Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie eine ETL-Pipeline (Extrahieren, Transformieren und Laden) mit Änderungsdatenerfassung (CDC) mithilfe von Lakeflow Spark Declarative Pipelines (SDP) für die Daten-Orchestrierung und das automatische Laden erstellen und bereitstellen. Eine ETL-Pipeline implementiert die Schritte zum Lesen von Daten aus Quellsystemen, zum Transformieren dieser Daten basierend auf Anforderungen, z. B. Datenqualitätsprüfungen und Datensatzdeduplizierung, und zum Schreiben der Daten in ein Zielsystem, z. B. ein Data Warehouse oder einen Data Lake.
In diesem Lernprogramm verwenden Sie Daten aus einer customers Tabelle in einer MySQL-Datenbank für:
- Extrahieren Sie die Änderungen aus einer Transaktionsdatenbank mithilfe von Debezium oder einem anderen Tool, und speichern Sie sie im Cloudobjektspeicher (S3, ADLS oder GCS). In diesem Lernprogramm überspringen Sie das Einrichten eines externen CDC-Systems und generieren stattdessen gefälschte Daten, um das Lernprogramm zu vereinfachen.
- Verwenden Sie das automatische Laden, um die Nachrichten inkrementell aus dem Cloudobjektspeicher zu laden und die unformatierten Nachrichten in der
customers_cdcTabelle zu speichern. Auto Loader ermittelt das Schema und verarbeitet die Schemaentwicklung. - Erstellen Sie die
customers_cdc_cleanTabelle, um die Datenqualität anhand der Erwartungen zu überprüfen. Beispielsweise sollteidniemalsnullsein, da es zum Ausführen von Upsert-Vorgängen verwendet wird. - Führen Sie
AUTO CDC ... INTOan den bereinigten CDC-Daten durch, um Änderungen in der finalencustomers-Tabelle einzufügen und zu aktualisieren. - Veranschaulichen Sie, wie eine Pipeline eine Tabelle für eine langsam ändernde Dimension vom Typ 2 erstellen kann, um sämtliche Änderungen nachzuverfolgen.
Ziel ist es, die Rohdaten in nahezu Echtzeit aufzunehmen und eine Tabelle für Ihr Analystenteam zu erstellen und gleichzeitig die Datenqualität sicherzustellen.
Das Lernprogramm verwendet die Medallion Lakehouse-Architektur, in der sie Rohdaten über die Bronzeschicht erfasst, Daten mit der Silberschicht bereinigt und überprüft und die dimensionale Modellierung und Aggregation mithilfe der Goldschicht anwendet. Weitere Informationen finden Sie unter "Was ist die Medallion Lakehouse-Architektur?
