Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Dieses Feature ist Beta und ist in den folgenden Regionen verfügbar: us-east-1 und us-west-2.
Mit den deklarativen APIs des Feature Stores können Sie zeitfensterbasierte Aggregationsmerkmale aus Datenquellen definieren und berechnen. In diesem Leitfaden werden die folgenden Workflows behandelt:
-
Workflow für die Featureentwicklung
- Verwenden Sie
create_feature, um Featureobjekte des Unity-Katalogs zu definieren, die in Modellschulungen und beim Servieren von Workflows verwendet werden können.
- Verwenden Sie
-
Modellschulungsworkflow
- Verwenden Sie
create_training_set, um Punkt-in-Zeit aggregierte Merkmale für maschinelles Lernen zu berechnen. Dadurch wird ein Trainingssatzobjekt zurückgegeben, das einen Spark DataFrame mit berechneten Features zurückgeben kann, die dem Beobachtungsdatensatz für das Training eines Modells hinzugefügt wurden. - Rufen Sie
log_modelmit diesem Schulungssatz auf, um dieses Modell im Unity-Katalog zusammen mit der Linie zwischen Feature- und Modellobjekten zu speichern. -
score_batchverwendet Unity Catalog-Abstammung, um den Featuredefinitionscode für korrekt punktuelle Zeit-Feature-Aggregationen zu nutzen, die zum Inferenz-Dataset für die Bewertung des Modells erweitert werden.
- Verwenden Sie
-
Arbeitsablauf zur Feature-Verarbeitung und Bereitstellung
- Nachdem Sie ein Feature mit
create_featuredefiniert oder es mitget_featureabgerufen haben, können Siematerialize_featuresverwenden, um das Feature oder die Gruppe von Features in einem Offline-Store für eine effiziente Wiederverwendung oder einem Online-Store für Onlinedienste zu materialisieren. - Verwenden Sie
create_training_setmit der materialisierten Sicht, um einen Offline-Batch-Trainingsdatensatz vorzubereiten.
- Nachdem Sie ein Feature mit
Ausführliche Dokumentationen zu log_model und score_batch, finden Sie unter "Verwenden von Features zum Trainieren von Modellen".
Anforderungen
Ein klassischer Computecluster mit Databricks Runtime 17.0 ML oder höher.
Sie müssen das benutzerdefinierte Python-Paket installieren. Die folgenden Codezeilen müssen jedes Mal ausgeführt werden, wenn ein Notizbuch ausgeführt wird:
%pip install databricks-feature-engineering>=0.14.0 dbutils.library.restartPython()
Schnellstartbeispiel
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering.entities import DeltaTableSource, Sum, Avg, ContinuousWindow, OfflineStoreConfig
from datetime import timedelta
CATALOG_NAME = "main"
SCHEMA_NAME = "feature_store"
TABLE_NAME = "transactions"
# 1. Create data source
source = DeltaTableSource(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
table_name=TABLE_NAME,
entity_columns=["user_id"],
timeseries_column="transaction_time"
)
# 2. Define features
fe = FeatureEngineeringClient()
features = [
fe.create_feature(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
name="avg_transaction_30d",
source=source,
inputs=["amount"],
function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=30))
),
fe.create_feature(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
source=source,
inputs=["amount"],
function=Sum(),
time_window=ContinuousWindow(window_duration=timedelta(days=7))
# name auto-generated: "amount_sum_continuous_7d"
),
]
# 3. Create training set using declarative features
`labeled_df` should have columns "user_id", "transaction_time", and "target". It can have other context features specific to the individual observations.
training_set = fe.create_training_set(
df=labeled_df,
features=features,
label="target",
)
training_set.load_df().display() # action: joins labeled_df with computed feature
# 4. Train model
with mlflow.start_run():
training_df = training_set.load_df()
# training code
fe.log_model(
model=model,
artifact_path="recommendation_model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=f"{CATALOG_NAME}.{SCHEMA_NAME}.recommendation_model",
)
# 5. (Optional) Materialize features for serving
fe.materialize_features(
features=features,
offline_config=OfflineStoreConfig(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
table_name_prefix="customer_features"
),
pipeline_state="ACTIVE",
cron_schedule="0 0 * * * ?" # Hourly
)
Hinweis
Nach der Materialisierung von Features können Sie die Modelle mit CPU-Modellbereitstellung bereitstellen. Ausführliche Informationen zur Online-Bereitstellung finden Sie unter Materialisieren und Bereitstellen deklarativer Features.
