Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden die integrierten Überwachungs- und Observierbarkeitsfeatures für deklarative Pipelines von Lakeflow beschrieben. Diese Features unterstützen Aufgaben wie:
- Beobachten des Fortschritts und des Status von Pipelineupdates. Weitere Informationen finden Sie unter Welche Pipelinedetails sind auf der Benutzeroberfläche verfügbar?.
- Warnung bei Pipelineereignissen wie Erfolg oder Ausfall von Pipelineupdates. Siehe Hinzufügen von E-Mail-Benachrichtigungen für Pipelineereignisse.
- Anzeigen von Metriken für Streamingquellen wie Apache Kafka und Auto Loader (Public Preview). Siehe Streamingmetriken anzeigen.
- Extrahieren detaillierter Informationen zu Pipelineupdates wie Datenherkunft, Datenqualitätsmetriken und Ressourcenverbrauch. Sehen Sie sich an, was ist das Lakeflow Declarative Pipelines-Ereignisprotokoll?.
- Definieren benutzerdefinierter Aktionen, die ausgeführt werden sollen, wenn bestimmte Ereignisse auftreten. Informationen finden Sie unter Definieren der benutzerdefinierten Überwachung von deklarativen Lakeflow-Pipelines mit Ereignishaken.
Informationen zum Überprüfen und Diagnostizieren der Abfrageleistung finden Sie im Access-Abfrageverlauf für deklarative Lakeflow-Pipelines. Diese Funktion ist in der öffentlichen Vorschauversion.
Hinzufügen von E-Mail-Benachrichtigungen für Pipelineereignisse
Sie können eine oder mehrere E-Mail-Adressen für den Empfang von Benachrichtigungen konfigurieren, wenn Folgendes auftritt:
- Ein Pipelineupdate wird erfolgreich abgeschlossen.
- Ein Pipelineupdate schlägt fehl, entweder mit einem wiederholbaren oder einem nicht wiederholbaren Fehler. Wählen Sie diese Option aus, um eine Benachrichtigung für alle Pipelinefehler zu erhalten.
- Ein Pipelineupdate schlägt mit einem nicht wiederholbaren (schwerwiegenden) Fehler fehl. Wählen Sie diese Option aus, um nur dann eine Benachrichtigung zu erhalten, wenn ein nicht wiederholbarer Fehler auftritt.
- Ein einzelner Datenfluss schlägt fehl.
So konfigurieren Sie E-Mail-Benachrichtigungen beim Erstellen oder Bearbeiten einer Pipeline:
- Klicken Sie auf Benachrichtigung hinzufügen.
- Geben Sie mindestens eine E-Mail-Adresse ein, um Benachrichtigungen zu empfangen.
- Klicken Sie auf das Kontrollkästchen für jeden Benachrichtigungstyp, um an die konfigurierten E-Mail-Adressen zu senden.
- Klicken Sie auf Benachrichtigung hinzufügen.
Anzeigen von Pipelines in der Benutzeroberfläche
Suchen Sie Ihre deklarativen Lakeflow-Pipelines über die Option "Aufträge und Pipelines " in der Arbeitsbereich-Randleiste. Dadurch wird die Seite "Aufträge und Pipelines " geöffnet, auf der Sie Informationen zu jedem Auftrag und jeder Pipeline anzeigen können, auf die Sie Zugriff haben. Klicken Sie auf den Namen einer Pipeline, um die Pipelinedetailseite zu öffnen.
Verwenden der Liste „Jobs und Pipelines“
Um die Liste der Pipelines anzuzeigen, auf die Sie Zugriff haben, klicken Sie auf das ![]() Aufträge & Pipelines in der Randleiste. Auf der Registerkarte "Aufträge & Pipelines " werden Informationen zu allen verfügbaren Aufträgen und Pipelines aufgelistet, z. B. der Ersteller, der Trigger (falls vorhanden) und das Ergebnis der letzten fünf Ausführungen.
