Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Tutorial zeigt Ihnen, wie man einen KI-Agenten entwickelt, der Datenabruf und Tools gemeinsam verwendet.
Hierbei handelt es sich um ein Lernprogramm auf mittlerer Ebene, in dem einige Kenntnisse über die Grundlagen des Erstellens eines Agents auf Databricks vorausgesetzt werden. Wenn Sie noch nicht mit der Erstellung von Agents vertraut sind, lesen Sie "Erste Schritte mit KI-Agents".
Das Beispielnotizbuch enthält den gesamten code, der im Lernprogramm verwendet wird.
In diesem Lernprogramm werden einige der wichtigsten Herausforderungen beim Erstellen von generativen KI-Anwendungen behandelt:
- Optimieren der Entwicklungsumgebung für allgemeine Aufgaben wie das Erstellen von Tools und debuggen der Agentausführung.
- Operative Herausforderungen wie:
- Agent-Konfiguration nachverfolgen
- Definieren von Eingaben und Ausgaben auf vorhersehbare Weise
- Verwalten von Versionen von Abhängigkeiten
- Versionssteuerung und Bereitstellung
- Messen und Verbessern der Qualität und Zuverlässigkeit eines Agenten.
Aus Gründen der Einfachheit verwendet dieses Lernprogramm einen In-Memory-Ansatz, um die Schlüsselwortsuche über ein Dataset zu ermöglichen, das in Teile gegliederte Databricks-Dokumentation enthält.
Beispielnotizbuch
Dieses eigenständige Notizbuch ist so konzipiert, dass Sie schnell mit Mosaik-KI-Agents mit einem Beispieldokumentkorpus arbeiten können. Es ist bereit zur Ausführung, ohne dass ein Setup oder Daten erforderlich sind.
Demo des Mosaic-AI-Agenten
Erstellen eines Agents und Tools
Mosaik AI Agent Framework unterstützt viele verschiedene Erstellungsframeworks. In diesem Beispiel wird LangGraph verwendet, um Konzepte zu veranschaulichen, dies ist jedoch kein LangGraph-Lernprogramm.
Beispiele für andere unterstützte Frameworks finden Sie unter Erstellen eines KI-Agents und dessen Bereitstellung auf Databricks Apps.
Der erste Schritt besteht darin, einen Agent zu erstellen. Sie müssen einen LLM-Client und eine Liste der Tools angeben. Das databricks-langchain Python-Paket enthält LangChain- und LangGraph-kompatible Clients für Databricks LLMs und Tools, die im Unity-Katalog registriert sind.
Der Endpunkt muss eine funktionsaufrufnde Foundation Model-API oder ein externes Modell sein, das AI-Gateway verwendet. Weitere Informationen finden Sie unter Unterstützte Modelle.
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
Der folgende Code definiert eine Funktion, die einen Agenten aus dem Modell und einigen Tools erstellt; die Diskussion über die inneren Abläufe dieses Agentencodes liegt außerhalb des Gültigkeitsbereichs dieser Seite. Weitere Informationen zum Erstellen eines LangGraph-Agents finden Sie in LangGraph-Dokumentation.
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
Definition von Agenten-Tools
Tools sind ein grundlegendes Konzept für Baumittel. Sie bieten die Möglichkeit, LLMs mit benutzerdefiniertem Code zu integrieren. Wenn eine Eingabeaufforderung und eine Liste von Tools bereitgestellt werden, generiert ein LLM, das Tools aufruft, die Argumente zur Nutzung des Tools. Weitere Informationen zu Tools und deren Verwendung mit Mosaik AI Agents finden Sie unter KI-Agent-Tools.
Der erste Schritt besteht darin, ein Schlüsselwortextraktionstool basierend auf TF-IDF zu erstellen. In diesem Beispiel wird scikit-learn und ein Unity-Katalogtool verwendet.
Das databricks-langchain-Paket bietet eine bequeme Möglichkeit, mit Unity-Katalogtools zu arbeiten. Der folgende Code veranschaulicht, wie ein Schlüsselwortextraktionstool implementiert und registriert wird.
Hinweis
Der Databricks-Arbeitsbereich verfügt über ein integriertes Tool, system.ai.python_execmit dem Sie Agents erweitern können, um Python-Skripts in einer Sandkastenumgebung auszuführen. Weitere nützliche integrierte Tools sind externe Verbindungen und KI-Funktionen.
