Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie Mithilfe von Databricks Model Serve Modell für Endpunkte erstellen, die benutzerdefinierte Modelle bedienen.
Die Model Serving bietet die folgenden Optionen für die Erstellung von Bereitstellungsendpunkten:
- Die Serving-Benutzeroberfläche
- REST-API
- MLflow Deployments SDK
Weitere Informationen zum Erstellen von Endpunkten für generative KI-Modelle finden Sie unter Erstellen von Basismodell-Bereitstellungsendpunkten.
Anforderungen
- Ihr Arbeitsbereich muss sich in einer unterstützten Region befinden.
- Wenn Sie benutzerdefinierte Bibliotheken oder Bibliotheken von einem privaten Spiegelserver mit Ihrem Modell verwenden, lesen Sie "Verwenden von benutzerdefinierten Python-Bibliotheken mit Model Serving ", bevor Sie den Modellendpunkt erstellen.
- Zum Erstellen von Endpunkten mithilfe des MLflow Deployments SDK müssen Sie den MLflow Deployment-Client installieren. Führen Sie zur Installation Folgendes aus:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Zugriffssteuerung
Informationen zu den Optionen für die Zugriffssteuerung für das Modell, das Endpunkte für die Endpunktverwaltung bedient, finden Sie unter Verwalten von Berechtigungen für ein Modell, das Endpunkt bedient.
Die Identität, unter der ein Modell ausgeführt wird, das den Endpunkt bedient, ist an den ursprünglichen Ersteller des Endpunkts gebunden. Nach der Endpunkterstellung kann die zugeordnete Identität nicht mehr geändert oder auf dem Endpunkt aktualisiert werden. Diese Identität und die zugehörigen Berechtigungen werden für den Zugriff auf Unity-Katalogressourcen für Bereitstellungen verwendet. Wenn die Identität nicht über die entsprechenden Berechtigungen für den Zugriff auf die erforderlichen Unity-Katalogressourcen verfügt, müssen Sie den Endpunkt löschen und unter einem Benutzer- oder Dienstprinzipal neu erstellen, der auf diese Unity-Katalogressourcen zugreifen kann.
Sie können auch Umgebungsvariablen hinzufügen, um Anmeldeinformationen für die Modellbereitstellung zu speichern. Siehe Konfigurieren des Zugriffs auf Ressourcen von Modell-Servierungsendpunkten
Erstellen eines Endpunkts
Serving-Benutzeroberfläche
Sie können einen Endpunkt für die Modellbereitstellung auf der Benutzeroberfläche für die Bereitstellung erstellen.
Klicken Sie in der Randleiste auf Serving, um die Serving-Benutzeroberfläche anzuzeigen.
Klicken Sie auf "Bereitstellungsendpunkt erstellen".
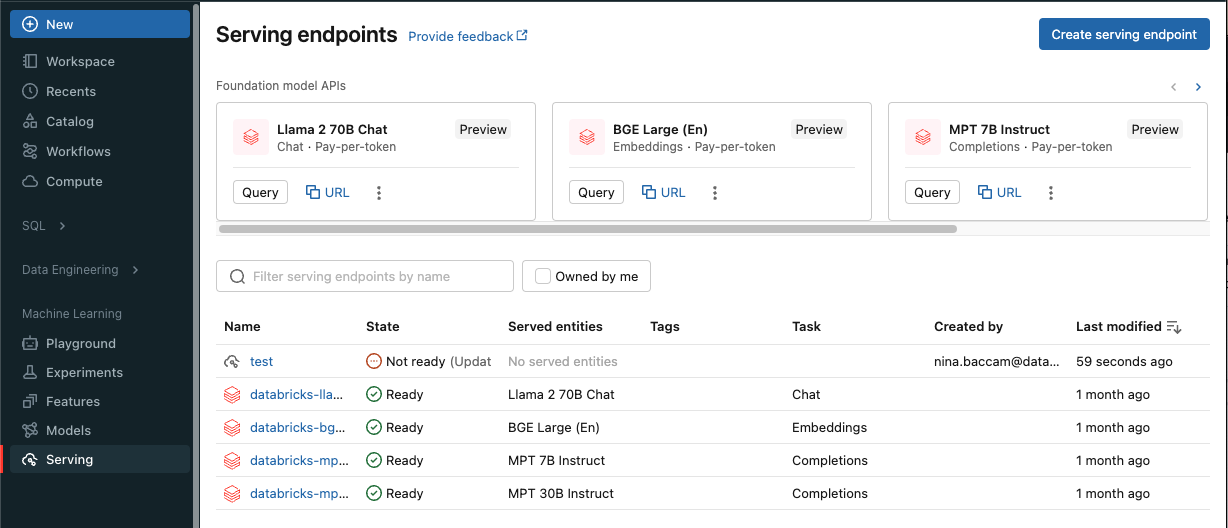
Für Modelle, die entweder im Modellregister des Arbeitsbereichs oder im Unity-Katalog registriert sind:
Geben Sie im Feld "Name " einen Namen für Ihren Endpunkt an.
