes sicher, bevor Sie beginnen:
Sie haben Zugriff auf ein Azure Stack Edge Pro-GPU-Gerät, das aktiviert und für die Computerolle konfiguriert ist. Sie verfügen über den Kubernetes-API-Endpunkt und haben diesen Endpunkt der
hosts-Datei auf dem Client hinzugefügt, der auf das Gerät zugreifen soll.Sie haben Zugriff auf ein Clientsystem mit einem unterstützten Betriebssystem. Wenn Sie einen Windows-Client verwenden, sollte für den Zugriff auf das Gerät auf dem System mindestens PowerShell 5.0 ausgeführt werden.
Speichern Sie die folgende
json-Datei für die Bereitstellung auf Ihrem lokalen System. Sie benötigen Informationen aus dieser Datei, um die IoT Edge-Bereitstellung auszuführen. Diese Bereitstellung basiert auf einfachen CUDA-Containern, die bei Nvidia öffentlich verfügbar sind.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Überprüfen von GPU-Treiber und CUDA-Version
Der erste Schritt ist die Prüfung, ob auf Ihrem Gerät der erforderliche GPU-Treiber und die erforderlichen CUDA-Versionen ausgeführt werden.
Stellen Sie auf Ihrem Gerät eine Verbindung mit der PowerShell-Schnittstelle her.
Führen Sie den folgenden Befehl aus:
Get-HcsGpuNvidiaSmiNotieren Sie sich die Informationen der NVIDIA-SMI-Ausgabe zur GPU-Version und die CUDA-Version auf Ihrem Gerät. Wenn Sie Azure Stack Edge 2102 ausführen, entspricht diese Version den folgenden Treiberversionen:
- GPU-Treiberversion: 460.32.03
- CUDA-Version: 11.2
Beispielausgabe:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Lassen Sie diese Sitzung geöffnet, da Sie sie für den gesamten Artikel zum Anzeigen der NVIDIA-SMI-Ausgabe verwenden.
Bereitstellen ohne Kontextfreigabe
Sie können jetzt eine Anwendung auf Ihrem Gerät bereitstellen, wenn der Multiprozessdienst nicht ausgeführt wird und keine Kontextfreigabe stattfindet. Die Bereitstellung erfolgt über das Azure-Portal im Namespace iotedge, der auf Ihrem Gerät vorhanden ist.
Erstellen eines Benutzers im IoT Edge-Namespace
Zuerst erstellen Sie einen Benutzer, der eine Verbindung mit dem Namespace iotedge herstellt. Die IoT Edge-Module werden im Namespace „iotedge“ bereitgestellt. Weitere Informationen finden Sie unter Kubernetes-Namespaces auf Ihrem Gerät.
Führen Sie die folgenden Schritte aus, um einen Benutzer zu erstellen und diesem Zugriff auf den Namespace iotedge zu gewähren.
Stellen Sie auf Ihrem Gerät eine Verbindung mit der PowerShell-Schnittstelle her.
Erstellen Sie einen neuen Benutzer im Namespace
iotedge. Führen Sie den folgenden Befehl aus:New-HcsKubernetesUser -UserName <user name>Beispielausgabe:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Kopieren Sie die angezeigte Ausgabe in eine Nur-Text-Datei. Speichern Sie die Ausgabe als config-Datei (ohne Erweiterung) im
.kube-Ordner Ihres Benutzerprofils auf Ihrem lokalen Computer, z. B. hier:C:\Users\<username>\.kube.Gewähren Sie dem erstellten Benutzer Zugriff auf den Namespace
iotedge. Führen Sie den folgenden Befehl aus:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Beispielausgabe:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Detaillierte Anweisungen finden Sie unter Verbinden mit einem Kubernetes-Cluster und Verwalten des Clusters über kubectl auf Ihrem Azure Stack Edge Pro-GPU-Gerät.
Bereitstellen von Modulen über das Portal
Stellen Sie IoT Edge-Module über das Azure-Portal bereit. Sie stellen öffentlich verfügbare Nvidia-CUDA-Beispielmodule bereit, die eine N-Körper-Simulation ausführen.
Stellen Sie sicher, dass der IoT Edge-Dienst auf Ihrem Gerät ausgeführt wird.
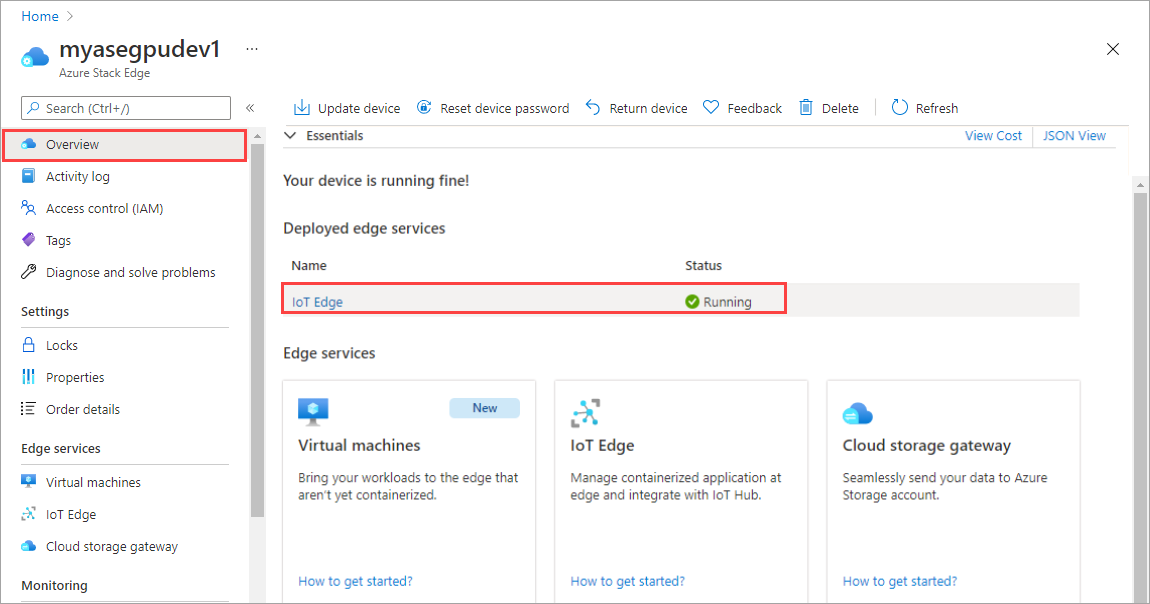
Wählen Sie im rechten Bereich die Kachel „IoT Edge“ aus. Wechseln Sie zu IoT Edge > Eigenschaften. Wählen Sie im rechten Bereich die IoT Hub-Ressource aus, die Ihrem Gerät zugeordnet ist.