Der implementierte Fluss sieht wie folgt aus:
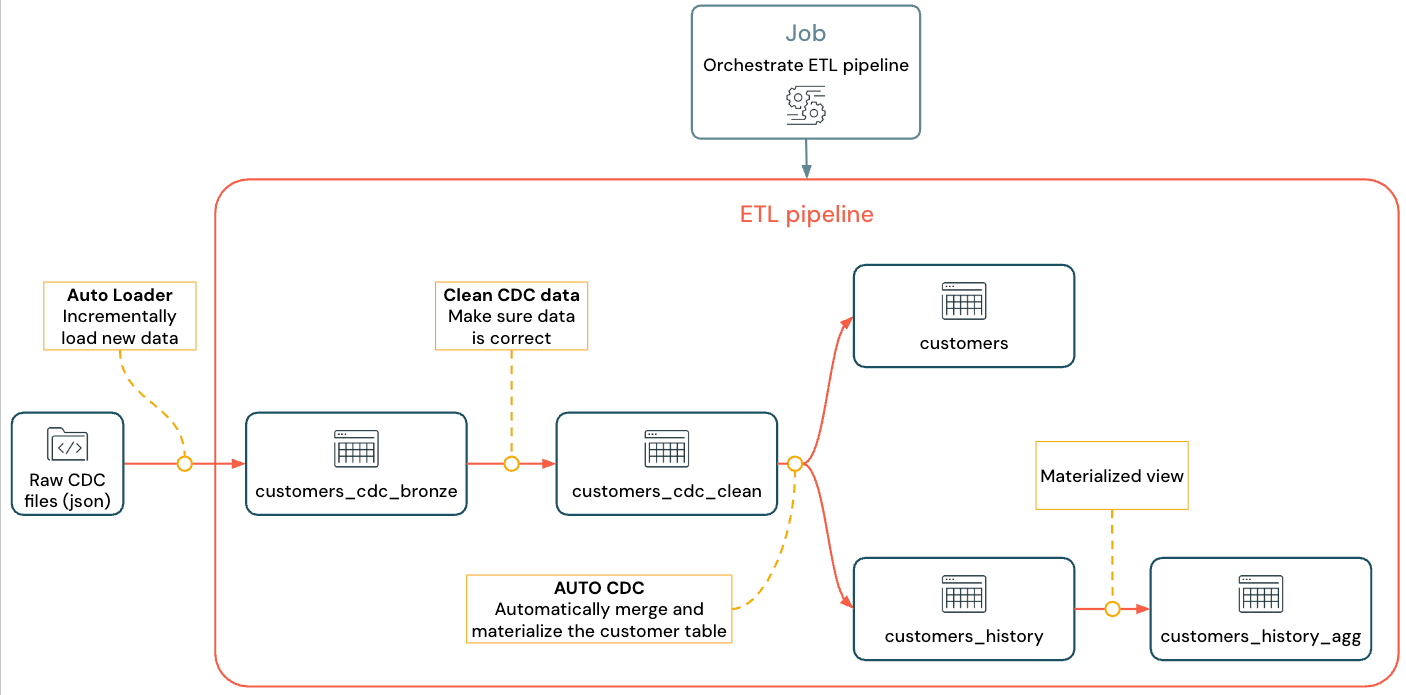
Weitere Informationen zu Pipeline, Auto Loader und CDC finden Sie unter Lakeflow Spark Declarative Pipelines, Was ist Auto Loader?, und Change Data Capture und Snapshots
Anforderungen
Um dieses Tutorial abzuschließen, müssen Sie die folgenden Anforderungen erfüllen:
- Melden Sie sich bei einem Azure Databricks-Arbeitsbereich an.
- Haben Sie Unity-Katalog für Ihren Arbeitsbereich aktiviert.
- Haben Sie serverlose Computefunktion für Ihr Konto aktiviert. Serverless Lakeflow Spark Declarative Pipelines ist in nicht allen Arbeitsbereichsregionen verfügbar. Siehe Features mit eingeschränkter regionaler Verfügbarkeit für verfügbare Regionen. Wenn die serverlose Berechnung für Ihr Konto nicht aktiviert ist, sollten die Schritte mit der Standardberechnung für Ihren Arbeitsbereich verwendet werden.
- Verfügen Sie über die Berechtigung zum Erstellen einer Computeressource oder des Zugriffs auf eine Computeressource.
- Verfügen Sie über Berechtigungen zum Erstellen eines neuen Schemas in einem Katalog. Die erforderlichen Berechtigungen sind
USE CATALOGundCREATE SCHEMA. - Verfügen Sie über Berechtigungen zum Erstellen eines neuen Volumes in einem vorhandenen Schema. Die erforderlichen Berechtigungen sind
USE SCHEMAundCREATE VOLUME.
Ändern der Datenerfassung in einer ETL-Pipeline
Change Data Capture (CDC) ist der Prozess, der Änderungen an Datensätzen erfasst, die an einer Transaktionsdatenbank (z. B. MySQL oder PostgreSQL) oder einem Data Warehouse vorgenommen wurden. CDC erfasst Vorgänge wie Löschvorgänge, Anfügevorgänge und Aktualisierungen, in der Regel als Datenstrom, um Tabellen in externen Systemen neu zu materialisieren. CDC ermöglicht das inkrementelle Laden, ohne dass Massendatenaktualisierungen erforderlich sind.
Hinweis
Um dieses Lernprogramm zu vereinfachen, überspringen Sie das Einrichten eines externen CDC-Systems. Gehen Sie davon aus, dass CDC-Daten als JSON-Dateien im Cloudobjektspeicher (S3, ADLS oder GCS) ausgeführt und gespeichert werden. In diesem Lernprogramm wird die Faker Bibliothek verwendet, um die im Lernprogramm verwendeten Daten zu generieren.
