Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, welche Optionen zum Schreiben von Abfrageanforderungen für Foundation-Modelle verfügbar sind und wie Sie sie an Ihren Modellbereitstellungsendpunkt senden. Sie können Foundation-Modelle abfragen, die von Databricks und Foundation-Modellen gehostet werden, die außerhalb von Databricks gehostet werden.
Informationen zu Abfrageanforderungen für herkömmliche ML- oder Python-Modelle finden Sie unter Abfragen von Bereitstellungsendpunkten für benutzerdefinierte Modelle.
Mosaik AI Model Serving unterstützt Foundation Models-APIs und externe Modelle für den Zugriff auf Foundation-Modelle. Model Serving verwendet eine einheitliche OpenAI-kompatible API und ein SDK für die Abfrage. Dies ermöglicht das Experimentieren und Anpassen von Foundation-Modellen für die Produktion in unterstützten Clouds und Anbietern.
Abfrageoptionen
Mosaic AI Model Serving bietet die folgenden Optionen zum Senden von Abfrageanforderungen an Endpunkte, die Foundation-Modelle bereitstellen:
| Methode | Einzelheiten |
|---|---|
| OpenAI-Client | Abfragen eines Modells, das von einem Mosaic AI Model Serving-Endpunkt mithilfe des OpenAI-Clients gehostet wird. Geben Sie das Modell an, das den Endpunktnamen als model-Eingabe angibt. Unterstützt für Chat-, Einbettungs- und Abschlussmodelle, die von Foundation Model-APIs oder externen Modellen zur Verfügung gestellt werden. |
| KI-Funktionen | Rufen Sie den Modellrückschluss direkt aus SQL mithilfe der SQL-Funktion „ai_query“ auf. Siehe Beispiel: Abfragen eines Foundation-Modells. |
| Serving-Benutzeroberfläche | Wählen Sie auf der Seite Bereitstellungsendpunkt die Option Endpunkt abfragen aus. Fügen Sie Eingabedaten des JSON-Formatmodells ein, und klicken Sie auf Anforderung übermitteln. Wenn das Modell ein Eingabebeispiel protokolliert hat, verwenden Sie Beispiel anzeigen, um es zu laden. |
| REST-API | Rufen Sie das Modell mithilfe der REST-API auf, und fragen Sie es ab. Details finden Sie unter POST /serving-endpoints/{name}/invocations. Informationen zum Bewerten von Anforderungen an Endpunkte, die mehreren Modellen dienen, finden Sie unter Abfragen einzelner Modelle hinter einem Endpunkt. |
| MLflow Deployments SDK | Verwenden Sie die Vorhersage() -Funktion des MLflow Deployments SDK, um das Modell abzufragen. |
| Databricks Python SDK | Das Databricks Python SDK ist eine Ebene über der REST-API. Es behandelt Details auf niedriger Ebene, z. B. die Authentifizierung, wodurch die Interaktion mit den Modellen erleichtert wird. |
Anforderungen
- Ein Modellbereitstellungsendpunkt.
- Ein Databricks-Arbeitsbereich in einer unterstützten Region.
- Sie müssen über Databricks-API-Token verfügen, um eine Bewertungsanforderung über den OpenAI-Client, die REST-API oder das MLflow Deployment SDK zu senden.
Wichtig
Als bewährte Sicherheitsmethode für Produktionsszenarien empfiehlt Databricks, Computer-zu-Computer-OAuth-Token für die Authentifizierung während der Produktion zu verwenden.
Für die Test- und Entwicklungsphase empfiehlt Databricks die Verwendung eines persönlichen Zugriffstokens, das Dienstprinzipalen anstelle von Arbeitsbereichsbenutzern gehört. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Installieren von Paketen
Nachdem Sie eine Abfragemethode ausgewählt haben, müssen Sie zuerst das entsprechende Paket für Ihren Cluster installieren.
