Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
MLflow-Protokollierte Modelle helfen Ihnen, den Fortschritt eines Modells während des gesamten Lebenszyklus nachzuverfolgen. Wenn Sie ein Modell trainieren, verwenden Sie mlflow.<model-flavor>.log_model(), um eine LoggedModel zu erstellen, die alle wichtigen Informationen mithilfe einer eindeutigen ID verbindet. Um die Leistungsfähigkeit von LoggedModels zu nutzen, beginnen Sie mit MLflow 3.
Für GenAI-Anwendungen können LoggedModels erstellt werden, um Git-Commits oder Parametersätze als dedizierte Objekte zu erfassen, die dann mit Traces und Metriken verknüpft werden können. In Deep Learning und klassischem ML werden LoggedModels aus MLflow-Läufen erzeugt, die bestehende Konzepte in MLflow sind und als Aufgaben betrachtet werden können, die Modellcode ausführen. Trainingsläufe erzeugen Modelle als Ausgaben, und Auswertungsläufe verwenden vorhandene Modelle als Eingabe, um Metriken und andere Informationen zu erzeugen, mit deren Hilfe Sie die Leistung eines Modells bewerten können.
Das LoggedModel Objekt wird während des gesamten Lebenszyklus des Modells in verschiedenen Umgebungen beibehalten und enthält Verknüpfungen zu Artefakten wie Metadaten, Metriken, Parametern und dem Code, der zum Generieren des Modells verwendet wird. Die protokollierte Modellnachverfolgung ermöglicht es Ihnen, Modelle miteinander zu vergleichen, das leistungsstärkste Modell zu finden und Informationen während des Debuggens nachzuverfolgen.
Protokollierte Modelle können auch in der Unity Catalog-Modellregistrierung registriert werden, wodurch Informationen zum Modell aus allen MLflow-Experimenten und Arbeitsbereichen an einem einzigen Ort zur Verfügung gestellt werden. Weitere Informationen finden Sie unter Modellregistrierungsverbesserungen mit MLflow 3.
![]()
Verbesserte Nachverfolgung für Generative KI- und Deep-Learning-Modelle
Generative KI- und Deep Learning-Workflows profitieren insbesondere von der granularen Nachverfolgung, die protokollierte Modelle bereitstellt.
Gen KI - einheitliche Evaluierungs- und Protokollierungsdaten:
- Gen-KI-Modelle generieren während der Auswertung und Bereitstellung zusätzliche Metriken, wie Rückmeldedaten von Prüfern und Trace-Daten.
- Mit der
LoggedModelEntität können Sie alle von einem Modell generierten Informationen mithilfe einer einzigen Schnittstelle abfragen.
Deep Learning – effizientes Prüfpunktmanagement:
- Deep Learning-Schulung erstellt mehrere Prüfpunkte, die Momentaufnahmen des Zustands des Modells an einem bestimmten Punkt während des Trainings sind.
- MLflow erstellt für jeden Prüfpunkt einen separaten
LoggedModel, der die Metriken und Leistungsdaten des Modells enthält. Auf diese Weise können Sie Prüfpunkte vergleichen und auswerten, um die leistungsstärksten Modelle effizient zu identifizieren.
Erstellen eines protokollierten Modells
Verwenden Sie zum Erstellen eines protokollierten Modells dieselbe log_model() API wie vorhandene MLflow-Workloads. Die folgenden Codeausschnitte zeigen, wie Sie ein protokolliertes Modell für KI-, Deep Learning- und herkömmliche ML-Workflows erstellen.
Vollständige, lauffähige Notizbuchbeispiele finden Sie unter Beispielnotizbücher.
Gen AI
Der folgende Codeausschnitt zeigt, wie ein LangChain-Agent protokolliert wird. Verwenden Sie die Methode log_model() für Ihre Variante des Agenten.
# Log the chain with MLflow, specifying its parameters
# As a new feature, the LoggedModel entity is linked to its name and params
model_info = mlflow.langchain.log_model(
lc_model=chain,
name="basic_chain",
params={
"temperature": 0.1,
"max_tokens": 2000,
"prompt_template": str(prompt)
},
model_type="agent",
input_example={"messages": "What is MLflow?"},
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
Starten Sie einen Auswertungsauftrag und verknüpfen Sie die Metriken mit einem protokollierten Modell, indem Sie die eindeutige model_id für die LoggedModel angeben.
