Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Lernprogramm führt Sie durch die Verwendung eines Azure Databricks-Notizbuchs zum Abfragen von Beispieldaten, die im Unity-Katalog mit SQL, Python, Scala und R gespeichert sind, und visualisieren dann die Abfrageergebnisse im Notizbuch.
Tip
Weisen Sie Genie Code (Agent-Modus) an, dies für Sie zu tun.
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
Anforderungen
Um die Aufgaben in diesem Artikel abzuschließen, müssen die folgenden Anforderungen erfüllt sein:
- Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein. Informationen zu den ersten Schritten mit Dem Unity-Katalog finden Sie unter "Erste Schritte mit Unity-Katalog".
- Sie müssen über die Berechtigung verfügen, eine vorhandene Computeressource zu verwenden oder eine neue Computeressource zu erstellen. Siehe Compute oder wenden Sie sich an Ihren Databricks-Administrator.
Schritt 1: Erstellen eines neuen Notebooks
Wenn Sie ein Notebook in Ihrem Arbeitsbereich erstellen möchten, wählen Sie in der Randleiste ![]() Neu aus, und wählen Sie dann Notebook aus. Im Arbeitsbereich wird ein leeres Notebook geöffnet.
Neu aus, und wählen Sie dann Notebook aus. Im Arbeitsbereich wird ein leeres Notebook geöffnet.
Weitere Informationen zum Erstellen und Verwalten von Notizbüchern finden Sie unter "Verwalten von Datenbricks-Notizbüchern".
Schritt 2: Abfragen einer Tabelle
Fragen Sie die Tabelle samples.nyctaxi.trips in Unity Catalog mithilfe Ihrer bevorzugten Sprache ab. Diese Tabelle ist eines der Beispiel-Datasets , die samples im Katalog enthalten sind.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die neue leere Notebookzelle ein. Dieser Code zeigt die Ergebnisse der Abfrage der Tabelle
samples.nyctaxi.tripsin Unity Catalog an.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Drücken Sie
Shift+Enter, um die Zelle auszuführen, und wechseln Sie dann zur nächsten Zelle.Die Abfrageergebnisse werden im Notebook angezeigt.
Schritt 3: Anzeigen der Daten
Zeigen Sie den durchschnittlichen Fahrpreis nach Fahrstrecke an, gruppiert nach der Postleitzahl des Startpunkts.
Klicken Sie neben der Registerkarte Tabelle auf + und klicken Sie dann auf Visualisierung.
Der Visualisierungs-Editor wird angezeigt.
Vergewissern Sie sich, dass in der Dropdownliste VisualisierungstypBalken ausgewählt ist.
Wählen Sie
fare_amountfür die X-Spalte aus.Wählen Sie
trip_distancefür die Y-Spalte aus.Wählen Sie
Averageals Aggregationstyp aus.Wählen Sie
pickup_zipals Gruppieren nach-Spalte aus.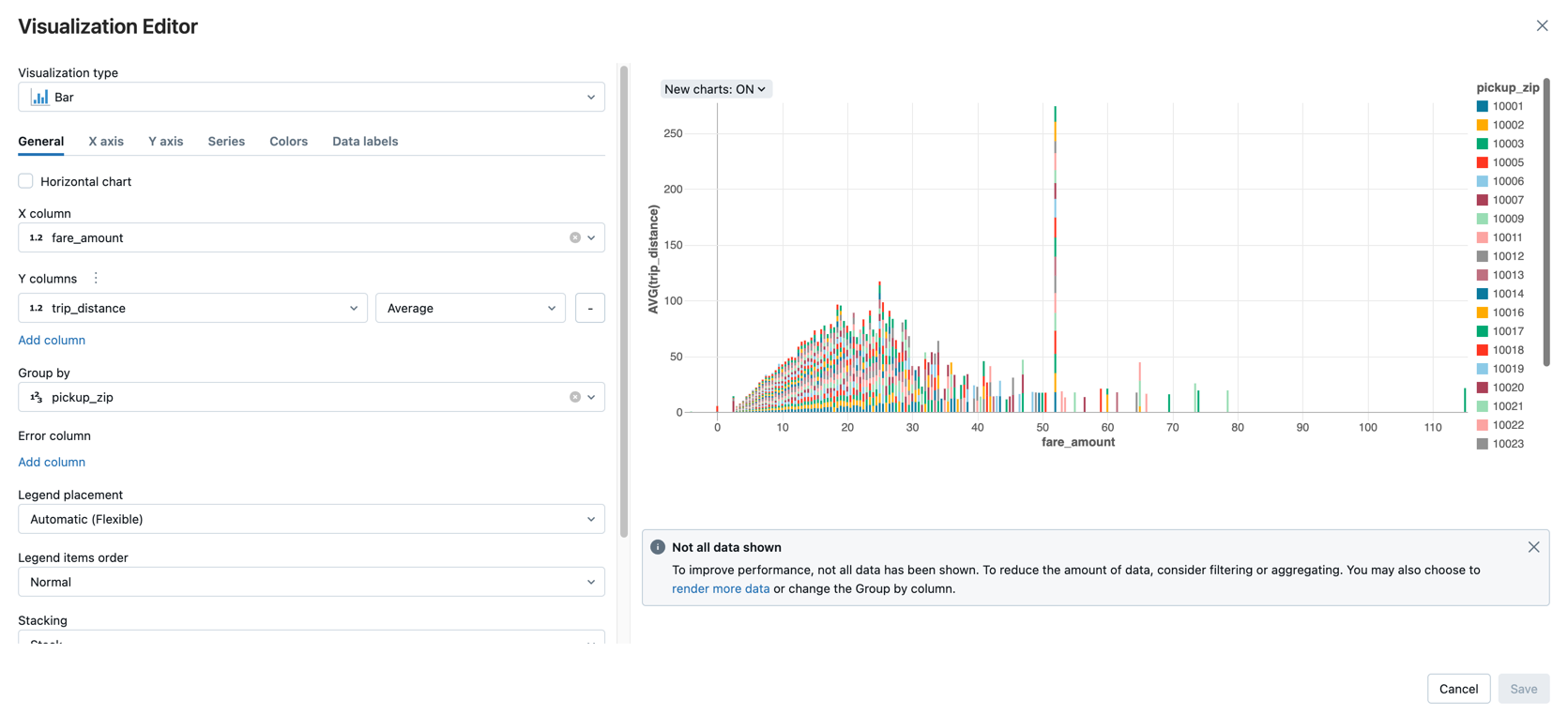
Klicken Sie auf Speichern.
Nächste Schritte
- Informationen zum Hinzufügen von Daten aus der CSV-Datei zum Unity-Katalog und zum Visualisieren von Daten finden Sie im Lernprogramm: Importieren und Visualisieren von CSV-Daten aus einem Notizbuch.
- Weitere Informationen zum Laden von Daten in Databricks mit Apache Spark finden Sie im Tutorial: Laden und Transformieren von Daten mithilfe von Apache Spark-DataFrames.
- Weitere Informationen über die Datenerfassung in Databricks finden Sie unter Standardconnectors in Lakeflow Connect.
- Weitere Informationen zum Abfragen von Daten mit Databricks finden Sie unter Abfragen von Daten.
- Weitere Informationen zu Visualisierungen finden Sie unter Visualisierungen in Databricks-Notizbüchern und SQL-Editor.
- Weitere Informationen zu explorativen Datenanalysetechniken (EDA) finden Sie im Lernprogramm: EDA-Techniken mithilfe von Databricks-Notizbüchern.