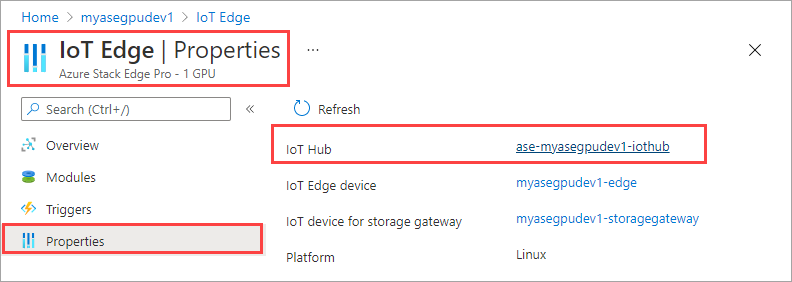
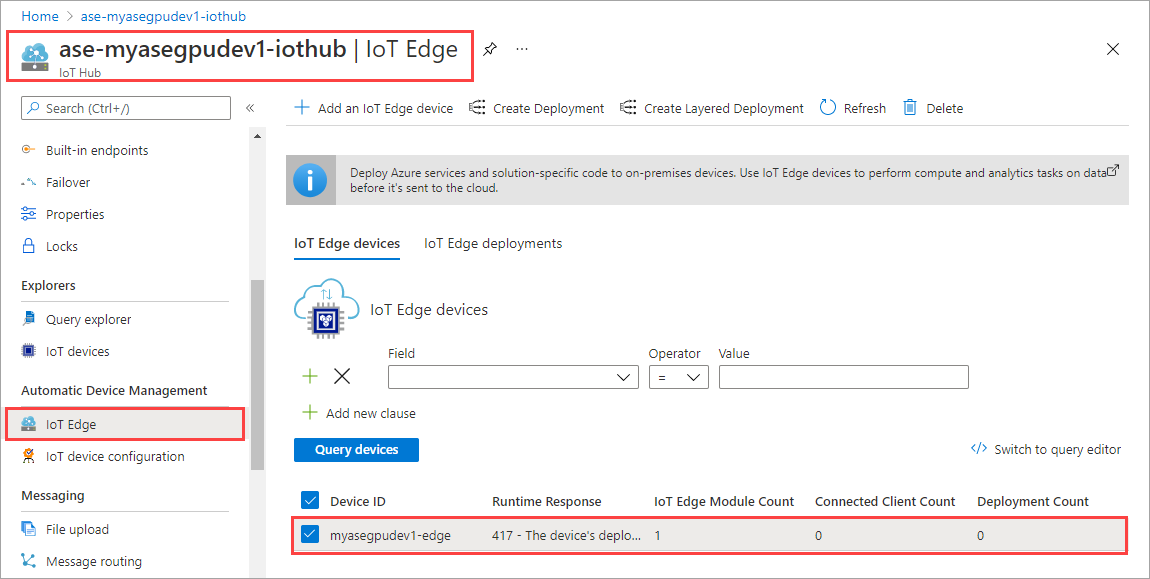
Wechseln Sie in der IoT Hub-Ressource zu Automatische Gerätebereitstellung > IoT Edge. Wählen Sie im rechten Bereich das IoT Edge-Gerät aus, das Ihrem Gerät zugeordnet ist.
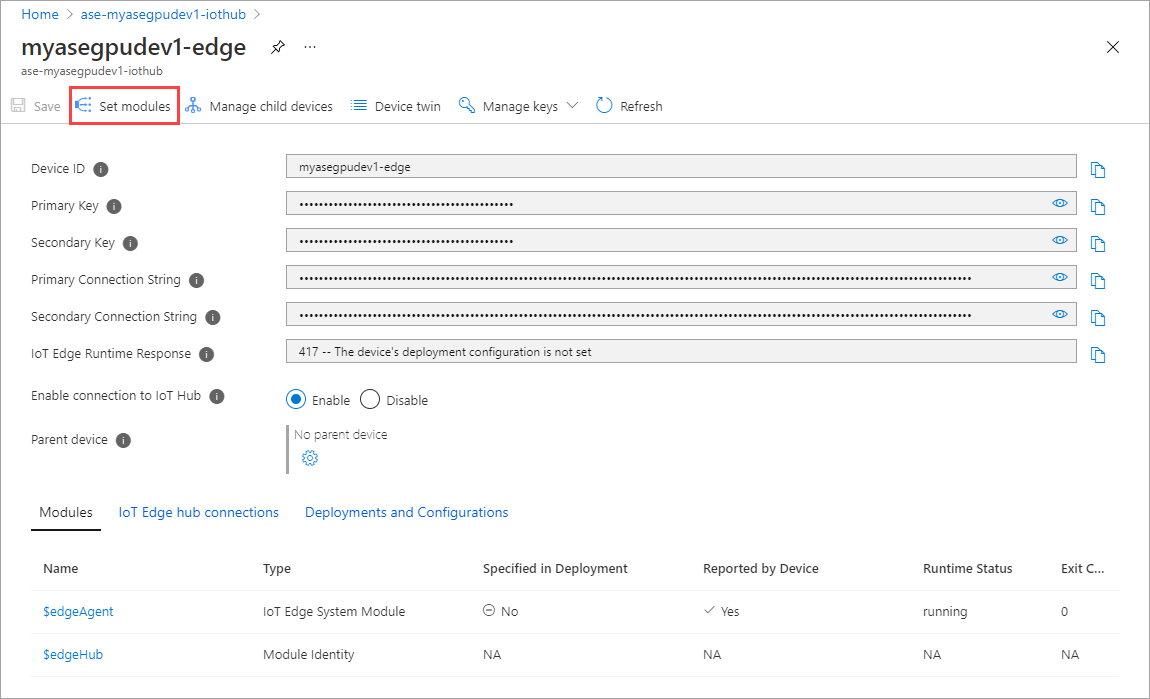
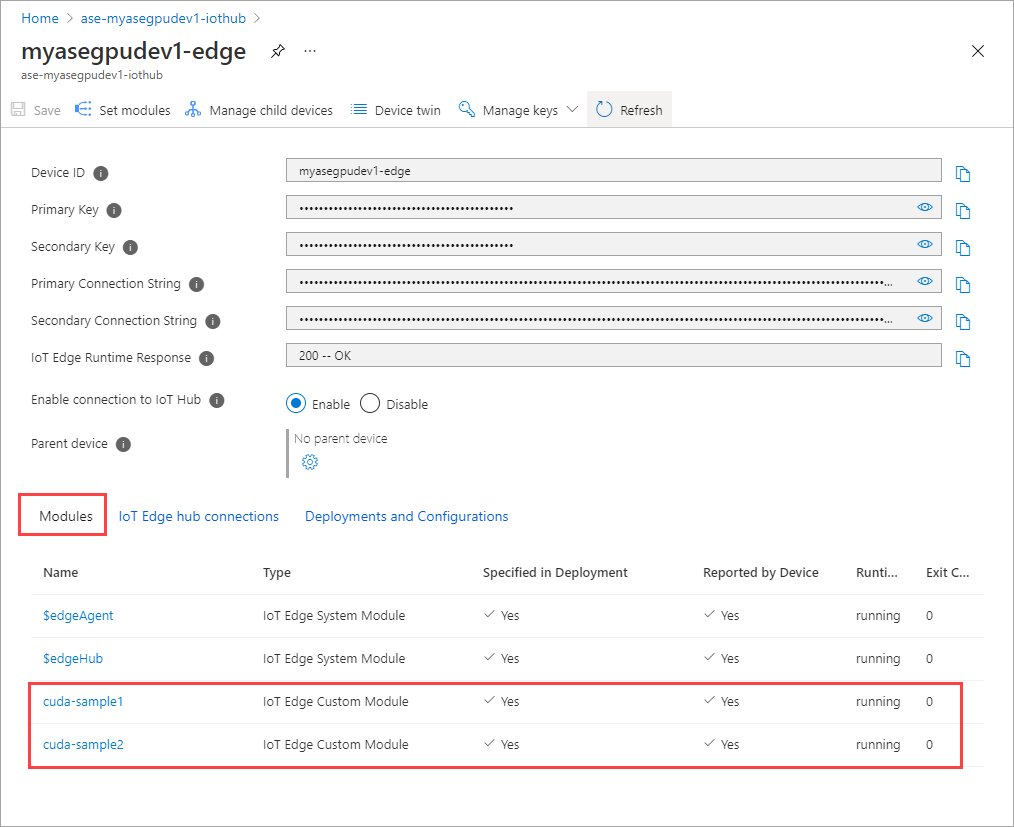
