Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
CI/CD (Continuous Integration and Continuous Delivery) ist ein Eckpfeiler moderner Datentechnik und Analysen, da sichergestellt wird, dass Codeänderungen schnell und zuverlässig integriert, getestet und bereitgestellt werden. Databricks erkennt, dass Sie möglicherweise vielfältige CI/CD-Anforderungen haben, die von Ihren Organisationseinstellungen, vorhandenen Workflows und spezifischen Technologieumgebungen geprägt sind, und bietet ein flexibles Framework, das verschiedene CI/CD-Optionen unterstützt.
Auf dieser Seite werden bewährte Methoden beschrieben, mit denen Sie robuste, angepasste CI/CD-Pipelines entwerfen und erstellen können, die ihren individuellen Anforderungen und Einschränkungen entsprechen. Durch die Nutzung dieser Erkenntnisse können Sie Ihre Data Engineering- und Analyseinitiativen beschleunigen, die Codequalität verbessern und das Risiko von Bereitstellungsfehlern verringern.
Kernprinzipien von CI/CD
Effektive CI/CD-Pipelines teilen grundlegende Grundsätze unabhängig von ihren implementierungsspezifischen Details. Die folgenden universellen bewährten Methoden gelten für organisatorische Einstellungen, Entwicklerworkflows und Cloudumgebungen und sorgen für Konsistenz in verschiedenen Implementierungen, unabhängig davon, ob Ihr Team Notizbuch-first-Entwicklungs- oder Infrastruktur-as-Code-Workflows priorisiert. Übernehmen Sie diese Grundsätze als Leitlinien und passen Sie sie an die Technologie und Prozesse Ihrer Organisation an.
- Versionsverwaltung für alles
- Speichern Sie Notizbücher, Skripts, Infrastrukturdefinitionen (IaC) und Auftragskonfigurationen in Git.
- Verwenden Sie Verzweigungsstrategien wie Gitflow, die an Standardentwicklungs-, Staging- und Produktionsbereitstellungsumgebungen ausgerichtet sind.
- Automatisieren von Tests
- Implementieren Sie Komponententests für Geschäftslogik mithilfe von Bibliotheken, z. B. Pytest für Python und ScalaTest für Scala .
- Überprüfen Sie die Funktionalität von Notebooks und Workflows mit Tools wie dem Databricks CLI bundle validate.
- Verwenden Sie Integrationstests für Workflows und Datenpipelinen, z. B. Chispa für Spark DataFrames.
- Verwenden von Infrastruktur als Code (IaC)
- Definieren Von Clustern, Aufträgen und Arbeitsbereichskonfigurationen mit deklarativen Automatisierungspaketen YAML oder Terraform.
- Parametrisieren Sie umgebungsspezifische Einstellungen anstelle von Hartcodierung, wie z. B. Clustergröße und Geheimnisse.
- Isolieren von Umgebungen
- Verwalten Sie separate Arbeitsbereiche für Entwicklung, Staging und Produktion.
- Verwenden Sie die MLflow-Modellregistrierung für modellbasierte Versionsverwaltung in allen Umgebungen.
- Wählen Sie Tools aus, die Ihrem Cloud-Ökosystem entsprechen:
- Azure: Azure DevOps und deklarative Automatisierungspakete oder Terraform.
- AWS: GitHub Actions und deklarative Automatisierungs-Bundles oder Terraform.
- GCP: Cloud Build- und deklarative Automatisierungspakete oder Terraform.
- Überwachen und Automatisieren von Rollbacks
- Verfolgen Sie die Erfolgsraten der Bereitstellung, die Auftragsleistung und die Testabdeckung.
- Implementieren Sie automatisierte Rollbackmechanismen für fehlgeschlagene Bereitstellungen.
- Vereinheitlichen der Bestandsverwaltung
- Verwenden Sie deklarative Automatisierungspakete , um Code, Aufträge und Infrastruktur als einzelne Einheit bereitzustellen. Vermeiden Sie die isolierte Verwaltung von Notizbüchern, Bibliotheken und Workflows.
Note
Databricks empfiehlt den Workload-Identitätsverbund für die CI/CD-Authentifizierung. Der Workload-Identitätsverbund beseitigt die Notwendigkeit von Databricks-Geheimschlüsseln, wodurch es die sicherste Möglichkeit ist, Ihre automatisierten Flüsse bei Databricks zu authentifizieren. Siehe Aktivieren des Workload-Identitätsverbunds in CI/CD.