Aufträge & Pipelines in der Randleiste. Auf der Registerkarte "Aufträge & Pipelines " werden Informationen zu allen verfügbaren Aufträgen und Pipelines aufgelistet, z. B. der Ersteller, der Trigger (falls vorhanden) und das Ergebnis der letzten fünf Ausführungen.
Wenn Sie die in der Liste angezeigten Spalten ändern möchten, klicken Sie auf ![]() , und wählen Sie Spalten aus, oder deaktivieren Sie sie.
, und wählen Sie Spalten aus, oder deaktivieren Sie sie.
Von Bedeutung
Die einheitliche Liste der Jobs und Pipelines befindet sich in der öffentlichen Vorschau. Sie können das Feature deaktivieren und zur Standardumgebung zurückkehren, indem Sie Aufträge und Pipelines deaktivieren: Einheitliche Verwaltung, Suche und Filterung. Weitere Informationen finden Sie unter Verwalten von Azure Databricks Previews .
Sie können Jobs in der Liste Jobs und Pipelines filtern, wie im folgenden Screenshot gezeigt.
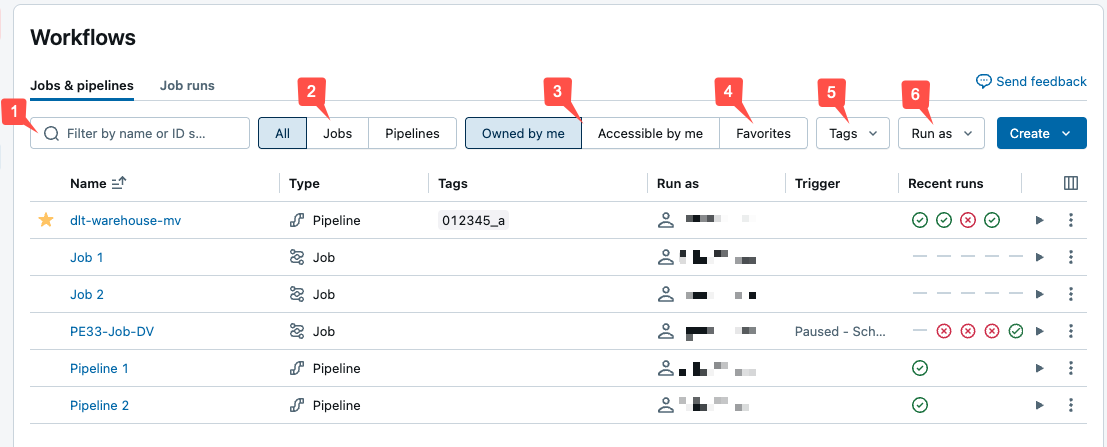
-
Textsuche: Die Schlüsselwortsuche wird für die Felder "Name " und "ID " unterstützt. Um nach einem Tag zu suchen, das mit einem Schlüssel und einem Wert erstellt wurde, können Sie nach dem Schlüssel und/oder dem Wert suchen. Beispielsweise können Sie für ein Tag mit dem Schlüssel
departmentund dem Wertfinancenachdepartmentoderfinancesuchen, um übereinstimmende Aufträgen zu ermitteln. Um nach dem Schlüssel und wert zu suchen, geben Sie den Schlüssel und den Wert ein, der durch einen Doppelpunkt getrennt ist (z. B.department:finance). - Typ: Filtern nach Aufträgen, Pipelines oder Allen. Wenn Sie Pipelines auswählen, können Sie auch nach Pipelinetyp filtern, einschließlich ETL- und Aufnahmepipelinen.
- Besitzer: Zeigen Sie nur die Aufträge an, die Sie besitzen.
- Favoriten: Anzeigen von Aufträgen, die Sie als Favoriten markiert haben.
- Tags: Verwenden Sie Tags. Um nach Tag zu suchen, können Sie das Dropdownmenü "Tags" verwenden, um gleichzeitig nach bis zu fünf Tags zu filtern oder die Stichwortsuche direkt zu verwenden.
-
Ausführen als: Filtern nach bis zu zwei
run asWerten.