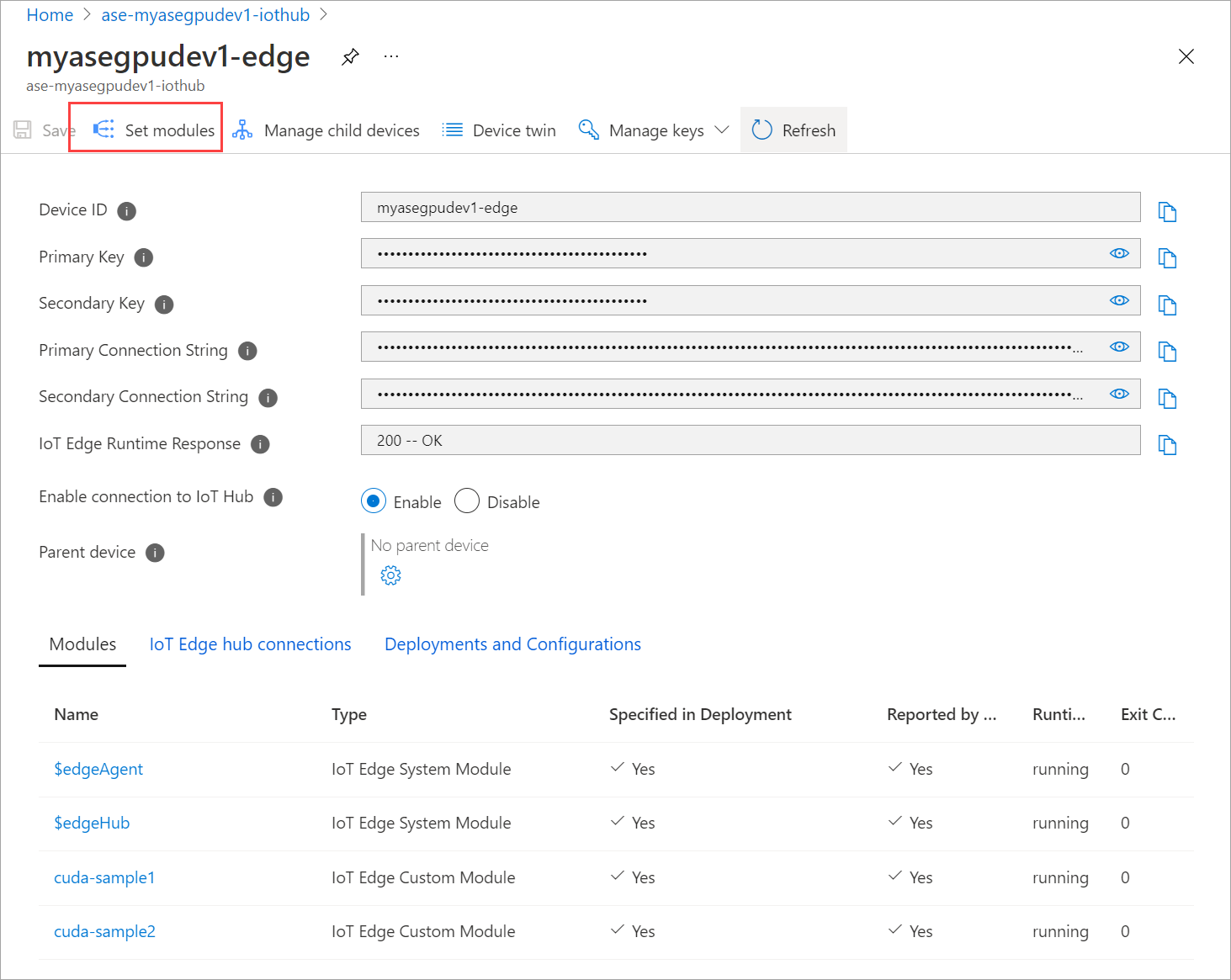
Wählen Sie Module festlegen aus.
Wählen Sie + Hinzufügen > + IoT Edge-Modul aus.
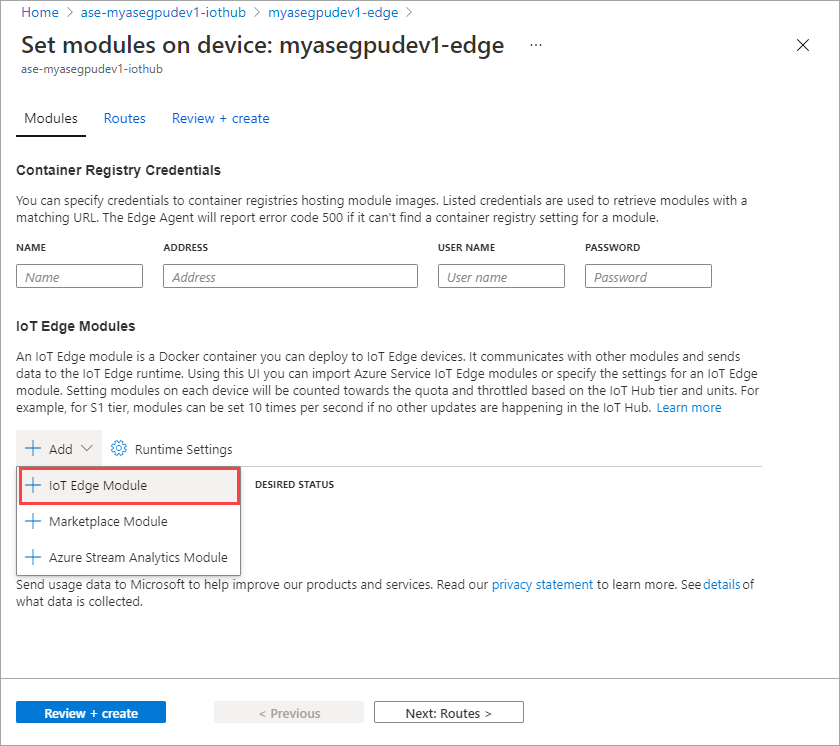
Geben Sie auf der Registerkarte Moduleinstellungen den Namen des IoT Edge-Moduls und die Image-URI an. Legen Sie die Richtlinie zur Imageübertragung per Pull auf Beim Erstellen fest.