Deklarative Automatisierungspakete für CI/CD
Deklarative Automatisierungspakete (früher als Databricks Asset Bundles bezeichnet) bieten einen leistungsstarken, einheitlichen Ansatz für die Verwaltung von Code, Workflows und Infrastruktur innerhalb des Databricks-Ökosystems und werden für Ihre CI/CD-Pipelines empfohlen. Durch die Bündelung dieser Elemente in eine einzelne YAML-definierte Einheit vereinfachen sie die Bereitstellung und sorgen für Konsistenz über alle Umgebungen hinweg. Für Benutzer, die sich an herkömmliche CI/CD-Workflows gewöhnt haben, kann die Übernahme von Bundles jedoch eine Veränderung der Denkweise erfordern.
Beispielsweise werden Java-Entwickler verwendet, um JARs mit Maven oder Gradle zu erstellen, Komponententests mit JUnit auszuführen und diese Schritte in CI/CD-Pipelines zu integrieren. Ebenso packen Python-Entwickler häufig Code in Räder und testen mit Pytest, während SQL-Entwickler sich auf die Abfrageüberprüfung und die Notizbuchverwaltung konzentrieren. Mit Bündeln konvergieren diese Workflows in ein strukturierteres und präskriptives Format, wobei die Bündelung von Code und Infrastruktur für die nahtlose Bereitstellung hervorgehoben wird.
In den folgenden Abschnitten erfahren Sie, wie Entwickler ihre Workflows anpassen können, um Pakete effektiv nutzen zu können.
Um schnell mit deklarativen Automatisierungspaketen zu beginnen, probieren Sie ein Lernprogramm aus: Entwickeln eines Auftrags mit deklarativen Automatisierungspaketen oder Entwickeln von Pipelines mit deklarativen Automatisierungspaketen.
Empfehlungen zur CI/CD-Quellcodeverwaltung
Entwickler müssen bei der Implementierung von CI/CD entscheiden, wie Quelldateien gespeichert und versioniert werden. Bündel ermöglichen es Ihnen, alles – Quellcode, Buildartefakte und Konfigurationsdateien – auf einfache Weise zu enthalten und sie im selben Quellcode-Repository zu finden, aber eine weitere Option besteht darin, Konfigurationsdateien von codebezogenen Dateien zu trennen. Die Auswahl hängt vom Workflow, der Projektkomplexität und den CI/CD-Anforderungen Ihres Teams ab, aber Databricks empfiehlt Folgendes:
- Verwenden Sie für kleine Projekte oder eine enge Kopplung zwischen Code und Konfiguration ein einzelnes Repository sowohl für die Code- als auch für die Bundlekonfiguration, um Workflows zu vereinfachen.
- Verwenden Sie für größere Teams oder unabhängige Veröffentlichungszyklen separate Repositorys für die Code- und Bündelkonfiguration, aber richten Sie klare CI/CD-Pipelines ein, die die Kompatibilität zwischen Versionen gewährleisten.
Unabhängig davon, ob Sie Ihre codebezogenen Dateien gemeinsam mit Ihren Bundlekonfigurationsdateien ablegen oder trennen möchten, verwenden Sie immer versionsbezogene Artefakte, wie z. B. Git-Commit-Hashes, beim Hochladen in Databricks oder externen Speicher, um die Rückverfolgbarkeit und Rollbackfunktionen sicherzustellen.
Einzelnes Repository für Code und Konfiguration
Bei diesem Ansatz werden sowohl quellcode- als auch Bundlekonfigurationsdateien im selben Repository gespeichert. Dies vereinfacht Workflows und sorgt für atome Änderungen.
| Pros | Cons |
|---|---|
|
|
Beispiel: Python-Code in einem Bundle
Dieses Beispiel enthält Python-Dateien und Bundledateien in einem Repository:
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── workflows/
│ │ ├── my_pipeline.yml # YAML pipeline def
│ │ └── my_pipeline_job.yml # YAML job def that runs pipeline
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
├── src/
│ ├── my_pipeline.ipynb # pipeline notebook
│ └── mypython.py # Additional Python
└── README.md
Separate Repositorys für Code und Konfiguration
Bei diesem Ansatz befindet sich der Quellcode in einem Repository, während die Bündelkonfigurationsdateien in einem anderen verwaltet werden. Diese Option eignet sich ideal für größere Teams oder Projekte, bei denen separate Gruppen anwendungsentwicklung und Databricks-Workflowverwaltung behandeln.