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(uc_client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function's metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
Hier ist eine Erläuterung des obigen Codes:
- Erstellt einen Client, der Unity-Katalog im Databricks-Arbeitsbereich als "Registrierung" zum Erstellen und Ermitteln von Tools verwendet.
- Definiert eine Python-Funktion, die TF-IDF Schlüsselwortextraktion ausführt.
- Registriert die Python-Funktion als Unity-Katalogfunktion.
Dieser Workflow löst mehrere häufige Probleme. Sie verfügen jetzt über eine zentrale Registrierung für Tools, die wie andere Objekte im Unity-Katalog gesteuert werden können. Wenn ein Unternehmen z. B. über eine Standardmethode zum Berechnen der internen Rückgaberate verfügt, können Sie sie als Funktion im Unity-Katalog definieren und allen Benutzern oder Agents mit der rolle FinancialAnalyst Zugriff gewähren.
Um dieses Tool von einem LangChain-Agent nutzbar zu machen, verwenden Sie das UCFunctionToolkit , das eine Sammlung von Tools erstellt, die dem LLM zur Auswahl übergeben werden:
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
Der folgende Code zeigt, wie das Tool getestet wird:
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
Der folgende Code erstellt einen Agent, der das Schlüsselwortextraktionstool verwendet.
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
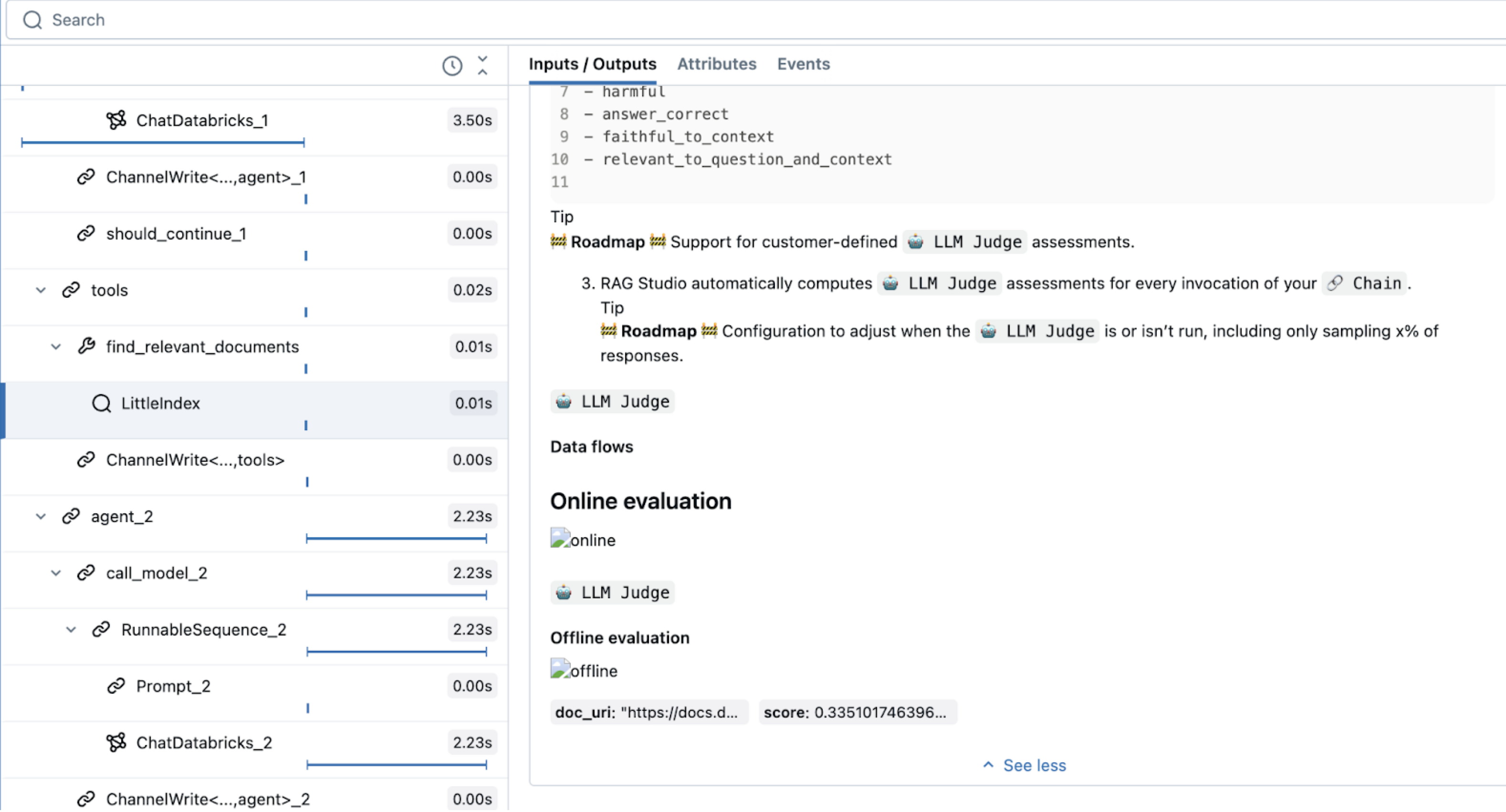
In der resultierenden Ablaufverfolgung können Sie sehen, dass die LLM das Tool ausgewählt hat.

