Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Verwenden Sie Erwartungen, um Qualitätseinschränkungen anzuwenden, die Daten überprüfen, während sie über ETL-Pipelines fließen. Erwartungen bieten einen besseren Einblick in die Datenqualitätsmetriken und ermöglichen es Ihnen, Aktualisierungen scheitern zu lassen oder Datensätze abzulehnen, wenn ungültige Datensätze erkannt werden.
Dieser Artikel enthält eine Übersicht über die Erwartungen, einschließlich Syntaxbeispiele und Verhaltensoptionen. Weitere erweiterte Anwendungsfälle und empfohlene bewährte Methoden finden Sie unter Erwartungsempfehlungen und erweiterte Muster.
Was sind Erwartungen?
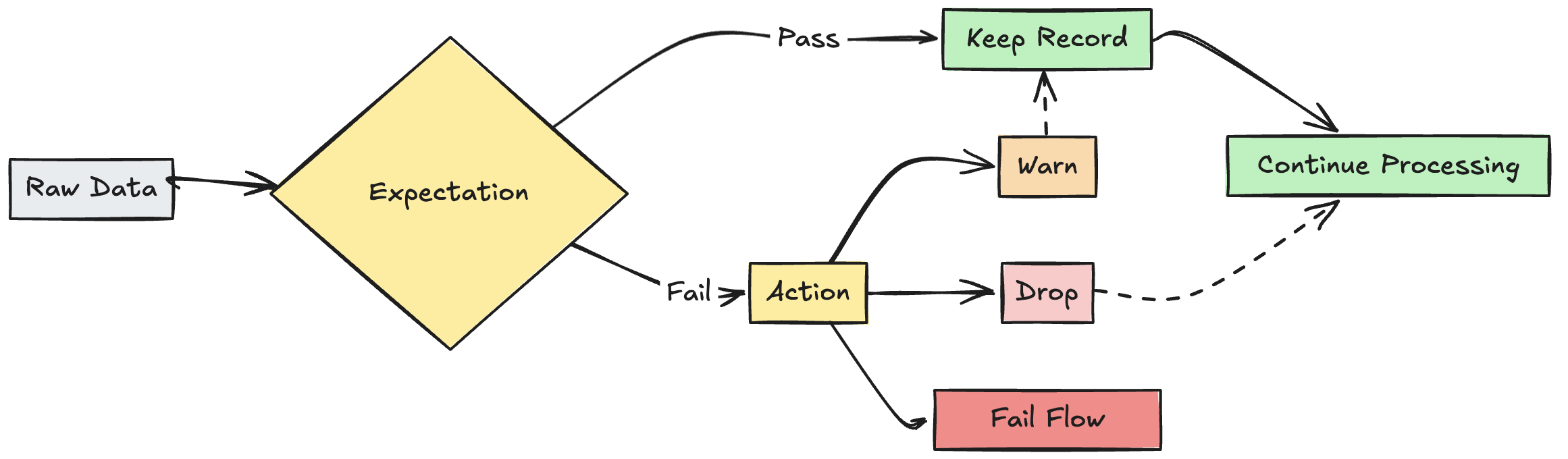
Erwartungen sind optionale Klauseln in der materialisierten Sicht einer Pipeline, der Streamingtabelle oder den Anweisungen zur Erstellung von Ansichten, die Datenqualitätsprüfungen auf jeden einzelnen Datensatz anwenden, der eine Abfrage durchläuft. Erwartungen verwenden standardmäßige SQL Boolean-Anweisungen, um Einschränkungen anzugeben. Sie können mehrere Erwartungen für ein einzelnes Dataset kombinieren und Erwartungen für alle Datasetdeklarationen in einer Pipeline festlegen.
In den folgenden Abschnitten werden die drei Komponenten einer Erwartung vorgestellt und Syntaxbeispiele bereitgestellt.
Erwartungsname
Jede Erwartung muss einen Namen haben, der als Bezeichner zum Nachverfolgen und Überwachen der Erwartung verwendet wird. Wählen Sie einen Namen aus, der die zu überprüfenden Metriken kommuniziert. Im folgenden Beispiel wird die Erwartung valid_customer_age definiert, um zu bestätigen, dass das Alter zwischen 0 und 120 Jahren liegt.