| Pros | Cons |
|---|---|
|
|
Beispiel: Java-Projekt und -Bündel
In diesem Beispiel befinden sich ein Java-Projekt und die zugehörigen Dateien in einem Repository, und die Bündeldateien befinden sich in einem anderen Repository.
Repository 1: Java-Dateien
Das erste Repository enthält alle Java-bezogenen Dateien:
java-app-repo/
├── pom.xml # Maven build configuration
├── src/
│ ├── main/
│ │ ├── java/ # Java source code
│ │ │ └── com/
│ │ │ └── mycompany/
│ │ │ └── app/
│ │ │ └── App.java
│ │ └── resources/ # Application resources
│ └── test/
│ ├── java/ # Unit tests for Java code
│ │ └── com/
│ │ └── mycompany/
│ │ └── app/
│ │ └── AppTest.java
│ └── resources/ # Test-specific resources
├── target/ # Compiled JARs and classes
└── README.md
- Entwickler schreiben Anwendungscode in
src/main/javaodersrc/main/scala. - Komponententests werden in
src/test/javaodersrc/test/scalagespeichert. - Bei einem Pull Request oder einem Commit machen CI/CD-Pipelines Folgendes:
- Kompilieren Sie den Code zu einem JAR, zum Beispiel
target/my-app-1.0.jar. - Laden Sie den JAR in ein Databricks Unity Catalog-Volume hoch. Siehe Upload JAR.
- Kompilieren Sie den Code zu einem JAR, zum Beispiel
Repository 2: Bündeln von Dateien
Ein zweites Repository enthält nur die Bundlekonfigurationsdateien:
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── jobs/
│ │ ├── my_java_job.yml # YAML job dev
│ │ └── my_other_job.yml # Additional job definitions
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
└── README.md
Die Bündelkonfiguration databricks.yml und Auftragsdefinitionen werden unabhängig voneinander verwaltet.
Die databricks.yml verweist auf das hochgeladene JAR-Artefakt, z. B.:
- jar: /Volumes/artifacts/my-app-${{ GIT_SHA }}.)jar
Empfohlener CI/CD-Workflow
Unabhängig davon, ob Sie Ihre Codedateien gemeinsam suchen oder von Ihren Paketkonfigurationsdateien trennen, wäre ein empfohlener Workflow der Folgende:
- Kompilieren und Testen des Codes
- Wird bei einem Pull Request oder einem Commit an den Mainbranch ausgelöst.
- Kompilieren Sie Code, und führen Sie Komponententests aus.
- Eine versionsierte Datei ausgeben, z. B.
my-app-1.0.jar.
- Laden Sie die kompilierte Datei, z. B. einen JAR, in ein Databricks Unity Catalog-Volume hoch, und speichern Sie sie.
- Speichern Sie die kompilierte Datei in einem Databricks Unity Catalog-Volume oder einem Artefakt-Repository wie AWS S3 oder Azure Blob Storage.
- Verwenden Sie ein Versionsschema, das an Git-Commit-Hashes oder semantische Versionsverwaltung gebunden ist, z. B.
dbfs:/mnt/artifacts/my-app-${{ github.sha }}.jar.
- Bündel validieren
- Führen Sie
databricks bundle validateaus, um sicherzustellen, dass diedatabricks.yml-Konfiguration korrekt ist. - Dieser Schritt stellt sicher, dass Fehlkonfigurationen, z. B. fehlende Bibliotheken, frühzeitig abgefangen werden.
- Führen Sie
- Bereitstellen des Bundles
- Um das Bundle in einer Staging- oder Produktionsumgebung bereitzustellen, verwenden Sie
databricks bundle deploy. - Verweisen Sie auf die hochgeladene kompilierte Bibliothek in
databricks.yml. Informationen zum Verweisen auf Bibliotheken finden Sie unter Deklarative Automatisierungsbundle-Bibliotheksabhängigkeiten.