- Endpunktnamen können das
databricks-Präfix nicht verwenden. Dieses Präfix ist für vorkonfigurierte Endpunkte von Databricks reserviert.
- Endpunktnamen können das
Im Abschnitt Bereitgestellte Entitäten
- Klicken Sie in das Feld Entität, um das Formular Auswahl der bedienten Entität zu öffnen.
- Wählen Sie entweder "Meine Modelle - Unity Katalog" oder "Meine Modelle - Modellregister" aus, basierend auf dem Ort, an dem Ihr Modell registriert ist. Das Formular wird basierend auf Ihrer Auswahl dynamisch aktualisiert.
- Nicht alle Modelle sind benutzerdefinierte Modelle. Modelle können Foundation-Modelle oder Features für die Bereitstellung von Funktionen sein.
- Wählen Sie aus, welches Modell und welche Modellversion Sie bereitstellen möchten.
- Wählen Sie den Prozentsatz des Datenverkehrs aus, der an Ihr bereitgestelltes Modell weitergeleitet wird.
- Wählen Sie die Rechnergröße aus, die Sie verwenden möchten. Sie können für Ihre Workloads CPU- oder GPU-Computeressourcen verwenden. Weitere Informationen zu verfügbaren GPU-Computes finden Sie unter GPU-Workloadtypen .
- Wählen Sie unter Compute Scale-out die Größe der Berechnungs-Skalierung aus, die der Anzahl der Anforderungen entspricht, die dieses bereitgestellte Modell gleichzeitig verarbeiten kann. Diese Zahl sollte ungefähr dem Ergebnis der folgenden Rechnung entsprechen: QPS × Modelllaufzeit. Informationen zu vom Kunden definierten Computeeinstellungen finden Sie unter Modellbereitstellungsgrenzwerte.
- Verfügbare Größen sind klein für 0-4 Anforderungen, mittlere 8-16 Anforderungen und Groß für 16-64 Anforderungen.
- Geben Sie an, ob der Endpunkt auf null skaliert werden soll, wenn er nicht verwendet wird. Skalierung auf Null wird für Produktionsendpunkte nicht empfohlen, da die Kapazität nicht garantiert wird, wenn sie auf Null skaliert wird. Wenn ein Endpunkt auf Null skaliert, tritt eine zusätzliche Latenz auf, die auch als Kaltstart bezeichnet wird, wenn der Endpunkt wieder hochskaliert, um Anfragen zu bedienen.
- Unter erweiterter Konfiguration haben Sie folgende Möglichkeiten:
- Benennen Sie die bereitgestellte Entität um, um anzupassen, wie sie im Endpunkt angezeigt wird.
- Fügen Sie Umgebungsvariablen hinzu, um Ressourcen von Ihrem Endpunkt aus zu verbinden oder protokollieren Sie Ihren Feature-Lookup-DataFrame in die Inference-Tabelle des Endpunkts. Für das Protokollieren des Feature-Lookup-DataFrames ist MLflow 2.14.0 oder höher erforderlich.