Datenquellen
DeltaTableSource
Hinweis
Zulässige Datentypen für timeseries_column: TimestampType, DateType. Andere ganzzahlige Datentypen können funktionieren, verursachen jedoch einen Genauigkeitsverlust für Zeitfensteraggregate.
Der folgende Code zeigt ein Beispiel mit der Tabelle aus dem main.analytics.user_events Unity-Katalog:
from databricks.feature_engineering.entities import DeltaTableSource
source = DeltaTableSource(
catalog_name="main", # Catalog name
schema_name="analytics", # Schema name
table_name="user_events", # Table name
entity_columns=["user_id"], # Join keys, used to look up features for an entity
timeseries_column="event_time" # Timestamp for time windows
)
Deklarative Feature-API
create_feature()-API
FeatureEngineeringClient.create_feature() bietet umfassende Validierung und stellt eine ordnungsgemäße Funktionskonstruktion sicher:
FeatureEngineeringClient.create_feature(
source: DataSource, # Required: DeltaTableSource
inputs: List[str], # Required: List of column names from the source
function: Union[Function, str], # Required: Aggregation function (Sum, Avg, Count, etc.)
time_window: TimeWindow, # Required: TimeWindow for aggregation
catalog_name: str, # Required: The catalog name for the feature
schema_name: str, # Required: The schema name for the feature
name: Optional[str], # Optional: Feature name (auto-generated if omitted)
description: Optional[str], # Optional: Feature description
filter_condition: Optional[str], # Optional: SQL WHERE clause to filter source data
) -> Feature
Parameter:
-
source: Die datenquelle, die in der Featureberechnung verwendet wird -
inputs: Liste der Spaltennamen aus der Quelle, die als Eingabe für die Aggregation verwendet werden sollen -
function: Die Aggregationsfunktion (Funktionsinstanz oder Zeichenfolgenname). Siehe Liste der unterstützten Funktionen unten. -
time_window: Das Zeitfenster für die Aggregation (TimeWindow-Instanz oder Diktat mit 'Dauer' und optionalem 'Offset') -
catalog_name: Der Katalogname für das Feature -
schema_name: Der Schemaname für das Feature -
name: Optionaler Featurename (automatisch generiert, wenn nicht angegeben) -
description: Optionale Beschreibung des Features -
filter_condition: Optionale SQL-Klausel WHERE zum Filtern von Quelldaten vor der Aggregation. Beispiel:"status = 'completed'","transaction" = "Credit" AND "amount > 100"
Gibt: Eine überprüfte Feature-Instanz
Wirft: ValueError, wenn eine Überprüfung fehlschlägt
Automatisch generierte Namen
Wenn name Dieser Parameter nicht angegeben wird, folgen Namen dem Muster: {column}_{function}_{window}. Beispiel:
-
price_avg_continuous_1h(1-Stunden-Durchschnittspreis) -
transaction_count_continuous_30d_1d(30-Tage-Anzahl der Transaktionen mit 1-Tages-Offset ab dem Ereigniszeitstempel)
Unterstützte Funktionen
Hinweis
Alle Funktionen werden über ein Aggregationszeitfenster angewendet, wie im abschnitt " Zeitfenster " unten beschrieben.
| Funktion | Kurzschrift | Description | Beispiel eines Anwendungsfalls |
|---|---|---|---|
Sum() |
"sum" |
Summe der Werte | Tägliche App-Nutzung pro Benutzer in Minuten |
Avg() |
"avg", "mean" |
Mittelwert der Werte | Mittlerer Transaktionsbetrag |
Count() |
"count" |
Anzahl der Datensätze | Anzahl der Anmeldungen pro Benutzer |
Min() |
"min" |
Minimalwert | Niedrigste Von einem tragbaren Gerät aufgezeichnete Herzfrequenz |
Max() |
"max" |
Maximalwert | Maximale Korbgröße pro Sitzung |
StddevPop() |
"stddev_pop" |
Standardabweichung der Population | Tägliche Transaktionsbetragsvariabilität für alle Kunden |
StddevSamp() |
"stddev_samp" |
Stichprobenstandardabweichung | Variabilität der Klickraten für Anzeigenkampagnen |
VarPop() |
"var_pop" |
Varianz der Population | Verbreitung von Sensorwerten für IoT-Geräte in einer Fabrik |
VarSamp() |
"var_samp" |
Stichprobenabweichung | Verteilung von Filmbewertungen über eine ausgewählte Gruppe |
ApproxCountDistinct(relativeSD=0.05) |
"approx_count_distinct"* |
Ungefähre eindeutige Anzahl | Unterschiedliche Anzahl der gekauften Artikel |
ApproxPercentile(percentile=0.95,accuracy=100) |
N/A | Ungefähres Perzentil | p95-Antwortverzögerung |
First() |
"first" |
Erster Wert | Erster Anmeldezeitstempel |
Last() |
"last" |
Letzter Wert | Zuletzt erworbener Betrag |
*Funktionen mit Parametern verwenden Standardwerte, wenn sie Kurzschreibweisen für Zeichenfolgen nutzen.