Um einen Job oder eine Pipeline zu starten, klicken Sie auf die Wiedergabeschaltfläche ![]() . Um einen Auftrag oder eine Pipeline zu beenden, klicken Sie auf die
. Um einen Auftrag oder eine Pipeline zu beenden, klicken Sie auf die ![]() . Um auf andere Aktionen zuzugreifen, klicken Sie auf das
. Um auf andere Aktionen zuzugreifen, klicken Sie auf das ![]() Sie können z. B. den Auftrag oder die Pipeline löschen oder auf Einstellungen für eine Pipeline aus diesem Menü zugreifen.
Sie können z. B. den Auftrag oder die Pipeline löschen oder auf Einstellungen für eine Pipeline aus diesem Menü zugreifen.
Welche Pipelinedetails sind auf der Benutzeroberfläche verfügbar?
Das Pipelinediagramm wird angezeigt, sobald eine Aktualisierung einer Pipeline erfolgreich gestartet wurde. Pfeile stellen Abhängigkeiten zwischen Datasets in Ihrer Pipeline dar. Standardmäßig zeigt die Seite mit den Pipelinedetails das neueste Update für die Tabelle an, aber Sie können ältere Updates aus einem Dropdownmenü auswählen.
Details umfassen die Pipeline-ID, den Quellcode, die Berechnungskosten, die Produktedition und den kanal, der für die Pipeline konfiguriert ist.
Um eine tabellarische Ansicht von Datasets anzuzeigen, klicken Sie auf die Registerkarte Liste. Mit der Ansicht Liste können Sie alle Datasets in Ihrer Pipeline anzeigen, die als Zeile in einer Tabelle dargestellt werden. Dies ist nützlich, wenn der Pipeline-DAG zu groß ist, um in der Graph-Ansicht angezeigt zu werden. Sie können die Anzeige der Datasets in der Tabelle mithilfe mehrerer Filter steuern, z. B. Name, Typ und Status des Datasets. Um zur DAG-Visualisierung zurückzukehren, klicken Sie auf Graph.
Der Ausführen als-Benutzer ist der Pipelinebesitzer, und Pipeline-Updates werden mit den Berechtigungen dieses Benutzers ausgeführt. Um den run as-Benutzer zu ändern, klicken Sie auf Berechtigungen, und ändern Sie den Pipelinebesitzer.
Wie können Datasetdetails angezeigt werden?
Wenn Sie auf ein Dataset in der Pipelinediagramm- oder Datasetliste klicken, werden Details zum Dataset angezeigt. Details umfassen das Datasetschema, Datenqualitätsmetriken und einen Link zum Quellcode, der das Dataset definiert.
Prüfen des Updateverlaufs
Klicken Sie auf das Dropdownmenü „Updateverlauf“, um den Verlauf und den Status von Pipelineupdates anzuzeigen.
Wählen Sie das Update im Dropdownmenü aus, um das Diagramm, details und Ereignisse für ein Update anzuzeigen. Klicken Sie auf Aktuelles Update anzeigen, um zum neuesten Update zurückzukehren.
Anzeigen von Streamingmetriken
Von Bedeutung
Streaming-Beobachtbarkeit für Lakeflow-Deklarative-Pipelines befindet sich in der öffentlichen Vorschau.
Sie können Streamingmetriken aus den von Spark Structured Streaming unterstützten Datenquellen wie Apache Kafka, Amazon Kinesis, Auto Loader und Delta-Tabellen für jeden Streamingfluss in Ihren Lakeflow Declarative Pipelines anzeigen. Metriken werden als Diagramme im rechten Bereich der Lakeflow-Deklarative Pipelines-Benutzeroberfläche angezeigt und enthalten Backlog-Sekunden, Backlogbytes, Backlog-Datensätze und Backlogdateien. In den Diagrammen wird der maximale Wert nach Minute aggregiert angezeigt, und ein Tooltip zeigt die maximalen Werte an, wenn Sie mit der Maus über das Diagramm fahren. Die Daten sind auf die letzten 48 Stunden ab der aktuellen Zeit beschränkt.