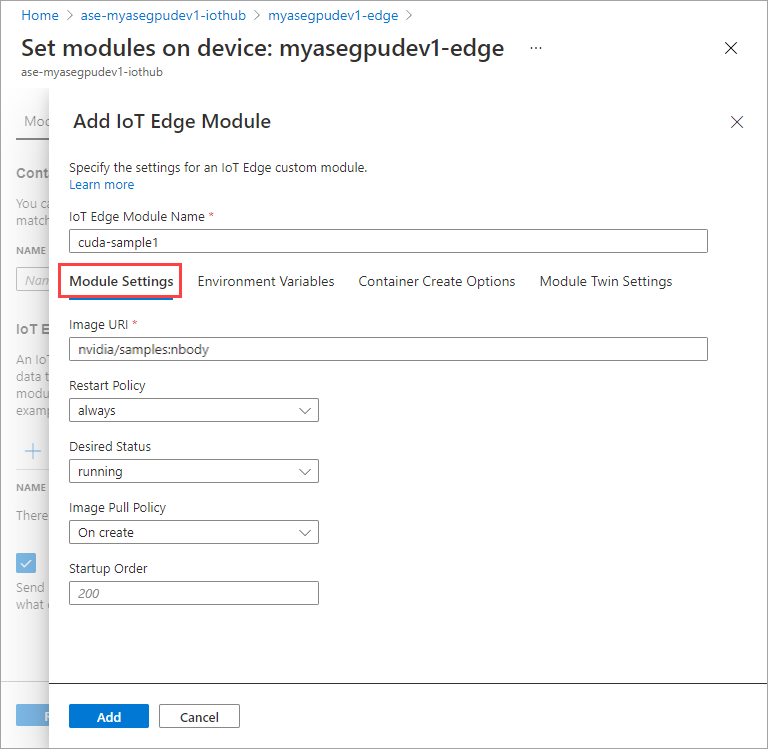
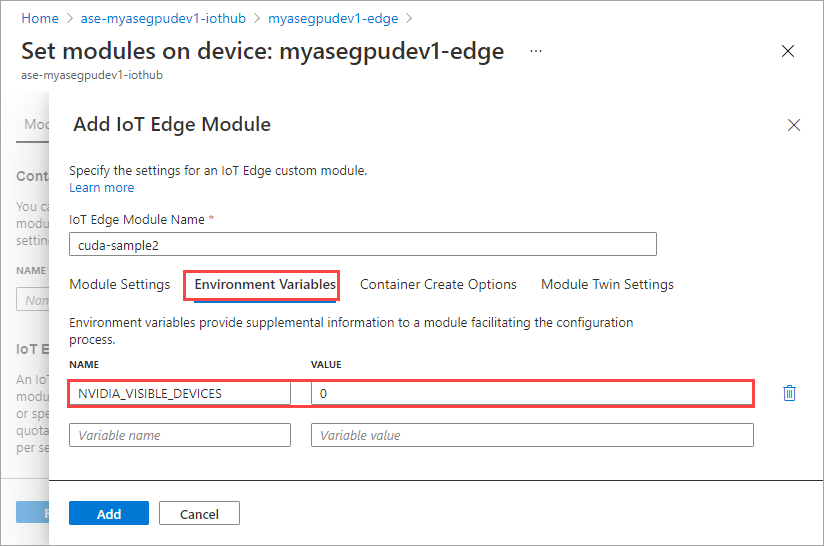
Geben Sie auf der Registerkarte Umgebungsvariablen für NVIDIA_VISIBLE_DEVICES den Wert 0 ein.
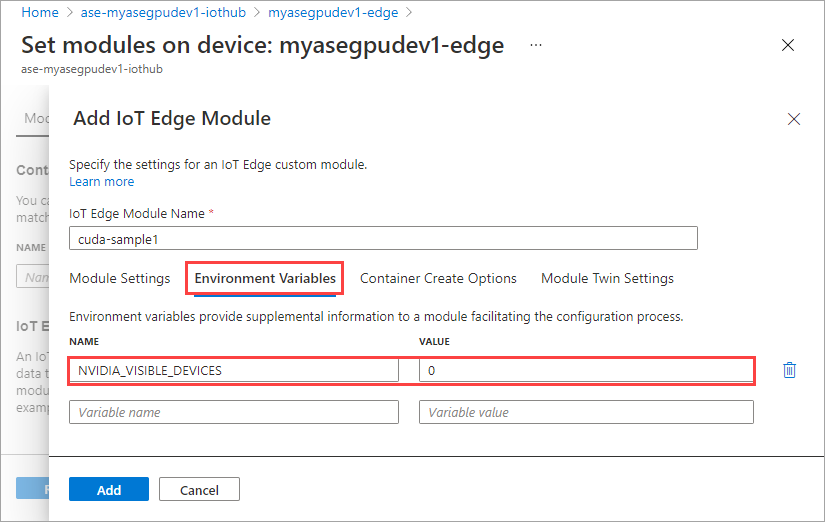
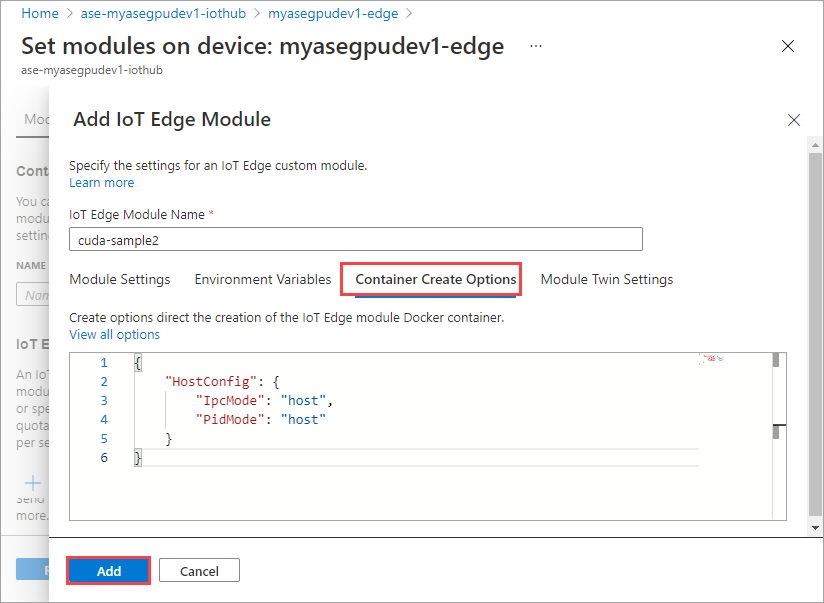
Geben Sie auf der Registerkarte Optionen für Containererstellung die folgenden Optionen an:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Die Optionen werden wie folgt angezeigt:
Klicken Sie auf Hinzufügen.