Das folgende Beispiel zeigt Fensteraggregationsfeatures, die über dieselbe Datenquelle definiert sind.
from databricks.feature_engineering.entities import Sum, Avg, Count, Max, ApproxCountDistinct
fe = FeatureEngineeringClient()
sum_feature = fe.create_feature(source=source, inputs=["amount"], function=Sum(), ...)
avg_feature = fe.create_feature(source=source, inputs=["amount"], function=Avg(), ...)
distinct_count = fe.create_feature(
source=source,
inputs=["product_id"],
function=ApproxCountDistinct(relativeSD=0.01),
...
)
Funktionen mit Filterbedingungen
Die deklarativen Feature-APIs unterstützen auch das Anwenden eines SQL-Filters, der als WHERE Klausel in Aggregationen angewendet wird. Filter sind hilfreich beim Arbeiten mit großen Quelltabellen, die eine Obermenge von Daten enthalten, die für die Featureberechnung erforderlich sind, und minimiert die Notwendigkeit, separate Ansichten über diesen Tabellen zu erstellen.
from databricks.feature_engineering.entities import Sum, Count, ContinuousWindow
from datetime import timedelta
# Only aggregate high-value transactions
high_value_sales = fe.create_feature(
catalog_name="main",
schema_name="ecommerce",
source=transactions,
inputs=["amount"],
function=Sum(),
time_window=ContinuousWindow(window_duration=timedelta(days=30)),
filter_condition="amount > 100" # Only transactions over $100
)
# Multiple conditions using SQL syntax
completed_orders = fe.create_feature(
catalog_name="main",
schema_name="ecommerce",
source=orders,
inputs=["order_id"],
function=Count(),
time_window=ContinuousWindow(window_duration=timedelta(days=7)),
filter_condition="status = 'completed' AND payment_method = 'credit_card'"
)
Zeitfenster
Deklarative APIs des Feature Engineering unterstützen drei verschiedene Fenstertypen, um das Lookback-Verhalten für zeitfensterbasierte Aggregationen zu steuern: fortlaufend, Tumbling und gleitend.
- Kontinuierliche Zeitfenster blicken von der Ereigniszeit aus zurück. Dauer und Offset werden explizit definiert.
- Springende Fenster sind feste, nicht überlappende Zeitfenster. Jeder Datenpunkt gehört zu genau einem Fenster.
- Gleitfenster sind überlappende und rollende Zeitfenster mit einem konfigurierbaren Slide-Intervall.
Die folgende Abbildung zeigt, wie sie funktionieren.