Wenn für Tabellen in Ihrer Pipeline Streamingmetriken verfügbar sind, wird das Symbol ![]() angezeigt, wenn Sie den gerichteten azyklischen Graphen der Pipeline in der Ansicht Graph der Benutzeroberfläche anzeigen. Zum Anzeigen der Streamingmetriken klicken Sie auf das
angezeigt, wenn Sie den gerichteten azyklischen Graphen der Pipeline in der Ansicht Graph der Benutzeroberfläche anzeigen. Zum Anzeigen der Streamingmetriken klicken Sie auf das ![]() , um das Streamingmetrikdiagramm auf der Registerkarte "Flüsse " im rechten Bereich anzuzeigen. Sie können auch einen Filter anwenden, um nur Tabellen mit Streamingmetriken anzuzeigen, indem Sie auf Liste und dann auf Mit Streamingmetrikenklicken.
, um das Streamingmetrikdiagramm auf der Registerkarte "Flüsse " im rechten Bereich anzuzeigen. Sie können auch einen Filter anwenden, um nur Tabellen mit Streamingmetriken anzuzeigen, indem Sie auf Liste und dann auf Mit Streamingmetrikenklicken.
Jede Streamingquelle unterstützt nur bestimmte Metriken. Metriken, die von einer Streamingquelle nicht unterstützt werden, stehen nicht zur Anzeige auf der Benutzeroberfläche zur Verfügung. In der folgenden Tabelle sind die Metriken aufgeführt, die für unterstützte Streamingquellen verfügbar sind:
| Quelle | Backlogbyte | Backlog-Datensätze | Backlogsekunden | Backlogdateien |
|---|---|---|---|---|
| Kafka | ✓ | ✓ | ||
| Kinese | ✓ | ✓ | ||
| Delta | ✓ | ✓ | ||
| Automatischer Lader | ✓ | ✓ | ||
| Google Pub/Sub | ✓ | ✓ |
Was ist das Lakeflow Declarative Pipelines-Ereignisprotokoll?
Das Ereignisprotokoll "Lakeflow Declarative Pipelines" enthält alle Informationen zu einer Pipeline, einschließlich Überwachungsprotokolle, Datenqualitätsprüfungen, Pipelinefortschritt und Datenleitung. Sie können das Ereignisprotokoll verwenden, um den Status Ihrer Datenpipelines nachzuverfolgen, zu verstehen und zu überwachen.
Sie können Ereignisprotokolleinträge in der Benutzeroberfläche von Lakeflow Declarative Pipelines, der Lakeflow Declarative Pipelines-API oder durch direkte Abfrage des Ereignisprotokolls anzeigen. Dieser Abschnitt konzentriert sich auf das direkte Abfragen des Ereignisprotokolls.
Sie können auch benutzerdefinierte Aktionen definieren, die ausgeführt werden sollen, wenn Ereignisse mit Ereignishooks protokolliert werden, z. B. das Senden von Warnungen.
Von Bedeutung
Löschen Sie nicht das Ereignisprotokoll, den übergeordneten Katalog oder das Schema, in dem es veröffentlicht wird. Das Löschen des Ereignisprotokolls kann dazu führen, dass die Pipeline während zukünftiger Ausführung nicht aktualisiert werden kann.
Ereignisprotokollschema
In folgender Tabelle wird das Ereignisprotokollschema beschrieben. Einige dieser Felder enthalten JSON-Daten, die geparst werden müssen, um einige Abfragen durchzuführen, wie z. B. das Feld details. Azure Databricks unterstützt den :-Operator zum Parsen von JSON-Feldern. Weitere Informationen zum :-Operator (Doppelpunkt).