Das von Ihnen hinzugefügte Modul sollte als Wird ausgeführt angezeigt werden.
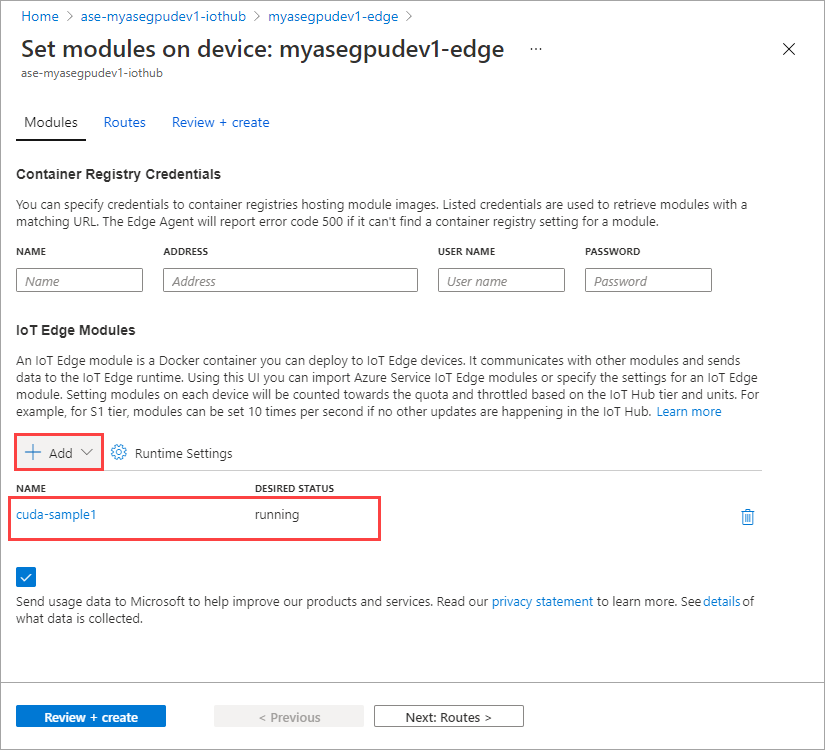
Wiederholen Sie sämtliche Schritte zum Hinzufügen eines Moduls, die Sie beim Hinzufügen des ersten Moduls ausgeführt haben. Nennen Sie das Modul in diesem Beispiel
cuda-sample2.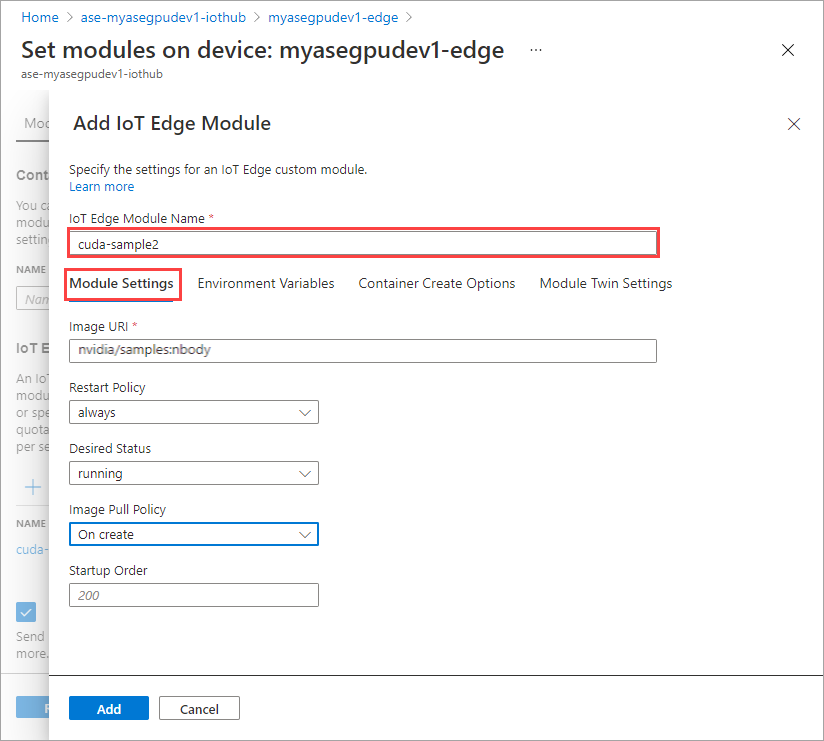
Verwenden Sie dieselbe Umgebungsvariable, da beide Module dieselbe GPU nutzen werden.
Verwenden Sie dieselben Optionen für die Containererstellung, die Sie für das erste Modul angegeben haben, und wählen Sie Hinzufügen aus.
Wählen Sie auf der Seite Module einrichten die Option Überprüfen und erstellen und dann Erstellen aus.
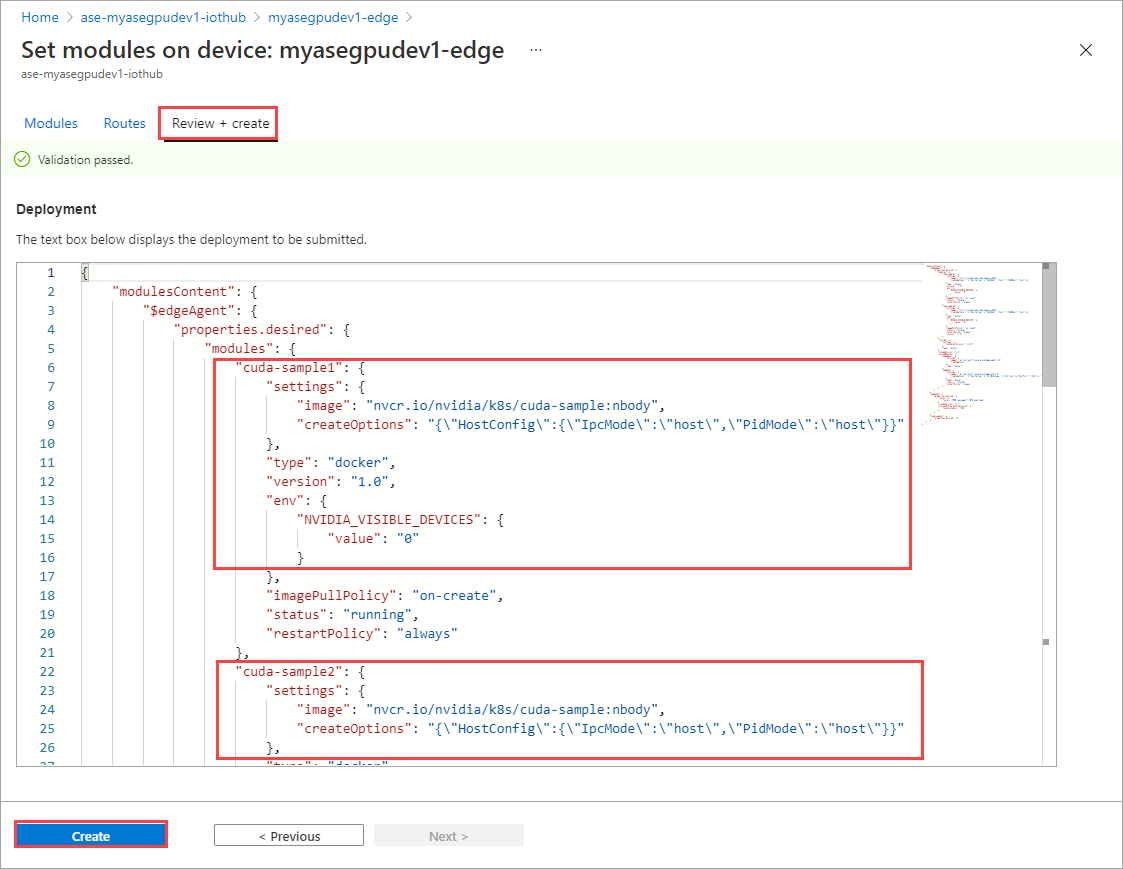
Der Laufzeitstatus beider Module sollte jetzt als Wird ausgeführt angezeigt werden.
