Ausführen einer Python-Datei auf einem Cluster mithilfe der Databricks-Erweiterung für Visual Studio Code
Dieser Artikel beschreibt, wie Sie eine Python-Datei auf einem Azure Databricks-Cluster mithilfe der Databricks-Erweiterung für Visual Studio Code ausführen. Weitere Informationen finden Sie unter Was ist die Databricks-Erweiterung für Visual Studio Code?.
Informationen zum Debuggen einer Python-Datei finden Sie unter Debuggen von Code mithilfe von Databricks Connect für die Databricks-Erweiterung für Visual Studio Code. Informationen zum Ausführen einer Python-Datei als Azure Databricks-Auftrag finden Sie unter Ausführen einer Python-Datei als Auftrag mithilfe der Databricks-Erweiterung für Visual Studio Code.
In diesem Artikel wird davon ausgegangen, dass Sie die Databricks-Erweiterung für Visual Studio Code bereits installiert und eingerichtet haben. Weitere Informationen finden Sie unter Installieren der Databricks-Erweiterung für Visual Studio Code.
Gehen Sie bei geöffneter Erweiterung und geöffnetem Codeprojekt wie folgt vor:
- Öffnen Sie in Ihrem Codeprojekt die Python-Datei, die Sie im Cluster ausführen möchten.
- Führen Sie eines der folgenden Verfahren aus:
Klicken Sie in der Explorer-Ansicht (Ansicht > Explorer) mit der rechten Maustaste auf die Datei, und wählen Sie dann im Kontextmenü Datei in Databricks hochladen und ausführen aus.
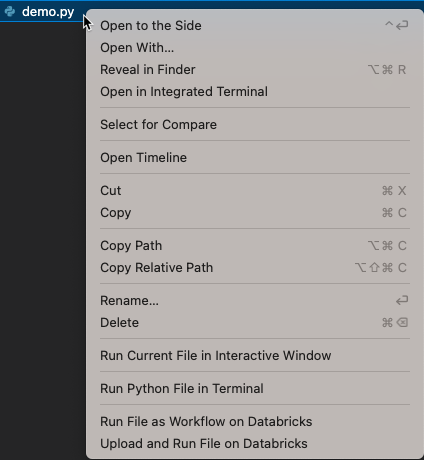
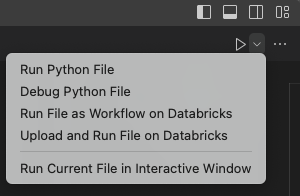
Klicken Sie in der Titelleiste des Datei-Editors auf den Dropdownpfeil neben dem Wiedergabesymbol (Ausführen oder Debuggen). Klicken Sie dann in der Dropdownliste auf Datei in Databricks hochladen und ausführen.
Die Datei wird im Cluster ausgeführt, und alle Ausgaben werden in der Debugging-Konsole (Ansicht > Debugging-Konsole) ausgegeben.