| Feld | BESCHREIBUNG |
|---|---|
id |
Ein eindeutiger Bezeichner für den Ereignisprotokolldatensatz. |
sequence |
Dies ist ein JSON-Dokument, das Metadaten zum Identifizieren und Anordnen von Ereignissen enthält. |
origin |
Ein JSON-Dokument, das Metadaten für den Ursprung des Ereignisses enthält, z. B. den Cloudanbieter, die Cloudanbieterregion, user_id, pipeline_id oder pipeline_type, um anzuzeigen, wo die Pipeline erstellt wurde, entweder DBSQL oder WORKSPACE. |
timestamp |
Dies ist der Zeitpunkt, zu dem das Ereignis aufgezeichnet wurde. |
message |
Dies ist eine Meldung für Benutzer*innen, die das Ereignis beschreibt. |
level |
Der Ereignistyp, z. B. INFO, WARN, ERROR oder METRICS. |
maturity_level |
Die Stabilität des Ereignisschemas. Mögliche Werte sind:
|
error |
Wenn ein Fehler aufgetreten ist, werden Details zur Beschreibung des Fehlers angezeigt. |
details |
Dies ist ein JSON-Dokument, das strukturierte Details des Ereignisses enthält. Dies ist das primäre Feld, das zum Analysieren von Ereignissen verwendet wird. |
event_type |
Der Ereignistyp. |
Abfragen des Ereignisprotokolls
Hinweis
In diesem Abschnitt werden das Standardverhalten und die Syntax für das Arbeiten mit Ereignisprotokollen für Pipelines beschrieben, die mit Unity Catalog und dem Standardveröffentlichungsmodus konfiguriert sind.
- Verhalten für Unity Catalog-Pipelines, die den Legacy-Veröffentlichungsmodus verwenden, finden Sie unter Arbeiten mit dem Ereignisprotokoll für die Legacy-Publishing-Modus-Pipelines in Unity Catalog.
- Verhalten und Syntax für Hive-Metastore-Pipelines finden Sie unter "Arbeiten mit dem Ereignisprotokoll für Hive-Metastore-Pipelines".
Standardmäßig schreibt Lakeflow Declarative Pipelines das Ereignisprotokoll in eine ausgeblendete Delta-Tabelle, die im Standardkatalog und Schema der Pipeline konfiguriert ist. Die Tabelle kann zwar ausgeblendet werden, aber dennoch von allen ausreichend privilegierten Benutzern abgefragt werden. Standardmäßig kann nur der Besitzer der Pipeline die Ereignisprotokolltabelle abfragen.
Standardmäßig wird der Name für das ausgeblendete Ereignisprotokoll als event_log_{pipeline_id} formatiert, wobei die Pipeline-ID die vom System zugewiesene UUID ist, bei der die Bindestriche durch Unterstriche ersetzt werden.
Sie können mit der JSON-Konfiguration interagieren, um das Ereignisprotokoll zu veröffentlichen. Wenn Sie ein Ereignisprotokoll veröffentlichen, geben Sie den Namen für das Ereignisprotokoll an und können optional einen Katalog und ein Schema angeben, wie im folgenden Beispiel gezeigt:
{
"id": "ec2a0ff4-d2a5-4c8c-bf1d-d9f12f10e749",
"name": "billing_pipeline",
"event_log": {
"catalog": "catalog_name",
"schema": "schema_name",
"name": "event_log_table_name"
}
}
Der Ereignisprotokollspeicherort dient auch als Schemaspeicherort für alle Auto Loader-Abfragen in der Pipeline. Databricks empfiehlt das Erstellen einer Ansicht über die Ereignisprotokolltabelle vor dem Ändern der Berechtigungen, da einige Berechnungseinstellungen Benutzern möglicherweise den Zugriff auf Schemametadaten ermöglichen können, wenn die Ereignisprotokolltabelle direkt freigegeben wird. Die folgende Beispielsyntax erstellt eine Ansicht in einer Ereignisprotokolltabelle und wird in den beispielen Ereignisprotokollabfragen verwendet, die in diesem Artikel enthalten sind.