- Um das Bundle in einer Staging- oder Produktionsumgebung bereitzustellen, verwenden Sie
Verzweigungsstrategie
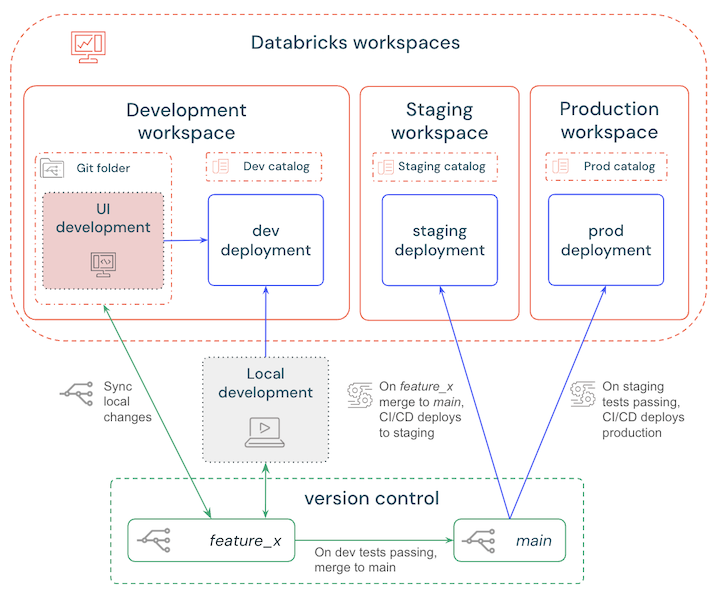
Es gibt verschiedene Verzweigungsstrategien, aus denen Sie wählen können, wenn Sie Ihre CI/CD-Pipeline einrichten. Die einfachste bewährte Methode ist:
- Entwickeln Sie lokal oder im Arbeitsbereich, und stellen Sie sie für einen Databricks-Entwicklungsarbeitsbereich bereit, um Änderungen zu testen.
- Erstellen Sie einen Feature-Branch, um Versionskontroll-Updates zu verwalten und Ihre lokalen Änderungen sowie die Änderungen im Arbeitsbereich regelmäßig zu synchronisieren.
- Wenn das Testen abgeschlossen ist, führen Sie die Feature-Verzweigung mit der Hauptzweigung zusammen.
- CI/CD stellt automatisch den Hauptzweig in einem Staging-Arbeitsbereich bereit und automatisierte Tests werden ausgelöst.
- Wenn die Staging-Tests und -Prüfungen bestehen, deployt CI/CD den Hauptzweig in einen Produktionsarbeitsbereich.
Diese Schritte werden im folgenden Diagramm beschrieben:
CI/CD für maschinelles Lernen
Machine Learning-Projekte stellen im Vergleich zur herkömmlichen Softwareentwicklung einzigartige CI/CD-Herausforderungen vor. Bei der Implementierung von CI/CD für ML-Projekte müssen Sie wahrscheinlich Folgendes berücksichtigen:
- Multi-Team-Koordination: Datenwissenschaftler, Ingenieure und MLOps-Teams verwenden häufig verschiedene Tools und Workflows. Databricks vereint diese Prozesse mit MLflow zur Verfolgung von Experimenten, Delta Sharing für Datengovernance und Declarative Automation Bundles für Infrastructure-as-Code.
- Daten- und Modellversionsverwaltung: ML-Pipelines erfordern nicht nur Code, sondern auch Schulungsdatenschemas, Featureverteilungen und Modellartefakte. Databricks Delta Lake stellt ACID-Transaktionen und eine Zeitreise für die Datenversionsverwaltung bereit, während die MLflow-Modellregistrierung die Modellherkunft handhabt.
- Reproduzierbarkeit in allen Umgebungen: ML-Modelle hängen von bestimmten Daten- und Code- und Infrastrukturkombinationen ab. Deklarative Automatisierungspakete sorgen für die atombasierte Bereitstellung dieser Komponenten in Entwicklungs-, Staging- und Produktionsumgebungen mit YAML-Definitionen.