Verwenden von Ablaufverfolgungen zum Debuggen von Agents
Die MLflow-Ablaufverfolgung ist ein leistungsstarkes Tool zum Debuggen und Beobachten von generativen KI-Anwendungen, einschließlich Agents. Es erfasst detaillierte Betriebsinformationen, indem es Spans verwendet, die bestimmte Codesegmente kapseln und Eingaben, Ausgaben und Timing-Daten aufzeichnen.
Aktivieren Sie für beliebte Bibliotheken wie LangChain die automatische Ablaufverfolgung mit mlflow.langchain.autolog(). Sie können auch mlflow.start_span() verwenden, um eine Trace anzupassen. Sie können beispielsweise benutzerdefinierte Datenwertfelder oder Beschriftungen für die Beobachtbarkeit hinzufügen. Der Code, der im Kontext dieser Spanne ausgeführt wird, wird den von Ihnen definierten Feldern zugeordnet. Geben Sie in diesem In-Memory TF-IDF-Beispiel einen Namen und einen Span-Typ an.
Weitere Informationen zu Tracing finden Sie unter MLflow Tracing – GenAI-Observability.
Im folgenden Beispiel wird ein Retriever-Tool mit einem einfachen speicherinternen TF-IDF Index erstellt. Es veranschaulicht sowohl die automatische Protokollierung für Toolausführungen als auch die benutzerdefinierte Span-Ablaufverfolgung für zusätzliche Observability:
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
Dieser Code verwendet einen speziellen Span-Typ, RETRIEVER, der für Retriever-Tools reserviert ist. Andere Mosaik-KI-Agent-Features (z. B. ai Playground, Überprüfen der Benutzeroberfläche und Auswertung) verwenden den RETRIEVER Span-Typ, um die Abrufergebnisse anzuzeigen.
Retriever-Tools erfordern, dass Sie ihr Schema angeben, um die Kompatibilität mit nachgeschalteten Databricks-Features sicherzustellen. Weitere Informationen zu mlflow.models.set_retriever_schema finden Sie unter Benutzerdefinierte Retriever-Schemas.
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
Definieren des Agents
Der nächste Schritt besteht darin, den Agent auszuwerten und für die Bereitstellung vorzubereiten. Auf hoher Ebene umfasst dies Folgendes:
- Definieren Sie eine vorhersagbare API für den Agent mithilfe einer Signatur.
- Hinzufügen der Modellkonfiguration, wodurch die Konfiguration von Parametern vereinfacht wird.
- Protokollieren Sie das Modell zusammen mit den Abhängigkeiten, die ihm eine reproduzierbare Umgebung bieten und es Ihnen ermöglichen, die Authentifizierung für andere Dienste zu konfigurieren.
Die MLflow-ChatAgent Schnittstelle vereinfacht die Definition von Agenteingaben und -ausgaben. Um ihn zu verwenden, definieren Sie Ihren Agent als Unterklasse von ChatAgent, implementieren nicht-Streaming-Ableitungen mit der predict-Funktion und Streaming-Ableitung mit der predict_stream-Funktion.
ChatAgent für Ihre Wahl des Agenterstellungsframeworks agnostisch ist, sodass Sie verschiedene Frameworks und Agentimplementierungen einfach testen und verwenden können – die einzige Anforderung besteht darin, die predict- und predict_stream-Schnittstellen zu implementieren.
Das Erstellen Ihres Agents mithilfe ChatAgent von:
- Unterstützung der Streamingausgabe
- Umfassender Nachrichtenverlauf bei Toolaufrufen: Rückgabe mehrerer Nachrichten, einschließlich zwischengeschalteter Nachrichten, für eine verbesserte Qualität und Konversationsverwaltung.