- (Optional) Wenn Sie Ihrem Endpunkt weitere bereitgestellte Entitäten hinzufügen möchten, klicken Sie auf "Entität hinzufügen ", und wiederholen Sie die oben aufgeführten Konfigurationsschritte. Sie können mehrere Modelle oder Modellversionen von einem einzelnen Endpunkt aus bereitstellen und den zwischen ihnen aufgeteilten Datenverkehr steuern. Weitere Informationen finden Sie unter "Bereitstellen mehrerer Modelle ".
Im Abschnitt "Routenoptimierung " können Sie die Routenoptimierung für Ihren Endpunkt aktivieren. Die Routenoptimierung wird für Endpunkte mit hohen QPS- und Durchsatzanforderungen empfohlen. Siehe Routenoptimierung bei der Bereitstellung von Endpunkten.
Im Abschnitt "AI Gateway " können Sie auswählen, welche Governancefeatures auf Ihrem Endpunkt aktiviert werden sollen. Siehe KI-Gateway.
Klicken Sie auf "Erstellen". Die Seite Bereitstellungsendpunkte wird mit dem Status „Nicht bereit“ für den Bereitstellungsendpunkt angezeigt.
REST-API
Sie können Endpunkte mithilfe der REST-API erstellen. Siehe POST /api/2.0/serving-endpoints für Konfigurationsparameter des Endpunkts.
Im folgenden Beispiel wird ein Endpunkt erstellt, der der dritten Version des Modells dient, das in der Registrierung des my-ads-model Unity-Katalogmodells registriert ist. Um ein Modell aus Unity Catalog anzugeben, geben Sie den vollständigen Modellnamen an, einschließlich des übergeordneten Katalogs und des Schemas, etwa catalog.schema.example-model. In diesem Beispiel wird eine benutzerdefinierte Parallelität mit min_provisioned_concurrency und max_provisioned_concurrencyverwendet. Parallelitätswerte müssen Vielfache von 4 sein.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
Hier sehen Sie eine Beispielantwort. Der Endpunktstatus config_update ist NOT_UPDATING , und das bereitgestellte Modell befindet sich in einem READY Zustand.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow Deployments SDK
MLflow-Bereitstellungen bieten eine API zum Erstellen, Aktualisieren und Löschen von Aufgaben. Die APIs für diese Aufgaben akzeptieren dieselben Parameter wie die REST-API für Bereitstellungsendpunkte. Siehe POST /api/2.0/serving-endpoints für Konfigurationsparameter des Endpunkts.
Im folgenden Beispiel wird ein Endpunkt erstellt, der der dritten Version des Modells dient, das in der Registrierung des my-ads-model Unity-Katalogmodells registriert ist. Sie müssen den vollständigen Modellnamen einschließlich übergeordnetem Katalog und Schema angeben, catalog.schema.example-modelz. B. . In diesem Beispiel wird eine benutzerdefinierte Parallelität mit min_provisioned_concurrency und max_provisioned_concurrencyverwendet. Parallelitätswerte müssen Vielfache von 4 sein.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
Arbeitsbereichsclient
Das folgende Beispiel zeigt, wie Sie einen Endpunkt mithilfe des Databricks Workspace Client SDK erstellen.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
Sie können auch:
- Aktivieren Sie Schlussfolgerungstabellen , um eingehende Anforderungen und ausgehende Antworten automatisch auf Ihr Modell zu erfassen, das Endpunkte bedient.
- Wenn Sie Rückschlusstabellen auf Ihrem Endpunkt aktiviert haben, können Sie Ihren Feature-Lookup-DataFrame in der Rückschlusstabelle protokollieren.
GPU-Workloadtypen
Die GPU-Bereitstellung ist mit den folgenden Paketversionen kompatibel:
- PyTorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0-2.13.0
- MLflow 2.4.0 und höher
Die folgenden Beispiele zeigen, wie GPU-Endpunkte mit unterschiedlichen Methoden erstellt werden.
Serving-Benutzeroberfläche
Um Ihren Endpunkt für GPU-Workloads mit der Benutzeroberfläche zu konfigurieren, wählen Sie den gewünschten GPU-Typ aus der Dropdownliste " ComputeTyp " aus, wenn Sie Ihren Endpunkt erstellen. Führen Sie die gleichen Schritte in " Endpunkt erstellen" aus, wählen Sie jedoch einen GPU-Workloadtyp anstelle von CPU aus.