- Kontinuierliches Umschulen und Überwachen: Modelle verschlechtern sich aufgrund von Datenverschiebung. Lakeflow-Aufträge ermöglichen automatisierte Umschulungspipelinen, während MLflow in Prometheus- und Databricks-Datenqualitätsüberwachung integriert wird, um die Leistungsnachverfolgung zu ermöglichen.
MLOps-Stapel für ML CI/CD
Databricks befasst sich mit ML CI/CD-Komplexität über MLOps Stacks, ein Framework auf Produktionsniveau, das deklarative Automatisierungsbündel, vorkonfigurierte CI/CD-Workflows und modulare ML-Projektvorlagen kombiniert. Diese Stapel erzwingen bewährte Methoden und ermöglichen gleichzeitig die Flexibilität für die Zusammenarbeit mit mehreren Teams über Datentechnik-, Data Science- und MLOps-Rollen hinweg.
| Team | Responsibilities | Beispielkomponenten für Bündel | Beispielartefakte |
|---|---|---|---|
| Dateningenieure | ETL-Pipelines erstellen, Datenqualität sicherstellen | Lakeflow Spark Declarative Pipelines YAML, Clusterrichtlinien |
etl_pipeline.yml, feature_store_job.yml |
| Datenwissenschaftler | Entwickeln von Modellschulungslogik, Validieren von Metriken | MLflow-Projekte, notizbuchbasierte Workflows |
train_model.yml, batch_inference_job.yml |
| MLOps-Ingenieure | Koordinieren von Bereitstellungen, Überwachen von Pipelines | Umgebungsvariablen, Überwachungs-Dashboards |
databricks.yml, lakehouse_monitoring.yml |
Eine ML CI/CD-Zusammenarbeit könnte wie folgt aussehen:
- Technische Fachkräfte für Daten committen ETL-Pipeline-Änderungen in ein Paket, wodurch eine automatisierte Schemaüberprüfung und eine Stagingbereitstellung ausgelöst werden.
- Wissenschaftliche Fachkräfte für Daten committen ML-Code, der Unit-Tests durchführt und in einen Staging-Arbeitsbereich für Integrationstests bereitstellt.
- MLOps-Techniker überprüfen Validierungsmetriken und fördern überprüfte Modelle zur Produktion mithilfe der MLflow Registry.
Details zur Implementierung finden Sie unter:
- MLOps Stacks Bundle: Schritt-für-Schritt-Anleitungen für die Bundleinitialisierung und Bereitstellung.
- MLOps Stacks GitHub-Repository: Vorkonfigurierte Vorlagen für Schulungen, Rückschlüsse und CI/CD.
Durch die Ausrichtung von Teams mit standardisierten Bündeln und MLOps-Stapeln können Organisationen die Zusammenarbeit optimieren und gleichzeitig die Auditierbarkeit über den GESAMTEN ML-Lebenszyklus hinweg beibehalten.
CI/CD für SQL-Entwickler
SQL-Entwickler, die Databricks SQL zum Verwalten von Streamingtabellen und materialisierten Ansichten verwenden, können Git-Integrations- und CI/CD-Pipelines nutzen, um ihre Workflows zu optimieren und qualitativ hochwertige Pipelines aufrechtzuerhalten. Mit der Einführung der Git-Unterstützung für Abfragen können SICH SQL-Entwickler auf das Schreiben von Abfragen konzentrieren, während Git die Versionsverwaltung ihrer .sql Dateien nutzt, was die Zusammenarbeit und Automatisierung ermöglicht, ohne umfassende Infrastrukturkenntnisse benötigen zu müssen. Darüber hinaus ermöglicht der SQL-Editor die Zusammenarbeit in Echtzeit und lässt sich nahtlos in Git-Workflows integrieren.
Für SQL-zentrierte Workflows:
SQL-Dateien der Versionssteuerung
- Speichern Sie .sql Dateien in Git-Repositorys mithilfe von Databricks Git-Ordnern oder externen Git-Anbietern, z. B. GitHub, Azure DevOps.
- Verwenden Sie Branches (z. B. Entwicklung, Staging, Produktion), um umgebungsspezifische Änderungen zu managen.
Integrieren Sie
.sqlDateien in CI/CD-Pipelines, um die Bereitstellung zu automatisieren:- Überprüfen Von Syntax- und Schemaänderungen während Pullanforderungen.
