Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Databricks Workflows orchestriert Datenverarbeitungs-, Machine Learning- und Analysepipelines auf der Databricks Data Intelligence-Plattform. Workflows verfügt über vollständig verwaltete Orchestrierungsdienste, die in die Databricks-Plattform integriert sind, einschließlich Azure Databricks-Aufträgen zum Ausführen von nicht interaktivem Code in Ihrem Azure Databricks-Arbeitsbereich und Delta Live Tables zum Erstellen zuverlässiger und verwaltbarer ETL-Pipelines.
Weitere Informationen zu den Vorteilen der Orchestrierung Ihrer Workflows mit der Databricks-Plattform finden Sie unter Databricks Workflows.
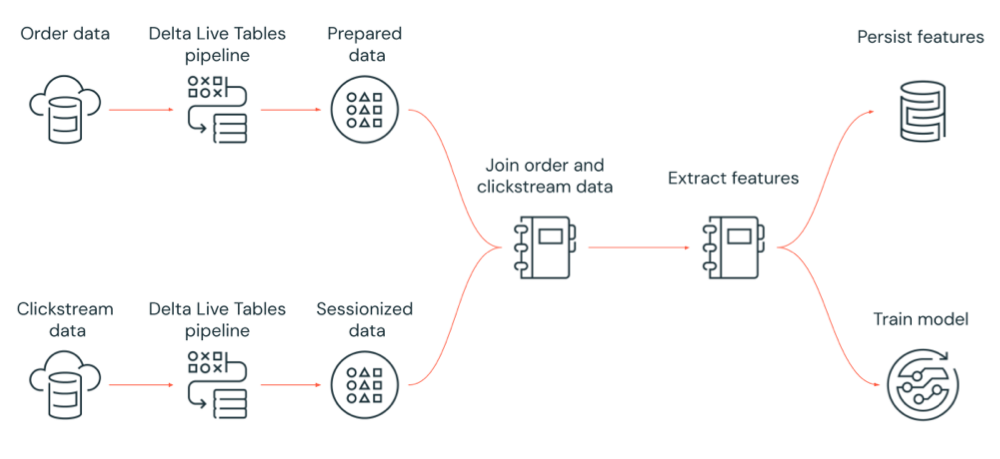
Ein Beispiel für einen Azure Databricks-Workflow
Das folgende Diagramm veranschaulicht einen Workflow, der von einem Azure Databricks-Auftrag orchestriert wird:
- Führen Sie eine Delta Live Tables-Pipeline aus, die unformatierte Clickstreamdaten aus dem Cloudspeicher erfasst, die Daten bereinigt und vorbereitet, die Daten sessionisiert und das endgültige sitzungsbasierte Dataset in Delta Lake speichert.
- Führen Sie eine Delta Live Tables-Pipeline aus, die Auftragsdaten aus dem Cloudspeicher erfasst, die Daten für die Verarbeitung bereinigt und transformiert und das endgültige Dataset in Delta Lake speichert.
- Verknüpfen Sie die Reihenfolge und sitzungsbasierte Clickstreamdaten, um ein neues Dataset für die Analyse zu erstellen.
- Extrahieren Sie Features aus den vorbereiteten Daten.
- Führen Sie Aufgaben parallel aus, um die Features dauerhaft zu speichern und ein Machine Learning-Modell zu trainieren.
Was sind Azure Databricks-Aufträge?
Ein Azure Databricks-Auftrag ist eine Möglichkeit, Ihre Datenverarbeitungs- und Analyseanwendungen in einem Azure Databricks-Arbeitsbereich auszuführen. Ihr Auftrag kann aus einer einzelnen Aufgabe bestehen oder eine große Anwendung mit mehreren Aufgaben-Workflows und komplexen Abhängigkeiten sein. Azure Databricks verwaltet die Aufgabenorchestrierung, Clusterverwaltung, Überwachung und Fehlerberichterstattung für alle Ihre Aufträge. Sie können Ihre Aufträge sofort ausführen, in regelmäßigen Abständen über ein benutzerfreundliches Planungssystem, wann immer neue Dateien an einem externen Speicherort eintreffen, oder kontinuierlich, um sicherzustellen, dass eine Instanz des Auftrags immer ausgeführt wird. Sie können Aufträge auch interaktiv in der Notebook-Benutzeroberfläche ausführen.