CREATE VIEW event_log_raw
AS SELECT * FROM catalog_name.schema_name.event_log_table_name;
Jede Instanz einer Pipelineausführung wird als Update bezeichnet. Sie möchten häufig Informationen für das neueste Update extrahieren. Führen Sie die folgende Abfrage aus, um den Bezeichner für das neueste Update zu suchen und in der temporären latest_update-Ansicht zu speichern. Diese Ansicht wird in den Beispielereignisprotokollabfragen in diesem Artikel verwendet:
CREATE OR REPLACE TEMP VIEW latest_update AS SELECT origin.update_id AS id FROM event_log_raw WHERE event_type = 'create_update' ORDER BY timestamp DESC LIMIT 1;
Im Unity-Katalog unterstützen Ansichten Streamingabfragen. Im folgenden Beispiel wird strukturiertes Streaming verwendet, um eine Ansicht abzufragen, die über einer Ereignisprotokolltabelle definiert ist:
df = spark.readStream.table("event_log_raw")
Die besitzende Person der Pipeline kann das Ereignisprotokoll als öffentliche Delta-Tabelle veröffentlichen, indem sie die Option Publish event log to metastore im Abschnitt Erweitert der Pipelinekonfiguration umschaltet. Sie können optional einen neuen Tabellennamen, Katalog und Schema für das Ereignisprotokoll angeben.
Abfragen von Herkunftsinformationen aus dem Ereignisprotokoll
Ereignisse, die Informationen zur Datenherkunft enthalten, weisen den Ereignistyp flow_definition auf. Das details:flow_definition-Objekt enthält das output_dataset und das input_datasets, welche jede Beziehung im Diagramm definieren.
Sie können die folgende Abfrage verwenden, um die Eingabe- und Ausgabedatasets zu extrahieren, um Herkunftsinformationen anzuzeigen:
SELECT
details:flow_definition.output_dataset as output_dataset,
details:flow_definition.input_datasets as input_dataset
FROM
event_log_raw,
latest_update
WHERE
event_type = 'flow_definition'
AND
origin.update_id = latest_update.id
output_dataset |
input_datasets |
|---|---|
customers |
null |
sales_orders_raw |
null |
sales_orders_cleaned |
["customers", "sales_orders_raw"] |
sales_order_in_la |
["sales_orders_cleaned"] |
Abfragen der Datenqualität aus dem Ereignisprotokoll
Wenn Sie die Erwartungen an Datasets in Ihrer Pipeline definieren, werden die Metriken für die Anzahl der übergebenen Datensätze und fehlgeschlagenen Erwartungen im details:flow_progress.data_quality.expectations Objekt gespeichert. Die Metrik für die Anzahl der verworfenen Datensätze wird im details:flow_progress.data_quality Objekt gespeichert. Ereignisse, die Informationen zur Datenqualität enthalten, weisen den Ereignistyp flow_progress auf.
Datenqualitätsmetriken sind für einige Datasets möglicherweise nicht verfügbar. Sehen Sie sich die Erwartungenseinschränkungen an.
Die folgenden Datenqualitätsmetriken sind verfügbar:
| Maßeinheit | BESCHREIBUNG |
|---|---|
dropped_records |
Die Anzahl der Einträge, die abgelehnt wurden, weil sie eine oder mehrere Erwartungen nicht erfüllt haben. |
passed_records |
Die Anzahl der Datensätze, die die Erwartungskriterien bestanden haben. |
failed_records |
Die Anzahl der Datensätze, bei denen die Erwartungskriterien nicht erfüllt wurden. |
Im folgenden Beispiel werden die Datenqualitätsmetriken für das letzte Pipelineupdate abgefragt:
SELECT
row_expectations.dataset as dataset,
row_expectations.name as expectation,
SUM(row_expectations.passed_records) as passing_records,
SUM(row_expectations.failed_records) as failing_records
FROM
(
SELECT
explode(
from_json(
details:flow_progress.data_quality.expectations,
"array<struct<name: string, dataset: string, passed_records: int, failed_records: int>>"
)
) row_expectations
FROM
event_log_raw,
latest_update
WHERE
event_type = 'flow_progress'
AND origin.update_id = latest_update.id
)
GROUP BY
row_expectations.dataset,
row_expectations.name
dataset |
expectation |
passing_records |
failing_records |
|---|---|---|---|
sales_orders_cleaned |
valid_order_number |
4083 | 0 |
Abfragen von Auto Loader-Ereignissen im Ereignisprotokoll
Lakeflow Declarative Pipelines generiert Ereignisse, wenn auto Loader Dateien verarbeitet. Bei Auto Loader-Ereignissen ist der event_typeoperation_progress und der details:operation_progress:type ist entweder AUTO_LOADER_LISTING oder AUTO_LOADER_BACKFILL. Das details:operation_progress Objekt enthält auch status, duration_ms, auto_loader_details:source_path und auto_loader_details:num_files_listed Felder.
