Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie eine unstrukturierte Datenpipeline für KI-Anwendungen der Generation erstellen. Unstrukturierte Pipelines eignen sich besonders für Retrieval-Augmented Generation (RAG)-Anwendungen.
Erfahren Sie, wie Sie unstrukturierte Inhalte wie Textdateien und PDF-Dateien in einen Vektorindex konvertieren, den KI-Agents oder andere Retriever abfragen können. Außerdem lernen Sie, wie Sie Ihre Pipeline durch Experimente und Optimierungen verbessern, um Daten zu unterteilen, zu indizieren und zu analysieren, sodass Sie die Pipeline bei Problemen anpassen und weiter experimentieren können, um bessere Ergebnisse zu erzielen.
Unstrukturiertes Daten-Pipeline-Notizbuch
Das folgende Notizbuch zeigt, wie Sie die Informationen in diesem Artikel implementieren, um eine unstrukturierte Datenpipeline zu erstellen.
Datenbricks unstrukturierte Datenpipeline
Wichtige Komponenten der Datenpipeline
Die Grundlage jeder RAG-Anwendung mit unstrukturierten Daten ist die Datenpipeline. Diese Pipeline ist für das Zusammenstellen und Vorbereiten der unstrukturierten Daten in einem Format verantwortlich, das die RAG-Anwendung effektiv nutzen kann.

Obwohl diese Datenpipeline je nach Anwendungsfall komplex werden kann, sind die wichtigsten Komponenten, die Sie beim ersten Erstellen Ihrer RAG-Anwendung berücksichtigen müssen:
- Korpuskomposition und Erfassung: Wählen Sie die richtigen Datenquellen und Inhalte basierend auf dem jeweiligen Anwendungsfall aus.
-
Vorverarbeitung von Daten: Transformieren Sie Rohdaten in ein sauberes, konsistentes Format, das zum Einbetten und Abrufen geeignet ist.
- Analyse: Extrahieren sie relevante Informationen aus den Rohdaten mithilfe geeigneter Analysetechniken.
-
Anreicherung: Anreichern von Daten mit zusätzlichen Metadaten und Entfernen von Rauschen.
- Metadatenextraktion: Extrahieren Sie hilfreiche Metadaten, um schnellere und effizientere Datenabrufe zu implementieren.
- Deduplizierung: Analysieren Sie die Dokumente, um Duplikate oder nahezu duplizierte Dokumente zu identifizieren und zu beseitigen.
- Filtern: Entfernen Sie irrelevante oder unerwünschte Dokumente aus der Sammlung.
- Blöcke: Unterteilen Sie die analysierten Daten in kleinere, verwaltbare Blöcke, um einen effizienten Abruf zu ermöglichen.
- Einbetten: Konvertieren Sie die geblockten Textdaten in eine numerische Vektordarstellung, die ihre semantische Bedeutung erfasst.
- Indizierung und Speicher: Erstellen Sie effiziente Vektorindizes für eine optimierte Suchleistung.
Korpuszusammensetzung und Aufnahme
Ihre RAG-Anwendung kann die erforderlichen Informationen nicht abrufen, um eine Benutzerabfrage ohne den richtigen Datenkorpus zu beantworten. Die richtigen Daten hängen vollständig von den spezifischen Anforderungen und Zielen Ihrer Anwendung ab, wodurch es entscheidend ist, zeitaufwendig zu sein, um die Nuancen der verfügbaren Daten zu verstehen. Weitere Informationen finden Sie im Workflow für generative KI-App-Entwickler.
Wenn Sie beispielsweise einen Kundensupport-Bot erstellen, können Sie Folgendes einschließen:
- Dokumente der Wissensdatenbank
- Häufig gestellte Fragen (FAQs)
- Produkthandbücher und -spezifikationen
- Leitfäden zur Problembehandlung
Binden Sie Domänenexperten und Projektbeteiligte von Anfang an ein, um relevante Inhalte zu identifizieren und zu zusammenstellen, die die Qualität und Abdeckung Ihres Datenkorpus verbessern können. Sie können Einblicke in die Arten von Abfragen liefern, die Benutzer wahrscheinlich übermitteln und dabei helfen, die wichtigsten Informationen einzuschließen.