OpenAI-Client
Um den OpenAI-Client zu verwenden, muss das databricks-openai-Paket für Ihren Cluster installiert sein. Dieses Paket stellt einen OpenAI-Client mit automatischer Autorisierung bereit, um generative KI-Modelle abzufragen. Führen Sie den folgenden Befehl in Ihrem Notebook oder lokalen Terminal aus:
pip install -U databricks-openai
Folgendes ist nur erforderlich, wenn das Paket für ein Databricks-Notebook installiert wird.
dbutils.library.restartPython()
REST-API
Der Zugriff auf die Bereitstellungs-REST-API ist in Databricks Runtime für Machine Learning verfügbar.
MLflow Deployments SDK
!pip install mlflow
Folgendes ist nur erforderlich, wenn das Paket für ein Databricks-Notebook installiert wird.
dbutils.library.restartPython()
Databricks Python SDK
Das Databricks-SDK für Python ist auf allen Azure Databricks-Clustern bereits installiert, die Databricks Runtime 13.3 LTS oder höher verwenden. Für Azure Databricks-Cluster, die Databricks Runtime 12.2 LTS und darunter verwenden, müssen Sie zuerst das Databricks-SDK für Python installieren. Siehe Databricks SDK für Python.
Foundation-Modelltypen
In der folgenden Tabelle sind die unterstützten Foundation-Modelle basierend auf dem Aufgabentyp zusammengefasst.
Wichtig
Meta-Llama-3.1-405B-Instruct wird eingestellt,
- Ab dem 15. Februar 2026 für Pay-per-Token-Workloads.
- Ab dem 15. Mai 2026 für bereitgestellte Durchsatzarbeitslasten.
Siehe "Eingestellte Modelle" für das empfohlene Ersatzmodell und Anleitungen für die Migration während der Außerbetriebnahme.
| Aufgabentyp | BESCHREIBUNG | Unterstützte Modelle | Wann sollte ich verwenden? Empfohlene Anwendungsfälle |
|---|---|---|---|
| Allgemeiner Zweck | Modelle, die entwickelt wurden, um natürliche, mehrfach geführte Unterhaltungen zu verstehen und daran teilzunehmen. Sie sind auf große Datasets menschlicher Dialoge optimiert, die es ihnen ermöglichen, kontextbezogene Antworten zu generieren, den Konversationsverlauf nachzuverfolgen und kohärente, menschliche Interaktionen über verschiedene Themen hinweg bereitzustellen. | Im Folgenden werden databricks-gehostete Foundation-Modelle unterstützt:
Im Folgenden werden externe Modelle unterstützt:
|
Empfohlen für Szenarien, in denen natürlicher, mehrschrittiger Dialog und kontextuelles Verständnis erforderlich sind.
|
| Einbettungen | Einbettungsmodelle sind Machine Learning-Systeme, die komplexe Daten wie Text, Bilder oder Audio in kompakte numerische Vektoren transformieren, die als Einbettungen bezeichnet werden. Diese Vektoren erfassen die wesentlichen Features und Beziehungen innerhalb der Daten, was eine effiziente Vergleichs-, Cluster- und semantische Suche ermöglicht. | Im Folgenden wird das von Databricks gehostete Basismodell unterstützt: Im Folgenden werden externe Modelle unterstützt:
|
Empfohlen für Anwendungen, bei denen semantisches Verständnis, Ähnlichkeitsvergleich und effizientes Abrufen oder Clustering komplexer Daten unerlässlich sind:
|
| Vision | Modelle zum Verarbeiten, Interpretieren und Analysieren visueller Daten wie Bilder und Videos, damit Maschinen die visuelle Welt "sehen" und verstehen können. | Im Folgenden werden databricks-gehostete Foundation-Modelle unterstützt:
Im Folgenden werden externe Modelle unterstützt:
|
Empfohlen, wo automatisierte, genaue und skalierbare Analyse visueller Informationen erforderlich ist:
|
| Denken | Erweiterte KI-Systeme, die zum Simulieren von menschlichen logischen Denken entwickelt wurden. Schlussfolgerungsmodelle integrieren Techniken wie symbolische Logik, probabilistische Schlussfolgerung und neurale Netzwerke, um Kontext zu analysieren, Aufgaben aufzuschlüsseln und ihre Entscheidungsfindung zu erläutern. | Im Folgenden wird das von Databricks gehostete Basismodell unterstützt:
Im Folgenden werden externe Modelle unterstützt:
|
Empfohlen, wo automatisierte, genaue und skalierbare Analyse visueller Informationen erforderlich ist:
|
Aufrufen der Funktion
Databricks Function Calling ist OpenAI-kompatibel und ist nur während des Modells verfügbar, das als Teil Foundation Model-APIs dient und Endpunkte bedient, die externen Modellendienen. Ausführliche Informationen finden Sie unter Funktionsaufrufe für Azure Databricks.