Aufzeichnen von CDC
Es stehen eine Vielzahl von CDC-Tools zur Verfügung. Eine der führenden Open-Source-Datenintegrationslösungen ist Debezium, aber es gibt auch andere Tools wie Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate und AWS DMS, die das Arbeiten mit Datenquellen erleichtern.
In diesem Lernprogramm verwenden Sie CDC-Daten aus einem externen System wie Debezium oder DMS. Debezium erfasst jede geänderte Zeile. In der Regel wird der Verlauf von Datenänderungen an Kafka-Themen gesendet oder als Dateien gespeichert.
Sie müssen die CDC-Informationen aus der customers-Tabelle im JSON-Format aufnehmen, prüfen, ob sie korrekt sind, und dann die Kundentabelle im Lakehouse erstellen.
CDC-Eingabe von Debezium
Für jede Änderung erhalten Sie eine JSON-Nachricht mit allen Feldern der Zeile, die aktualisiert wird (id, firstname, , lastname, email). address Die Nachricht enthält auch zusätzliche Metadaten:
-
operation: Ein Vorgangscode, in der Regel (DELETE,APPEND,UPDATE). -
operation_date: Datum und Zeitstempel für den Datensatz für jede Vorgangsaktion.
Tools wie Debezium können erweiterte Ausgaben erzeugen, z. B. den Zeilenwert vor der Änderung, aber in diesem Lernprogramm werden sie aus Gründen der Einfachheit weggelassen.
Schritt 1: Erstellen einer Pipeline
Erstellen Sie eine neue ETL-Pipeline, um Ihre CDC-Datenquelle abzufragen und Tabellen in Ihrem Arbeitsbereich zu generieren.
Klicken Sie in Ihrem Arbeitsbereich auf
 Neu in der oberen linken Ecke.
Neu in der oberen linken Ecke.Klicken Sie auf ETL-Pipeline.
Ändern Sie den Titel der Pipeline in
Pipelines with CDC tutorialoder einen Namen, den Sie bevorzugen.Wählen Sie unter dem Titel einen Katalog und ein Schema aus, für den Sie Schreibberechtigungen besitzen.
Dieser Katalog und dieses Schema werden standardmäßig verwendet, wenn Sie keinen Katalog oder schema in Ihrem Code angeben. Ihr Code kann in einen beliebigen Katalog oder schema schreiben, indem er den vollständigen Pfad angibt. In diesem Lernprogramm werden die hier angegebenen Standardwerte verwendet.
Wählen Sie unter "Erweiterte Optionen" die Option "Start" mit einer leeren Datei aus.
Wählen Sie einen Ordner für Ihren Code aus. Sie können " Durchsuchen" auswählen, um die Liste der Ordner im Arbeitsbereich zu durchsuchen. Sie können einen beliebigen Ordner auswählen, für den Sie Schreibberechtigungen besitzen.
Um die Versionssteuerung zu verwenden, wählen Sie einen Git-Ordner aus. Wenn Sie einen neuen Ordner erstellen müssen, wählen Sie das
Wählen Sie Python oder SQL für die Sprache Ihrer Datei basierend auf der Sprache aus, die Sie für das Lernprogramm verwenden möchten.
Klicken Sie auf "Auswählen ", um die Pipeline mit diesen Einstellungen zu erstellen, und öffnen Sie den Lakeflow Pipelines Editor.
Sie verfügen jetzt über eine leere Pipeline mit einem Standardkatalog und einem Standardschema. Richten Sie als Nächstes die Beispieldaten ein, die im Lernprogramm importiert werden sollen.
Schritt 2: Erstellen der zu importierenden Beispieldaten in diesem Lernprogramm
Dieser Schritt ist nicht erforderlich, wenn Sie Ihre eigenen Daten aus einer vorhandenen Quelle importieren. Für dieses Lernprogramm generieren Sie gefälschte Daten als Beispiel für das Lernprogramm. Erstellen Sie ein Notizbuch zum Ausführen des Python-Datengenerierungsskripts. Dieser Code muss nur einmal ausgeführt werden, um die Beispieldaten zu generieren. Erstellen Sie ihn also im Ordner der Pipeline explorations , der nicht als Teil einer Pipelineaktualisierung ausgeführt wird.
