Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Deklarative Automatisierungspakete (früher als Databricks Asset Bundles bezeichnet) sind ein Tool zur Erleichterung der Einführung bewährter Methoden für Software engineering, einschließlich Quellcodeverwaltung, Codeüberprüfung, Tests und fortlaufender Integration und Bereitstellung (CI/CD) für Ihre Daten und KI-Projekte. Bundles bieten eine Möglichkeit, Metadaten zusammen mit den Quelldateien Ihres Projekts einzuschließen und datenbricks-Ressourcen wie Aufträge und Pipelines als Quelldateien zu beschreiben. Letztendlich handelt es sich bei einem Bündel um eine End-to-End-Definition eines Projekts, einschließlich der Struktur, Test und Bereitstellung des Projekts. Dies erleichtert die Zusammenarbeit an Projekten während der aktiven Entwicklung.
Die Sammlung von Quelldateien und Metadaten ihres Bündelprojekts wird als einzelnes Bündel für Ihre Zielumgebung bereitgestellt. Ein Paket enthält die folgenden Bestandteile:
- Erforderliche Konfigurationen von Cloud-Infrastruktur und Arbeitsbereichen
- Quelldateien, z. B. Notebooks und Python-Dateien, welche die Geschäftslogik enthalten
- Definitionen und Einstellungen für Databricks-Ressourcen, z. B. Lakeflow-Aufträge, Lakeflow-Pipelines, Dashboards, Model Serving-Endpunkte, MLflow-Experimente und registrierte MLflow-Modelle
- Einheiten- und Integrationstests
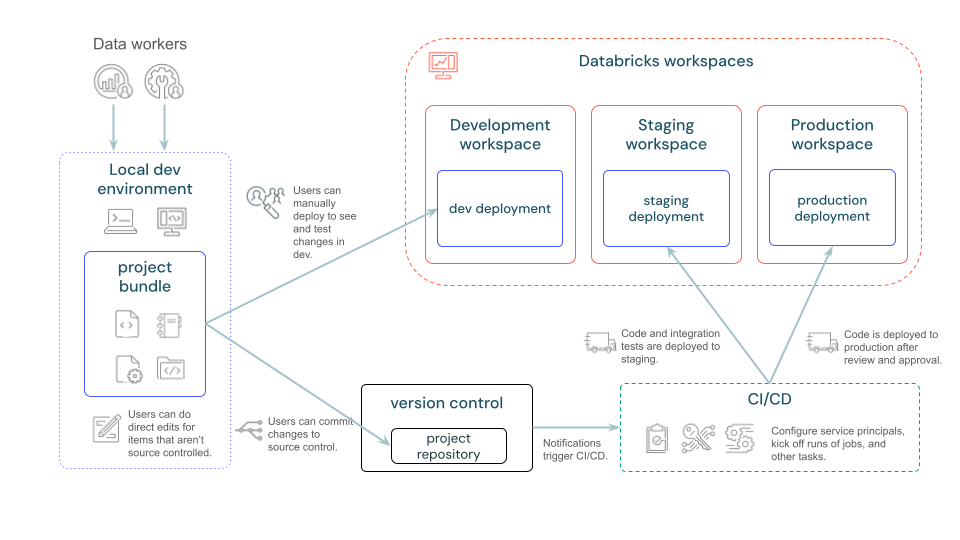
Das folgende Diagramm bietet eine allgemeine Übersicht über eine Entwicklungs- und CI/CD-Pipeline mit Bundles:
Videoanleitung
In diesem Video wird gezeigt, wie Sie mit deklarativen Automatisierungspaketen (5 Minuten) arbeiten.
Wann sollte ich Bundles verwenden?
Deklarative Automatisierungspakete sind ein Infrastruktur-as-Code -Ansatz (IaC) zum Verwalten Ihrer Databricks-Projekte. Verwenden Sie sie, wenn Sie komplexe Projekte verwalten möchten, bei denen mehrere Mitwirkende und Automatisierung unerlässlich sind, und eine kontinuierliche Integration und Bereitstellung (CI/CD) eine Voraussetzung sind. Da Bündel über YAML-Vorlagen und -Dateien definiert und verwaltet werden, die Sie zusammen mit dem Quellcode erstellen und pflegen, passen sie gut zu Szenarien, in denen IaC der passende Ansatz ist.