REST-API
Um Ihre Modelle mithilfe von GPUs bereitzustellen, schließen Sie das Feld in die workload_type Endpunktkonfiguration ein.
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
MLflow Deployments SDK
Das folgende Beispiel zeigt, wie Sie einen GPU-Endpunkt mithilfe des MLflow Deployments SDK erstellen.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
Arbeitsbereichsclient
Das folgende Beispiel zeigt, wie Sie einen GPU-Endpunkt mit dem Databricks Workspace Client SDK erstellen.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
In der folgenden Tabelle sind die verfügbaren GPU-Workloadtypen zusammengefasst, die unterstützt werden.
| GPU-Workload-Typ | GPU-Instanz | GPU-Arbeitsspeicher |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Ändern eines benutzerdefinierten Modellendpunkts
Nachdem Sie einen benutzerdefinierten Modellendpunkt aktiviert haben, können Sie die Computekonfiguration wie gewünscht aktualisieren. Diese Konfiguration ist besonders hilfreich, wenn Sie zusätzliche Ressourcen für Ihr Modell benötigen. Die Größe der Arbeitslast und die Computerkonfiguration spielen eine wichtige Rolle bei der Ressourcenzuweisung für die Bereitstellung Ihres Modells.
Hinweis
Aktualisierungen der Endpunktkonfiguration können fehlschlagen. Wenn Fehler auftreten, bleibt die vorhandene aktive Konfiguration wirksam, als ob das Update nicht ausgeführt wurde.
Stellen Sie sicher, dass das Update erfolgreich angewendet wurde, indem Sie den Status Ihres Endpunkts überprüfen.
Bis die neue Konfiguration bereit ist, stellt die alte Konfiguration weiterhin Vorhersagedatenverkehr bereit. Während ein Update ausgeführt wird, kann kein weiteres Update durchgeführt werden. Sie können jedoch eine in Bearbeitung ausgeführte Aktualisierung von der Serving-Benutzeroberfläche abbrechen.
Serving-Benutzeroberfläche