Hinweis
Dieser Code verwendet Faker , um die CDC-Beispieldaten zu generieren. Faker ist für die automatische Installation verfügbar, daher verwendet das Tutorial %pip install faker. Sie können auch eine Abhängigkeit von Fälschung für das Notizbuch festlegen. Siehe Hinzufügen von Abhängigkeiten zum Notizbuch.
Klicken Sie im Lakeflow-Pipelines-Editor in der Randleiste des Asset-Browsers links neben dem Editor auf das
Hinzufügen, und wählen Sie dann Erkundung aus.Geben Sie ihm einen Namen, wie
Setup data, und wählen Sie Python. Sie können den Standardzielordner beibehalten, der ein neuerexplorationsOrdner ist.Klicken Sie auf "Erstellen". Dadurch wird ein Notizbuch im neuen Ordner erstellt.
Geben Sie den folgenden Code in die erste Zelle ein. Sie müssen die Definitionen von
<my_catalog>und<my_schema>so ändern, dass sie dem im vorherigen Verfahren ausgewählten Standardkatalog und Schema entsprechen.%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Um das im Lernprogramm verwendete Dataset zu generieren, drücken Sie die Umschalttaste + und Enter, um den Code auszuführen.
Wahlfrei. Um eine Vorschau der in diesem Lernprogramm verwendeten Daten anzuzeigen, geben Sie den folgenden Code in die nächste Zelle ein, und führen Sie den Code aus. Aktualisieren Sie den Katalog und das Schema so, dass er dem Pfad aus dem vorherigen Code entspricht.
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Dadurch wird ein großer Datensatz (mit gefälschten CDC-Daten) generiert, den Sie im restlichen Lernprogramm verwenden können. Im nächsten Schritt nehmen Sie die Daten mithilfe des automatischen Ladeprogramms ein.
Schritt 3: Inkrementelles Laden von Daten mit Auto-Loader
Der nächste Schritt besteht darin, die Rohdaten aus dem (gefälschten) Cloudspeicher in eine Bronzeschicht aufzunehmen.
Dies kann aus mehreren Gründen herausfordernd sein, da Sie müssen:
- Arbeiten Sie im großen Maßstab, und nehmen Sie möglicherweise Millionen von kleinen Dateien auf.
- Ableiten des Schemas und des JSON-Typs.
- Behandeln Sie ungültige Datensätze mit falschem JSON-Schema.
- Kümmern Sie sich um die Schemaentwicklung (z. B. eine neue Spalte in der Kundentabelle).
Auto Loader vereinfacht diese Datenaufnahme, einschließlich der Schema-Erkennung und Schema-Evolution, während es auf Millionen eingehender Dateien skaliert. Auto Loader ist in Python mit cloudFiles und in SQL SELECT * FROM STREAM read_files(...) verfügbar und kann mit einer Vielzahl von Formaten (JSON, CSV, Apache Avro usw.) verwendet werden:
Durch das Definieren der Tabelle als Streamingtabelle wird sichergestellt, dass Nur neue eingehende Daten verwendet werden. Wenn Sie sie nicht als Streamingtabelle definieren, werden alle verfügbaren Daten gescannt und erfasst. Weitere Informationen finden Sie unter Streamingtabellen .
Um die eingehenden CDC-Daten mit Auto Loader aufzunehmen, kopieren und fügen Sie den folgenden Code in die Codedatei ein, die mit Ihrer Pipeline erstellt wurde (aufgerufen
my_transformation.py). Sie können Python oder SQL basierend auf der Sprache verwenden, die Sie beim Erstellen der Pipeline ausgewählt haben. Achten Sie darauf, die<catalog>und<schema>durch die für die Standardpipeline eingerichteten zu ersetzen.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" )Klicken Sie auf
 Führen Sie die Datei oder die Pipeline aus, um ein Update für die verbundene Pipeline zu starten. Bei nur einer Quelldatei in Ihrer Pipeline sind diese funktional gleichwertig.
Führen Sie die Datei oder die Pipeline aus, um ein Update für die verbundene Pipeline zu starten. Bei nur einer Quelldatei in Ihrer Pipeline sind diese funktional gleichwertig.
Nach Abschluss des Updates wird der Editor mit Informationen zu Ihrer Pipeline aktualisiert.
