Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
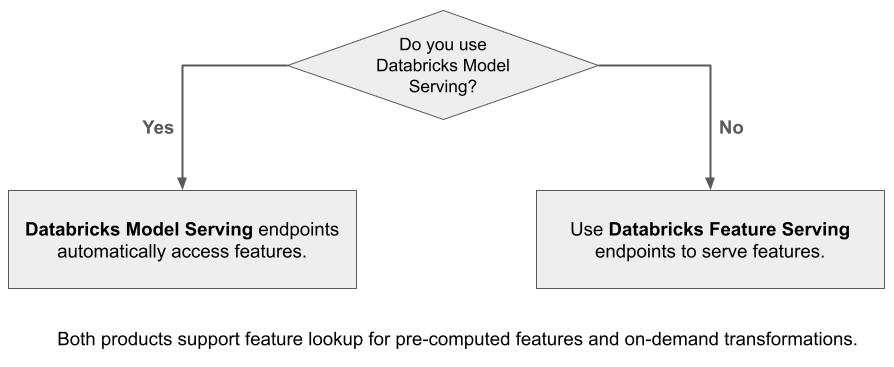
Databricks Feature Serving macht Daten auf der Databricks-Plattform für Modelle oder Anwendungen verfügbar, die außerhalb von Azure Databricks bereitgestellt werden. Feature Serving-Endpunkte werden automatisch skaliert, um den Echtzeitdatenverkehr anzupassen und einen latenzarmen Hochverfügbarkeitsdienst für die Bereitstellung von Funktionen bereitzustellen. Auf dieser Seite wird beschrieben, wie Feature Serving eingerichtet und verwendet wird. Ein Schritt-für-Schritt-Tutorial finden Sie unter Beispiel: Bereitstellen und Abfragen eines Feature-Endpunkts.
Wenn Sie Model Serve verwenden, um ein Modell zu bedienen, das mithilfe von Features von Databricks erstellt wurde, sucht das Modell automatisch und transformiert Features für Rückschlussanforderungen. Mit Databricks Feature Serving können Sie strukturierte Daten für RAG-Anwendungen (Retrieval Augmented Generation) sowie Funktionen bereitstellen, die für andere Anwendungen erforderlich sind, z. B. Modelle, die außerhalb von Databricks oder einer anderen Anwendung bereitgestellt werden, die Funktionen auf der Grundlage von Daten im Unity-Katalog erfordert.
Vorteile des Feature Serving
Databricks Feature Serving stellt eine einzelne Schnittstelle bereit, die vorbereitete und On-Demand-Funktionen bereitstellt. Es umfasst auch die folgenden Vorteile:
- Einfachheit: Databricks übernimmt die Infrastruktur. Mit einem einzelnen API-Aufruf erstellt Databricks eine produktionsbereite Bereitstellungsumgebung.
- Hochverfügbarkeit und Skalierbarkeit. Feature Serving-Endpunkte werden automatisch hoch- und herunterskaliert, um das Volumen der Bereitstellungsanforderungen anzupassen.
- Sicherheit: Endpunkte werden in einer sicheren Netzwerkgrenze bereitgestellt und verwenden dedizierten Compute, der beendet wird, wenn der Endpunkt gelöscht oder auf Null skaliert wird.
Anforderungen
- Databricks Runtime 14.2 ML oder höher.
- Um die Python-API zu verwenden, erfordert feature Serving
databricks-feature-engineeringVersion 0.1.2 oder höher, die in Databricks Runtime 14.2 ML integriert ist. Für frühere Versionen von Databricks Runtime ML installieren Sie die erforderliche Version manuell mithilfe von%pip install databricks-feature-engineering>=0.1.2. Wenn Sie ein Databricks-Notizbuch verwenden, müssen Sie den Python Kernel neu starten, indem Sie diesen Befehl in einer neuen Zelle ausführen:dbutils.library.restartPython(). - Für die Verwendung des Databricks SDK benötigt Feature Serving die
databricks-sdk-Version 0.18.0 oder höher. Um die erforderliche Version manuell zu installieren, verwenden Sie%pip install databricks-sdk>=0.18.0. Wenn Sie ein Databricks-Notizbuch verwenden, müssen Sie den Python Kernel neu starten, indem Sie diesen Befehl in einer neuen Zelle ausführen:dbutils.library.restartPython().
Databricks Feature Serving bietet eine Benutzeroberfläche und mehrere programmgesteuerte Optionen zum Erstellen, Aktualisieren, Abfragen und Löschen von Endpunkten. Dieser Artikel enthält Anweisungen für jede der folgenden Optionen:
- Databricks UI
- REST-API
- Python-API
- Databricks SDK
Um die REST-API oder das MLflow Deployments SDK zu verwenden, müssen Sie über ein Databricks-API-Token verfügen.