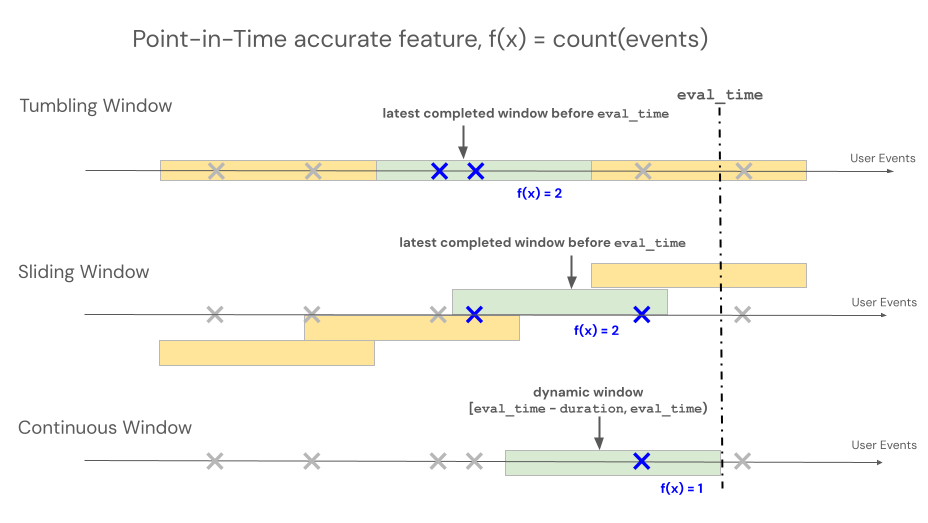
Fortlaufendes Fenster
Fortlaufende Fenster sind aktuelle und Echtzeit-Aggregate, die typischerweise bei Streamingdaten eingesetzt werden. In Streaming-Pipelines gibt das kontinuierliche Fenster nur dann eine neue Datenzeile aus, wenn sich der Inhalt des Fensters mit fester Länge ändert, z. B. wenn ein Ereignis hinzukommt oder entfernt wird. Wenn ein fortlaufendes Fenster-Feature in Schulungspipelines verwendet wird, wird eine zeitpunktgenaue Featureberechnung für die Quelldaten mit der festen Länge ausgeführt, die unmittelbar vor dem Zeitstempel eines bestimmten Ereignisses liegt. Auf diese Weise können Online-Offline-Abweichungen oder Datenverluste verhindert werden. Merkmale zum Zeitpunkt T aggregieren Ereignisse im Zeitraum von [T − Dauer, T).
class ContinuousWindow(TimeWindow):
window_duration: datetime.timedelta
offset: Optional[datetime.timedelta] = None
In der folgenden Tabelle sind die Parameter für ein fortlaufendes Fenster aufgeführt. Die Start- und Endzeiten des Fensters basieren wie folgt auf diesen Parametern:
- Startzeit:
evaluation_time - window_duration + offset(einschließlich) - Endzeitpunkt:
evaluation_time + offset(exklusiv)
| Parameter | Constraints |
|---|---|
offset (wahlweise) |
Muss ≤ 0 sein (verschiebt das Fenster rückwärts in der Zeit ab dem Endzeitstempel). Verwenden Sie offset, um etwaige Systemverzögerungen zwischen dem Zeitpunkt der Erstellung des Ereignisses und dem Ereigniszeitstempel zu berücksichtigen, um zukünftige Überläufe von Ereignissen in Schulungsdatensätzen zu verhindern. Wenn beispielsweise eine Verzögerung von einer Minute zwischen dem Zeitpunkt besteht, zu dem Ereignisse erstellt werden, und dem Zeitpunkt, zu dem diese Ereignisse schließlich in einer Quelltabelle landen und ihnen ein Zeitstempel zugewiesen wird, dann wäre der Offset timedelta(minutes=-1). |
window_duration |
Muss 0 sein > |
from databricks.feature_engineering.entities import ContinuousWindow
from datetime import timedelta
# Look back 7 days from evaluation time
window = ContinuousWindow(window_duration=timedelta(days=7))
Definieren Sie ein fortlaufendes Fenster mit Offset unter Verwendung des untenstehenden Codes.
# Look back 7 days, but end 1 day ago (exclude most recent day)
window = ContinuousWindow(
window_duration=timedelta(days=7),
offset=timedelta(days=-1)
)
Beispiele für fortlaufende Fenster
window_duration=timedelta(days=7), offset=timedelta(days=0): Dadurch wird ein 7-tägiges Lookbackfenster erstellt, das zur aktuellen Auswertungszeit endet. Für eine Veranstaltung um 2:00 Uhr am Tag 7 umfasst dies alle Ereignisse von 2:00 Uhr am Tag 0 bis (aber nicht einschließlich) 2:00 Uhr am Tag 7.window_duration=timedelta(hours=1), offset=timedelta(minutes=-30): Dadurch wird ein 1-Stündiges Lookbackfenster erstellt, das 30 Minuten vor der Auswertungszeit endet. Für eine Veranstaltung um 13:00 Uhr umfasst dies alle Veranstaltungen von 1:30 bis (aber nicht einschließlich) 2:30 Uhr. Dies ist nützlich, um Dateneinnahmeverzögerungen zu berücksichtigen.