Überwachen der Workloadbereitstellung
Öffnen Sie eine neue PowerShell-Sitzung.
Listen Sie die Pods auf, die im Namespace
iotedgeausgeführt werden. Führen Sie den folgenden Befehl aus:kubectl get pods -n iotedgeBeispielausgabe:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Auf Ihrem Gerät werden zwei Pods ausgeführt:
cuda-sample1-97c494d7f-lnmnsundcuda-sample2-d9f6c4688-2rld9.Während beide Container die N-Körper-Simulation ausführen, überprüfen Sie die GPU-Auslastung in der NVIDIA-SMI-Ausgabe. Wechseln Sie zur PowerShell-Schnittstelle des Geräts, und führen Sie
Get-HcsGpuNvidiaSmiaus.Im Folgenden sehen Sie eine Beispielausgabe, wenn beide Container die N-Körper-Simulation ausführen:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Wie Sie sehen können, werden auf GPU 0 zwei Container mit N-Körper-Simulation ausgeführt. Sie können sich auch den entsprechenden Arbeitsspeicherverbrauch ansehen.
Nachdem die Simulation abgeschlossen ist, zeigt die NVIDIA-SMI-Ausgabe, dass auf dem Gerät keine Prozesse ausgeführt werden.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Sehen Sie sich nach Abschluss der N-Körper-Simulation die Protokolle an, um die Details der Bereitstellung und die für die Simulation erforderliche Zeit besser zu verstehen.
Hier sehen Sie eine Beispielausgabe aus dem ersten Container:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Hier sehen Sie eine Beispielausgabe aus dem zweiten Container:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Beenden Sie die Modulbereitstellung. Gehen Sie in der IoT Hub-Ressource für Ihr Gerät folgendermaßen vor:
Wechseln Sie zu Automatische Gerätebereitstellung > IoT Edge. Wählen Sie das IoT Edge-Gerät aus, das Ihrem Gerät entspricht.
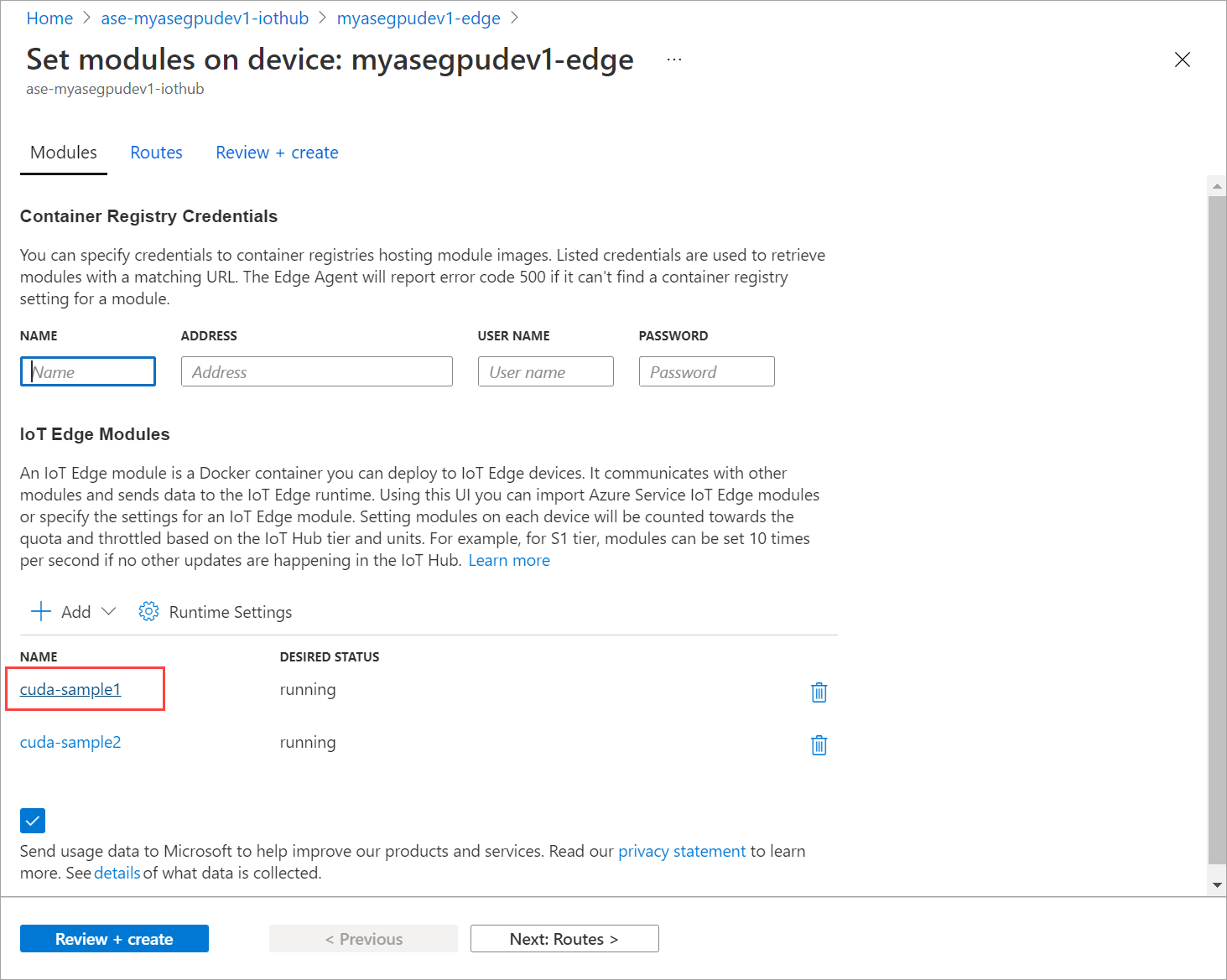
Wechseln Sie zu Module festlegen, und wählen Sie ein Modul aus.
Wählen Sie auf der Registerkarte Module ein Modul aus.