Databricks empfiehlt, Daten auf skalierbare und inkrementelle Weise aufzunehmen. Azure Databricks bietet verschiedene Methoden für die Datenaufnahme, einschließlich vollständig verwalteter Connectors für SaaS-Anwendungen und API-Integrationen. Als bewährte Methode sollten rohe Quelldaten aufgenommen und in einer Zieltabelle gespeichert werden. Mit diesem Ansatz wird sichergestellt, dass Daten erhalten, nachverfolgt und überprüft werden. Siehe Standardanschlüsse in Lakeflow Connect.
Vorverarbeitung von Daten
Nachdem die Daten aufgenommen wurden, ist es wichtig, die Rohdaten in ein einheitliches Format zu bereinigen und zu formatieren, das zum Einbetten und Abrufen geeignet ist.
Syntaxanalyse
Nachdem Sie die entsprechenden Datenquellen für Ihre Retriever-Anwendung identifiziert haben, extrahiert der nächste Schritt die erforderlichen Informationen aus den Rohdaten. Dieser Prozess, der als Analyse bezeichnet wird, umfasst das Transformieren der unstrukturierten Daten in ein Format, das die RAG-Anwendung effektiv verwenden kann.
Welche spezifischen Analysetechniken und Tools Sie dabei verwenden, hängt von der Art der Daten ab, mit denen Sie arbeiten. Zum Beispiel:
- Textdokumente (PDFs, Word-Dokumente): Standardbibliotheken wie unstructured und PyPDF2 können verschiedene Dateiformate verarbeiten und bieten Anpassungsoptionen für den Analyseprozesses.
- HTML-Dokumente: HTML-Analysebibliotheken wie BeautifulSoup und lxml können verwendet werden, um relevante Inhalte aus Webseiten zu extrahieren. Diese Bibliotheken können dabei helfen, in der HTML-Struktur zu navigieren, bestimmte Elemente auszuwählen und den gewünschten Text oder die gewünschten Attribute zu extrahieren.
- Bilder und gescannte Dokumente: Optische Zeichenerkennungstechniken (OCR) sind in der Regel erforderlich, um Text aus Bildern zu extrahieren. Beliebte OCR-Bibliotheken umfassen Open Source-Bibliotheken wie Tesseract oder SaaS-Versionen wie Amazon Textract, Azure AI Vision OCR und Google Cloud Vision API.
Bewährte Methoden für die Datenanalyse
Die Analyse stellt sicher, dass die Daten sauber, strukturiert und bereit für die Erstellung von Einbettungen und Vektorsuchen sind. Berücksichtigen Sie beim Analysieren Ihrer Daten die folgenden bewährten Methoden:
- Datenreinigung: Stellen Sie den extrahierten Text vor, um irrelevante oder laute Informationen wie Kopfzeilen, Fußzeilen oder Sonderzeichen zu entfernen. Verringern Sie die Menge an unnötigen oder falsch formatierten Informationen, die Ihre RAG-Kette verarbeiten muss.
- Behandlung von Fehlern und Ausnahmen: Implementieren Sie Fehlerbehandlungs- und Protokollierungsmechanismen, um während des Analyseprozesses aufgetretene Probleme zu identifizieren und zu beheben. Dies hilft Ihnen, Probleme schnell zu identifizieren und zu beheben. Häufig werden Sie so auf vorgelagerte Probleme mit der Qualität der Quelldaten aufmerksam.
- Anpassung der Analyselogik: Je nach Struktur und Format Ihrer Daten müssen Sie ggf. die Analyselogik anpassen, um die relevantesten Informationen zu extrahieren. Es kann zwar vorab zusätzlichen Aufwand erfordern, aber investieren Sie die Zeit, um dies bei Bedarf zu tun, da es häufig viele nachgelagerte Qualitätsprobleme verhindert.
- Bewertung der Analysequalität: Bewerten Sie regelmäßig die Qualität der analysierten Daten durch manuelle Stichproben der Ausgabe. Dies kann Ihnen dabei helfen, Probleme oder Verbesserungspotenziale im Zusammenhang mit dem Analyseprozess zu identifizieren.
Anreicherung
Bereichern Sie Daten mit zusätzlichen Metadaten, und entfernen Sie Rauschen. Obwohl die Anreicherung optional ist, kann sie die Gesamtleistung Ihrer Anwendung drastisch verbessern.
Metadatenextraktion
Das Generieren und Extrahieren von Metadaten, die wichtige Informationen zu Inhalt, Kontext und Struktur des Dokuments erfassen, kann die Abrufqualität und Leistung einer RAG-Anwendung erheblich verbessern. Metadaten bieten zusätzliche Signale, die die Relevanz verbessern, erweiterte Filterung ermöglichen und domänenspezifische Suchanforderungen unterstützen.