Im folgenden Beispiel werden Auto Loader-Ereignisse für das neueste Update abgefragt.
SELECT
timestamp,
details:operation_progress.status,
details:operation_progress.type,
details:operation_progress:auto_loader_details
FROM
event_log_raw,
latest_update
WHERE
event_type like 'operation_progress'
AND
origin.update_id = latest.update_id
AND
details:operation_progress.type in ('AUTO_LOADER_LISTING', 'AUTO_LOADER_BACKFILL')
Überwachen des Datenbacklogs durch Abfragen des Ereignisprotokolls
Lakeflow Declarative Pipelines verfolgt, wie viele Daten im Backlog im details:flow_progress.metrics.backlog_bytes Objekt vorhanden sind. Ereignisse, die Backlogmetriken enthalten, haben den Ereignistyp flow_progress. Im folgenden Beispiel werden die Backlog-Metriken für das letzte Pipelineupdate abgefragt:
SELECT
timestamp,
Double(details :flow_progress.metrics.backlog_bytes) as backlog
FROM
event_log_raw,
latest_update
WHERE
event_type ='flow_progress'
AND
origin.update_id = latest_update.id
Hinweis
Die Backlogmetriken sind je nach Datenquellentyp und Databricks-Runtime-Version der Pipeline möglicherweise nicht verfügbar.
Überwachen erweiterter automatischer Ereignisse aus dem Ereignisprotokoll auf Pipelines ohne serverlose Aktivierung
Bei deklarativen Lakeflow-Pipelines, die keine serverlose Berechnung verwenden, erfasst das Ereignisprotokoll die Änderungen der Clustergröße, wenn die erweiterte automatische Skalierung in Ihren Pipelines aktiviert ist. Ereignisse, die Informationen zur erweiterten automatischen Skalierung enthalten, weisen den Ereignistyp autoscaleauf. Die Größe der Anforderungsinformationen des Clusters wird im details:autoscale-Objekt gespeichert. Im folgenden Beispiel wird die Größe des erweiterten Automatischkalierungsclusters für die letzte Pipelineaktualisierung abfragen:
SELECT
timestamp,
Double(
case
when details :autoscale.status = 'RESIZING' then details :autoscale.requested_num_executors
else null
end
) as starting_num_executors,
Double(
case
when details :autoscale.status = 'SUCCEEDED' then details :autoscale.requested_num_executors
else null
end
) as succeeded_num_executors,
Double(
case
when details :autoscale.status = 'PARTIALLY_SUCCEEDED' then details :autoscale.requested_num_executors
else null
end
) as partially_succeeded_num_executors,
Double(
case
when details :autoscale.status = 'FAILED' then details :autoscale.requested_num_executors
else null
end
) as failed_num_executors
FROM
event_log_raw,
latest_update
WHERE
event_type = 'autoscale'
AND
origin.update_id = latest_update.id
Überwachen der Nutzung der Computeressourcen
cluster_resources-Ereignisse liefern Metriken zur Anzahl der Aufgabenslots im Cluster, zur Auslastung dieser Aufgabenslots und zur Anzahl von Aufgaben, die auf die Planung warten.
Wenn die erweiterte automatische Skalierung aktiviert ist, cluster_resources enthalten Ereignisse auch Metriken für den Automatischen Skalierungsalgorithmus, einschließlich latest_requested_num_executorsund optimal_num_executors. Die Ereignisse zeigen auch den Status des Algorithmus als unterschiedliche Zustände an wie z. B. CLUSTER_AT_DESIRED_SIZE, SCALE_UP_IN_PROGRESS_WAITING_FOR_EXECUTORS und BLOCKED_FROM_SCALING_DOWN_BY_CONFIGURATION.