Legen Sie auf der Registerkarte Moduleinstellungen die Option Gewünschter Status auf „beendet“ fest. Wählen Sie Update.
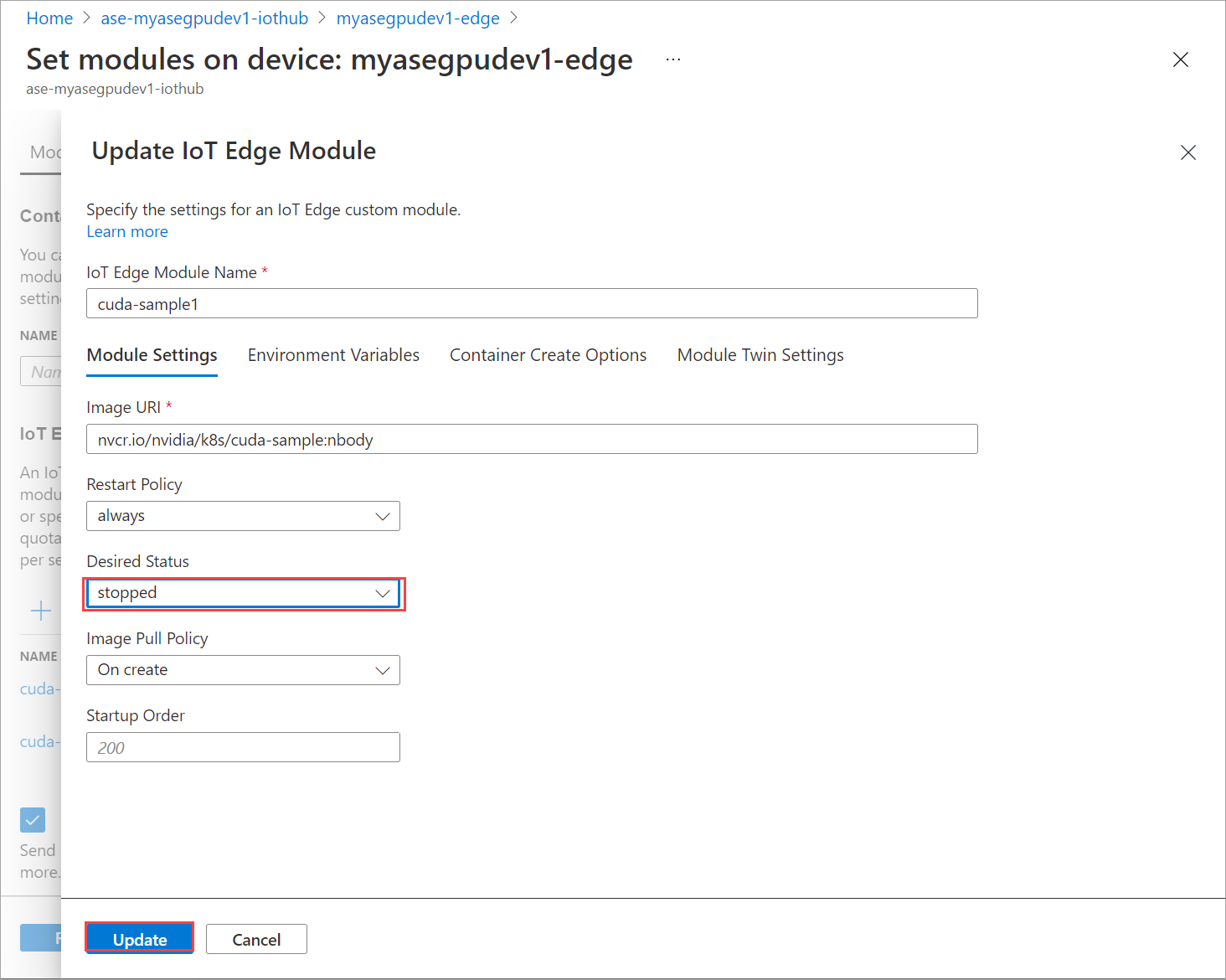
Wiederholen Sie die Schritte, um das zweite auf dem Gerät bereitgestellte Modul zu beenden. Wählen Sie Überprüfen und erstellen und anschließend Erstellen aus. Dadurch sollte die Bereitstellung aktualisiert werden.
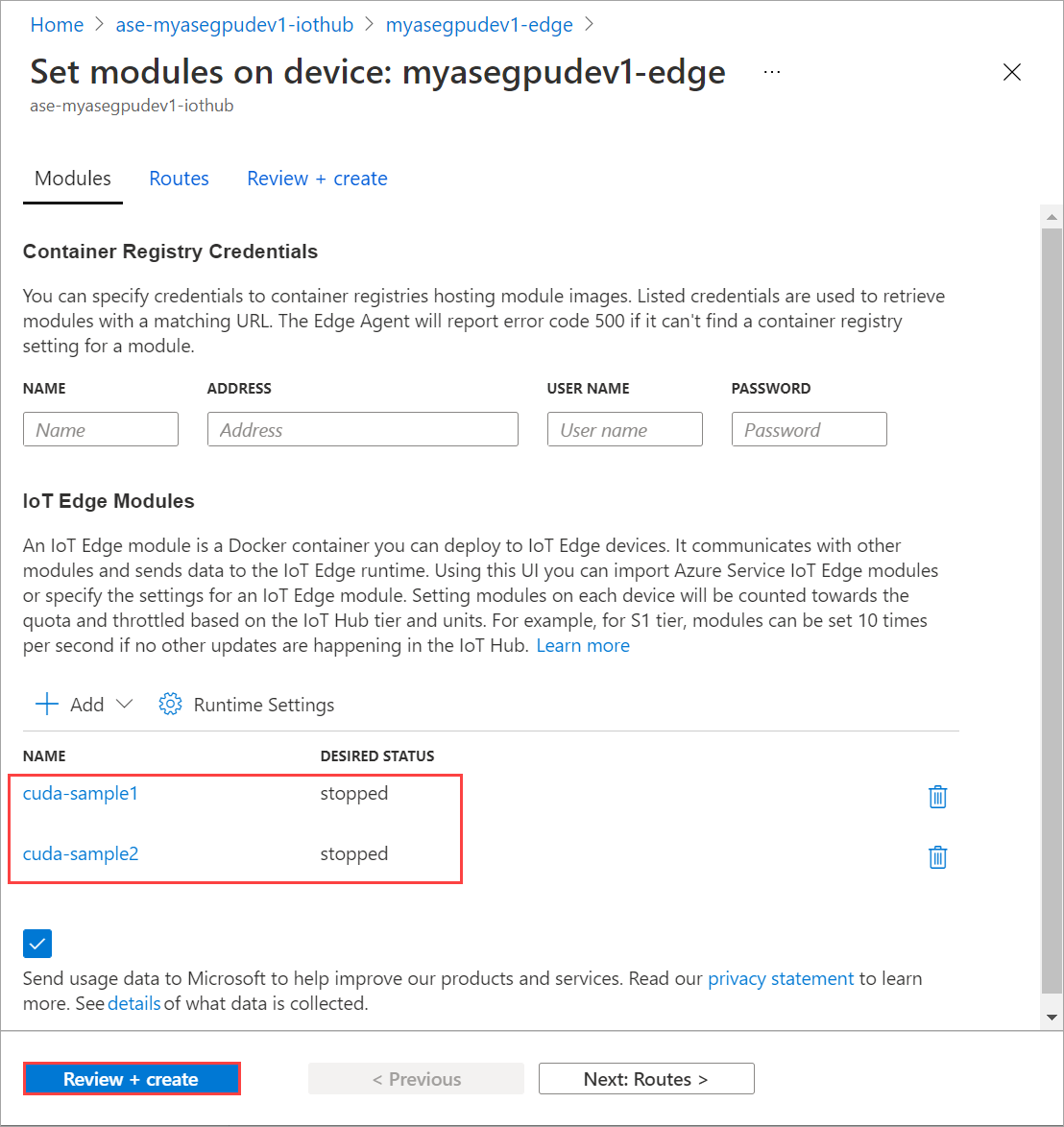
Aktualisieren Sie die Seite Module festlegen mehrmals, bis der Laufzeitstatus als Beendet angezeigt wird.