Zu den idealen Szenarien für den Einsatz von Bundles gehören:
- Entwickeln Sie Daten-, Analyse- und ML-Projekte im Team. Pakete können Ihnen dabei helfen, verschiedene Quelldateien effizient zu organisieren und zu verwalten. Dadurch werden eine reibungslose Zusammenarbeit und optimierte Prozesse sichergestellt.
- Arbeiten Sie schneller an Lösungen für ML-Probleme. Verwalten Sie Ressourcen der ML-Pipeline (z. B. Trainings- und Batch-Rückschluss-Aufträge), indem Sie ML-Projekte verwenden, die von Anfang an nach bewährten Methoden arbeiten.
- Legen Sie Organisationsstandards für neue Projekte fest, indem Sie benutzerdefinierte Bundlevorlagen erstellen, die Standardberechtigungen, Dienstprinzipale und CI/CD-Konfigurationen enthalten.
- Einhaltung gesetzlicher Vorschriften: In Branchen, in denen die Einhaltung gesetzlicher Vorschriften ein erhebliches Problem darstellt, können Bundles dazu beitragen, einen versionsierten Verlauf von Code und Infrastrukturarbeit aufrechtzuerhalten. Dies unterstützt die Governance und stellt sicher, dass die erforderlichen Compliancestandards erfüllt sind.
Wie funktionieren Bündel?
Bündelmetadaten werden mithilfe von YAML-Dateien definiert, welche die Artefakte, Ressourcen und Konfiguration eines Databricks-Projekts angeben. Die Databricks CLI kann dann zum Überprüfen, Bereitstellen und Ausführen von Bündeln mithilfe dieser YAML-Bündeldateien verwendet werden. Sie können Bündelprojekte direkt in IDEs, Terminals oder innerhalb von Databricks ausführen.
Bündel können manuell oder basierend auf einer Vorlage erstellt werden. Die Databricks CLI stellt Standardvorlagen für einfache Anwendungsfälle bereit, aber für spezifischere oder komplexere Aufträge können Sie benutzerdefinierte Bündelvorlagen erstellen, um die bewährten Methoden Ihres Teams zu implementieren und allgemeine Konfigurationen konsistent zu halten.
Weitere Informationen zur Konfiguration von YAML, die zum Ausdrücken von deklarativen Automatisierungspaketen verwendet wird, finden Sie unter Deklarative Automation Bundles-Konfiguration.
Was muss ich installieren, um Bundles zu verwenden?
Deklarative Automatisierungspakete sind ein Feature der Databricks CLI. Sie erstellen Bündel lokal, und verwenden Sie dann die Databricks CLI, um Ihre Bündel für Remote-Databricks-Arbeitsbereiche bereitzustellen und Bündelworkflows in diesen Arbeitsbereichen über die Befehlszeile auszuführen.
Hinweis
Wenn Sie nur Bündel im Arbeitsbereich verwenden möchten, müssen Sie die Databricks CLI nicht installieren. Siehe Zusammenarbeiten an Bundles im Arbeitsbereich.
Zum Erstellen, Bereitstellen und Ausführen von Bundles in Ihren Azure Databricks-Arbeitsbereichen:
Für den Databricks-Remotearbeitsbereich müssen Arbeitsbereichsdateien aktiviert sein. Wenn Sie Databricks Runtime Version 11.3 LTS oder höher verwenden, ist dieses Feature standardmäßig aktiviert.
Sie müssen die Databricks CLI, Version v0.218.0 oder höher, installieren. Informationen zum Installieren oder Aktualisieren der Databricks CLI finden Sie unter Installieren oder Aktualisieren der Databricks CLI.