- Das Pipelinediagramm (DAG) in der Randleiste rechts neben dem Code zeigt eine einzelne Tabelle.
customers_cdc_bronze - Eine Zusammenfassung des Updates wird oben im Pipelineressourcenbrowser angezeigt.
- Details der generierten Tabelle werden im unteren Bereich angezeigt, und Sie können Daten aus der Tabelle durchsuchen, indem Sie sie auswählen.
Dies sind die rohen Bronzeschichtdaten, die aus dem Cloudspeicher importiert werden. Bereinigen Sie im nächsten Schritt die Daten, um eine Silberschichttabelle zu erstellen.
Schritt 4: Bereinigen und Erwartungen zum Nachverfolgen der Datenqualität
Nachdem die Bronzeschicht definiert wurde, erstellen Sie die Silberschicht, indem Sie Erwartungen zur Kontrolle der Datenqualität hinzufügen. Überprüfen Sie die folgenden Bedingungen:
- Die ID darf niemals sein
null. - Der CDC-Vorgangstyp muss gültig sein.
- JSON muss vom automatischen Ladeprogramm korrekt gelesen werden.
Zeilen, die diese Bedingungen nicht erfüllen, werden gelöscht.
Weitere Informationen finden Sie unter Management der Datenqualität mit Pipeline-Erwartungen.
Klicken Sie in der Seitenleiste des Pipelineressourcen-Browsers auf das
Fügen SieTransformation hinzu.Geben Sie einen Namen ein, und wählen Sie eine Sprache (Python oder SQL) für die Quellcodedatei aus. Sie können Sprachen in einer Pipeline kombinieren und abgleichen, sodass Sie einen der Sprachen für diesen Schritt auswählen können.
Um eine Silberschicht mit einer gereinigten Tabelle zu erstellen und Einschränkungen zu erzwingen, kopieren Sie den folgenden Code, und fügen Sie ihn in die neue Datei ein (wählen Sie Python oder SQL basierend auf der Sprache der Datei aus).
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Klicken Sie auf
Führen Sie die Datei oder die Pipeline aus, um ein Update für die verbundene Pipeline zu starten.Da es jetzt zwei Quelldateien gibt, tun diese nicht dasselbe, aber in diesem Fall ist die Ausgabe identisch.
- Führen Sie die Pipeline aus, um die gesamte Pipeline einschließlich des Codes aus Schritt 3 auszuführen. Wenn Ihre Eingabedaten aktualisiert wurden, würde dies alle Änderungen aus dieser Quelle in Ihre Bronzeschicht ziehen. Dadurch wird der Code nicht aus dem Datensetupschritt ausgeführt, da sich dieser im Ordner "Explorations" befindet und nicht Teil der Quelle für Ihre Pipeline ist.
- Datei ausführen führt nur die aktuelle Quelldatei aus. In diesem Fall generiert dies, ohne dass Ihre Eingabedaten aktualisiert werden, die Silberdaten aus der zwischengespeicherten Bronzetabelle. Es wäre nützlich, nur diese Datei für eine schnellere Iteration auszuführen, wenn Sie Ihren Pipelinecode erstellen oder bearbeiten.
Wenn die Aktualisierung abgeschlossen ist, können Sie sehen, dass das Pipelinediagramm jetzt zwei Tabellen (mit der silbernen Schicht je nach Bronzeschicht) anzeigt, und im unteren Bereich werden Details für beide Tabellen angezeigt. Der obere Bereich des Pipeline-Assets-Browsers zeigt jetzt mehrere Zeitangaben an, aber nur Details für den letzten Durchlauf.
Erstellen Sie als Nächstes Die endgültige Goldschichtversion der customers Tabelle.
Schritt 5: Materialisieren der Kundentabelle mit einem AUTO CDC-Datenstrom
Bis zu diesem Punkt haben die Tabellen die CDC-Daten in jedem Schritt nur weitergegeben. Erstellen Sie nun die customers Tabelle, die sowohl die aktuellste Ansicht enthält als auch ein Replikat der ursprünglichen Tabelle ist, nicht die Liste der CDC-Vorgänge, die sie erstellt haben.
Dies ist nicht trivial, manuell zu implementieren. Sie müssen Dinge wie die Datendeduplizierung berücksichtigen, um die aktuellste Zeile zu behalten.