Diese Informationen können in Verbindung mit den automatischen Skalierungsereignissen angezeigt werden, um ein Gesamtbild der erweiterten automatischen Skalierung bereitzustellen.
Im folgenden Beispiel wird der Größenverlauf der Vorgangswarteschlange für die letzte Pipelineaktualisierung abfragt:
SELECT
timestamp,
Double(details :cluster_resources.avg_num_queued_tasks) as queue_size
FROM
event_log_raw,
latest_update
WHERE
event_type = 'cluster_resources'
AND
origin.update_id = latest_update.id
Im folgenden Beispiel wird der Nutzungsverlauf für die letzte Pipelineaktualisierung abfragt:
SELECT
timestamp,
Double(details :cluster_resources.avg_task_slot_utilization) as utilization
FROM
event_log_raw,
latest_update
WHERE
event_type = 'cluster_resources'
AND
origin.update_id = latest_update.id
Im folgenden Beispiel wird der Verlauf der Executoranzahl abgefragt, begleitet von Metriken, die nur für erweiterte automatische Skalierungspipelinen verfügbar sind, einschließlich der Anzahl der vom Algorithmus in der neuesten Anforderung angeforderten Executoren, die optimale Anzahl der vom Algorithmus basierend auf den neuesten Metriken empfohlenen Ausführungsalgorithmus und den Zustand des automatischen Algorithmus:
SELECT
timestamp,
Double(details :cluster_resources.num_executors) as current_executors,
Double(details :cluster_resources.latest_requested_num_executors) as latest_requested_num_executors,
Double(details :cluster_resources.optimal_num_executors) as optimal_num_executors,
details :cluster_resources.state as autoscaling_state
FROM
event_log_raw,
latest_update
WHERE
event_type = 'cluster_resources'
AND
origin.update_id = latest_update.id
Deklarative Pipelines für Lakeflow überwachen
Sie können Lakeflow Declarative Pipelines-Ereignisprotokolleinträge und andere Azure Databricks-Überwachungsprotokolle verwenden, um ein vollständiges Bild davon zu erhalten, wie Daten in Lakeflow Declarative Pipelines aktualisiert werden.
Lakeflow Declarative Pipelines verwendet die Anmeldeinformationen des Pipelinebesitzers, um Updates auszuführen. Sie können die verwendeten Anmeldeinformationen ändern, indem Sie den Pipelinebesitzer aktualisieren. Lakeflow Declarative Pipelines zeichnet den Benutzer für Aktionen in der Pipeline auf, einschließlich Pipelineerstellung, Bearbeitungen zur Konfiguration und Auslösen von Updates.
Eine Referenz zu Unity Catalog-Überwachungsereignissen finden Sie unter Unity Catalog-Ereignisse.
Abfragen von Benutzeraktionen im Ereignisprotokoll
Sie können das Ereignisprotokoll verwenden, um Ereignisse wie Benutzeraktionen zu überwachen. Ereignisse, die Informationen zu Benutzeraktionen enthalten, haben den Ereignistyp user_action.
Informationen zur Aktion werden im user_action-Objekt im details-Feld gespeichert. Verwenden Sie die folgende Abfrage, um ein Überwachungsprotokoll von Benutzerereignissen zu erstellen. Informationen zum Erstellen der event_log_raw in dieser Abfrage verwendeten Ansicht finden Sie unter Abfragen des Ereignisprotokolls.
SELECT timestamp, details:user_action:action, details:user_action:user_name FROM event_log_raw WHERE event_type = 'user_action'
timestamp |
action |
user_name |
|---|---|---|
| 2021-05-20T19:36:03.517+0000 | START |
user@company.com |
| 2021-05-20T19:35:59.913+0000 | CREATE |
user@company.com |
| 2021-05-27T00:35:51.971+0000 | START |
user@company.com |
Runtimeinformationen
Sie können Laufzeitinformationen für ein Pipelineupdate anzeigen, z. B. die Databricks-Runtime-Version für das Update:
SELECT details:create_update:runtime_version:dbr_version FROM event_log_raw WHERE event_type = 'create_update'
dbr_version |
|---|
| 11,0 |