Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Die Empfehlungen zur manuellen Optimierung in diesem Artikel gelten nicht für verwaltete Tabellen im Unity-Katalog, die die automatische Optimierung der Dateigröße verwenden. Verwenden Sie für neue Tabellen verwaltete Tabellen im Unity-Katalog mit Standardeinstellungen.
In Databricks Runtime 13.3 und höher empfiehlt Databricks die Verwendung von Clustering für das Tabellenlayout. Siehe Verwenden von Flüssigclustering für Tabellen.
Databricks empfiehlt die Verwendung der prädiktiven Optimierung zur automatischen Ausführung OPTIMIZE und VACUUM für Tabellen. Siehe Prädiktive Optimierung für verwaltete Unity Catalog-Tabellen.
In Databricks Runtime 10.4 LTS und höher sind die automatische Komprimierung und optimierte Schreibvorgänge für MERGE-, UPDATE- und DELETE-Vorgänge immer aktiviert. Sie können diese Funktion nicht deaktivieren.
Es gibt Optionen zum manuellen oder automatischen Konfigurieren der Zieldateigröße für Schreibvorgänge und für OPTIMIZE Vorgänge. Azure Databricks stimmt viele dieser Einstellungen automatisch ab und aktiviert Features, die die Tabellenleistung automatisch verbessern, indem sie nach Dateien mit der richtigen Größe suchen.
Bei verwalteten Tabellen im Unity Catalog werden die meisten dieser Konfigurationen von Databricks automatisch optimiert, wenn Sie ein SQL Warehouse oder Databricks Runtime 11.3 LTS oder höher verwenden.
Wenn Sie eine Workload von Databricks Runtime 10.4 LTS oder älter aktualisieren, finden Sie weitere Informationen unter zum Upgrade auf die automatische Komprimierung im Hintergrund.
Wann OPTIMIZE ausgeführt werden soll
Automatische Komprimierung und optimierte Schreibvorgänge reduzieren jeweils kleine Dateiprobleme, sind jedoch kein vollständiger Ersatz für OPTIMIZE. Insbesondere für Tabellen, die größer als 1 TB sind, empfiehlt Databricks die Ausführung von OPTIMIZE nach einem Zeitplan, um Dateien weiter zu konsolidieren. Databricks empfiehlt Liquid Clustering zur verbesserten Datenüberspringung. Wenn das Liquid Clustering aktiviert ist, werden die Daten von OPTIMIZE automatisch anhand der Clusterschlüssel neu organisiert. Siehe Verwenden von Flüssigclustering für Tabellen.
Für verwaltete Tabellen im Unity-Katalog wird die Predictive Optimization automatisch auf Tabellen ausgeführt OPTIMIZE , bei denen die Vorhersageoptimierung aktiviert ist.
Was ist die automatische Auto-Optimierung in Azure Databricks?
Der Begriff automatische Optimierung wird zuweilen verwendet, um Funktionen zu beschreiben, die durch die Einstellungen autoOptimize.autoCompact und autoOptimize.optimizeWrite gesteuert werden. Dieser Begriff ist nicht mehr verwendet, um jede Einstellung individuell zu beschreiben. Weitere Informationen finden Sie unter "Automatische Komprimierung " und "Optimierte Schreibvorgänge".
Automatische Komprimierung
Die automatische Komprimierung kombiniert kleine Dateien in Tabellenpartitionen, um kleine Dateiprobleme zu reduzieren. Sie wird synchron auf dem Cluster ausgeführt, der den Schreibvorgang ausführt, nachdem der Schreibvorgang erfolgreich war, und komprimiert nur Dateien, die noch nicht komprimiert wurden.
Autokomprimierung und Predictive Optimization sind unabhängige Features, die separat oder zusammen verwendet werden können. Die automatische Komprimierung wird auf dem Cluster ausgeführt, der die Schreibvorgänge ausführt, während die Vorhersageoptimierung Wartungsvorgänge asynchron mithilfe der serverlosen Berechnung ausführt.