- Stellen Sie
.sql-Dateien in SQL-Workflows oder -Aufträgen von Databricks bereit.
Parametrisieren für die Umgebungsisolation
Verwenden Sie Variablen in
.sqlDateien, um umgebungsspezifische Ressourcen dynamisch zu referenzieren, z. B. Datenpfade oder Tabellennamen:CREATE OR REFRESH STREAMING TABLE ${env}_sales_ingest AS SELECT * FROM read_files('s3://${env}-sales-data')
Planen und Überwachen von Aktualisierungen
- Verwenden Sie SQL-Aufgaben in einem Databricks-Auftrag, um Aktualisierungen von Tabellen und materialisierten Ansichten (
REFRESH MATERIALIZED VIEW view_name) zu planen. - Überwachen sie den Aktualisierungsverlauf mithilfe von Systemtabellen.
- Verwenden Sie SQL-Aufgaben in einem Databricks-Auftrag, um Aktualisierungen von Tabellen und materialisierten Ansichten (
Ein Workflow kann folgendes sein:
- Entwickeln: Schreiben und Testen von
.sql-Skripts lokal oder im Databricks SQL-Editor und committen Sie sie dann in einem Git-Branch. - Validate: Während einer Pullanforderung überprüfen Sie die Syntax und Schemakompatibilität mithilfe automatisierter CI-Prüfungen.
- Bereitstellen: Stellen Sie beim Zusammenführen die .sql-Skripte mithilfe von CI/CD-Pipelines in der Zielumgebung bereit, zum Beispiel GitHub Actions oder Azure Pipelines.
- Überwachen: Verwenden Sie Databricks-Dashboards und -Warnungen, um die Abfrageleistung und Datenfrische nachzuverfolgen.
CI/CD für Dashboardentwickler
Databricks unterstützt die Integration von Dashboards in CI/CD-Workflows mithilfe von Declarative Automation Bundles. Diese Funktion ermöglicht Dashboardentwicklern Folgendes:
- Versionssteuerungsdashboards, die die Auditierbarkeit gewährleisten und die Zusammenarbeit zwischen Teams vereinfachen.
- Automatisieren Sie Bereitstellungen von Dashboards zusammen mit Aufträgen und Pipelines in allen Umgebungen, um die End-to-End-Ausrichtung zu ermöglichen.
- Verringern Sie manuelle Fehler, und stellen Sie sicher, dass Updates in allen Umgebungen einheitlich angewendet werden.
- Beibehalten Sie hochwertige Analytik-Workflows, indem Sie CI/CD-Best Practices einhalten.
Für Dashboards in CI/CD:
Verwenden Sie den
databricks bundle generateBefehl, um vorhandene Dashboards als JSON-Dateien zu exportieren und die YAML-Konfiguration zu generieren, die sie in das Bundle einschließt:resources: dashboards: sales_dashboard: display_name: 'Sales Dashboard' file_path: ./dashboards/sales_dashboard.lvdash.json warehouse_id: ${var.warehouse_id}Speichern Sie diese
.lvdash.jsonDateien in Git-Repositorys, um Änderungen nachzuverfolgen und effektiv zusammenzuarbeiten.Stellen Sie Dashboards automatisch in CI/CD-Pipelines mit
databricks bundle deploybereit. Zum Beispiel der Bereitstellungsschritt bei GitHub Actions:name: Deploy Dashboard run: databricks bundle deploy --target=prod env: DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }}Verwenden Sie Variablen, z. B.
${var.warehouse_id}, zum Parametrisieren von Konfigurationen wie SQL-Warehouses oder Datenquellen, um eine nahtlose Bereitstellung in Entwicklungs-, Staging- und Produktionsumgebungen sicherzustellen.Verwenden Sie die
bundle generate --watchOption, lokale Dashboard-JSON-Dateien kontinuierlich mit Änderungen zu synchronisieren, die in der Databricks-Benutzeroberfläche vorgenommen wurden. Wenn Diskrepanzen auftreten, verwenden Sie das--force-Flag während der Bereitstellung, um Remotedashboards mit lokalen Versionen zu überschreiben.
Informationen zu Dashboards in Bündeln finden Sie in der Dashboardressource. Ausführliche Informationen zu Paketbefehlen finden Sie in der bundle-Befehlsgruppe.