Rollierendes Fenster
Für Features, die mithilfe von Sturzfenstern definiert sind, werden Aggregationen über ein vordefiniertes Fenster mit fester Länge berechnet, das durch ein Folienintervall voranschreitet, wodurch nicht überlappende Fenster erzeugt werden, die die vollständige Partitionszeit aufweisen. Daher trägt jedes Ereignis in der Quelle zu genau einem Fenster bei. Features zur zeitaggregatieren t Daten von Fenstern, die auf oder vor t (exklusiv) enden. Windows beginnt in der Unix-Epoche.
class TumblingWindow(TimeWindow):
window_duration: datetime.timedelta
In der folgenden Tabelle sind die Parameter für ein Sturzfenster aufgeführt.
| Parameter | Constraints |
|---|---|
window_duration |
Muss 0 sein > |
from databricks.feature_engineering.entities import TumblingWindow
from datetime import timedelta
window = TumblingWindow(
window_duration=timedelta(days=7)
)
Beispiel für ein Tumbling-Fenster
-
window_duration=timedelta(days=5): Dadurch werden jeweils vordefinierte Fenster mit fester Länge von 5 Tagen erstellt. Beispiel: Fenster #1 erstreckt sich über Tag 0 bis Tag 4, Fenster #2 erstreckt sich über Tag 5 bis Tag 9, Fenster #3 erstreckt sich über Tag 10 bis Tag 14 usw. Insbesondere enthält Window #1 alle Ereignisse mit Zeitstempeln, die am00:00:00.00Tag 0 bis (aber nicht einschließlich) aller Ereignisse mit Zeitstempel00:00:00.00am Tag 5 beginnen. Jedes Ereignis gehört zu genau einem Fenster.
Gleitendes Fenster
Für mit Gleitfenstern definierte Features werden Aggregationen über ein vordefiniertes Fenster mit fester Länge berechnet, das mit einem Verschiebungsintervall voranschreitet, wodurch überlappende Fenster entstehen. Jedes Ereignis in der Quelle kann zur Featureaggregation für mehrere Fenster beitragen. Features zum Zeitpunkt t aggregieren Daten von Fenstern, die vor t (exklusiv) enden. Windows beginnt in der Unix-Epoche.
class SlidingWindow(TimeWindow):
window_duration: datetime.timedelta
slide_duration: datetime.timedelta
In der folgenden Tabelle sind die Parameter für ein Gleitfenster aufgeführt.
| Parameter | Constraints |
|---|---|
window_duration |
Muss 0 sein > |
slide_duration |
Muss > 0 sein und <window_duration |
from databricks.feature_engineering.entities import SlidingWindow
from datetime import timedelta
window = SlidingWindow(
window_duration=timedelta(days=7),
slide_duration=timedelta(days=1)
)
Beispiel für gleitendes Fenster
-
window_duration=timedelta(days=5), slide_duration=timedelta(days=1): Dadurch werden überlappende 5-Tage-Fenster erstellt, die jedes Mal um 1 Tag voranschreiten. Beispiel: Fenster Nr. 1 erstreckt sich über Tag 0 bis Tag 4, Fenster #2 erstreckt sich über Tag 1 bis Tag 5, Fenster #3 erstreckt sich über Tag 2 bis Tag 6 usw. Jedes Fenster enthält Ereignisse vom00:00:00.00Starttag bis zum (aber nicht einschließlich)00:00:00.00am Endtag. Da sich Fenster überlappen, kann ein einzelnes Ereignis zu mehreren Fenstern gehören (in diesem Beispiel gehört jedes Ereignis zu bis zu 5 verschiedenen Fenstern).
API-Methoden
create_training_set()
Funktionen mit markierten Daten für ML-Training kombinieren:
FeatureEngineeringClient.create_training_set(
df: DataFrame, # DataFrame with training data
features: Optional[List[Feature]], # List of Feature objects
label: Union[str, List[str], None], # Label column name(s)
exclude_columns: Optional[List[str]] = None, # Optional: columns to exclude
# API continues to support creating training set using materialized feature tables and functions
) -> TrainingSet
Rufen Sie auf TrainingSet.load_df , um originale Schulungsdaten abzurufen, die mit den dynamisch berechneten Funktionen von Point-in-Time verbunden sind.