Während Bibliotheken wie LangChain und LlamaIndex integrierte Parser bereitstellen, die automatisch zugeordnete Standardmetadaten extrahieren können, ist es häufig hilfreich, dies mit benutzerdefinierten Metadaten zu ergänzen, die auf Ihren spezifischen Anwendungsfall zugeschnitten sind. Mit diesem Ansatz wird sichergestellt, dass kritische domänenspezifische Informationen erfasst und nachgelagerte Abrufe und Erzeugung verbessert werden. Sie können auch große Sprachmodelle (LLMs) verwenden, um die Metadatenerweiterung zu automatisieren.
Zu den Metadatentypen gehören:
- Metadaten auf Dokumentebene: Dateiname, URLs, Autoreninformationen, Erstellungs- und Änderungszeitstempel, GPS-Koordinaten und Dokumentversionsverwaltung.
- Inhaltsbasierte Metadaten: Extrahierte Schlüsselwörter, Zusammenfassungen, Themen, benannte Entitäten und domänenspezifische Tags (Produktnamen und Kategorien wie PII oder HIPAA).
- Strukturelle Metadaten: Abschnittsüberschriften, Inhaltsverzeichnis, Seitenzahlen und semantische Inhaltsgrenzen (Kapitel oder Unterabschnitte).
- Kontextmetadaten: Quellsystem, Aufnahmedatum, Datenempfindlichkeitsstufe, Originalsprache oder transnationale Anweisungen.
Das Speichern von Metadaten neben geblockten Dokumenten oder deren entsprechenden Einbettungen ist für eine optimale Leistung unerlässlich. Es hilft auch, die abgerufenen Informationen einzugrenzen und die Genauigkeit und Skalierbarkeit Ihrer Anwendung zu verbessern. Darüber hinaus kann die Integration von Metadaten in Hybridsuchpipelinen, was bedeutet, dass die Kombination der Vektor-Ähnlichkeitssuche mit schlüsselwortbasierter Filterung die Relevanz verbessern kann, insbesondere in großen Datasets oder bestimmten Suchkriterienszenarien.
Deduplizierung
Je nach Ihren Quellen können Sie mit doppelten Dokumenten oder in der Nähe von Duplikaten enden. Wenn Sie beispielsweise von einem oder mehreren freigegebenen Laufwerken ziehen, können mehrere Kopien desselben Dokuments an mehreren Speicherorten vorhanden sein. Einige dieser Kopien können subtile Änderungen aufweisen. Ebenso kann Ihre Knowledge Base Kopien Ihrer Produktdokumentation oder Entwürfe von Blogbeiträgen haben. Wenn diese Duplikate in Ihrem Korpus verbleiben, können Sie in Ihrem endgültigen Index mit hoch redundanten Blöcken enden, die die Leistung Ihrer Anwendung verringern können.
Sie können einige Duplikate allein mithilfe von Metadaten beseitigen. Wenn ein Element beispielsweise denselben Titel und das Erstellungsdatum aufweist, aber mehrere Einträge aus verschiedenen Quellen oder Speicherorten vorhanden sind, können Sie diese basierend auf den Metadaten filtern.
Dies reicht jedoch möglicherweise nicht aus. Um Duplikate basierend auf dem Inhalt der Dokumente zu identifizieren und zu beseitigen, können Sie eine Technik verwenden, die als lokal vertraulichen Hashing bezeichnet wird. Eine Technik namens "MinHash " funktioniert hier gut, und eine Spark-Implementierung ist bereits in Spark ML verfügbar. Es funktioniert, indem ein Hash für das Dokument basierend auf den darin enthaltenen Wörtern erstellt und dann Duplikate oder nahezu Duplikate durch Verknüpfen mit diesen Hashes effizient identifiziert werden können. Auf sehr hoher Ebene ist dies ein vierstufiger Prozess:
- Erstellen Sie einen Featurevektor für jedes Dokument. Ziehen Sie bei Bedarf Techniken wie die Entfernung von Stoppwörtern, Stemming und Lemmatisierung in Betracht, um die Ergebnisse zu verbessern, und führen Sie anschließend eine Tokenisierung zu n-Grammen durch.