Sie können einen Auftrag über die Benutzeroberfläche, die CLI oder durch Aufrufen der Auftrags-API erstellen und ausführen. Sie können einen fehlerhaften oder abgebrochenen Auftrag mithilfe der Benutzeroberfläche oder API reparieren und erneut ausführen. Sie können die Ergebnisse der Auftragsausführung mithilfe der Benutzeroberfläche, der CLI, der API und von Benachrichtigungen (z. B. E-Mail-, Webhookziel- oder Slack-Benachrichtigungen) überwachen.
Informationen zum Verwenden der Databricks CLI finden Sie unter Was ist die Databricks-CLI?. Informationen zur Verwendung der Auftrags-API finden Sie unter Auftrags-API.
In den folgenden Abschnitten werden wichtige Features von Azure Databricks-Aufträgen behandelt.
Wichtig
- Ein Arbeitsbereich ist auf 1000 gleichzeitige Auftragsausführungen beschränkt. Wenn Sie eine Ausführung anfordern, die nicht sofort gestartet werden kann, wird eine
429 Too Many Requests-Antwort zurückgegeben. - Die Anzahl von Aufträgen, die von einem Arbeitsbereich innerhalb einer Stunde erstellt werden können, ist auf 10000 beschränkt (einschließlich „runs submit“). Diese Beschränkung wirkt sich auch auf Aufträge aus, die mit den REST-API- und Notebook-Workflows erstellt wurden.
Implementieren von Datenverarbeitung und -analyse mit Auftragsaufgaben
Sie implementieren Ihren Datenverarbeitungs- und Analyseworkflow mithilfe von Aufgaben. Ein Auftrag besteht aus einer oder mehreren Aufgaben. Sie können Auftragsaufgaben erstellen, die Notebooks, JARS, Delta Live Tables-Pipelines oder Python-, Scala- und Spark-Übertragungen sowie Java-Anwendungen ausführen. Ihre Auftragsaufgaben können auch Databricks SQL-Abfragen, Warnungen und Dashboards orchestrieren, um Analysen und Visualisierungen zu erstellen. Alternativ können Sie den dbt-Task verwenden, um dbt-Transformationen in Ihrem Workflow auszuführen. Ältere spark-submit-Anwendungen werden ebenfalls unterstützt.
Sie können auch einen Task zu einem Auftrag hinzufügen, die einen anderen Auftrag ausführt. Mit dieser Funktion können Sie einen großen Prozess in mehrere kleinere Aufträge aufteilen oder generalisierte Module erstellen, die von mehreren Aufträgen wiederverwendet werden können.
Sie steuern die Ausführungsreihenfolge der Aufgaben, indem Sie Abhängigkeiten zwischen den Aufgaben angeben. Sie können Aufgaben so konfigurieren, dass sie nacheinander oder parallel ausgeführt werden.
Ausführen von Aufträgen interaktiv, kontinuierlich oder mithilfe von Auftragstriggern
Sie können Ihre Aufträge interaktiv über die Auftrags-Benutzeroberfläche, API oder CLI ausführen oder einen fortlaufenden Auftrag ausführen. Sie können einen Zeitplan für die regelmäßige Ausführung Ihres Auftrags erstellen oder Ihren Auftrag ausführen, wenn neue Dateien an einem externen Speicherort wie Amazon S3, Azure Storage oder Google-Cloudspeicher eintreffen.
Überwachen des Auftragsfortschritts mit Benachrichtigungen
Sie können Benachrichtigungen erhalten, wenn ein Auftrag oder eine Aufgabe gestartet oder abgeschlossen wird oder ein Fehler auftritt. Sie können Benachrichtigungen an eine oder mehrere E-Mail-Adressen oder an Systemziele wie Webhookziele oder Slack senden. Weitere Informationen finden Sie unter Hinzufügen von E-Mail- und Systembenachrichtigungen für Auftragsereignisse.
Überwachen von Auftragskosten und -aktivitäten mit Systemtabellen
Systemtabellen enthalten ein workflow Schema, in dem Sie Datensätze im Zusammenhang mit der Auftragsaktivität in Ihrem Konto anzeigen können. Weitere Informationen finden Sie unter Auftragssystemtabellenreferenz.