Databricks empfiehlt, regelmäßig auf die neueste Version der CLI zu aktualisieren, um neue Bundlefeatures nutzen zu können. Um die installierte Version von Databricks CLI zu ermitteln, führen Sie folgenden Befehl aus:
databricks --versionSie haben die Databricks CLI für den Zugriff auf Ihre Databricks-Arbeitsbereiche konfiguriert. Databricks empfiehlt, den Zugriff mithilfe der OAuth-Benutzer-zu-Computer-Authentifizierung (U2M) zu konfigurieren, die unter "Konfigurieren des Zugriffs auf Ihren Arbeitsbereich" beschrieben wird. Weitere Authentifizierungsmethoden werden in der Authentifizierung für deklarative Automatisierungsbündel beschrieben.
Wie beginne ich mit Bundles?
Die schnellste Methode zum Starten der lokalen Bündelentwicklung ist die Verwendung einer Bündelprojektvorlage. Erstellen Sie Ihr erstes Bündelprojekt mit dem Databricks CLI-Befehl bundle init. Dieser Befehl bietet eine Auswahl an von Databricks zur Verfügung gestellten Standardpaketvorlagen. Zudem werden einige Fragen zum Initialisieren von Projektvariablen gestellt.
databricks bundle init
Das Erstellen Ihres Bündels ist der erste Schritt im Lebenszyklus eines Bündels. Entwickeln Sie als Nächstes Ihr Paket, indem Sie Paketeinstellungen und Ressourcen in der Datei databricks.yml und in den Konfigurationsdateien der Ressourcen definieren. Zuletzt führen Sie die Überprüfung und Bereitstellung Ihres Pakets durch und führen dann Ihre Workflows aus.
Tipp
Bundle-Konfigurationsbeispiele finden Sie in Bundle-Konfigurationsbeispielen und im Bundle-Beispiel-Repository in GitHub.
Nächste Schritte
- Erstellen Sie ein Bündel, das ein Notizbuch in einem Azure Databricks-Arbeitsbereich bereitstellt, und führt dann das bereitgestellte Notizbuch in einem Azure Databricks-Auftrag oder einer Pipeline aus. Siehe Entwickeln eines Auftrags mit deklarativen Automatisierungspaketen und Entwickeln von Pipelines mit deklarativen Automatisierungspaketen.
- Erstellen Sie ein Bundle, das einen MLOps-Stack bereitstellt und ausführt. Siehe Deklarative Automatisierungslösungen für MLOps-Stacks.
- Initieren Sie eine Bundle-Bereitstellung als Teil eines CI/CD-Workflows (Continuous Integration/Continuous Deployment) in GitHub. Siehe Ausführen eines CI/CD-Workflows mit einem Bundle, das ein Pipelineupdate ausführt.
- Erstellen Sie ein Bundle, das eine Python-Wheel-Datei erstellt, bereitstellt und ausführt. Siehe Erstellen einer Python-Raddatei mit deklarativen Automatisierungspaketen.
- Generieren Sie eine Konfiguration in Ihrem Bundle für einen Auftrag oder eine andere Ressource in Ihrem Workspace, und binden Sie sie dann an die Ressource im Workspace, damit die Konfiguration synchronisiert bleibt. Siehe databricks bundle generate und databricks bundle deployment bind.
- Erstellen Sie ein Bündel und stellen Sie es im Arbeitsbereich bereit. Siehe Zusammenarbeiten an Bundles im Arbeitsbereich.
- Erstellen Sie eine benutzerdefinierte Vorlage, die Sie und andere zum Erstellen eines Pakets verwenden können. Eine benutzerdefinierte Vorlage kann Standardberechtigungen, Dienstprinzipale und eine benutzerdefinierte CI/CD-Konfiguration enthalten. Siehe Projektvorlagen für deklarative Automatisierungspakete.
- Migrieren Sie von dbx zu deklarativen Automatisierungspaketen. Siehe Migrieren von dbx zu Bundles.
- Entdecken Sie die neuesten neuen Features, die für deklarative Automatisierungspakete veröffentlicht wurden. Siehe Versionshinweise zur Funktion "Deklarative Automatisierungspakete".