# Start a run to represent the evaluation job
with mlflow.start_run() as evaluation_run:
eval_dataset: mlflow.entities.Dataset = mlflow.data.from_pandas(
df=eval_df,
name="eval_dataset",
)
# Run the agent evaluation
result = mlflow.evaluate(
model=f"models:/{logged_model.model_id}",
data=eval_dataset,
model_type="databricks-agent"
)
# Log evaluation metrics and associate with agent
mlflow.log_metrics(
metrics=result.metrics,
dataset=eval_dataset,
# Specify the ID of the agent logged above
model_id=logged_model.model_id
)
das Deep Learning
Der folgende Codeausschnitt zeigt, wie protokollierte Modelle während der Deep Learning-Schulung erstellt werden. Verwenden Sie die log_model() Methode für Ihren Geschmack des MLflow-Modells.
# Start a run to represent the training job
with mlflow.start_run():
# Load the training dataset with MLflow. We will link training metrics to this dataset.
train_dataset: Dataset = mlflow.data.from_pandas(train_df, name="train")
X_train, y_train = prepare_data(train_dataset.df)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(scripted_model.parameters(), lr=0.01)
for epoch in range(101):
X_train, y_train = X_train.to(device), y_train.to(device)
out = scripted_model(X_train)
loss = criterion(out, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Obtain input and output examples for MLflow Model signature creation
with torch.no_grad():
input_example = X_train[:1]
output_example = scripted_model(input_example)
# Log a checkpoint with metrics every 10 epochs
if epoch % 10 == 0:
# Each newly created LoggedModel checkpoint is linked with its
# name, params, and step
model_info = mlflow.pytorch.log_model(
pytorch_model=scripted_model,
name=f"torch-iris-{epoch}",
params={
"n_layers": 3,
"activation": "ReLU",
"criterion": "CrossEntropyLoss",
"optimizer": "Adam"
},
step=epoch,
signature=mlflow.models.infer_signature(
model_input=input_example.cpu().numpy(),
model_output=output_example.cpu().numpy(),
),
input_example=X_train.cpu().numpy(),
)
# Log metric on training dataset at step and link to LoggedModel
mlflow.log_metric(
key="accuracy",
value=compute_accuracy(scripted_model, X_train, y_train),
step=epoch,
model_id=model_info.model_id,
dataset=train_dataset
)
Traditionelles Maschinelles Lernen
Der folgende Codeausschnitt zeigt, wie Sie ein Sklearn-Modell loggen und Metriken mit dem Logged Model verknüpfen. Verwenden Sie die log_model() Methode für Ihren Geschmack des MLflow-Modells.
## Log the model
model_info = mlflow.sklearn.log_model(
sk_model=lr,
name="elasticnet",
params={
"alpha": 0.5,
"l1_ratio": 0.5,
},
input_example = train_x
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
# Evaluate the model on the training dataset and log metrics
# These metrics are now linked to the LoggedModel entity
predictions = lr.predict(train_x)
(rmse, mae, r2) = compute_metrics(train_y, predictions)
mlflow.log_metrics(
metrics={
"rmse": rmse,
"r2": r2,
"mae": mae,
},
model_id=logged_model.model_id,
dataset=train_dataset
)
Beispielnotebooks
Beispielnotizbücher, die die Verwendung von LoggedModels veranschaulichen, finden Sie auf den folgenden Seiten:
Anzeigen von Modellen und Nachverfolgen des Fortschritts
Sie können Ihre protokollierten Modelle in der Arbeitsbereichs-UI anzeigen:
- Wechseln Sie zur Registerkarte "Experimente " in Ihrem Arbeitsbereich.
- Wählen Sie ein Experiment aus. Wählen Sie dann die Registerkarte " Modelle " aus.
Diese Seite enthält alle protokollierten Modelle, die dem Experiment zugeordnet sind, sowie deren Metriken, Parameter und Artefakte.
![]()
Sie können Diagramme generieren, um Metriken über Läufe hinweg nachzuverfolgen.