Wichtig
Ein Erwartungsname muss für ein bestimmtes Dataset eindeutig sein. Sie können Erwartungen über mehrere Datasets hinweg in einer Pipeline wiederverwenden. Weitere Informationen finden Sie unter Portierbare und wiederverwendbare Erwartungen.
Python
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
Einschränkung zur Bewertung
Die Einschränkungsklausel ist eine SQL-bedingte Anweisung, die für jeden Datensatz als wahr oder falsch ausgewertet werden muss. Die Einschränkung enthält die tatsächliche Logik für die Überprüfung. Wenn ein Datensatz diese Bedingung nicht erfüllt, wird die Erwartung ausgelöst.
Einschränkungen müssen gültige SQL-Syntax verwenden und dürfen folgendes nicht enthalten:
- Benutzerdefinierte Python-Funktionen
- Aufrufe externer Dienste
- Unterabfragen, die auf andere Tabellen verweisen
Im Folgenden finden Sie Beispiele für Einschränkungen, die den Erstellungsanweisungen des Datasets hinzugefügt werden können:
Python
Die Syntax für eine Einschränkung in Python lautet:
@dlt.expect(<constraint-name>, <constraint-clause>)
Es können mehrere Einschränkungen angegeben werden:
@dlt.expect(<constraint-name>, <constraint-clause>)
@dlt.expect(<constraint2-name>, <constraint2-clause>)
Beispiele
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
Die Syntax für eine Einschränkung in SQL lautet:
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> )
Mehrere Einschränkungen müssen durch ein Komma getrennt werden:
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> ),
CONSTRAINT <constraint2-name> EXPECT ( <constraint2-clause> )
Beispiele
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
Aktion bei ungültigem Datensatz
Sie müssen eine Aktion angeben, um zu bestimmen, was passiert, wenn ein Datensatz die Überprüfung fehlschlägt. In der folgenden Tabelle werden die verfügbaren Aktionen beschrieben:
| Maßnahme | SQL-Syntax | Python-Syntax | Ergebnis |
|---|---|---|---|
| warnen (Standard) | EXPECT |
dlt.expect |
Ungültige Datensätze werden in das Ziel geschrieben. |
| fallen lassen | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
Ungültige Datensätze werden gelöscht, bevor Daten in das Ziel geschrieben werden. Die Anzahl der verworfenen Datensätze wird zusammen mit anderen Datasetmetriken protokolliert. |
| Fehler | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
Ungültige Datensätze verhindern, dass das Update erfolgreich ausgeführt wird. Manuelle Eingriffe sind erforderlich, bevor sie erneut verarbeitet werden. Diese Erwartung verursacht einen Fehler eines einzelnen Flusses und führt nicht dazu, dass andere Flüsse in Ihrer Pipeline fehlschlagen. |
Sie können auch erweiterte Logik implementieren, um ungültige Datensätze unter Quarantäne zu stellen, ohne dass Daten verloren gehen oder gelöscht werden. Weitere Informationen finden Sie unter Ungültige Datensätze unter Quarantäne stellen.
Metriken zur Erwartungsverfolgung
Sie können Nachverfolgungsmetriken für Aktionen vom Typ warn oder drop über die Pipelinebenutzeroberfläche anzeigen. Da fail das Update fehlschlägt, wenn ein ungültiger Datensatz erkannt wird, werden Metriken nicht aufgezeichnet.
Führen Sie zum Anzeigen von Erwartungsmetriken die folgenden Schritte aus:
- Klicken Sie in der Randleiste Ihres Azure Databricks-Arbeitsbereichs auf Aufträge und Pipelines.
- Klicken Sie auf den Namen Ihrer Pipeline.
- Klicken Sie auf ein Dataset mit definierter Erwartung.
- Wählen Sie die Registerkarte "Datenqualität " in der rechten Randleiste aus.
Sie können Datenqualitätsmetriken anzeigen, indem Sie das Lakeflow Declarative Pipelines-Ereignisprotokoll abfragen. Siehe Abfragedatenqualität aus dem Ereignisprotokoll.