- Multi-Agent-Systemunterstützung
- Databricks-Featureintegration: Out-of-the-Box-Kompatibilität mit AI Playground, Agent Evaluation und Agent Monitoring.
- Typisierte Erstellungsschnittstellen: Schreiben Sie Agent-Code mit typisierten Python-Klassen, und nutzen Sie dabei das AutoVervollständigen von IDE und Notebook.
Weitere Informationen zum Erstellen einer ChatAgent Datei finden Sie unter Legacy-Eingabe- und Ausgabe-Agent-Schema (Model Serving).
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
Der folgende Code zeigt, wie die ChatAgentverwendet wird.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What are Pipelines in Databricks?"},
]
}
)
Konfigurieren von Agents mit Parametern
Mit dem Agent Framework können Sie die Ausführung des Agents mit Parametern steuern. Dies bedeutet, dass Sie verschiedene Agentkonfigurationen schnell testen können, z. B. das Wechseln von LLM-Endpunkten oder das Testen verschiedener Tools, ohne den zugrunde liegenden Code zu ändern.
Der folgende Code erstellt ein Konfigurationswörterbuch, das beim Initialisieren des Modells Agentparameter festlegt.
Weitere Informationen zum Parametrisieren von Agents finden Sie unter Parametrisieren von Code für die Bereitstellung in allen Umgebungen.
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-3-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
Protokollieren des Agents
Nachdem Sie den Agent definiert haben, kann er jetzt protokolliert werden. Bei MLflow bedeutet die Protokollierung eines Agents, die Konfiguration des Agents (einschließlich Abhängigkeiten) zu speichern, damit er für die Auswertung und Bereitstellung verwendet werden kann.
Hinweis
Bei der Entwicklung von Agents in einem Notizbuch leitet MLflow die Abhängigkeiten des Agents aus der Notizbuchumgebung ab.
Um einen Agent aus einem Notizbuch zu protokollieren, können Sie den gesamten Code schreiben, der das Modell in einer einzelnen Zelle definiert, und dann den %%writefile magischen Befehl verwenden, um die Definition des Agents in einer Datei zu speichern:
%%writefile agent.py
...
<Code that defines the agent>
Wenn der Agent Zugriff auf externe Ressourcen benötigt, z. B. Unity Catalog, um das Schlüsselwortextraktionstool auszuführen, müssen Sie die Authentifizierung für den Agent konfigurieren, damit er bei der Bereitstellung auf die Ressourcen zugreifen kann.
Um die Authentifizierung für Databricks-Ressourcen zu vereinfachen, aktivieren Sie die automatische Authentifizierungsdurchlauf:
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
Weitere Informationen zu Logging-Agenten finden Sie unter Codebasierte Protokollierung.
Den Agenten auswerten
Der nächste Schritt besteht darin, den Agent auszuwerten, um zu sehen, wie er ausgeführt wird. Die Agent-Auswertung ist eine Herausforderung und stellt viele Fragen auf, z. B. die folgenden:
- Was sind die richtigen Metriken zur Bewertung der Qualität? Wie vertraue ich auf die Ausgaben dieser Metriken?
- Ich muss viele Ideen auswerten - wie kann ich...
- die Auswertung schnell ausführen, sodass die meiste Zeit nicht mit dem Warten verbracht wird?
- Vergleichen Sie schnell die verschiedenen Versionen meines Agents nach Qualität, Kosten und Latenz.
- Wie kann ich schnell die Ursache von Qualitätsproblemen identifizieren?
Als Data Scientist oder Entwickler sind Sie möglicherweise nicht der eigentliche Fachexperte. Der Rest dieses Abschnitts beschreibt Die Tools zur Agentauswertung, mit denen Sie eine gute Ausgabe definieren können.
Erstellen Sie einen Auswertungssatz
Um zu definieren, welche Qualität für einen Agent bedeutet, verwenden Sie Metriken, um die Leistung des Agents für einen Auswertungssatz zu messen. Siehe Definieren von "Qualität": Auswertungssätze.
Mit der Agent-Auswertung können Sie synthetische Auswertungssätze erstellen und die Qualität messen, indem Sie Auswertungen ausführen. Die Idee besteht darin, aus den Fakten zu beginnen, wie z. B. eine Reihe von Dokumenten, und "rückwärts arbeiten", indem sie diese Fakten verwenden, um eine Reihe von Fragen zu generieren. Sie können die generierten Fragen beeinflussen, indem Sie einige Richtlinien vorgeben.