Lakeflow Spark Declarative Pipelines lösen diese Herausforderungen mit der AUTO CDC Operation.
Klicken Sie auf der Randleiste der Pipelineressourcen auf das
Hinzufügen und Transformieren.Geben Sie einen Namen ein, und wählen Sie eine Sprache (Python oder SQL) für die neue Quellcodedatei aus. Sie können eine der Sprachen für diesen Schritt erneut auswählen, aber den richtigen Code unten verwenden.
Um die CDC-Daten mithilfe von
AUTO CDCLakeflow Spark Declarative Pipelines zu verarbeiten, kopieren Sie den folgenden Code, und fügen Sie ihn in die neue Datei ein.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Klicken Sie auf
Führen Sie die Datei aus, um ein Update für die verbundene Pipeline zu starten.
Wenn das Update abgeschlossen ist, können Sie sehen, dass Ihr Pipelinediagramm 3 Tabellen anzeigt, die von Bronze zu Silber zu Gold wechseln.
Schritt 6: Nachverfolgen des Aktualisierungsverlaufs mit langsam veränderlicher Dimension Typ 2 (SCD2)
Es ist häufig erforderlich, eine Tabelle zu erstellen, die alle Änderungen nachverfolgt, die sich aus APPEND, , UPDATEund DELETE:
- Verlauf: Sie möchten einen Verlauf aller Änderungen an Ihrer Tabelle beibehalten.
- Rückverfolgbarkeit: Sie möchten sehen, welcher Vorgang aufgetreten ist.
SCD2 mit Lakeflow SDP
Delta unterstützt Änderungsdatenfluss (CHANGE Data Flow, CDF) und table_change kann Tabellenänderungen in SQL und Python abfragen. Der Hauptanwendungsfall von CDF besteht jedoch darin, Änderungen in einer Pipeline zu erfassen, nicht um eine vollständige Ansicht der Tabellenänderungen von Anfang an zu erstellen.
Die Implementierung wird insbesondere komplex, wenn Sie über außerhalb der Reihenfolge liegende Ereignisse verfügen. Wenn Sie Ihre Änderungen nach einem Zeitstempel sequenzieren und eine Änderung erhalten müssen, die in der Vergangenheit aufgetreten ist, müssen Sie einen neuen Eintrag in der SCD-Tabelle anfügen und die vorherigen Einträge aktualisieren.
Lakeflow SDP entfernt diese Komplexität und ermöglicht es Ihnen, eine separate Tabelle zu erstellen, die alle Änderungen von Anfang an enthält. Diese Tabelle kann dann im Maßstab mit bestimmten Partitionen oder ZORDER-Spalten verwendet werden, falls erforderlich. Out-of-Order-Felder werden von Haus aus basierend auf der _sequence_by gehandhabt.
Verwenden Sie zum Erstellen einer SCD2-Tabelle die Option STORED AS SCD TYPE 2 in SQL oder stored_as_scd_type="2" in Python.
Hinweis
Sie können auch einschränken, welche Spalten das Feature verfolgt, indem Sie die Option verwenden: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
Klicken Sie auf der Randleiste der Pipelineressourcen auf das
Hinzufügen und Transformieren.Geben Sie einen Namen ein, und wählen Sie eine Sprache (Python oder SQL) für die neue Quellcodedatei aus.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue Datei ein.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Klicken Sie auf
Führen Sie die Datei aus, um ein Update für die verbundene Pipeline zu starten.
Wenn die Aktualisierung abgeschlossen ist, enthält das Pipelinediagramm die neue customers_history Tabelle, auch abhängig von der Silberschichttabelle, und im unteren Bereich werden die Details für alle vier Tabellen angezeigt.
Schritt 7: Erstellen einer materialisierten Ansicht, die nachverfolgt, wer ihre Informationen am meisten geändert hat
Die Tabelle customers_history enthält alle historischen Änderungen, die ein Benutzer an seinen Informationen vorgenommen hat. Erstellen Sie eine einfache materialisierte Ansicht in der Goldschicht, die nachverfolgt, wer ihre Informationen am meisten geändert hat. Dies könnte für die Betrugserkennungsanalyse oder Benutzerempfehlungen in einem realen Szenario verwendet werden. Darüber hinaus wurden durch das Anwenden von Änderungen mit SCD2 bereits Duplikate entfernt, sodass Sie die Zeilen pro Benutzer-ID direkt zählen können.