Aufbewahren ungültiger Datensätze
Das Aufbewahren ungültiger Datensätze ist das Standardverhalten für Erwartungen. Verwenden Sie den expect-Operator, wenn Sie Datensätze aufbewahren möchten, die gegen die Erwartung verstoßen, aber Metriken dazu sammeln möchten, wie viele Datensätze eine Einschränkung erfüllen bzw. nicht erfüllen. Datensätze, die gegen die Erwartung verstoßen, werden dem Zieldatensatz zusammen mit gültigen Datensätzen hinzugefügt:
Python
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
Ungültige Datensätze ablegen
Verwenden Sie den expect_or_drop Operator, um eine weitere Verarbeitung ungültiger Datensätze zu verhindern. Datensätze, die gegen die Erwartung verstoßen, werden aus dem Zieldatensatz gelöscht:
Python
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
Fehler bei ungültigen Datensätzen
Wenn ungültige Datensätze inakzeptabel sind, verwenden Sie den Operator, um die expect_or_fail Ausführung sofort zu beenden, wenn eine Datensatzüberprüfung fehlschlägt. Wenn es sich bei dem Vorgang um eine Tabellenaktualisierung handelt, setzt das System die Transaktion atomisch zurück:
Python
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
Wichtig
Wenn in einer Pipeline mehrere parallele Flüsse definiert sind, führt ein Ausfall eines einzelnen Flusses nicht zu einem Fehler anderer Flüsse.
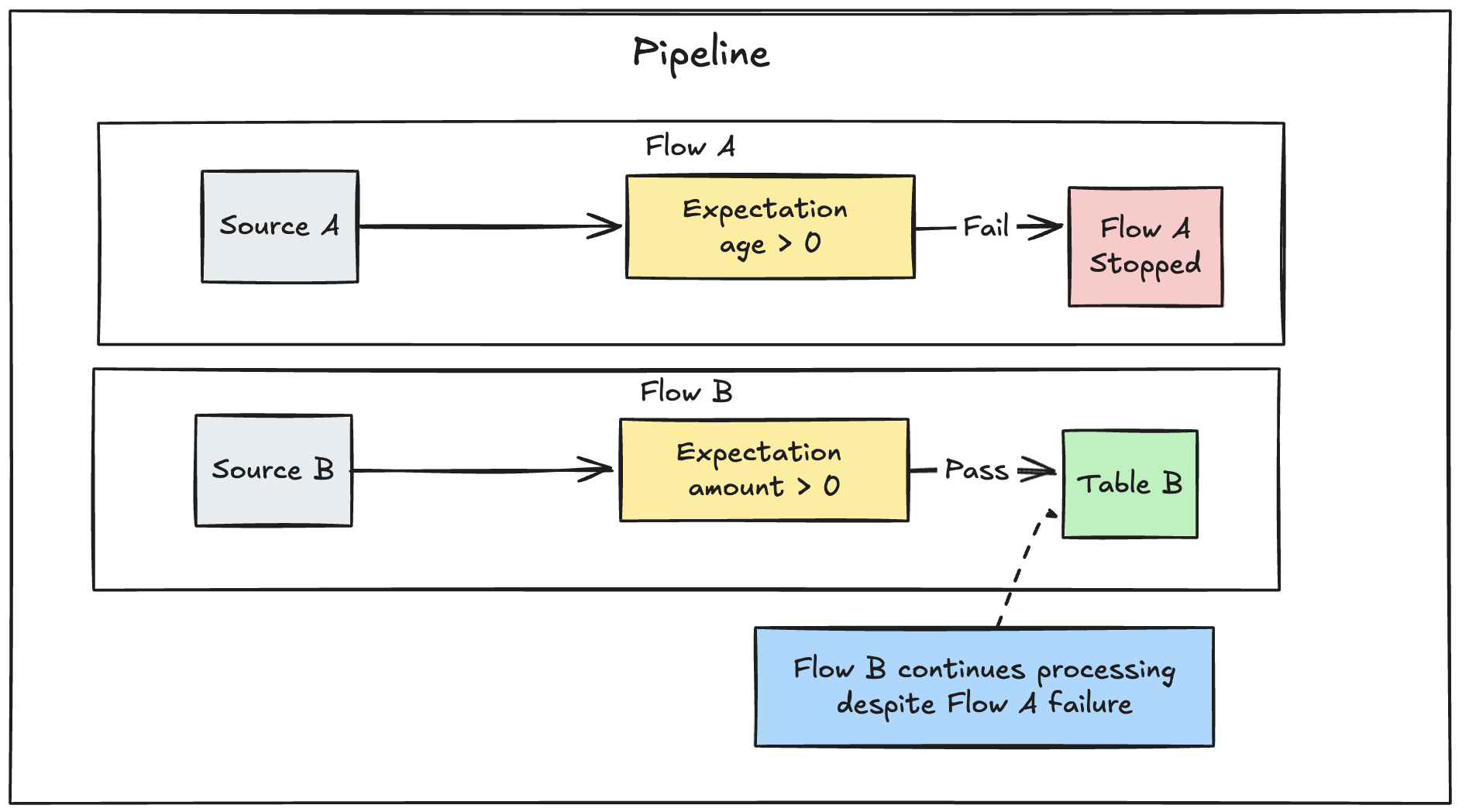