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
Die generierten Auswertungen umfassen Folgendes:
Ein Anforderungsfeld, das wie die zuvor erwähnte
ChatAgentRequestaussieht:{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]}Eine Liste der "erwarteten abgerufenen Inhalte". Das Retriever-Schema wurde mit
content- unddoc_uriFeldern definiert.[{"content":"If your workspace's [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}]Eine Liste der erwarteten Fakten. Wenn Sie zwei Antworten vergleichen, kann es schwierig sein, kleine Unterschiede zwischen ihnen zu finden. Erwartete Fakten klären, was eine richtige Antwort von einer teilweise richtigen oder falschen Antwort unterscheidet und verbessern sowohl die Qualität der KI-Richter als auch die Erfahrung der Personen, die am Agent arbeiten.
["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."]Ein source_id-Feld, das hier
SYNTHETIC_FROM_DOCist. Wenn Sie umfassendere Auswertungssätze erstellen, stammen die Beispiele aus verschiedenen Quellen, sodass dieses Feld sie unterscheidet.
Weitere Informationen zum Erstellen von Auswertungssätzen finden Sie unter Synthetizerauswertungssätze.
Bewerten des Agents mithilfe von LLM-Richtern
Die manuelle Auswertung der Leistung eines Agents für so viele generierte Beispiele lässt sich nicht gut skalieren. Im großen Maßstab ist die Verwendung von LLMs als Richter eine viel vernünftigere Lösung. Verwenden Sie den folgenden Code, um die integrierten Richter zu verwenden, die bei der Verwendung der Agentauswertung verfügbar sind:
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
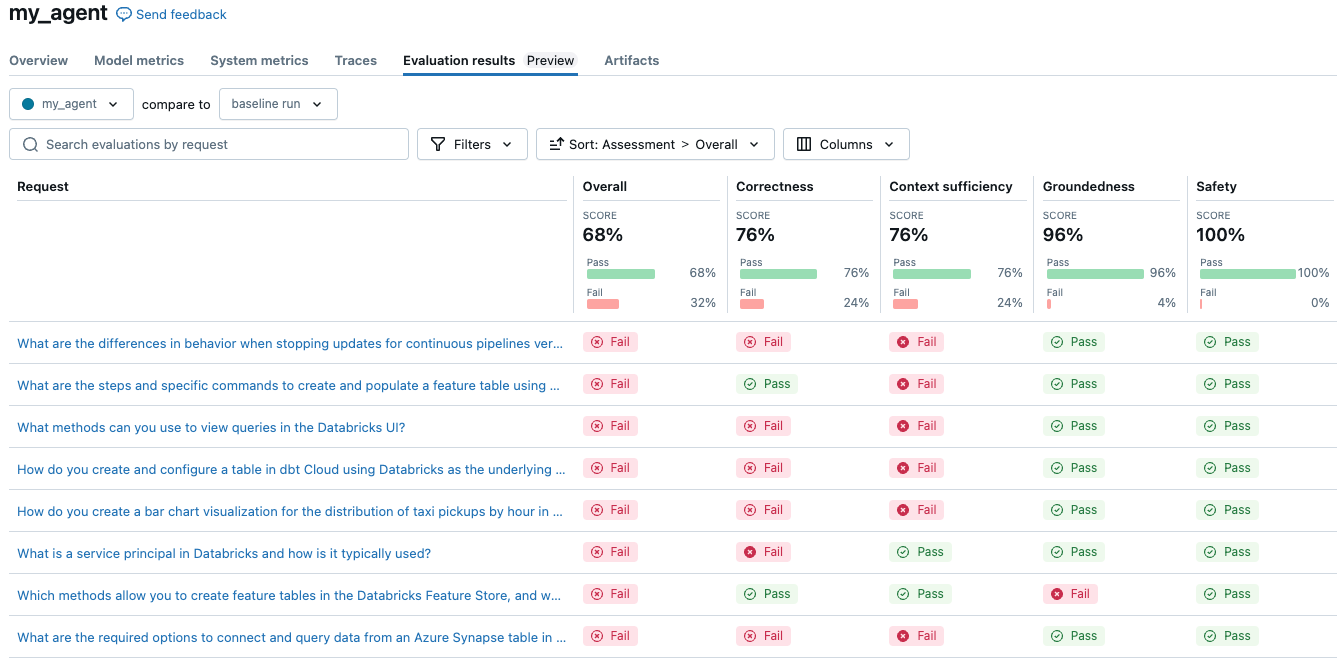
Der einfache Agent hat insgesamt 68 % bewertet. Ihre Ergebnisse können sich je nach der verwendeten Konfiguration hier unterscheiden. Das Ausführen eines Experiments zum Vergleichen von drei verschiedenen LLMs für Kosten und Qualität ist so einfach wie das Ändern der Konfiguration und erneute Auswertung.