Klicken Sie auf der Randleiste der Pipelineressourcen auf das
Hinzufügen und Transformieren.Geben Sie einen Namen ein, und wählen Sie eine Sprache (Python oder SQL) für die neue Quellcodedatei aus.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue Quelldatei ein.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count("address").alias("address_count"), count("email").alias("email_count"), count("firstname").alias("firstname_count"), count("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count("address") as address_count, count("email") AS email_count, count("firstname") AS firstname_count, count("lastname") AS lastname_count FROM customers_history GROUP BY idKlicken Sie auf
Führen Sie die Datei aus, um ein Update für die verbundene Pipeline zu starten.
Nachdem die Aktualisierung abgeschlossen ist, gibt es eine neue Tabelle im Pipelinediagramm, die von der customers_history Tabelle abhängt, und Sie können sie im unteren Bereich anzeigen. Ihre Pipeline ist jetzt fertiggestellt. Sie können sie testen, indem Sie eine vollständige Ausführungspipeline ausführen. Die einzigen Schritte, die noch ausstehen, sind, die Pipeline so zu planen, dass sie regelmäßig aktualisiert wird.
Schritt 8: Erstellen eines Auftrags zum Ausführen der ETL-Pipeline
Erstellen Sie als Nächstes einen Workflow, um die Datenaufnahme-, Verarbeitungs- und Analyseschritte in Ihrer Pipeline mithilfe eines Databricks-Auftrags zu automatisieren.
- Wählen Sie oben im Editor die Schaltfläche "Zeitplan " aus.
- Wenn das Dialogfeld " Zeitplan" angezeigt wird, wählen Sie "Zeitplan hinzufügen" aus.
- Dadurch wird das Dialogfeld " Neuer Zeitplan " geöffnet, in dem Sie einen Auftrag erstellen können, um Die Pipeline in einem Zeitplan auszuführen.
- Geben Sie optional dem Auftrag einen Namen.
- Standardmäßig ist der Zeitplan so festgelegt, dass er einmal pro Tag ausgeführt wird. Sie können diese Standardeinstellung akzeptieren oder Ihren eigenen Zeitplan festlegen. Wenn Sie "Erweitert" auswählen, haben Sie die Möglichkeit, einen bestimmten Zeitpunkt festzulegen, zu dem der Auftrag ausgeführt wird. Wenn Sie weitere Optionen auswählen , können Sie Benachrichtigungen erstellen, wenn der Auftrag ausgeführt wird.
- Wählen Sie "Erstellen" aus, um die Änderungen anzuwenden und den Auftrag zu erstellen.
Jetzt wird der Auftrag täglich ausgeführt, um Ihre Pipeline auf dem neuesten Stand zu halten. Sie können " Zeitplan" erneut auswählen, um die Liste der Zeitpläne anzuzeigen. Sie können Zeitpläne für Ihre Pipeline aus diesem Dialogfeld verwalten, einschließlich Hinzufügen, Bearbeiten oder Entfernen von Zeitplänen.
Wenn Sie auf den Namen des Zeitplans (oder Auftrags) klicken, gelangen Sie zur Seite des Auftrags in der Liste "Aufträge & Pipelines ". Von dort aus können Sie Details zu Auftragsausführungen anzeigen, einschließlich des Verlaufs der Ausführung, oder den Auftrag sofort mit der Schaltfläche " Jetzt ausführen" ausführen.
Weitere Informationen zu Auftragsausführungen finden Sie unter Überwachung und Beobachtbarkeit für Lakeflow-Aufträge.
Weitere Ressourcen
- Lakeflow Spark Deklarative Datenpipelines
- Lernprogramm: Erstellen einer ETL-Pipeline mit Lakeflow Spark Declarative Pipelines
- Ändern der Datenerfassung und Momentaufnahmen
- Die AUTO CDC-APIs: Vereinfachen der Änderungsdatenerfassung mit Pipelines
- Konvertieren einer Pipeline in ein Databricks Asset Bundle-Projekt
- Was ist das automatische Laden?