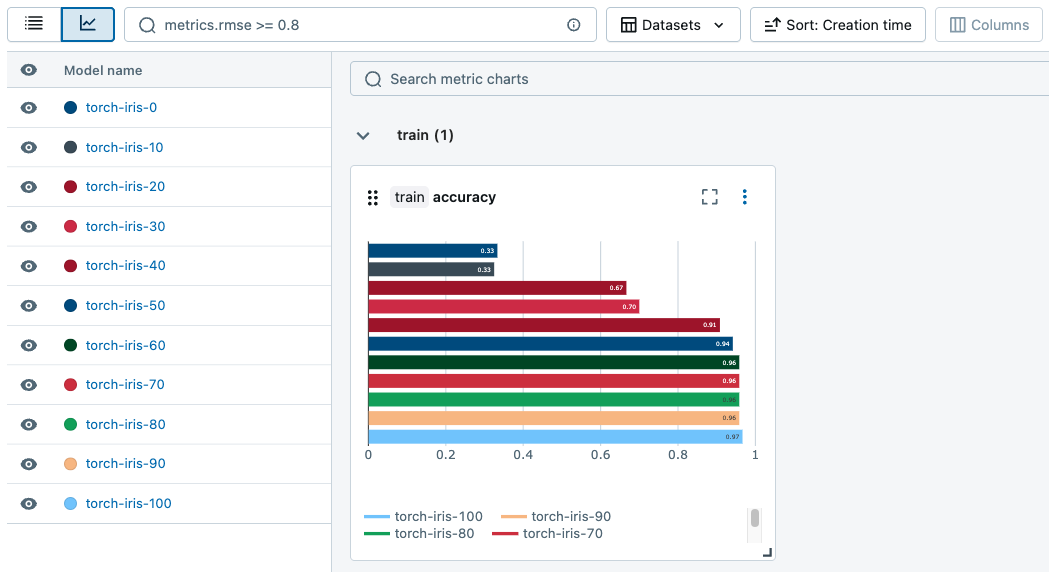
Protokollierte Modelle suchen und filtern
Auf der Registerkarte "Modelle " können Sie protokollierte Modelle basierend auf ihren Attributen, Parametern, Tags und Metriken suchen und filtern.
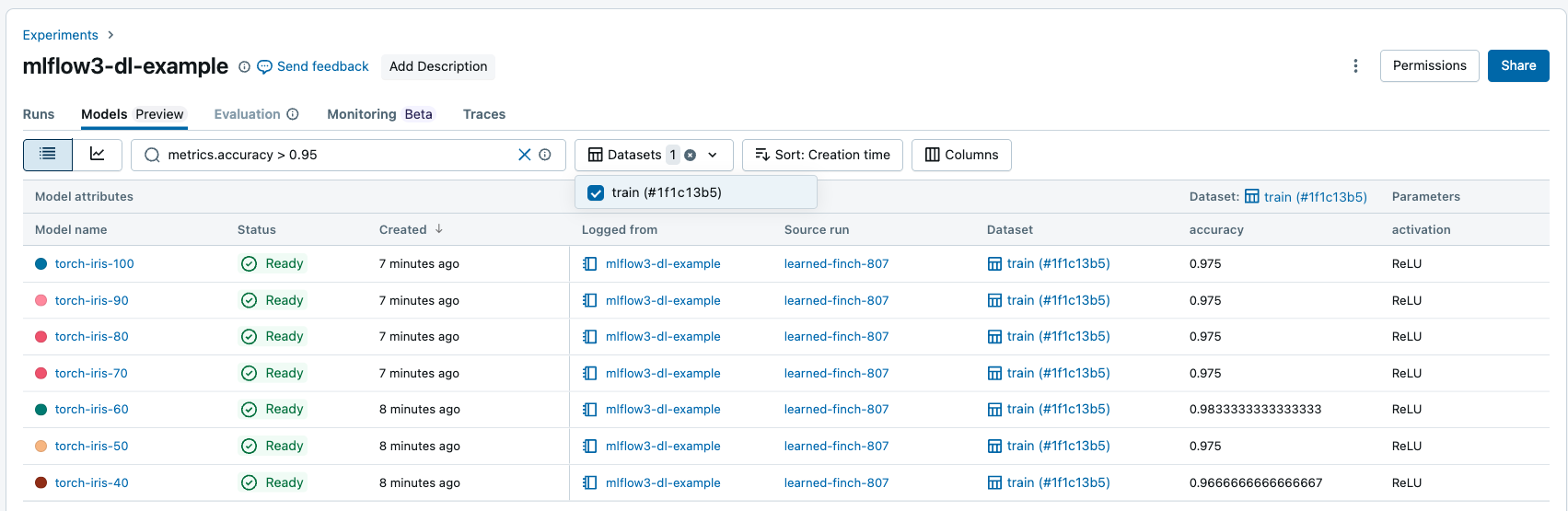
Sie können Metriken basierend auf datasetspezifischer Leistung filtern, und nur Modelle mit übereinstimmenden Metrikwerten für die angegebenen Datasets werden zurückgegeben. Wenn Datasetfilter ohne Metrikfilter bereitgestellt werden, werden Modelle mit allen Metriken für diese Datasets zurückgegeben.