Erwägen Sie, die Modellkonfiguration so zu ändern, dass eine andere LLM-, Systemaufforderungs- oder Temperatureinstellung verwendet wird.
Diese Richter können angepasst werden, um die gleichen Richtlinien zu befolgen, die menschliche Experten verwenden würden, um eine Antwort zu bewerten. Weitere Informationen zu LLM-Richtern finden Sie unter Integrierte KI-Richter (MLflow 2).
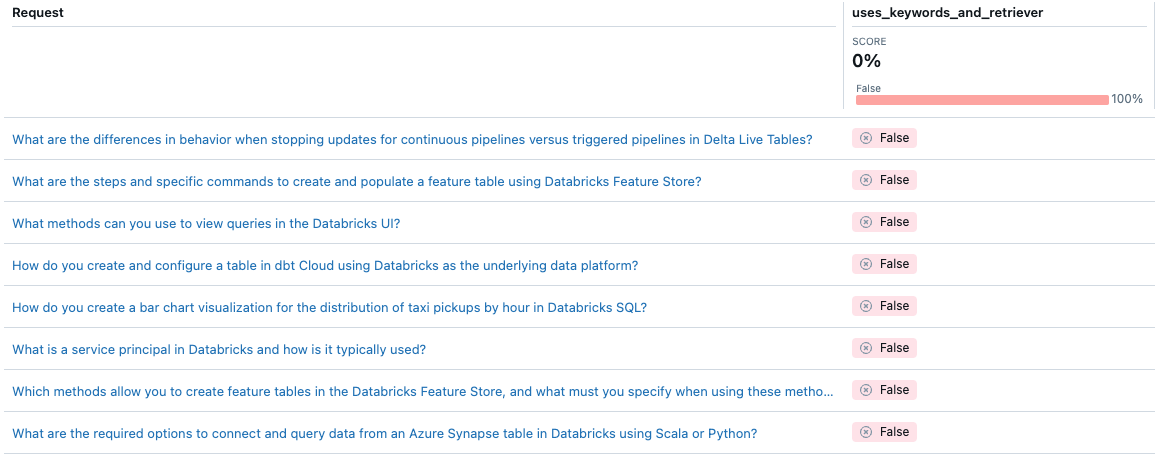
Mit der Agentenevaluierung können Sie anpassen, wie Sie die Qualität eines bestimmten Agenten mithilfe von benutzerdefinierten Metrikenmessen. Sie können sich die Auswertung wie einen Integrationstest und einzelne Metriken als Komponententests vorstellen. Im folgenden Beispiel wird eine boolesche Metrik verwendet, um zu überprüfen, ob der Agent sowohl die Schlüsselwortextraktion als auch den Retriever für eine bestimmte Anforderung verwendet:
from databricks.agents.evals import metric
@metric
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
Beachten Sie, dass der Agent niemals die Schlüsselwortextraktion verwendet. Wie können Sie dieses Problem beheben?
Bereitstellen und Überwachen des Agents
Wenn Sie bereit sind, Ihren Agent mit echten Benutzern zu testen, bietet Agent Framework eine produktionsfähige Lösung für die Bereitstellung des Agents auf Mosaik AI Model Serving.
Die Bereitstellung von Agents für die Modellbereitstellung bietet die folgenden Vorteile:
- Die Modellbereitstellung verwaltet die automatische Skalierung, Protokollierung, Versionssteuerung und Zugriffssteuerung, sodass Sie sich auf die Entwicklung von Qualitäts-Agents konzentrieren können.
- Experten können die Prüf-App verwenden, um mit dem Agenten zu interagieren und Feedback zu geben, das in Ihre Überwachung und Auswertung integriert werden kann.
- Sie können den Agent überwachen, indem Sie Auswertungen zum Live-Datenverkehr ausführen. Obwohl der Datenverkehr keine Ground Truth enthält, führen die Richter der LLMs (und die von Ihnen erstellte benutzerdefinierte Metrik) eine unbeaufsichtigte Bewertung durch.
Der folgende Code stellt die Agents auf einem Dienst-Endpoint bereit. Weitere Informationen finden Sie unter Bereitstellen eines Agents für generative KI-Anwendungen (Model Serving).
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)