Sie können die Auftragssystemtabellen auch mit Abrechnungstabellen verknüpfen, um die Kosten von Aufträgen über Ihr Konto hinweg zu überwachen. Weitere Informationen finden Sie unter Überwachen der Kosten von Aufträgen mit Systemtabellen.
Ausführen Ihrer Aufträge mit Azure Databricks-Computeressourcen
Databricks-Cluster und SQL-Warehouses stellen die Berechnungsressourcen für Ihre Aufträge bereit. Sie können Ihre Aufträge mit einem Auftragscluster, einem Allzweckcluster oder einem SQL-Warehouse ausführen:
- Ein Auftragscluster ist ein dedizierter Cluster für Ihren Auftrag oder einzelne Auftragsaufgaben. Ihr Auftrag kann einen Auftragscluster verwenden, der von allen Aufgaben freigegeben wird, oder Sie können einen Cluster für einzelne Aufgaben konfigurieren, wenn Sie eine Aufgabe erstellen oder bearbeiten. Ein Auftragscluster wird erstellt, wenn der Auftrag oder die Aufgabe gestartet und beendet wird, wenn der Auftrag oder die Aufgabe endet.
- Ein Allzweckcluster ist ein freigegebener Cluster, der manuell gestartet und beendet wird und für mehrere Benutzer und Aufträge freigegeben werden kann.
Um die Ressourcennutzung zu optimieren, empfiehlt Databricks die Verwendung eines Auftragsclusters für Ihre Aufträge. Zur Reduzierung der Wartezeit auf den Clusterstart sollten Sie einen Allzweckcluster verwenden. Weitere Informationen finden Sie unter Verwenden von Azure Databricks-Compute mit Ihren Aufträgen.
Sie verwenden ein SQL Warehouse, um Databricks SQL-Aufgaben wie Abfragen, Dashboards oder Warnungen auszuführen. Sie können auch ein SQL-Warehouse verwenden, um dbt-Transformationen mit der dbt-Aufgabe auszuführen.
Nächste Schritte
Erste Schritte mit Azure Databricks-Aufträgen:
Erstellen Sie Ihren ersten Azure Databricks-Auftrag mit dem Schnellstart.
Erfahren Sie, wie Sie Workflows mit der Benutzeroberfläche von Azure Databricks-Aufträgen erstellen und ausführen.
Erfahren Sie, wie Sie mit serverlosen Workflows einen Auftrag ausführen, ohne Azure Databricks-Computeressourcen zu konfigurieren.
Erfahren Sie mehr über die Ausführung von Überwachungsaufträgen auf der Benutzeroberfläche von Azure Databricks-Aufträgen.
Erfahren Sie mehr über Konfigurationsoptionen für Aufträge.
Erfahren Sie mehr über das Erstellen und Verwalten sowie die Problembehandlung von Workflows mit Azure Databricks-Aufträgen:
- Erfahren Sie, wie Sie Informationen zwischen Aufgaben in einem Azure Databricks-Auftrag mithilfe von Aufgabenwerten weiterleiten.
- Erfahren Sie, wie Sie Kontext zu Auftragsausführungen an Auftragsaufgaben mit Aufgabenparametervariablen übergeben.
- Erfahren Sie, wie Sie Ihre Auftragstasks basierend auf den Status der Abhängigkeiten des Tasks für die bedingte Ausführung konfigurieren.
- Erfahren Sie, wie Sie Probleme mit fehlerhaften Aufträgen beheben.
- Lassen Sie sich mit Auftragsausführungsbenachrichtigungen benachrichtigen, wenn Ihr Auftrag gestartet oder abgeschlossen wurde oder fehlschlägt.
- Lösen Sie Ihre Aufträge nach einem benutzerdefinierten Zeitplan aus, oder führen Sie einen fortlaufenden Auftrag aus.
- Erfahren Sie, wie Sie Ihren Azure Databricks-Auftrag ausführen, wenn neue Daten mit Triggern für Dateiankunft eintreffen.
- Erfahren Sie, wie Sie Databricks-Computeressourcen verwenden, um Ihre Aufträge auszuführen.
- Erfahren Sie mehr über Auftrags-API-Updates, um das Erstellen und Verwalten von Workflows mit Azure Databricks-Aufträgen zu unterstützen.
- Verwenden Sie Anleitungen und Tutorials, um mehr über die Implementierung von Datenworkflows mit Azure Databricks-Aufträgen zu erfahren.
Was ist Delta Live Tables?