Wichtig
Als bewährte Sicherheitsmethode für Produktionsszenarien empfiehlt Databricks, Computer-zu-Computer-OAuth-Token für die Authentifizierung während der Produktion zu verwenden.
Für die Test- und Entwicklungsphase empfiehlt Databricks die Verwendung eines persönlichen Zugriffstokens, das Dienstprinzipalen anstelle von Arbeitsbereichsbenutzern gehört. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Authentifizierung für Feature Serving
Informationen zur Authentifizierung finden Sie unter Authorize access to Azure Databricks resources.
Erstellen der Datei FeatureSpec
Eine FeatureSpec ist ein benutzerdefinierter Satz von Features und Funktionen. Sie können Features und Funktionen in einer FeatureSpec kombinieren.
FeatureSpecs werden in Einheits-Katalog gespeichert und verwaltet und erscheinen im Catalog Explorer.
Die Tabellen, die in einem FeatureSpec angegeben sind, müssen in einem Online-Feature-Store oder einem Online-Store eines Drittanbieters veröffentlicht werden. Siehe Databricks Online Feature Stores.
Sie müssen das databricks-feature-engineering-Paket verwenden, um ein FeatureSpec zu erstellen.
Definieren Sie zunächst die Funktion:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
Anschließend können Sie die Funktion in einer FeatureSpec:
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Angeben von Standardwerten
Um Standardwerte für Features anzugeben, verwenden Sie den default_values Parameter in der FeatureLookup. Sehen Sie sich das folgende Beispiel an:
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
Wenn die Feature-Spalten mithilfe des rename_outputs Parameters umbenannt werden, muss default_values die umbenannten Feature-Namen verwenden.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Erstellen eines Endpunkts
FeatureSpec definiert den Endpunkt. Weitere Informationen finden Sie in Create custom model serving endpoints, the Python API documentation, or the Databricks SDK documentation for details.
Hinweis
Für Workloads, die latenzempfindlich sind oder hohe Abfragen pro Sekunde erfordern, bietet Model Serving Routenoptimierung für benutzerdefinierte Modellbereitstellungsendpunkte, siehe Routenoptimierung bei der Bereitstellung von Endpunkten.
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Python-API
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
REST-API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Um den Endpunkt anzuzeigen, klicken Sie in der linken Randleiste der Databricks-Benutzeroberfläche auf Bereitstellen. Wenn der Status Bereit lautet, kann der Endpunkt auf Abfragen antworten. Weitere Informationen zur Modellbereitstellung finden Sie unter Model Serving.
Speichern des erweiterten DataFrames in der Ableitungstabelle
Für Endpunkte, die ab Februar 2025 erstellt wurden, können Sie das Modell konfigurieren, das den Endpunkt bedient, um den erweiterten DataFrame zu protokollieren, der die Nachschlagefunktionswerte und Funktionsrückgabewerte enthält. Der DataFrame wird in der Inferenztabelle für das bereitgestellte Modell gespeichert.
Anweisungen zum Festlegen dieser Konfiguration finden Sie unter Protokollfeatures-Lookup DataFrames in Inferencetabellen übertragen.
Informationen zu Rückschlusstabellen finden Sie unter Monitor-bereitgestellte Modelle mithilfe von AI-Gateway-fähigen Rückschlusstabellen.
Abrufen eines Endpunkts
Sie können das Databricks SDK oder die Python-API verwenden, um die Metadaten und den Status eines Endpunkts abzurufen.
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Python-API
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Abrufen des Schemas eines Endpunkts
Sie können das Databricks SDK oder die REST-API verwenden, um das Schema eines Endpunkts abzurufen. Weitere Informationen zum Endpunktschema finden Sie unter Abrufen eines Modells, das Endpunktschemas dient.
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
REST-API
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Abfragen eines Endpunkts
Sie können die REST-API, das MLflow Deployments SDK oder die Serving UI verwenden, um einen Endpunkt abzufragen.
Der folgende Code zeigt, wie Sie Anmeldeinformationen einrichten und den Client bei Verwendung des MLflow Deployments SDK erstellen.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Hinweis
Als bewährte Methode für die Sicherheit empfiehlt Databricks, dass Sie bei der Authentifizierung mit automatisierten Tools, Systemen, Skripten und Anwendungen persönliche Zugriffstoken verwenden, die zu Dienstprinzipalen und nicht zu Benutzern des Arbeitsbereichs gehören. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Abfragen eines Endpunkts mithilfe von APIs
Dieser Abschnitt enthält Beispiele zum Abfragen eines Endpunkts mithilfe der REST-API oder des MLflow Deployments SDK.