- Passen Sie ein MinHash-Modell an und hashen Sie die Vektoren mithilfe von MinHash für Jaccard-Entfernung.
- Führen Sie einen Ähnlichkeitsabgleich mit diesen Hashes aus, um ein Ergebnisset für jedes Duplikat oder fast doppeltes Dokument zu erzeugen.
- Filtern Sie die Duplikate, die Sie nicht beibehalten möchten.
Ein grundlegender Deduplizierungsschritt kann die Dokumente beliebig auswählen, die aufbewahrt werden sollen (z. B. das erste Dokument in den Ergebnissen jedes Duplikats oder eine zufällige Auswahl unter den Duplikaten). Eine potenzielle Verbesserung wäre das Auswählen der "besten" Version des Duplikats mithilfe anderer Logik (z. B. zuletzt aktualisiert, Publikationsstatus oder autoritative Quelle). Beachten Sie außerdem, dass Sie möglicherweise mit dem Featurierungsschritt und der Anzahl der Hashtabellen experimentieren müssen, die im MinHash-Modell verwendet werden, um die übereinstimmenden Ergebnisse zu verbessern.
Weitere Informationen finden Sie in der Spark-Dokumentation zu lokalitätsabhängigem Hashing.
Filtern
Einige der Dokumente, die Sie in Ihren Korpus aufnehmen, sind möglicherweise nicht für Ihren Agenten nützlich, entweder weil sie für ihren Zweck irrelevant sind, zu alt oder unzuverlässig sind oder weil sie problematische Inhalte wie schädliche Sprache enthalten. Dennoch können andere Dokumente vertrauliche Informationen enthalten, die Sie nicht über Ihren Agent verfügbar machen möchten.
Daher sollten Sie einen Schritt in Ihre Pipeline einbeziehen, um diese Dokumente mithilfe von Metadaten herauszufiltern, z. B. das Anwenden eines Toxizitätsklassifizierers auf das Dokument, um eine Vorhersage zu erzeugen, die Sie als Filter verwenden können. Ein weiteres Beispiel wäre das Anwenden eines PII-Erkennungsalgorithmus (Personally Identifiable Information) auf die Dokumente zum Filtern von Dokumenten.
Schließlich sind alle Dokumentquellen, die Sie in Ihren Agent eingeben, potenzielle Angriffsvektoren für schlechte Akteure, um Datenvergiftungsangriffe zu starten. Sie können auch erwägen, Erkennungs- und Filtermechanismen hinzuzufügen, um diese zu identifizieren und zu beseitigen.
Chunking
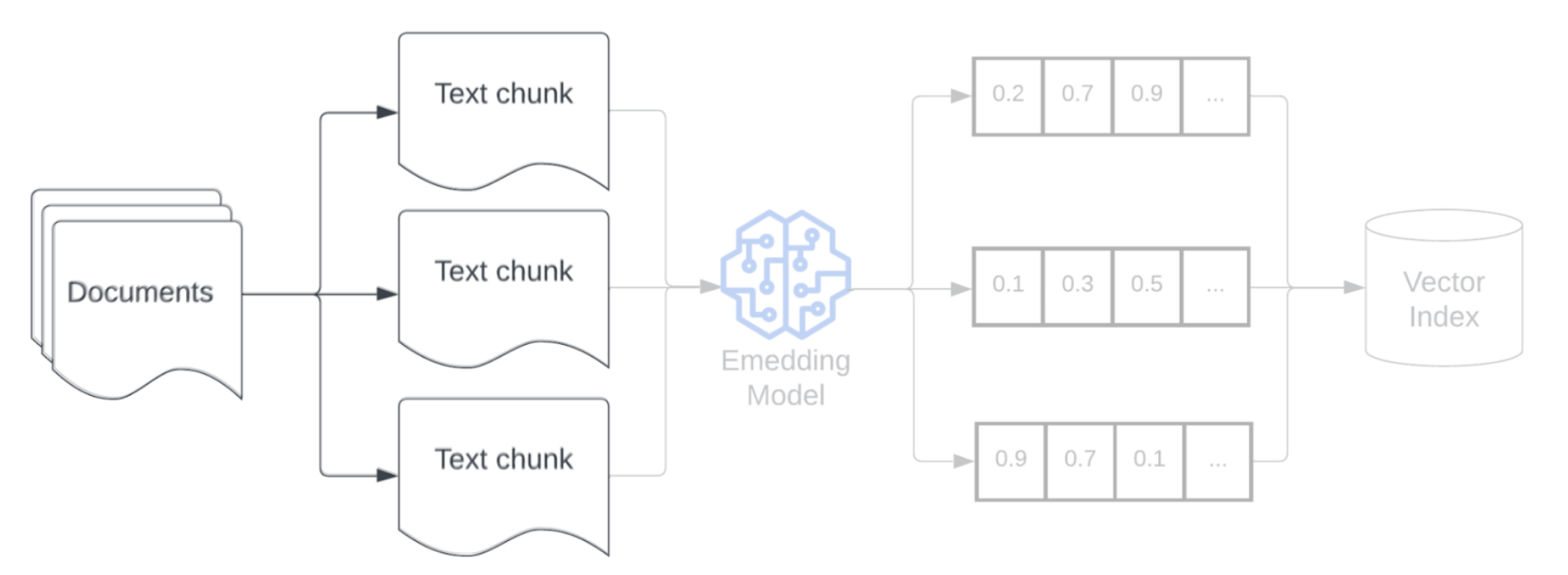
Nach dem Analysieren der Rohdaten in ein strukturiertes Format, das Entfernen von Duplikaten und das Filtern unerwünschter Informationen besteht der nächste Schritt darin, sie in kleinere, verwaltbare Einheiten aufzuteilen, die als Blöcke bezeichnet werden. Durch das Segmentieren großer Dokumente in kleinere, semantisch konzentrierte Blöcke wird sichergestellt, dass abgerufene Daten in den Kontext des LLM passen und gleichzeitig die Einbeziehung von ablenkenden oder irrelevanten Informationen minimieren. Die Entscheidungen, die beim Chunking getroffen werden, wirken sich direkt auf die abgerufenen Daten aus, die die LLM bereitstellt, wodurch es eine der ersten Stufen der Optimierung in einer RAG-Anwendung ausmacht.
Berücksichtigen Sie bei der Segmentierung Ihrer Daten folgende Faktoren:
- Segmentierungsstrategie: Die Methode, mit der der ursprüngliche Text in Blöcke aufgeteilt wird. Dies kann grundlegende Techniken wie das Aufteilen nach Sätzen, Absätzen, bestimmten Zeichen-/Tokenanzahlen und komplexeren dokumentspezifischen Aufteilungsstrategien umfassen.
- Blockgröße: Kleinere Blöcke konzentrieren sich möglicherweise auf bestimmte Details, verlieren jedoch einige kontextbezogene Informationen. Größere Blöcke erfassen möglicherweise mehr Kontext, können aber irrelevante Informationen enthalten oder rechenintensiv sein.
- Überlappung von Blöcken: Um sicherzustellen, dass bei der Aufteilung der Daten in Blöcke keine wichtigen Informationen verloren gehen, empfiehlt sich gegebenenfalls eine gewisse Überlappung von benachbarten Blöcken. Überlappende Vorgänge können die Erhaltung von Kontinuität und Kontext in Blöcken gewährleisten und die Abrufergebnisse verbessern.
- Semantische Kohärenz: Ziel ist es, semantisch kohärente Blöcke zu erstellen, die verwandte Informationen enthalten, aber unabhängig voneinander als sinnvolle Texteinheit stehen können. Berücksichtigen Sie hierzu die Struktur der ursprünglichen Daten wie Absätze, Abschnitte oder Themengrenzen.
- Metadaten:Relevante Metadaten, z. B. der Name des Quelldokuments, die Abschnittsüberschrift oder produktnamen, können den Abruf verbessern. Diese zusätzlichen Informationen können helfen, Abrufabfragen mit Datenblöcken abzugleichen.
Datensegmentierungsstrategien
Die Suche nach der richtigen Segmentierungsmethode ist sowohl iterativ als auch kontextabhängig. Es gibt keinen Ansatz, der für alle passt. Die optimale Blockgröße und -methode hängt vom jeweiligen Anwendungsfall und der Art der verarbeiteten Daten ab. Im Allgemeinen können Chunking-Strategien wie folgt betrachtet werden:
- Segmentierung mit fester Größe: Bei dieser Strategie wird der Text in Blöcke mit einer vordefinierten Größe aufgeteilt – also etwa mit einer festen Anzahl von Zeichen oder Token (z. B. LangChain CharacterTextSplitter). Die Aufteilung nach einer beliebigen Anzahl von Zeichen/Token ist zwar schnell und einfach einzurichten, führt aber in der Regel nicht zu konsistenten, semantisch kohärenten Blöcken. Dieser Ansatz funktioniert selten für Anwendungen auf Produktionsniveau.
- Absatzbasierte Segmentierung: Bei dieser Strategie werden die natürlichen Absatzgrenzen im Text verwendet, um Blöcke zu definieren. Diese Methode kann dazu beitragen, die semantische Kohärenz der Blöcke beizubehalten, da Absätze häufig verwandte Informationen enthalten (z. B. LangChain RecursiveCharacterTextSplitter).
- Formatspezifische Blöcke: Formate wie Markdown oder HTML weisen eine inhärente Struktur auf, die Blockgrenzen definieren kann (z. B. Markdownheader). Tools wie der LangChain MarkdownHeaderTextSplitter oder die HTML header/section-basierten Splitter können zu diesem Zweck verwendet werden.
- Semantische Segmentierung: Techniken wie Themenmodellierungstechniken können angewendet werden, um semantisch kohärente Abschnitte im Text zu identifizieren. Diese Ansätze analysieren den Inhalt oder die Struktur jedes Dokuments, um die am besten geeigneten Abschnittsgrenzen basierend auf Themenverschiebungen zu ermitteln. Obwohl komplexer als grundlegende Ansätze, kann semantisches Chunking helfen, Blöcke zu erstellen, die stärker den natürlichen semantischen Unterteilungen im Text entsprechen (z. B. LangChain SemanticChunker).
Beispiel: Blöcke mit fester Größe
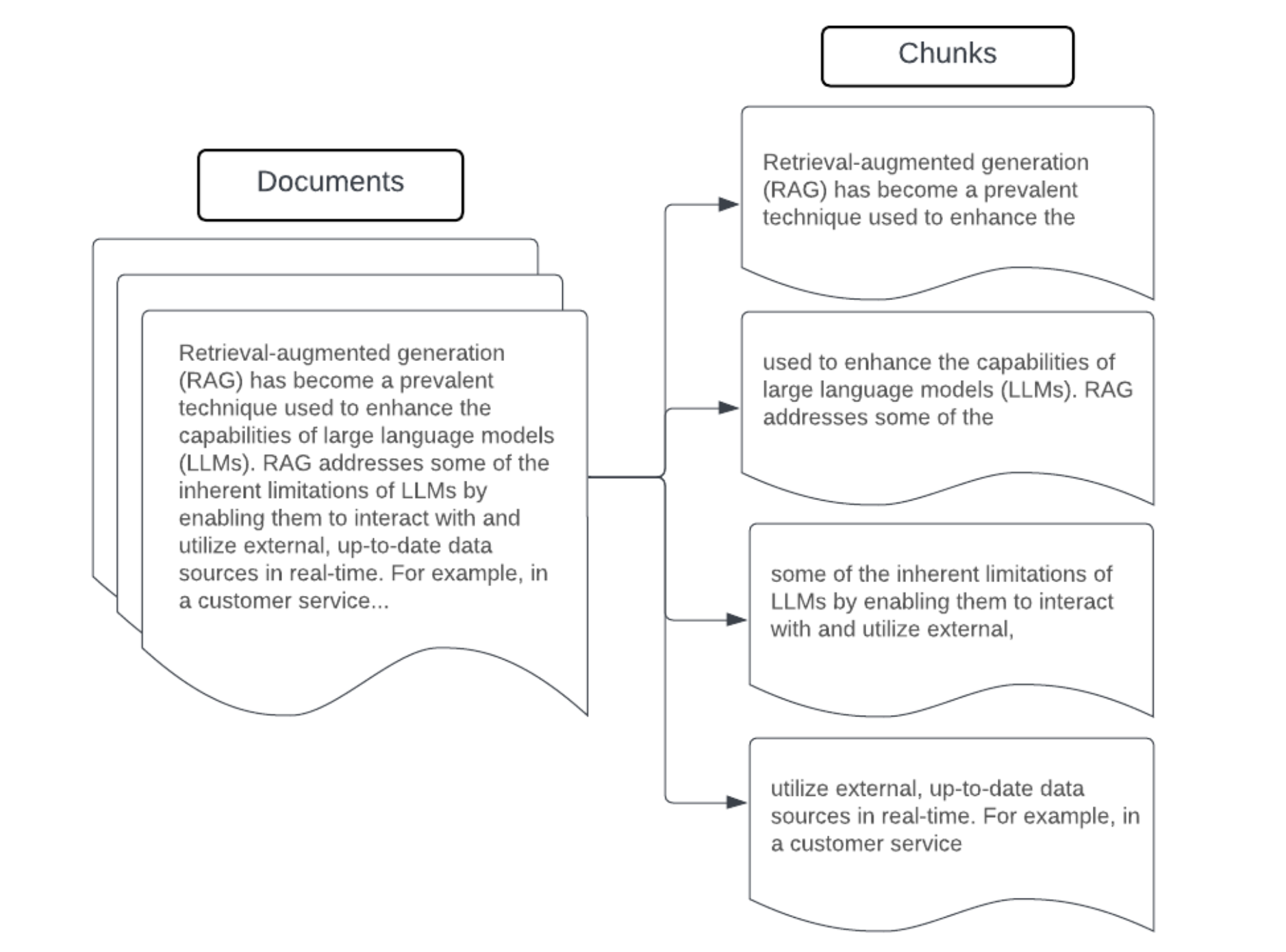
Chunking-Beispiel mit fester Blockgröße mithilfe von LangChains RecursiveCharacterTextSplitter mit chunk_size=100 und chunk_overlap=20. ChunkViz bietet eine interaktive Möglichkeit, zu visualisieren, wie verschiedene Chunkgrößen und Überlappungswerte von Langchain's Zeichensplittern die resultierenden Chunks beeinflussen.
Einbettung
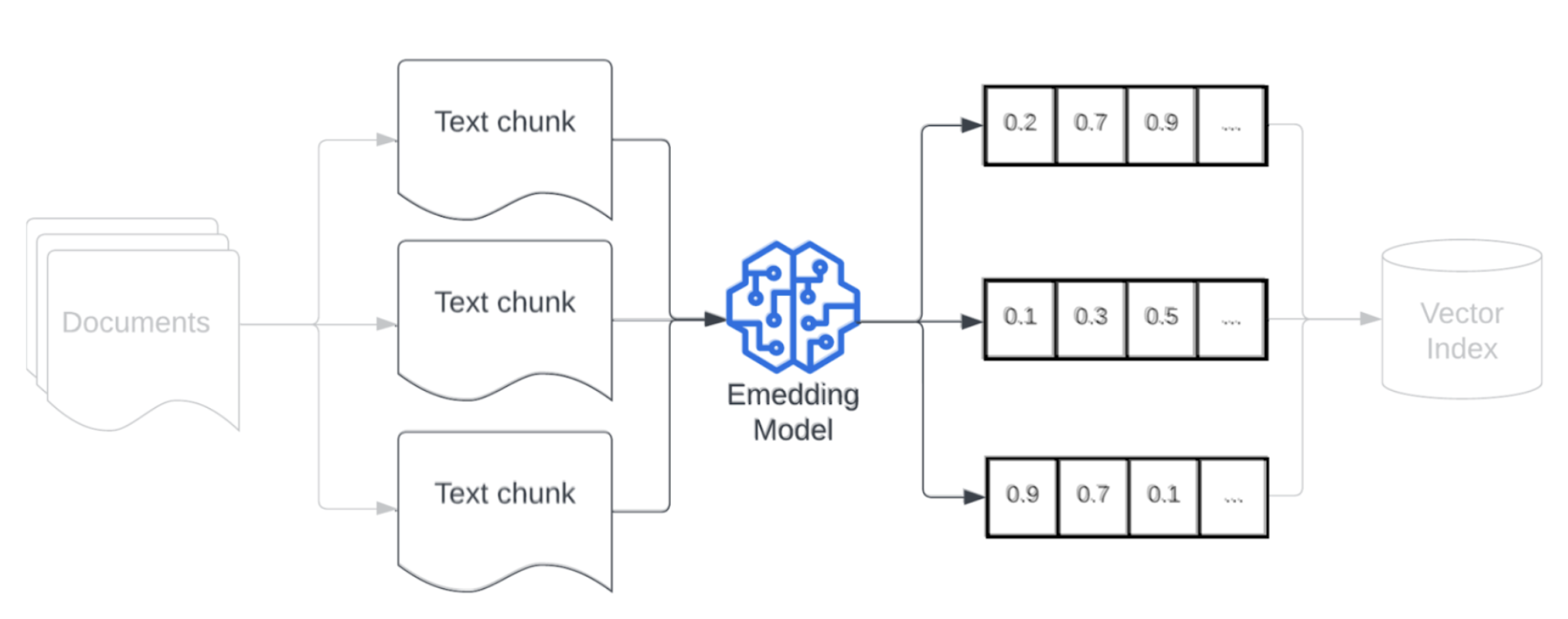
Nach der Segmentierung Ihrer Daten müssen die Textblöcke mithilfe eines Einbettungsmodells in eine Vektordarstellung konvertiert werden. Ein Einbettungsmodell konvertiert jeden Textabschnitt in eine Vektordarstellung, die seine semantische Bedeutung erfasst. Durch die Darstellung von Blöcken als dichte Vektoren ermöglichen Einbettungen einen schnellen und präzisen Abruf der relevantesten Blöcke basierend auf ihrer semantischen Ähnlichkeit mit einer Abrufabfrage. Die Abrufabfrage wird zur Abfragezeit mithilfe des gleichen Einbettungsmodells transformiert, das zum Einbetten von Datenblöcken in der Datenpipeline verwendet wird.
Berücksichtigen Sie bei der Wahl eines Einbettungsmodells folgende Faktoren:
- Modellauswahl: Jedes Einbettungsmodell verfügt über Nuancen, und die verfügbaren Benchmarks erfassen möglicherweise nicht die spezifischen Merkmale Ihrer Daten. Es ist entscheidend, ein Modell auszuwählen, das auf ähnliche Daten trainiert wurde. Es kann auch von Vorteil sein, alle verfügbaren Einbettungsmodelle zu untersuchen, die für bestimmte Aufgaben entwickelt wurden. Experimentieren Sie mit verschiedenen Standard-Einbettungsmodellen (auch mit solchen, die ggf. auf Standardbestenlisten wie MTEB niedriger bewertet sind). Einige Beispiele, die Sie berücksichtigen sollten:
- Max. Token: Kennen Sie die maximale Tokengrenze für Das ausgewählte Einbettungsmodell. Wenn Sie Blöcke übergeben, die diesen Grenzwert überschreiten, werden sie abgeschnitten. Dadurch gehen möglicherweise wichtige Informationen verloren. Die Tokenobergrenze von bge-large-en-v1.5 liegt beispielsweise bei 512 Token.
- Modellgröße: Größere Einbettungsmodelle funktionieren im Allgemeinen besser, erfordern jedoch mehr Rechenressourcen. Basierend auf Ihrem spezifischen Anwendungsfall und verfügbaren Ressourcen müssen Sie leistung und Effizienz ausgleichen.
- Feinabstimmung: Wenn Sich Ihre RAG-Anwendung mit domänenspezifischen Sprachen (z. B. internen Unternehmens akronyme oder Terminologie) befasst, sollten Sie das Einbettungsmodell auf domänenspezifische Daten optimieren. Dies kann dazu beitragen, dass das Modell die Nuancen und Terminologie Ihrer jeweiligen Domäne besser erfassen kann und häufig zu einer verbesserten Abrufleistung führen kann.
Indizierung und Speicher
Der nächste Schritt in der Pipeline besteht darin, Indizes für die Einbettungen und die in den vorherigen Schritten generierten Metadaten zu erstellen. In dieser Phase werden hochdimensionale Vektoreinbettungen in effiziente Datenstrukturen organisiert, die schnelle und genaue Ähnlichkeitssuchen ermöglichen.
Mosaik AI Vector Search verwendet die neuesten Indizierungstechniken, wenn Sie einen Vektorsuchendpunkt und einen Index bereitstellen, um schnelle und effiziente Nachschlagevorgänge für Ihre Vektorsuchabfragen sicherzustellen. Sie müssen sich keine Gedanken über Das Testen und Auswählen der besten Indizierungstechniken machen.
Nachdem Ihr Index erstellt und bereitgestellt wurde, kann er in einem System gespeichert werden, das skalierbare Abfragen mit geringer Latenz unterstützt. Verwenden Sie für PRODUKTIONS-RAG-Pipelines mit großen Datasets eine Vektordatenbank oder einen skalierbaren Suchdienst, um eine niedrige Latenz und einen hohen Durchsatz sicherzustellen. Speichern Sie zusätzliche Metadaten zusammen mit Einbettungen, um eine effiziente Filterung während des Abrufs zu ermöglichen.