Strukturierte Ausgaben
Strukturierte Ausgaben sind openAI-kompatibel und stehen nur während des Modells als Teil von Foundation Model-APIs zur Verfügung. Ausführliche Informationen finden Sie unter "Strukturierte Ausgaben" in Azure Databricks.
Prompt-Zwischenspeicherung
Das Prompt-Caching wird für von Databricks gehostete Claude-Modelle als Teil der Foundation Model-APIs unterstützt.
Sie können den cache_control Parameter in Ihren Abfrageanforderungen angeben, um Folgendes zwischenzuspeichern:
- Textinhaltsnachrichten im
messages.contentArray. - Denken sie an Nachrichteninhalte im
messages.contentArray. - Bilderinhaltsblöcke im
messages.contentArray. - Toolverwendung, Ergebnisse und Definitionen im
toolsArray.
Siehe Foundation-Modell-REST-API-Referenz.
TextContent
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's the date today?",
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
ReasonContent
{
"messages": [
{
"role": "assistant",
"content": [
{
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "Thinking...",
"signature": "[optional]"
},
{
"type": "summary_encrypted_text",
"data": "[encrypted text]"
}
]
}
]
}
]
}
ImageContent
Bildnachrichteninhalte müssen die codierten Daten als Quelle verwenden. URLs werden nicht unterstützt.
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,[content]"
},
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
ToolCall-Inhalt
{
"messages": [
{
"role": "assistant",
"content": "Ok, let’s get the weather in New York.",
"tool_calls": [
{
"type": "function",
"id": "123",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"New York, NY\"}"
},
"cache_control": { "type": "ephemeral" }
}
]
}
]
}
Hinweis
Die Databricks REST-API ist openAI-kompatibel und unterscheidet sich von der anthropischen API. Diese Unterschiede wirken sich auch auf Antwortobjekte wie die folgenden aus:
- Die Ausgabe wird im
choicesFeld zurückgegeben. - Streaming-Blockformat. Alle Chunks entsprechen demselben Format, wobei
choicesdie Antwortdeltaenthält und in jedem Chunk die Nutzung zurückgegeben wird. - Der Stoppgrund wird im
finish_reasonFeld zurückgegeben.- Anthropic verwendet:
end_turn,stop_sequence,max_tokensundtool_use - Databricks verwendet
stop,stop,lengthundtool_callsjeweils.