Hinweis
Delta Live Tables erfordert den Premium-Plan. Kontaktieren Sie Ihr Databricks-Kontoteam für weitere Informationen.
Delta Live Tables ist ein Framework, das die ETL- und Streamingdatenverarbeitung vereinfacht. Delta Live Tables bietet eine effiziente Erfassung von Daten mit integrierter Unterstützung für Autoloader-, SQL- und Python-Schnittstellen, die die deklarative Implementierung von Datentransformationen und das Schreiben transformierter Daten in Delta Lake unterstützen. Sie müssen lediglich die gewünschten Transformationen für Ihre Daten definieren. Delta Live Tables kümmert sich um Aufgabenorchestrierung, Clusterverwaltung, Überwachung, Datenqualität und Fehlerbehandlung.
Informationen zu den ersten Schritten finden Sie unter Was ist Delta Live Tables?.
Azure Databricks-Aufträge und Delta Live Tables
Azure Databricks-Aufträge und Delta Live Tables bieten ein umfassendes Framework zum Erstellen und Bereitstellen von End-to-End-Datenverarbeitungs- und Analyseworkflows.
Verwenden Sie Delta Live Tables für die gesamte Erfassung und Transformation von Daten. Verwenden Sie Azure Databricks-Aufträge, um Workloads zu orchestrieren, die aus einer einzelnen Aufgabe oder mehreren Datenverarbeitungs- und Analyseaufgaben auf der Databricks-Plattform bestehen, einschließlich der Erfassung und Transformation von Delta Live Tables.
Als Workfloworchestrierungssystem unterstützen Azure Databricks-Aufträge auch Folgendes:
- Ausführen von Aufträgen auf einer ausgelösten Basis, z. B. Ausführen eines Workflows nach einem Zeitplan.
- Datenanalyse durch SQL-Abfragen, Maschinelles Lernen und Datenanalyse mit Notebooks, Skripts, externen Bibliotheken usw.
- Ausführen eines Auftrags, der aus einer einzelnen Aufgabe besteht, z. B. Ausführen eines Apache Spark-Auftrags, der in einer JAR-Datei gepackt ist.
Workfloworchestrierung mit Apache AirFlow
Databricks empfiehlt zwar die Verwendung von Azure Databricks-Aufträgen, um Ihre Datenworkflows zu orchestrieren, sie können aber auch Apache Airflow verwenden, um Ihre Datenworkflows zu verwalten und zu planen. Mit Airflow definieren Sie Ihren Workflow in einer Python-Datei, und Airflow verwaltet die Planung und Ausführung des Workflows. Weitere Informationen finden Sie unter Orchestrieren von Azure Databricks-Aufträgen mit Apache Airflow.
Workfloworchestrierung mit Azure Data Factory
Azure Data Factory (ADF) ist ein cloudbasierter Datenintegrationsdienst, mit dem Sie Dienste für die Speicherung, Verschiebung und Verarbeitung von Daten in automatisierten Datenpipelines kombinieren können. Sie können ADF verwenden, um einen Azure Databricks-Auftrag als Teil einer ADF-Pipeline zu orchestrieren.
Informationen zum Ausführen eines Auftrags mithilfe der ADF-Webaktivität, einschließlich der Authentifizierung bei Azure Databricks aus ADF, finden Sie unter Verwenden der Azure Databricks-Auftragsorchestrierung in Azure Data Factory.
ADF bietet außerdem integrierte Unterstützung für das Ausführen von Databricks-Notebooks, Python-Skripts oder Code, der in JAR-Dateien gepackt ist, in einer ADF-Pipeline.
Weitere Informationen zum Ausführen eines Databricks-Notebooks in einer ADF-Pipeline finden Sie unter Ausführen eines Databricks-Notebooks mit der Databricks-Notebookaktivität in Azure Data Factory sowie unter Transformieren von Daten durch Ausführen eines Databricks-Notebooks.
Weitere Informationen zum Ausführen eines Python-Skripts in einer ADF-Pipeline finden Sie unter Transformieren von Daten durch Ausführen einer Python-Aktivität in Azure Databricks.
Weitere Informationen zum Ausführen von Code, der in eine JAR-Datei gepackt ist, in einer ADF-Pipeline finden Sie unter Transformieren von Daten durch Ausführen einer JAR-Aktivität in Azure Databricks.