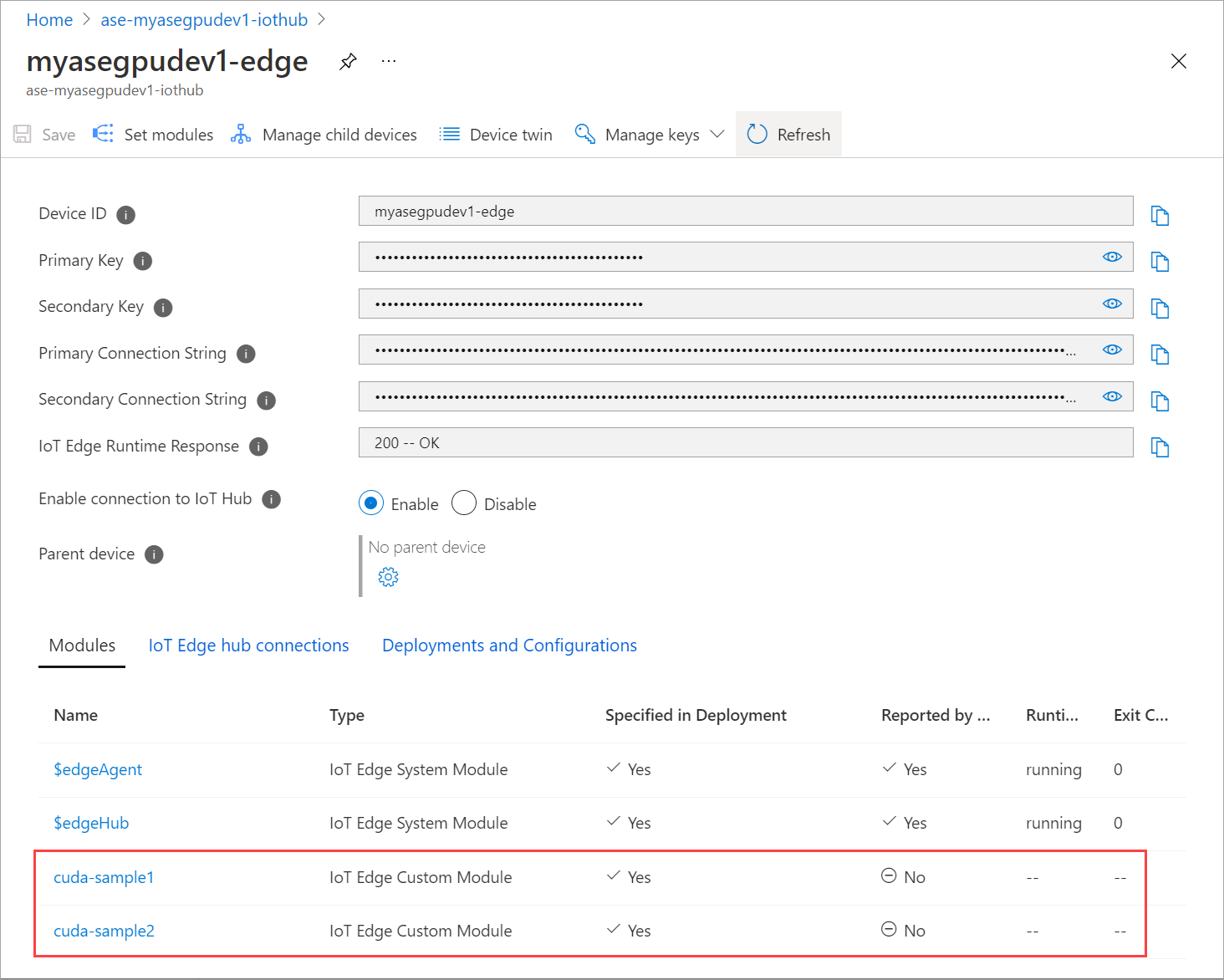
Bereitstellen mit Kontextfreigabe
Jetzt können Sie die N-Körper-Simulation in zwei CUDA-Containern bereitstellen, wenn der Multiprozessdienst auf Ihrem Gerät ausgeführt wird. Aktivieren Sie zunächst den Multiprozessdienst auf dem Gerät.
Stellen Sie auf Ihrem Gerät eine Verbindung mit der PowerShell-Schnittstelle her.
Um den Multiprozessdienst auf Ihrem Gerät zu aktivieren, führen Sie den Befehl
Start-HcsGpuMPSaus.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Rufen Sie die NVIDIA-SMI-Ausgabe von der PowerShell-Schnittstelle des Geräts ab. Sie können sehen, dass der
nvidia-cuda-mps-server-Prozess oder der Multiprozessdienst auf dem Gerät ausgeführt wird.Beispielausgabe:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiStellen Sie die Module bereit, die Sie zuvor beendet haben. Legen Sie den Gewünschten Status über Module festlegen auf „wird ausgeführt“ fest.
Beispielausgabe:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Wie Sie sehen, wurden die Module auf Ihrem Gerät bereitgestellt und werden ausgeführt.
Wenn die Module bereitgestellt sind, startet auch die Ausführung der N-Körper-Simulation in beiden Container. Hier sehen Sie eine Beispielausgabe, nachdem die Simulation im ersten Container abgeschlossen wurde:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Hier sehen Sie eine Beispielausgabe, nachdem die Simulation im zweiten Container abgeschlossen wurde:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Rufen Sie die NVIDIA-SMI-Ausgabe von der PowerShell-Schnittstelle des Geräts ab, wenn beide Container die N-Körper-Simulation ausführen. Hier sehen Sie eine Beispielausgabe. Es gibt drei Prozesse: Der Prozess
nvidia-cuda-mps-server(Typ C) entspricht dem Multiprozessdienst, und die/tmp/nbody-Prozesse (Typ M und C) entsprechen den von den Modulen bereitgestellten N-Körper-Workloads.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi