Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Lernprogramm führt Sie durch die Verwendung eines Azure Databricks-Notizbuchs zum Importieren von Daten aus einer CSV-Datei mit Babynamendaten aus health.data.ny.gov in Ihr Unity-Katalogvolume mithilfe von Python, Scala und R. Außerdem lernen Sie, einen Spaltennamen zu ändern, die Daten zu visualisieren und in einer Tabelle zu speichern.
Hinweis
Wenn Sie Databricks Free Edition verwenden, wählen Sie die Python-Registerkarte für alle Codebeispiele in diesem Lernprogramm aus. Free Edition unterstützt R oder Scala nicht. Darüber hinaus schränkt Free Edition den ausgehenden Internetzugriff ein, sodass Sie die CSV-Datei mithilfe der Arbeitsbereichsbenutzeroberfläche hochladen müssen, anstatt sie mit Code herunterzuladen. Ausführliche Anweisungen finden Sie in Schritt 3 .
Anforderungen
Um die Aufgaben in diesem Artikel abzuschließen, müssen die folgenden Anforderungen erfüllt sein:
- Ihr Arbeitsbereich muss Unity-Katalog aktiviert haben. Informationen zu den ersten Schritten mit Dem Unity-Katalog finden Sie unter "Erste Schritte mit Unity-Katalog". Azure Databricks Free Edition und kostenlose Testarbeitsbereiche haben unity Catalog standardmäßig aktiviert.
- Sie müssen das
WRITE VOLUME-Recht für ein Volume, dasUSE SCHEMA-Recht für das übergeordnete Schema und dasUSE CATALOG-Recht für den übergeordneten Katalog haben. Free Edition-Benutzer verfügen standardmäßig über diese Berechtigungen für den Arbeitsbereichskatalog unddefaultdas Schema. - Sie müssen über die Berechtigung verfügen, eine vorhandene Computeressource zu verwenden oder eine neue Computeressource zu erstellen. Siehe "Compute" oder kontaktieren Sie Ihren Azure Databricks-Administrator.
Tipp
Ein vollständiges Notizbuch für diesen Artikel finden Sie unter Importieren und Visualisieren von Datennotizbüchern.
Schritt 1: Erstellen eines neuen Notebooks
Wenn Sie ein Notizbuch in Ihrem Arbeitsbereich erstellen möchten, klicken Sie in der Randleiste auf ![]() neu ", und klicken Sie dann auf " Notizbuch". Im Arbeitsbereich wird ein leeres Notebook geöffnet.
neu ", und klicken Sie dann auf " Notizbuch". Im Arbeitsbereich wird ein leeres Notebook geöffnet.
Weitere Informationen zum Erstellen und Verwalten von Notizbüchern finden Sie unter "Verwalten von Datenbricks-Notizbüchern".
Schritt 2: Definieren von Variablen
In diesem Schritt definieren Sie Variablen für die Verwendung im Beispiel-Notebook, das Sie in diesem Artikel erstellen. Sie benötigen die Namen eines Unity-Katalogkatalogs, -Schemas und -Volumes.
Tipp
Wenn Sie Ihren Katalog- und Schemanamen nicht kennen, klicken Sie auf das ![]() Katalog in der Randleiste. Der Arbeitsbereichskatalog trägt denselben Namen wie Ihr Arbeitsbereich und wird im Katalogfenster angezeigt. Erweitern Sie sie, um verfügbare Schemas anzuzeigen. Benutzer der kostenlosen Edition und der kostenlosen Testversion können den Arbeitsbereich-Katalog und das
Katalog in der Randleiste. Der Arbeitsbereichskatalog trägt denselben Namen wie Ihr Arbeitsbereich und wird im Katalogfenster angezeigt. Erweitern Sie sie, um verfügbare Schemas anzuzeigen. Benutzer der kostenlosen Edition und der kostenlosen Testversion können den Arbeitsbereich-Katalog und das default-Schema verwenden.
Wenn Sie kein Volume haben, erstellen Sie ein Volume, indem Sie den folgenden Befehl in einer Notizbuchzelle ausführen (ersetzen Sie <catalog_name> und <schema_name> durch Ihre Werte):
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Ersetzen Sie
<catalog-name>,<schema-name>und<volume-name>durch die Katalog-, Schema- und Volumenamen für ein Unity Catalog-Volume. Ersetzen Sie optional dentable_name-Wert durch einen Tabellennamen Ihrer Wahl. Sie speichern die Babynamendaten in dieser Tabelle weiter unten in diesem Artikel.Drücken Sie
Shift+Enter, um die Zelle auszuführen und eine neue leere Zelle zu erstellen.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Schritt 3: Importieren der CSV-Datei
In diesem Schritt importieren Sie eine CSV-Datei mit Babynamendaten aus health.data.ny.gov in Ihr Unity Catalog-Volume. Wählen Sie eine der folgenden Methoden:
- Hochladen mithilfe der Arbeitsbereichsbenutzeroberfläche – Verwenden Sie diese Methode, wenn Sie databricks Free Edition verwenden oder wenn der Codedownload in Option B mit einem Netzwerkfehler fehlschlägt. Free Edition und andere serverlose Computeumgebungen beschränken den ausgehenden Internetzugriff, sodass Sie die Datei von Ihrem lokalen Computer hochladen müssen.
- Herunterladen mit Code – Verwenden Sie diese Methode, wenn Ihre Computeumgebung über ausgehenden Internetzugriff verfügt.
Option A: Hochladen mit der Arbeitsbereichs-UI
- Öffnen Sie auf Ihrem lokalen Computer health.data.ny.gov/api/views/jxy9-yhdk/rows.csv in Ihrem Browser. Die Datei wird auf Ihren Computer heruntergeladen als
rows.csv. - Suchen Sie die heruntergeladene Datei auf Ihrem Computer, und benennen Sie sie von
rows.csvinbaby_names.csvum. Dies entspricht derfile_nameVariablen, die Sie in Schritt 2 definiert haben. - Kehren Sie zu Ihrem Azure Databricks-Arbeitsbereich zurück. Klicken Sie in der Randleiste auf
 Neu > hinzufügen" oder "Daten hochladen".
Neu > hinzufügen" oder "Daten hochladen". - Klicken Sie auf "Dateien auf ein Volume hochladen".
- Klicken Sie auf "Durchsuchen ", und wählen Sie die
baby_names.csvDatei aus, oder ziehen Sie sie in den Uploadbereich. - Wählen Sie unter "Zielvolume" das Volume aus, das Sie in Schritt 2 angegeben haben.
- Kehren Sie nach Abschluss des Uploads zu Ihrem Notizbuch zurück, und fahren Sie mit Schritt 4 fort.
Weitere Informationen zum Hochladen von Dateien finden Sie unter "Arbeiten mit Dateien in Unity-Katalogvolumes".
Option B: Herunterladen mit Code
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Dieser Code kopiert die
rows.csvDatei aus health.data.ny.gov mithilfe des Befehls "Databricks dbutils " in Ihr Unity-Katalogvolume.Drücken Sie
Shift+Enter, um die Zelle auszuführen, und wechseln Sie dann zur nächsten Zelle.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Schritt 4: Laden von CSV-Daten in einen Datenrahmen
In diesem Schritt erstellen Sie einen Datenrahmen namens df aus der CSV-Datei, die Sie zuvor in Ihr Unity Catalog-Volume geladen haben, indem Sie die Methode spark.read.csv verwenden.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Dieser Code lädt Babynamendaten aus der CSV-Datei in den Datenrahmen
df.Drücken Sie
Shift+Enter, um die Zelle auszuführen, und wechseln Sie dann zur nächsten Zelle.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Sie können Daten aus vielen unterstützten Dateiformaten laden.
Schritt 5: Visualisieren von Daten aus einem Notebook
In diesem Schritt verwenden Sie die Methode display(), um den Inhalt des Datenrahmens in einer Tabelle im Notebook anzuzeigen, und visualisieren dann die Daten in einem Wortwolkendiagramm im Notebook.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notizbuchzelle ein, und klicken Sie dann auf "Zelle ausführen ", um die Daten in einer Tabelle anzuzeigen.
Python
display(df)Scala
display(df)R
display(df)Überprüfen Sie die Ergebnisse in der Tabelle.
Klicken Sie neben der Registerkarte "Tabelle " auf + "Visualisierung", und klicken Sie dann auf "Visualisierung".
Klicken Sie im Visualisierungs-Editor auf "Visualisierungstyp", und vergewissern Sie sich, dass die Word-Cloud ausgewählt ist.
Überprüfen Sie in der Spalte "Wörter", ob
First Namesie ausgewählt ist.Klicken Sie in der Häufigkeitsgrenze auf
35.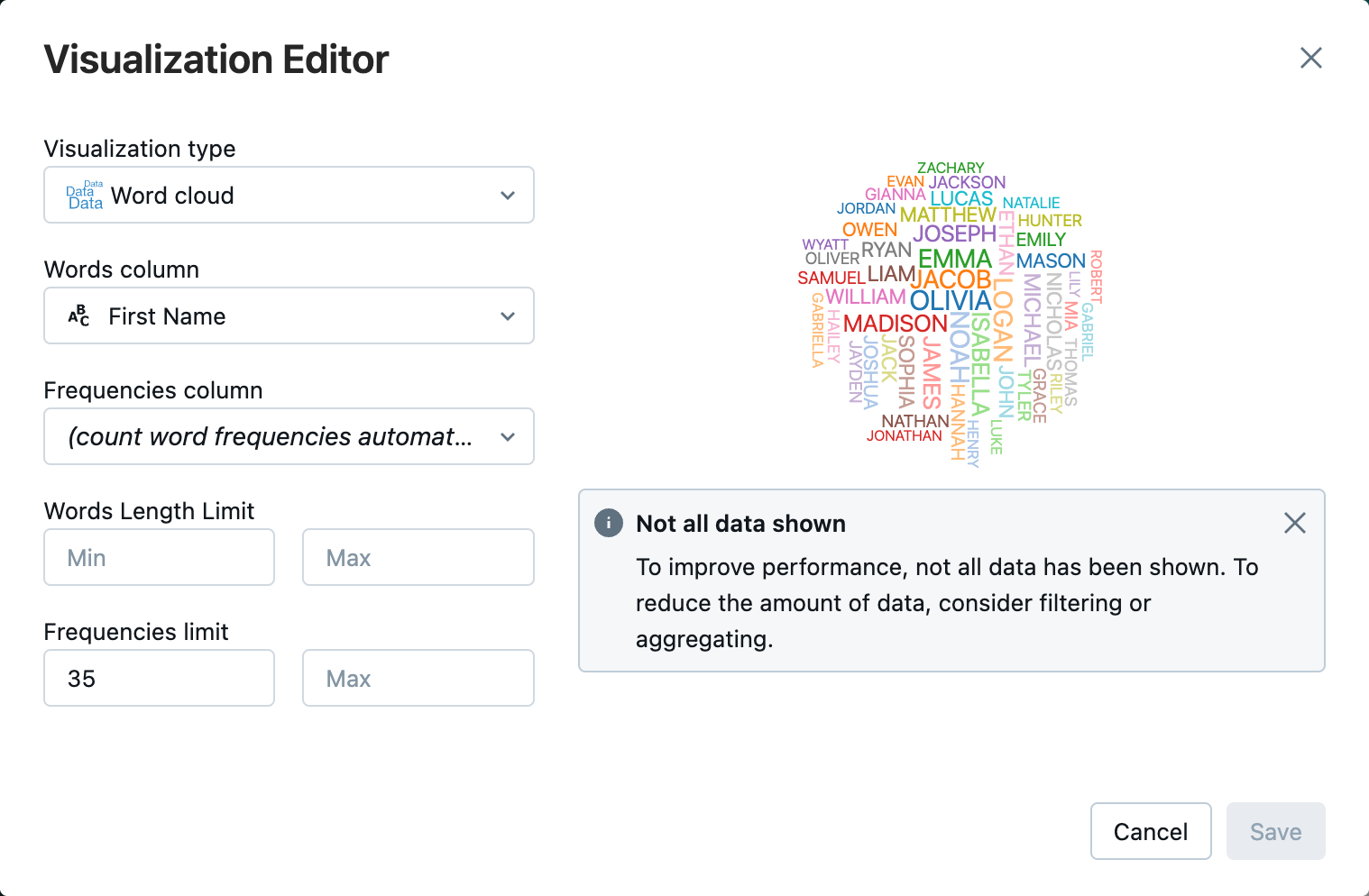
Klicken Sie auf "Speichern".
Schritt 6: Speichern des DataFrame in einer Tabelle
Wichtig
Um Ihren DataFrame im Unity Catalog zu speichern, benötigen Sie Tabellenprivilegien CREATE für den Katalog und das Schema. Informationen zu Berechtigungen im Unity-Katalog finden Sie unter "Berechtigungen" und "Sicherungsobjekte" im Unity-Katalog und "Berechtigungen verwalten" im Unity-Katalog.
Kopieren Sie den folgenden Code, und fügen Sie ihn in eine leere Notebookzelle ein. Dieser Code ersetzt ein Leerzeichen im Spaltennamen. Sonderzeichen, z. B. Leerzeichen, sind in Spaltennamen nicht zulässig. Dieser Code verwendet die Apache Spark-Methode
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Kopieren Sie den folgenden Code, und fügen Sie ihn in eine leere Notebookzelle ein. Dieser Code speichert den Inhalt des Datenrahmens in einer Tabelle in Unity Catalog mithilfe der Tabellennamenvariablen, die Sie am Anfang dieses Artikels definiert haben.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Um zu überprüfen, ob die Tabelle gespeichert wurde, klicken Sie in der linken Randleiste auf "Katalog ", um die Benutzeroberfläche des Katalog-Explorers zu öffnen. Öffnen Sie Ihren Katalog und dann das Schema, um zu überprüfen, ob die Tabelle angezeigt wird.
Klicken Sie auf die Tabelle, um das Tabellenschema auf der Registerkarte "Übersicht " anzuzeigen.
Klicken Sie auf "Beispieldaten ", um 100 Datenzeilen aus der Tabelle anzuzeigen.
Daten-Notebooks importieren und visualisieren
Verwenden Sie eines der folgenden Notebooks, um die Schritte in diesem Artikel auszuführen. Ersetzen Sie <catalog-name>, <schema-name> und <volume-name> durch die Katalog-, Schema- und Volumenamen für ein Unity Catalog-Volume. Ersetzen Sie optional den table_name-Wert durch einen Tabellennamen Ihrer Wahl.
Python
Importieren von Daten aus CSV mithilfe des Python
Scala
Importieren von Daten aus CSV mithilfe des Scala
R
Importieren von Daten aus CSV mithilfe des R
Nächste Schritte
- Informationen zu explorativen Datenanalysetechniken (EDA) finden Sie im Lernprogramm: EDA-Techniken mithilfe von Databricks-Notizbüchern.
- Informationen zum Erstellen einer ETL-Pipeline (Extrahieren, Transformieren und Laden) finden Sie im Lernprogramm: Erstellen einer ETL-Pipeline mit Lakeflow-Pipelines und Tutorial: Erstellen einer ETL-Pipeline mit Apache Spark auf der Databricks-Plattform