- Anthropic verwendet:
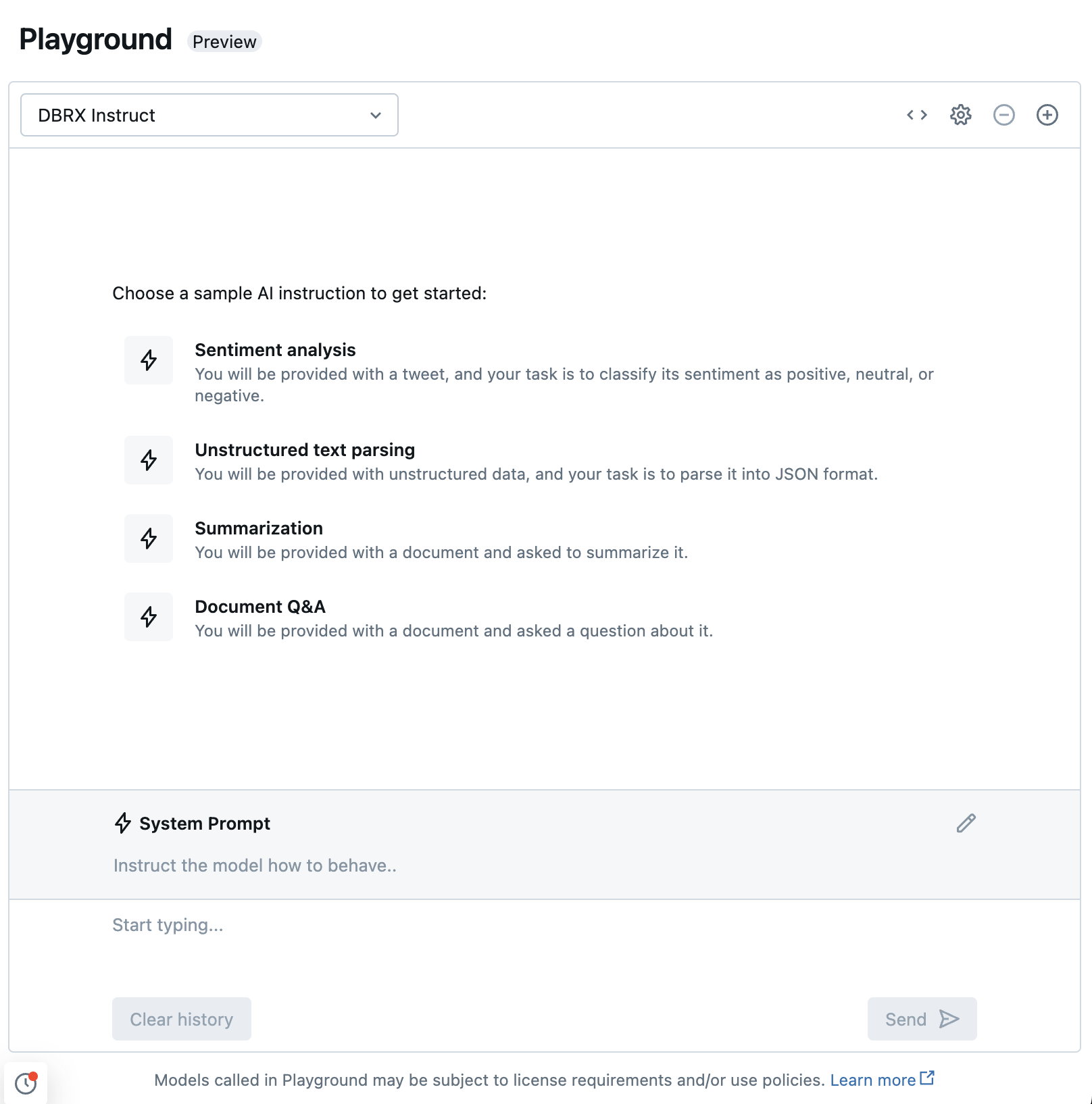
Chatten mit unterstützten LLMs im KI-Playground
Sie können mit unterstützten großen Sprachmodellen interagieren, indem Sie den KI-Playground verwenden. Der KI-Playground ist eine Chat-ähnliche Umgebung, in der Sie LLMs aus Ihrem Azure Databricks-Arbeitsbereich testen, auffordern und vergleichen können.
Zusätzliche Ressourcen
- Überwachen von bereitgestellten Modellen mithilfe von Unity AI Gateway-fähigen Ableitungstabellen
- Bereitstellen von Batch-Inferenzpipelines
- Databricks Foundation Model-Schnittstellen
- Externe Modelle in Mosaic AI Model Serving
- Lernprogramm: Erstellen externer Modellendpunkte zum Abfragen von OpenAI-Modellen
- Databricks-gehostete Foundation-Modelle, die in Foundation Model-APIs verfügbar sind
- Foundation Model-REST-API-Referenz