MLflow Deployments SDK
Wichtig
Im folgenden Beispiel wird die predict()-API aus dem MLflow Deployments SDK verwendet. Diese API ist experimentell, und die API-Definition kann sich ändern.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
REST-API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Abfragen eines Endpunkts mithilfe der Benutzeroberfläche
Sie können einen Dienstendpunkt direkt über die Benutzeroberfläche des Diensts abfragen. Die Benutzeroberfläche enthält generierte Codebeispiele, mit denen Sie den Endpunkt abfragen können.
Klicken Sie in der linken Randleiste des Azure Databricks Arbeitsbereichs auf Serving.
Klicken Sie auf den Endpunkt, den Sie abfragen möchten.
Klicken Sie oben rechts auf dem Bildschirm auf den Abfrageendpunkt.
Geben Sie im Feld Anforderung den Anforderungstext im JSON-Format ein.
Klicke auf Anforderung senden.
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
Der Query-Endpunkt enthält generierten Beispielcode in curl, Python und SQL. Klicken Sie auf die Registerkarten, um den Beispielcode anzuzeigen und zu kopieren.
Um den Code zu kopieren, klicken Sie oben rechts im Textfeld auf das Kopiersymbol.
Einen Endpunkt aktualisieren
Wichtig
Verwenden Sie zum Ändern der Konfiguration eines Feature Serving-Endpunkts (z. B. Ändern der FeatureSpec Größe oder Workload) immer die in diesem Abschnitt beschriebenen Update-APIs. Löschen Sie den Endpunkt nicht und erstellen Sie den Endpunkt neu, um Änderungen anzuwenden. Das Löschen eines Liveendpunkts verursacht sofortige Ausfallzeiten und unterbricht alle Anwendungen, die sie abfragen.
Sie können einen Endpunkt mithilfe der REST-API, des Databricks SDK oder der Dienstbenutzeroberfläche aktualisieren.
Aktualisieren eines Endpunkts mithilfe von APIs
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
REST-API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Aktualisieren eines Endpunkts mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um die Serving UI zu bedienen:
- Klicken Sie in der linken Randleiste des Azure Databricks Arbeitsbereichs auf Serving.
- Klicken Sie in der Tabelle auf den Namen des Endpunkts, den Sie aktualisieren möchten. Der Endpunktbildschirm wird angezeigt.
- Klicken Sie oben rechts auf dem Bildschirm auf Endpunkt bearbeiten.
- Bearbeiten Sie im Dialogfeld Endpunkt bearbeiten die Endpunkteinstellungen nach Bedarf.
- Klicken Sie auf Aktualisieren, um Ihre Änderungen zu speichern.

Einen Endpunkt löschen
Warnung
Diese Aktion kann nicht rückgängig gemacht werden. Das Löschen eines Endpunkts zur Featurebereitstellung führt zu sofortigen Ausfallzeiten für alle Anwendungen, die sie abfragen. Wenn Sie die Konfiguration des Endpunkts ändern möchten, verwenden Sie "Aktualisieren eines Endpunkts ", anstatt den Endpunkt zu löschen und neu zu erstellen.
Sie können einen Endpunkt mithilfe der REST-API, des Databricks SDK, der Python-API oder der Dienstbenutzeroberfläche löschen.
Löschen eines Endpunkts mithilfe von APIs
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
Python-API
fe.delete_feature_serving_endpoint(name="customer-features")
REST-API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Löschen eines Endpunkts mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen Endpunkt mithilfe der Serving UI zu löschen:
- Klicken Sie in der linken Randleiste des Azure Databricks Arbeitsbereichs auf Serving.
- Klicken Sie in der Tabelle auf den Namen des Endpunkts, den Sie löschen möchten. Der Endpunktbildschirm wird angezeigt.
- Klicken Sie oben rechts auf dem Bildschirm auf das
 und wählen Sie "Löschen" aus.
und wählen Sie "Löschen" aus.

Überwachen der Integrität eines Endpunkts
Informationen zu den Protokollen und Metriken, die für Feature Serving-Endpunkte verfügbar sind, finden Sie unter Überwachen der Modellqualität und der Endpunktintegrität.
Zugriffssteuerung
Informationen zu Berechtigungen für Endpunkte zur Featurebereitstellung finden Sie unter Verwalten von Berechtigungen auf einem Modellbereitstellungsendpunkt.
Notebook mit Beispielen
Dieses Notizbuch veranschaulicht die Verwendung des Databricks SDK zum Erstellen eines Feature-Serving-Endpunkts mithilfe des Databricks Online Feature Store.