Problembehandlung bei fehlerhaften Updates aufgrund von Erwartungsfehlern
Wenn eine Pipeline aufgrund einer Erwartungsverletzung fehlschlägt, müssen Sie den Pipelinecode korrigieren, um die ungültigen Daten korrekt zu behandeln, bevor Sie die Pipeline erneut ausführen.
Erwartungen, die so konfiguriert sind, dass Pipelines fehlschlagen, ändern den Spark-Abfrageplan Ihrer Transformationen, um Informationen nachzuverfolgen, die zum Erkennen und Melden von Verstößen erforderlich sind. Sie können diese Informationen verwenden, um zu identifizieren, welcher Eingabedatensatz zu einer Verletzung für viele Abfragen geführt hat. Lakeflow Declarative Pipelines stellt eine dedizierte Fehlermeldung bereit, um solche Verstöße zu melden. Hier sehen Sie ein Beispiel für eine Fehlermeldung zur Erwartungsverletzung:
[EXPECTATION_VIOLATION.VERBOSITY_ALL] Flow 'sensor-pipeline' failed to meet the expectation. Violated expectations: 'temperature_in_valid_range'. Input data: '{"id":"TEMP_001","temperature":-500,"timestamp_ms":"1710498600"}'. Output record: '{"sensor_id":"TEMP_001","temperature":-500,"change_time":"2024-03-15 10:30:00"}'. Missing input data: false
Management mehrerer Erwartungen
Hinweis
Während sowohl SQL als auch Python mehrere Erwartungen in einem einzelnen Dataset unterstützen, ermöglicht nur Python das Gruppieren mehrerer Erwartungen und das Angeben kollektiver Aktionen.
