Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Databricks-Erweiterung für Visual Studio Code bietet zusätzliche Features in Visual Studio Code, mit denen Sie deklarative Automatisierungspakete auf einfache Weise definieren, bereitstellen und ausführen können, um CI/CD Best Practices auf Ihre Lakeflow-Aufträge, Lakeflow Spark Declarative Pipelines und MLOps Stacks anzuwenden. Erfahren Sie , was deklarative Automatisierungspakete sind?.
Informationen zum Installieren der Databricks-Erweiterung für Visual Studio Code finden Sie unter Installieren der Databricks-Erweiterung für Visual Studio Code.
Deklarative Automatisierungsbundle-Unterstützung in Projekten
Die Databricks-Erweiterung für Visual Studio Code fügt die folgenden Features für Ihre Deklarativen Automatisierungsbundle-Projekte hinzu:
- Einfache Authentifizierung und Konfiguration Ihrer deklarativen Automatisierungspakete über die Visual Studio Code UI, einschließlich AuthType-Profilauswahl . Siehe Einrichten der Autorisierung für die Databricks-Erweiterung für Visual Studio Code.
- Ein Ziel-Selektor im Erweiterungsbereich von Databricks, um schnell zwischen verschiedenen Zielumgebungen für Pakete zu wechseln. Siehe Ändern des Zielbereitstellungsarbeitsbereichs.
- Die Option Override-Jobs-Cluster im Bündel im Erweiterungsbereich ermöglicht eine einfache Überschreibung von Clustern.
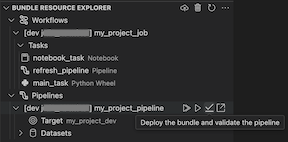
- Eine Ansicht "Ressourcen-Explorer für Bundles ", in der Sie Ihre Bündelressourcen mithilfe der Visual Studio Code-Benutzeroberfläche durchsuchen können, stellen Sie die ressourcen des lokalen Databricks-Bestandspakets mit einem einzigen Klick in Ihrem Remote-Azure Databricks-Arbeitsbereich bereit, und wechseln Sie direkt zu Ihren bereitgestellten Ressourcen in Ihrem Arbeitsbereich aus Visual Studio Code. Siehe Bündel-Ressourcen-Explorer.
- Eine Bündel-Variablenansicht, mit der Sie Ihre Bündelvariablen mithilfe der Visual Studio Code-Benutzeroberfläche durchsuchen und bearbeiten können. Siehe Bündel-Variablenansicht.
Bündelressourcen-Explorer
Die Ansicht Paketressourcen-Explorer in der Databricks-Erweiterung für Visual Studio Code verwendet die Ressourcendefinitionen in der Paketkonfiguration des Projekts, um Ressourcen einschließlich der Pipelinedatasets und ihrer Schemas anzuzeigen. Außerdem können Sie Ressourcen bereitstellen und ausführen, partielle Aktualisierungen von Pipelines überprüfen und ausführen, Pipelineausführungsereignisse und Diagnosen anzeigen und zu Ressourcen in Ihrem Azure Databricks-Remotearbeitsbereich navigieren. Informationen zu Bündel-Konfigurationsressourcen finden Sie unter Ressourcen.
Zum Beispiel eine einfache Auftragsdefinition:
resources:
jobs:
my-notebook-job:
name: 'My Notebook Job'
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
In der Ansicht Bündelressourcen-Explorer in der Erweiterung wird die Notebook-Job-Ressource angezeigt:
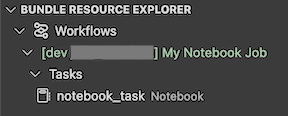
Bereitstellen und Ausführen eines Auftrags
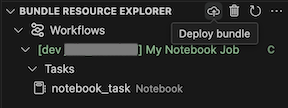
Um das Bündel bereitzustellen, klicken Sie auf das Cloud-Symbol (Bündel bereitstellen).
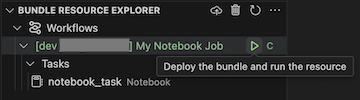
Um den Auftrag auszuführen, wählen Sie in der Ansicht Bündelressourcen-Explorer den Namen des Jobs aus, der in diesem Beispiel Mein Notebook-Job ist. Klicken Sie als Nächstes auf das Wiedergabesymbol (Bereitstellen des Bündels und Ausführen der Ressource).
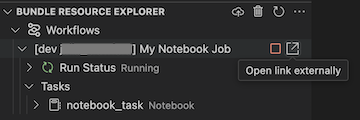
Um den ausgeführten Auftrag anzuzeigen, erweitern Sie in der Ansicht Bündelressourcen-Explorer den Job-Namen, klicken Sie auf Status ausführen und klicken Sie dann auf das Link-Symbol (Link extern öffnen).
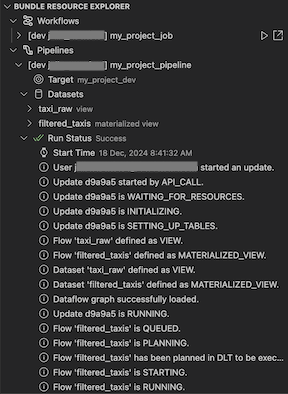
Überprüfen und Diagnostizieren von Pipelineproblemen
Für eine Pipeline können Sie die Validierung und ein teilweises Update auslösen, indem Sie die Pipeline auswählen und anschließend auf das Symbol (Bereitstellen des Bündels und Validieren der Pipeline) klicken. Die Ereignisse der Ausführung werden angezeigt, und alle Fehler können im Visual Studio Code-Panel PROBLEME diagnostiziert werden.
Bündel-Variablenansicht
In der Ansicht Bündel-Variablenansicht in der Databricks-Erweiterung für Visual Studio Code werden alle benutzerdefinierten Variablen und zugehörigen Einstellungen angezeigt, die in ihrer Bundle-Konfiguration definiert sind. Sie können Variablen auch direkt mithilfe der Bündel-Variablenansicht definieren. Diese Werte überschreiben die in den Bündel-Konfigurationsdateien festgelegten. Informationen zu benutzerdefinierten Variablen finden Sie unter Benutzerdefinierte Variablen.
Die Bündel-Variablenansicht in der Erweiterung würde beispielsweise Folgendes anzeigen:

Für die Variable my_custom_var, die in dieser Bündel-Konfiguration definiert ist:
variables:
my_custom_var:
description: 'Max workers'
default: '4'
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}