Verwenden Sie die folgenden Einstellungen, um die automatische Komprimierung zu konfigurieren:
| Setting | Delta | Eisberg | Description |
|---|---|---|---|
| Automatische Komprimierung aktivieren (Tabelleneigenschaft) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
Aktiviert die automatische Komprimierung auf Tabellenebene. |
| Automatische Komprimierung aktivieren (Spark-Sitzung) | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
Aktiviert die automatische Komprimierung auf Sitzungsebene. |
| Maximale Ausgabedateigröße | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
Steuert die Größe der Zielausgabedatei. |
| Minimale Dateien zum Auslösen der Komprimierung | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
Legt die Mindestanzahl kleiner Dateien fest, die in einer Partition oder Tabelle erforderlich sind, um die automatische Komprimierung auszulösen. |
Bei diesen Einstellungen sind die folgenden Optionen möglich:
| Optionen | Verhalten |
|---|---|
auto (empfohlen) |
Stimmt die Zieldateigröße unter Berücksichtigung anderer Autotuning-Funktionen ab. Erfordert Databricks Runtime 10.4 LTS oder höher. |
legacy |
Alias für true. Erfordert Databricks Runtime 10.4 LTS oder höher. |
true |
Verwenden Sie 128 MB als Zieldateigröße. Keine dynamische Größenanpassung. |
false |
Deaktiviert die automatische Komprimierung. Kann auf Sitzungsebene festgelegt werden, um die automatische Komprimierung für alle Tabellen zu überschreiben, die in der Workload geändert wurden. |
Hinweis
Azure Databricks empfiehlt die Verwendung der automatischen Einstellung, um die Größe der Ausgabedatei basierend auf der Tabellengröße zu steuern. Siehe Autotune-Dateigröße basierend auf der Tabellengröße.
Optimierte Schreibvorgänge
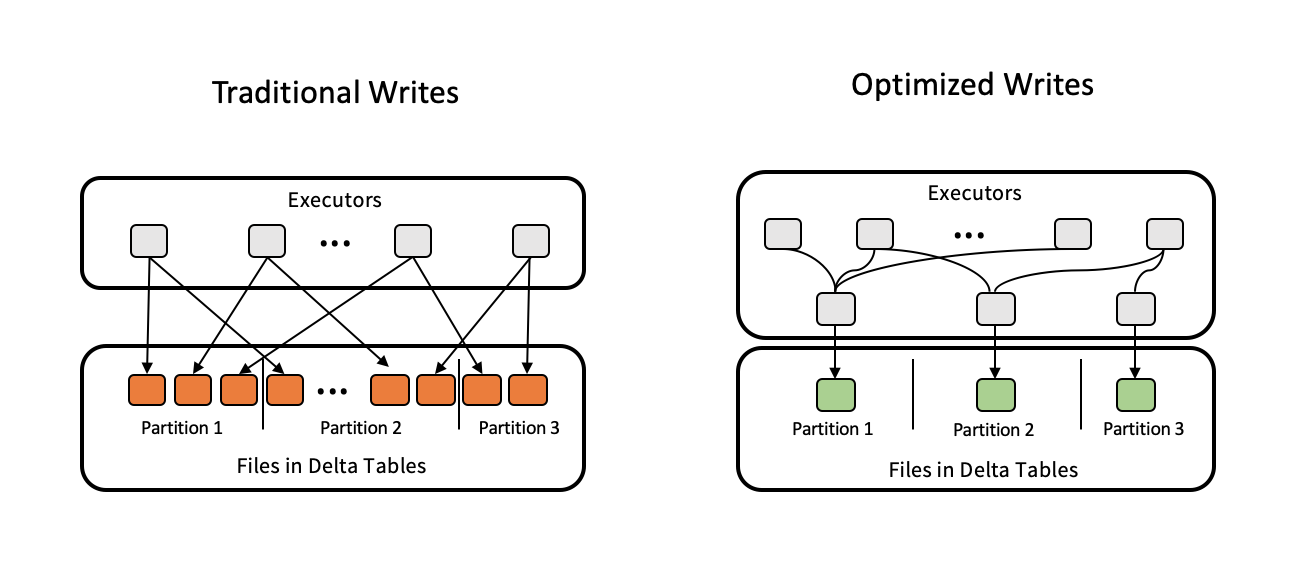
Optimierte Schreibvorgänge optimieren die Dateigröße, während Daten geschrieben werden, und verbessern die Effizienz nachfolgender Lesevorgänge in der Tabelle.
Optimierte Schreibvorgänge sind für partitionierte Tabellen am effektivsten, da sie die Anzahl der kleinen Dateien reduzieren, die in jede Partition geschrieben werden. Das Schreiben weniger großer Dateien ist effizienter als das Schreiben vieler kleiner Dateien; es kann jedoch zu einer Erhöhung der Schreiblatenz kommen, da Daten vor dem Schreiben gemischt werden.
Die folgende Abbildung zeigt, wie optimierte Schreibvorgänge funktionieren:
Hinweis
Möglicherweise verfügen Sie über Code, mit dem coalesce(n) oder repartition(n) ausgeführt werden, kurz bevor Sie Ihre Daten schreiben, um die Anzahl der geschriebenen Dateien zu steuern. Durch optimierte Schreibvorgänge entfällt die Notwendigkeit der Verwendung dieses Musters.
Optimierte Schreibvorgänge sind standardmäßig für die folgenden Vorgänge in Databricks Runtime 9.1 LTS und höher aktiviert:
MERGE-
UPDATEmit Unterabfragen -
DELETEmit Unterabfragen
Optimierte Schreibvorgänge sind auch für alle CTAS-Anweisungen und INSERT-Vorgänge aktiviert, wenn SQL-Warehouses verwendet werden. In Databricks Runtime ab Version 13.3 LTS haben alle Tabellen, die im Unity-Katalog registriert sind, optimierte Schreibvorgänge für CTAS-Anweisungen und INSERT-Vorgänge für partitionierte Tabellen aktiviert.
Optimierte Schreibvorgänge können auf Tabellen- oder Sitzungsebene mit den folgenden Einstellungen aktiviert werden:
- Tabelleneigenschaft:
autoOptimize.optimizeWrite - SparkSession-Einstellung:
spark.databricks.delta.optimizeWrite.enabled(Delta) oderspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
Bei diesen Einstellungen sind die folgenden Optionen möglich:
| Optionen | Verhalten |
|---|---|
true |
Verwenden Sie 128 MB als Zieldateigröße. |
false |
Deaktiviert optimierte Schreibvorgänge. Kann auf Sitzungsebene festgelegt werden, um die automatische Komprimierung für alle Tabellen zu überschreiben, die in der Workload geändert wurden. |
Festlegen der Größe der Zieldatei
Wenn Sie die Größe von Dateien in der Tabelle optimieren möchten, legen Sie die TabelleneigenschafttargetFileSize auf die gewünschte Größe fest. Wenn gesetzt, versuchen alle Datenlayout-Optimierungsvorgänge mit bestem Bemühen, Dateien der angegebenen Größe zu erzeugen, darunter Optimierung, Liquid Clustering, Automatisierte Verdichtung und optimierte Schreibvorgänge.
Hinweis
Wenn Sie verwaltete Unity Catalog-Tabellen und SQL-Warehouses oder Databricks Runtime 11.3 LTS und höher verwenden, berücksichtigen nur OPTIMIZE-Befehle die Einstellung targetFileSize.
| Eigentum | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (Eisberg) |
Typ: Größe in Bytes oder höheren Einheiten. Beschreibung: Die Zieldateigröße. Beispiel: 104857600 (Byte) oder 100mb.Standardwert: keiner |
Bei vorhandenen Tabellen können Sie eigenschaften mithilfe des SQL-Befehls ALTER TABLESET TBL PROPERTIESfestlegen und aufheben. Sie können diese Eigenschaften auch automatisch festlegen, wenn Sie neue Tabellen mit Spark-Sitzungskonfigurationen erstellen. Ausführliche Informationen finden Sie in der Referenz zu den Tabelleneigenschaften.
Automatisches Abstimmen der Dateigröße basierend auf der Tabellengröße
Um den Bedarf an manueller Optimierung zu minimieren, passt Azure Databricks die Dateigröße von Tabellen basierend auf der Größe der Tabelle automatisch ab. Azure Databricks verwendet kleinere Dateigrößen für kleinere Tabellen und größere Dateigrößen für größere Tabellen, sodass die Anzahl der Dateien in der Tabelle nicht zu groß wird. Azure Databricks führt kein automatisches Abstimmen von Tabellen durch, die Sie auf eine bestimmte Zielgröße abgestimmt haben.
Die Zieldateigröße basiert auf der aktuellen Größe der Tabelle. Für Tabellen, die kleiner sind als 2,56 TB, beträgt die automatisch optimierte Größe der Zieldatei 256 MB. Bei Tabellen mit einer Größe zwischen 2,56 TB und 10 TB steigt die Zielgröße linear von 256 MB auf 1 GB. Für Tabellen, die größer sind als 10 TB, beträgt die Zieldateigröße 1 GB.
Hinweis
Wenn die Zieldateigröße für eine Tabelle ansteigt, werden vorhandene Dateien mit dem Befehl OPTIMIZE nicht erneut optimiert und in größere Dateien umgewandelt. Eine große Tabelle kann daher immer einige Dateien enthalten, die kleiner sind als die Zielgröße. Wenn es erforderlich ist, auch diese kleineren Dateien in größere Dateien zu optimieren, können Sie mit der Tabelleneigenschaft targetFileSize eine feste Zieldateigröße für die Tabelle konfigurieren.
Wenn eine Tabelle inkrementell geschrieben wird, ergeben sich abhängig von der Tabellengröße in etwa folgende Zieldateigrößen und Dateianzahlen. Die Dateianzahl in dieser Tabelle ist nur ein Beispiel. Die tatsächlichen Ergebnisse hängen von zahlreichen Faktoren ab.
| Tabellengröße | Größe der Zieldatei | Ungefähre Anzahl von Dateien in der Tabelle |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10.240 |
| 3 Terabyte | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Einschränken der Zeilen, die in einer Datendatei geschrieben werden
Bei Tabellen mit begrenztem Datenvolumen tritt möglicherweise ein Fehler auf, wenn die Anzahl der Zeilen in einer bestimmten Datendatei die Supportlimits des Parquet-Formats überschreitet. Um diesen Fehler zu vermeiden, können Sie die SQL-Sitzungskonfiguration spark.sql.files.maxRecordsPerFile verwenden, um die maximale Anzahl von Datensätzen anzugeben, die in eine einzelne Datei für eine Tabelle geschrieben werden sollen. Wenn Sie null oder einen negativen Wert angeben, gilt kein Grenzwert.
In Databricks Runtime 11.3 LTS und höher können Sie auch die DataFrameWriter-Option maxRecordsPerFile verwenden, wenn Sie die DataFrame-APIs zum Schreiben in eine Tabelle verwenden. Bei Angabe von maxRecordsPerFile wird der Wert der SQL-Sitzungskonfiguration spark.sql.files.maxRecordsPerFile ignoriert.
Hinweis
Databricks empfiehlt die Verwendung dieser Option nicht, es sei denn, dies ist erforderlich, um den oben genannten Fehler zu vermeiden. Diese Einstellung kann für einige verwaltete Unity Catalog-Tabellen mit sehr begrenztem Datenvolumen weiterhin erforderlich sein.
Upgrade auf automatische Komprimierung im Hintergrund
Die automatische Komprimierung im Hintergrund ist für verwaltete Unity Catalog-Tabellen in Databricks Runtime 11.3 LTS und höher verfügbar. Für die automatische Hintergrundkomprimierung ist keine prädiktive Optimierung erforderlich. Gehen Sie bei der Migration einer Legacy-Workload oder Tabelle wie folgt vor:
- Entfernen Sie die Spark-Konfiguration
spark.databricks.delta.autoCompact.enabled(Delta) oderspark.databricks.iceberg.autoCompact.enabled(Iceberg) aus den Konfigurationseinstellungen für Cluster oder Notizbücher. - Führen Sie
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)für jede Tabelle (Delta) oderALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) aus, um alle älteren Einstellungen für die automatische Komprimierung zu entfernen.
Nach dem Entfernen dieser Legacykonfigurationen sollte die automatische Komprimierung im Hintergrund automatisch für alle verwalteten Unity Catalog-Tabellen ausgelöst werden.