Nachdem Sie einen Modellendpunkt aktiviert haben, wählen Sie "Endpunkt bearbeiten" aus, um die Computekonfiguration Ihres Endpunkts zu ändern.
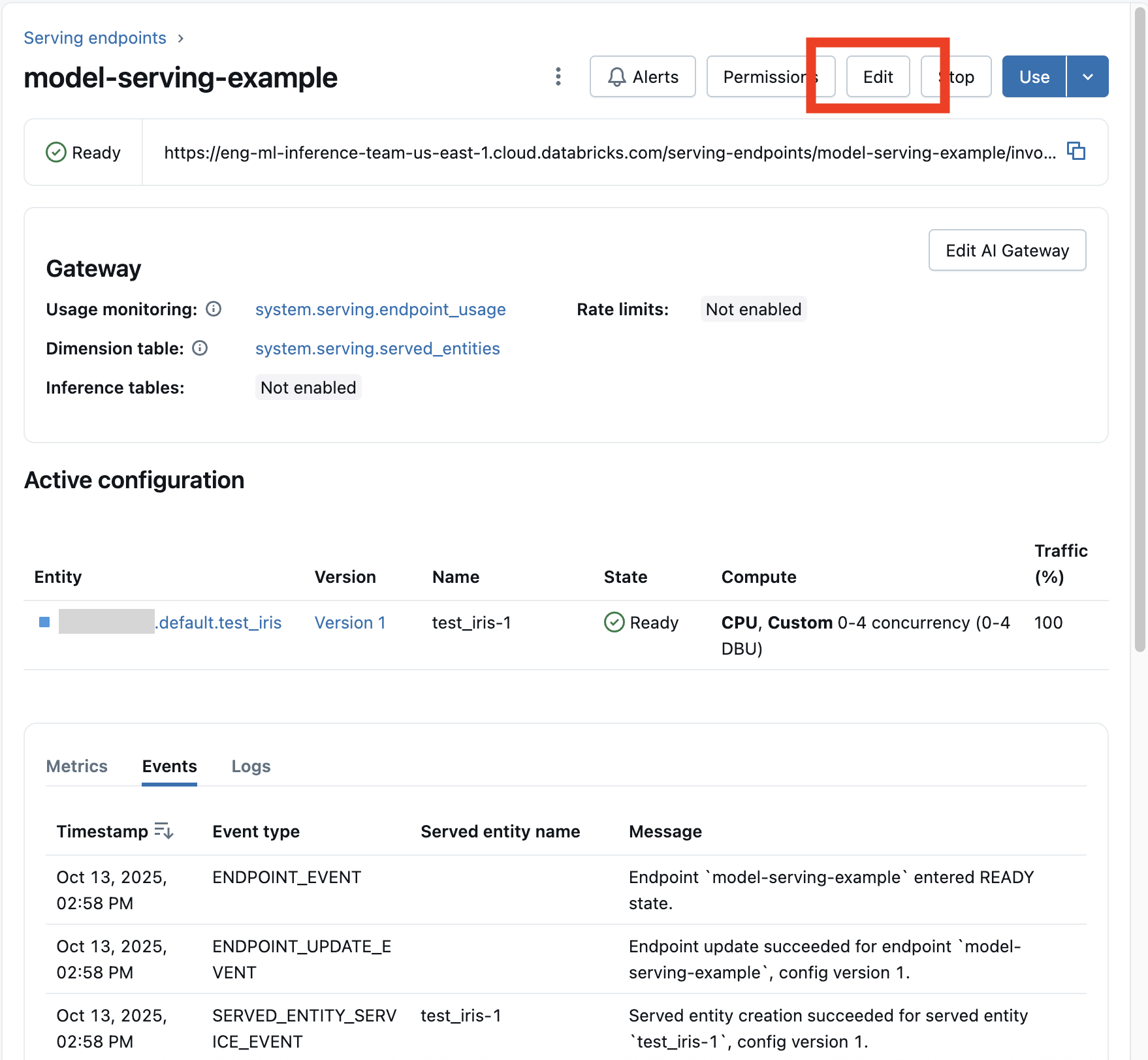
Sie können die meisten Aspekte der Endpunktkonfiguration ändern, mit Ausnahme des Endpunktnamens und bestimmter unveränderlicher Eigenschaften.
Sie können ein laufendes Konfigurationsupdate abbrechen, indem Sie auf der Detailseite des Endpunkts "Aktualisieren abbrechen " auswählen.
REST-API
Nachfolgend sehen Sie ein Beispiel für ein Endpunktkonfigurationsupdate mit der REST-API. Siehe PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow Deployments SDK
Das MLflow Deployments SDK verwendet dieselben Parameter wie die REST-API, siehe PUT /api/2.0/serving-endpoints/{name}/config for request and response schema details.
Im folgenden Codebeispiel wird ein Modell aus der Unity Catalog-Modellregistrierung verwendet:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Bewerten eines Modellendpunkts
Um Ihr Modell zu bewerten, senden Sie Anforderungen an den Modellbereitstellungsendpunkt.
Zusätzliche Ressourcen
- Verwalten sie das Modell, das Endpunkte bedient.
- Externe Modelle im Mosaik AI Model Serving.
- Wenn Sie es bevorzugen, Python zu verwenden, können Sie das Echtzeit-Bereitstellungs-SDK von Databricks verwenden.
Notebook-Beispiele
Die folgenden Notebooks umfassen verschiedene in Databricks registrierte Modelle, die Sie verwenden können, um Modellbereitstellungsendpunkte einzurichten und auszuführen. Weitere Beispiele finden Sie im Lernprogramm: Bereitstellen und Abfragen eines benutzerdefinierten Modells.
Die Modellbeispiele können in den Arbeitsbereich importiert werden, indem Sie den Anweisungen im Import eines Notizbuchs folgen. Nachdem Sie ein Modell aus einem der Beispiele ausgewählt und erstellt haben, registrieren Sie es im Unity-Katalog, und führen Sie dann die Schritte des UI-Workflows für die Modellbereitstellung aus.