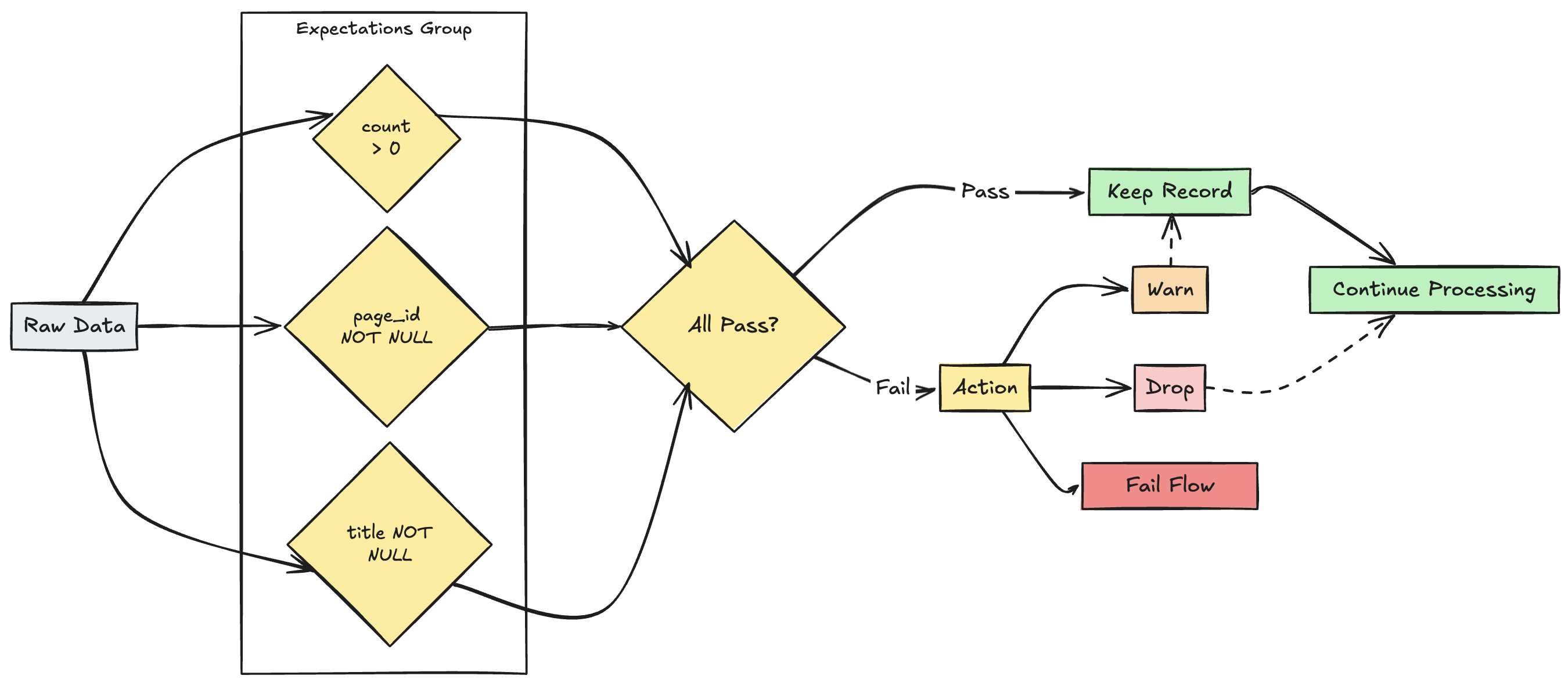
Sie können mehrere Erwartungen gruppieren und kollektive Aktionen mithilfe der Funktionen expect_all, expect_all_or_drop und expect_all_or_fail angeben.
Diese Dekorateure akzeptieren ein Python-Wörterbuch als Argument, wobei der Schlüssel der Erwartungsname und der Wert die Erwartungseinschränkung ist. Sie können die gleichen Erwartungen in mehreren Datasets in Ihrer Pipeline wiederverwenden. Im Folgenden finden Sie Beispiele für die einzelnen expect_all Python-Operatoren:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset
Einschränkungen
- Da nur Streamingtabellen und materialisierte Ansichten Erwartungen unterstützen, werden Datenqualitätsmetriken nur für diese Objekttypen unterstützt.
- Datenqualitätsmetriken sind nicht verfügbar, wenn:
- Für eine Abfrage sind keine Erwartungen definiert.
- Ein Fluss verwendet einen Operator, der die Erwartungen nicht unterstützt.
- Der Flusstyp, z. B. Lakeflow Declarative Pipelines sinks, erfüllt keine Erwartungen.
- Es gibt keine Aktualisierungen der zugeordneten Streamingtabelle oder der materialisierten Ansicht für einen bestimmten Flusslauf.
- Die Pipelinekonfiguration enthält nicht die erforderlichen Einstellungen für die Erfassung von Metriken, z. B.
pipelines.metrics.flowTimeReporter.enabled.
- In einigen Fällen enthält ein
COMPLETEDFluss möglicherweise keine Metriken. Stattdessen werden Metriken in jedem Mikrobatch in einemflow_progressEreignis mit dem StatusRUNNINGgemeldet.