Anforderungen für df Argument:
- Muss alle
entity_columnsaus Feature-Datenquellen enthalten - Muss
timeseries_columnaus Feature-Datenquellen enthalten. - Sollte Beschriftungsspalten enthalten
Zeitpunktgenauigkeit: Features werden nur mit Quelldaten berechnet, die vor dem Zeitstempel jeder Zeile verfügbar sind, um ein Lecken zukünftiger Daten in der Modellschulung zu verhindern. Berechnungen nutzen die Fensterfunktionen von Spark zur Effizienz.
log_model()
Protokollieren Sie ein Modell mit Featuremetadaten für die Nachverfolgung von Linien und die automatische Featuresuche während der Ableitung:
FeatureEngineeringClient.log_model(
model, # Trained model object
artifact_path: str, # Path to store model artifact
flavor: ModuleType, # MLflow flavor module (e.g., mlflow.sklearn)
training_set: TrainingSet, # TrainingSet used for training
registered_model_name: Optional[str], # Optional: register model in Unity Catalog
)
Der flavor Parameter gibt das zu verwendende MLflow-Modell-Variantenmodul an, z. B. mlflow.sklearn oder mlflow.xgboost.
Modelle, die mit einer TrainingSet protokolliert werden, verfolgen automatisch die Abstammung zu den Merkmalen, die in der Schulung verwendet werden. Ausführliche Dokumentation finden Sie unter "Verwenden von Features zum Trainieren von Modellen".
score_batch()
Durchführen der Batch-Inferenz mit automatischer Merkmalsuche:
FeatureEngineeringClient.score_batch(
model_uri: str, # URI of logged model
df: DataFrame, # DataFrame with entity keys and timestamps
) -> DataFrame
score_batch verwendet die Feature-Metadaten, die mit dem Modell gespeichert sind, um zeitpunktgenau korrekte Features automatisch für die Inferenzen zu berechnen, wodurch die Konsistenz mit dem Training sichergestellt wird. Ausführliche Dokumentation finden Sie unter "Verwenden von Features zum Trainieren von Modellen".
Bewährte Methoden
Featurebenennung
- Verwenden Sie beschreibende Namen für unternehmenskritische Features.
- Halten Sie einheitliche Benennungskonventionen teamübergreifend ein.
- Lassen Sie die automatische Generierung explorative Funktionen übernehmen.
Zeitfenster
- Verwenden Sie Offsets, um instabile aktuelle Daten auszuschließen.
- Fensterbegrenzungen an Geschäftszyklen ausrichten (täglich, wöchentlich).
- Berücksichtigen Sie die Aktualität von Daten im Vergleich zu Funktionsstabilitätskonflikten.
Leistung
- Gruppieren Sie Features nach Datenquelle, um Datenüberprüfungen zu minimieren.
- Verwenden Sie geeignete Fenstergrößen für Ihren Anwendungsfall.
Testen
- Testen Sie Zeitfensterbegrenzungen mit bekannten Datenszenarien.
Allgemeine Muster
Kundenanalysen
fe = FeatureEngineeringClient()
features = [
# Recency: Number of transactions in the last day
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["transaction_id"],
function=Count(), time_window=ContinuousWindow(window_duration=timedelta(days=1))),
# Frequency: transaction count over the last 90 days
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["transaction_id"],
function=Count(), time_window=ContinuousWindow(window_duration=timedelta(days=90))),
# Monetary: total spend in the last month
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["amount"],
function=Sum(), time_window=ContinuousWindow(window_duration=timedelta(days=30)))
]
Trendanalyse
# Compare recent vs. historical behavior
fe = FeatureEngineeringClient()
recent_avg = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=7))
)
historical_avg = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=7), offset=timedelta(days=-7))
)
Saisonale Muster
# Same day of week, 4 weeks ago
fe = FeatureEngineeringClient()
weekly_pattern = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=1), offset=timedelta(weeks=-4))
)
Einschränkungen
- Die Namen von Entitäts- und Zeitserienspalten müssen zwischen dem Schulungsdatensatz und den Quelltabellen übereinstimmen, wenn sie in der
create_training_setAPI verwendet werden. - Der Spaltenname, der als
label-Spalte im Schulungsdatensatz verwendet wird, sollte nicht in den Quelltabellen existieren, die zur Definition vonFeatures verwendet werden. - Eine eingeschränkte Liste von Funktionen (UDAFs) wird in der
create_featureAPI unterstützt.