Sie können basierend auf den folgenden Attributen filtern:
model_idmodel_namestatusartifact_uri-
creation_time(numerisch) -
last_updated_time(numerisch)
Verwenden Sie die folgenden Operatoren, um Zeichenfolgenähnliche Attribute, Parameter und Tags zu durchsuchen und zu filtern:
-
=!=INNOT IN
Verwenden Sie die folgenden Vergleichsoperatoren, um numerische Attribute und Metriken zu durchsuchen und zu filtern:
-
=, ,!=>,<, ,>=<=
Protokollierte Modelle programmgesteuert durchsuchen
Sie können mithilfe der MLflow-API nach protokollierten Modellen suchen:
## Get a Logged Model using a model_id
mlflow.get_logged_model(model_id = <my-model-id>)
## Get all Logged Models that you have access to
mlflow.search_logged_models()
## Get all Logged Models with a specific name
mlflow.search_logged_models(
filter_string = "model_name = <my-model-name>"
)
## Get all Logged Models created within a certain time range
mlflow.search_logged_models(
filter_string = "creation_time >= <creation_time_start> AND creation_time <= <creation_time_end>"
)
## Get all Logged Models with a specific param value
mlflow.search_logged_models(
filter_string = "params.<param_name> = <param_value_1>"
)
## Get all Logged Models with specific tag values
mlflow.search_logged_models(
filter_string = "tags.<tag_name> IN (<tag_value_1>, <tag_value_2>)"
)
## Get all Logged Models greater than a specific metric value on a dataset, then order by that metric value
mlflow.search_logged_models(
filter_string = "metrics.<metric_name> >= <metric_value>",
datasets = [
{"dataset_name": <dataset_name>, "dataset_digest": <dataset_digest>}
],
order_by = [
{"field_name": metrics.<metric_name>, "dataset_name": <dataset_name>,"dataset_digest": <dataset_digest>}
]
)
Weitere Informationen und zusätzliche Suchparameter finden Sie in der MLflow 3-API-Dokumentation.
Suche wird anhand von Modelleingaben und -ausgaben durchgeführt.
Sie können nach Modell-ID suchen, um alle Ausführungen zurückzugeben, die das protokollierte Modell als Eingabe oder Ausgabe aufweisen. Weitere Informationen zur Syntax der Filterzeichenfolge finden Sie unter "Filter for runs".
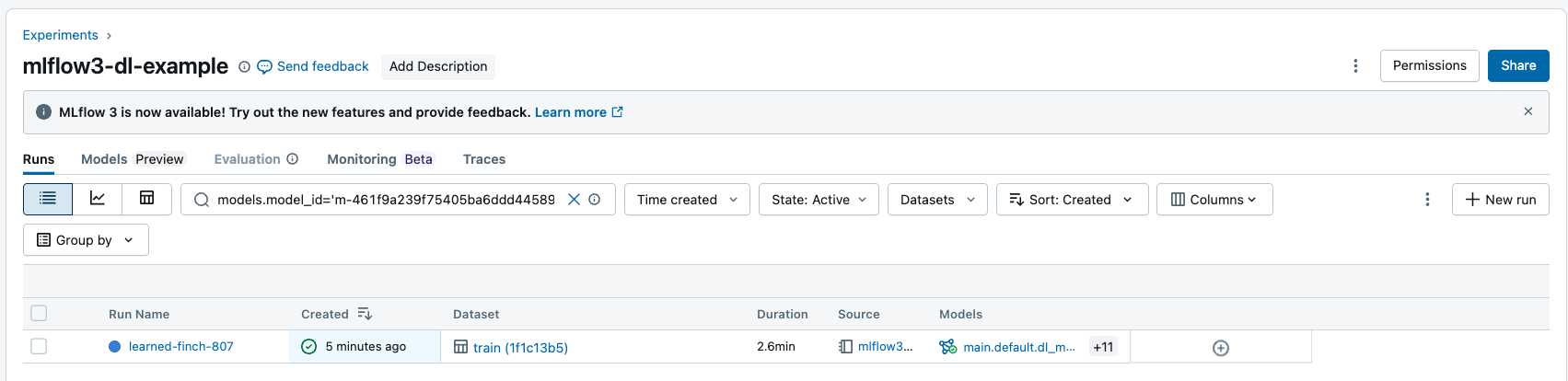
Sie können mithilfe der MLflow-API nach Ausführungen suchen:
## Get all Runs with a particular model as an input or output by model id
mlflow.search_runs(filter_string = "models.model_id = <my-model-id>")
Nächste Schritte
Weitere Informationen zu anderen neuen Features von MLflow 3 finden Sie in den folgenden Artikeln: