Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Databricks SQL
Databricks SQL ![]() Databricks Runtime
Databricks Runtime
Azure Databricks verwendet mehrere Regeln, um Konflikte zwischen Datentypen zu lösen:
- Promotion erweitert einen Datentyp sicher auf einen breiteren Datentyp.
- Das implizite Downcasting beschränkt einen Typ. Das Gegenteil der Erweiterung.
- Implizites Crosscasting wandelt einen Typ in einen Typ einer anderen Typfamilie um.
Sie können auch explizit zwischen vielen Typen umwandeln:
- Umwandlungsfunktion wandelt zwischen den meisten Typen um und gibt Fehler zurück, wenn dies nicht möglich ist.
- try_cast Funktion funktioniert wie die Cast-Funktion, gibt aber NULL zurück, wenn ungültige Werte übergeben werden.
- Andere eingebaute Funktionen zwischen den Typen unter Verwendung der bereitgestellten Formatdirektiven zu wechseln.
Typ-Heraufufung
Bei der Typerweiterung wird ein Typ in einen anderen Typ derselben Typfamilie umgewandelt, der alle möglichen Werte des ursprünglichen Typs enthält.
Daher ist die Typerweiterung ein sicherer Vorgang.
TINYINT hat z. B. einen Bereich von -128 bis 127. Alle möglichen Werte können sicher auf INTEGER erweitert werden.
Typrangfolgenliste
Die Typrangfolgenliste bestimmt, ob Werte eines bestimmten Datentyps implizit auf einen anderen Datentyp heraufgestuft werden können.
| Datentyp | Rangfolgeliste (vom niedrigsten zum höchsten Typ) |
|---|---|
| TINYINT | TINYINT - SMALLINT ->> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| SMALLINT | SMALLINT - INT ->> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| INT | INT - BIGINT ->> DECIMAL -> FLOAT (1) -> DOUBLE |
| BIGINT | BIGINT -> DEZIMAL -> FLOAT (1) -> DOUBLE |
| DECIMAL | DEZIMAL -> FLOAT (1) -> DOUBLE |
| FLOAT | FLOAT (1) -> DOUBLE |
| DOUBLE | DOUBLE |
| DATE | DATUM -> ZEITSTEMPEL |
| ZEIT | ZEIT (4) |
| TIMESTAMP | TIMESTAMP |
| ARRAY | ARRAY (2) |
| BINARY | BINARY |
| BOOLEAN | BOOLEAN |
| INTERVAL | INTERVAL |
| GEOGRAFIE | GEOGRAFIE(ANY) |
| GEOMETRIE | GEOMETRY(ANY) |
| MAP | MAP (2) |
| STRING | STRING |
| STRUCT | STRUKTUR (2) |
| VARIANT | VARIANT |
| OBJECT | OBJEKT (3) |
(1) Für die am wenigsten häufige TypauflösungFLOAT wird übersprungen, um Genauigkeitsverluste zu vermeiden.
(2) Bei einem komplexen Typ wendet die Rangfolgeregel rekursiv auf die Komponentenelemente an.
(3)OBJECT existiert nur innerhalb eines VARIANT.
(4) Der am wenigsten häufig verwendete Typ und TIME(n)TIME(m) ist TIME(max(n, m)).
TIME weder höher noch auf einen anderen Typ heraufstufen TIMESTAMP .
Zeichenketten und NULL
Für STRINGs und nicht typisierte NULL-Werte gelten spezielle Regeln:
-
NULLDer erste Typ kann in jeden anderen Typ umgewandelt werden. -
STRINGkann auf , , , ,BIGINTBINARY, ,BOOLEAN, , undDATE.DOUBLEINTERVALTIMETIMESTAMPWenn der tatsächliche Zeichenfolgenwert nicht in den kleinsten gemeinsamen Typ umgewandelt werden kann, gibt Azure Databricks einen Laufzeitfehler aus. Beim Erweitern zuINTERVALmuss der Zeichenfolgenwert mit den Intervalleeinheiten übereinstimmen.
Typrangfolgendiagramm
Dies ist eine grafische Darstellung der Rangfolgenhierarchie, die die Typrangfolgenliste sowie Regeln zu Zeichenfolgen und NULLs kombiniert.
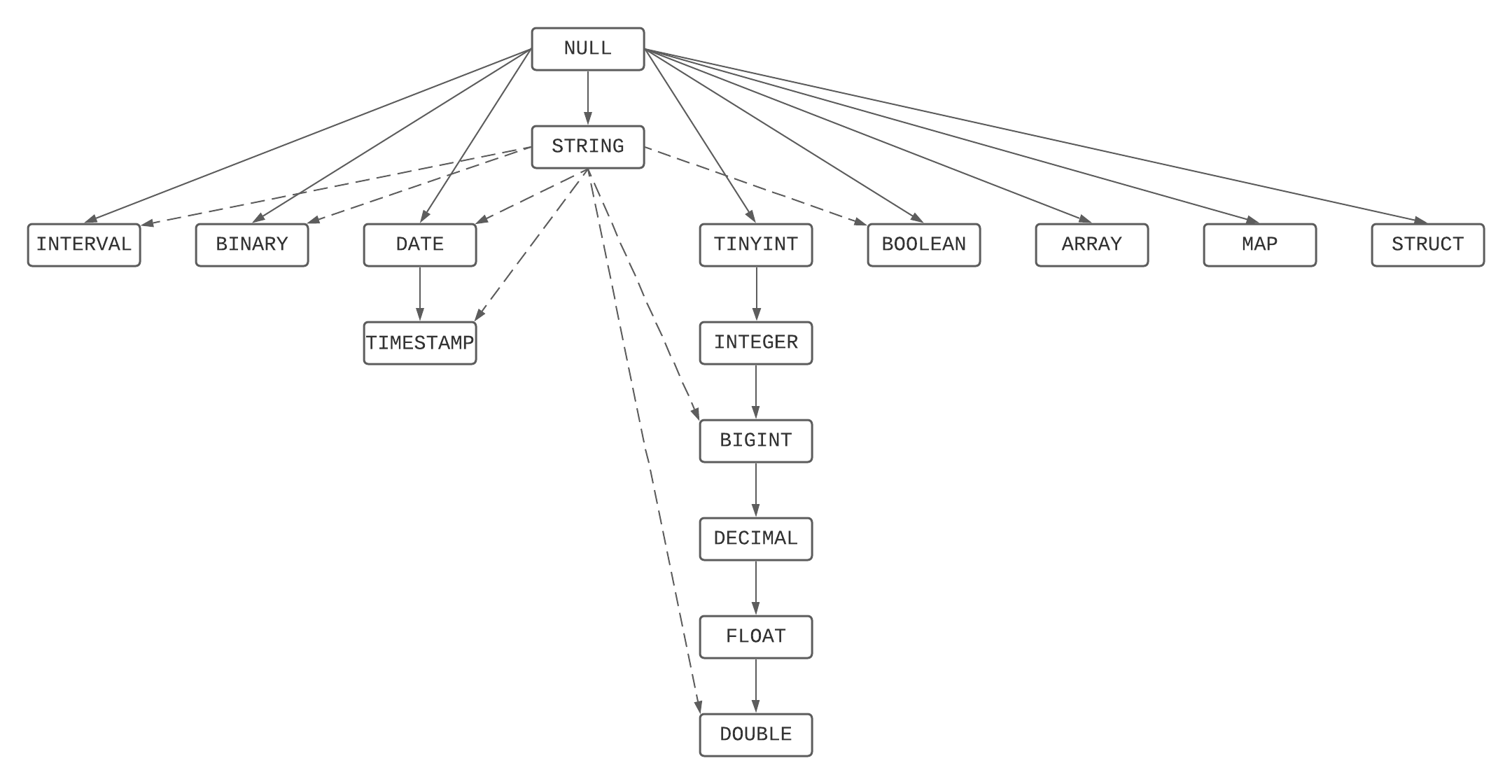
Auflösung des kleinsten gemeinsamen Typs
Der kleinste gemeinsame Typ aus einer Reihe von Typen ist der niedrigste Typ, der aus der Typrangfolgendiagramm von allen Elementen der Reihe von Typen erreicht werden kann.
Die Auflösung des kleinsten gemeinsamen Typs wird für Folgendes verwendet:
- Entscheiden, ob eine Funktion, die einen Parameter eines angegebenen Typs erwartet, mit einem Argument eines niedrigeren Typs aufgerufen werden kann.
- Leiten Sie den Argumenttyp für eine Funktion ab, die einen gemeinsamen Argumenttyp für mehrere Parameter erwartet, z. B. koaleszieren, in, kleinst oder größt.
- Ableiten der Operandentypen für Operatoren wie z. B. arithmetische Operationen oder Vergleiche.
- Leiten Sie den Ergebnistyp für Ausdrücke wie den Fallausdruck ab.
- Leiten Sie die Element-, Schlüssel- oder Werttypen für Array- und Map-Konstruktoren ab.
- Ableiten des Ergebnistyps der UNION-, INTERSECT- oder EXCEPT-Mengenoperatoren.
Parametrisierte Typen
Einige Datentypen enthalten Parameter, die sich auf ihre Genauigkeit oder Skalierung auswirken. Wenn der am wenigsten häufig verwendete Typ parametrisierte Typen umfasst, werden die Ergebnisparameter berechnet, sodass Werte beider Eingabetypen ohne Verlust dargestellt werden können.
DEZIMAL(p, s)
Die am wenigsten häufig verwendete Art von DECIMAL(p1, s1) und DECIMAL(p2, s2) ist eine DECIMAL , deren Skalierung und Genauigkeit alle Werte aus beiden Typen berücksichtigen:
resultScale = max(s1, s2)
maxIntegerDigits = max(p1 - s1, p2 - s2)
resultPrecision = min(38, resultScale + maxIntegerDigits)
Wenn resultScale + maxIntegerDigits diese Genauigkeit überschritten 38 wird (die maximale DEZIMAL-Genauigkeit), wird die Genauigkeit begrenzt 38 , und die Skalierung wird reduziert, um ganzzahlige Ziffern beizubehalten.
Der am wenigsten häufig verwendete Typ von Und liegt beispielsweise daran, dass DECIMAL(10, 2) Skalierungsziffern und DECIMAL(12, 5) ganzzahlige Ziffern eine Genauigkeit von DECIMAL(15, 5), die erweitert werden müssen, um max(2, 5) = 5 signifikante Ziffern mit 5 Dezimalstellen zu haltenmax(8, 7) = 8.13158 + 5 = 13
TIME(p)
Der am wenigsten häufig verwendete Typ und TIME(n)TIME(m) ist TIME(max(n, m)).
Der am wenigsten verbreitete Typ von TIME(0) und TIME(6) ist TIME(6)z. B. .
Zusätzliche Regeln
Spezielle Regeln werden angewendet, wenn der kleinste gemeinsame Typ in FLOAT aufgelöst wird. Wenn einer der beitragenden Typen ein genauer numerischer Typ (TINYINT, SMALLINT, INTEGER, BIGINT oder DECIMAL) ist, wird der kleinste gemeinsame Typ per Push auf DOUBLE gesetzt, um einen potenziellen Verlust von Ziffern zu vermeiden.
Wenn der am wenigsten verbreitete Typ eine STRING ist, wird die Sortierung gemäß den Sortierungsrangfolgeregeln berechnet.
Implizites Downcasting und Crosscasting
Azure Databricks nutzt diese Formen der impliziten Umwandlung nur beim Funktions- und Operatoraufruf und nur dort, wo die Absicht eindeutig bestimmt werden kann.
Implizite Abwärtsumwandlung
Implizites Downcasting wandelt automatisch einen höheren Typ in einen niedrigeren Typ um, ohne dass Sie die Umwandlung explizit angeben müssen. Downcasting ist praktisch, birgt aber das Risiko unerwarteter Laufzeitfehler, wenn der tatsächliche Wert im niedrigeren Typ nicht darstellbar ist.
Bei Downcasting wird die Typrangfolgenliste in umgekehrter Reihenfolge angewendet. Die Datentypen
GEOGRAPHYundGEOMETRYwerden niemals heruntergestuft.
Implizites Crosscasting
Implizites Crosscasting wandelt einen Wert aus einer Typfamilie in eine andere um, ohne dass Sie die Umwandlung explizit angeben müssen.
Azure Databricks unterstützt implizites Crosscasting von:
- Beliebiger einfacher Typ, außer
BINARY, ,GEOGRAPHYundGEOMETRY, bisSTRING. - A
STRINGfür einen beliebigen einfachen Typ mit Ausnahme vonGEOGRAPHYundGEOMETRY.
- Beliebiger einfacher Typ, außer
Umwandlung beim Funktionsaufruf
Bei einer aufgelösten Funktion oder einem aufgelösten Operator gelten die folgenden Regeln in der Reihenfolge, in der sie aufgelistet sind, für jedes Parameter-Argumentpaar:
Wenn ein unterstützter Parametertyp Teil des Typrangfolgediagramms des Arguments ist, stuft Azure Databricks das Argument zu diesem Parametertyp hoch.
In den meisten Fällen gibt die Funktionsbeschreibung explizit die unterstützten Typen oder die Kette an, z. B. „beliebiger numerischer Typ“.
So wird z. B. sin(expr) ausgeführt auf
DOUBLE, akzeptiert jedoch jede Zahl.Wenn der erwartete Parametertyp ein
STRINGist und das Argument ein einfacher Typ ist, wandelt Azure Databricks das Argument in den Zeichenfolgenparametertyp um.Beispielsweise wird bei substr(str, start, len) erwartet, dass
streinSTRINGist. Stattdessen können Sie einen numerischen oder datetime-Typ übergeben.Wenn der Argumenttyp ein
STRINGund der erwartete Parametertyp ein einfacher Typ ist, überschreibt Azure Databricks das Zeichenfolgenargument auf den breitesten unterstützten Parametertyp.Beispielsweise erwartet date_add(Datum, Tage) ein
DATEund einINTEGER.Wenn Sie
date_add()mit zweiSTRINGaufrufen, konvertiert Azure Databricks den ersten zuSTRINGund den zweitenDATEzu einemSTRING.Wenn die Funktion einen numerischen Typ erwartet, z. B. einen
INTEGERTyp oder einenDATETyp, aber das Argument ist ein allgemeinerer Typ, z. B. einDOUBLEoderTIMESTAMP, Azure Databricks setzt das Argument implizit in diesen Parametertyp herunter .Ein date_add(Datum, Tage) erwartet z. B. ein
DATEund einINTEGER.Wenn Sie
date_add()mit einerTIMESTAMPund einerBIGINTaufrufen, wandelt Azure Databricks die zu einerTIMESTAMPum, indem es die Zeitkomponente entfernt, und wandelt dieDATEzu einerBIGINTum.Andernfalls löst Azure Databricks einen Fehler aus.
Examples
Die coalesce Funktion akzeptiert einen beliebigen Satz von Argumenttypen, solange sie einen am wenigsten häufig verwendeten Typ aufweisen.
Der Ergebnistyp ist der kleinste gemeinsame Typ der Argumente.
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: DATATYPE_MISMATCH.DATA_DIFF_TYPES
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: CAST_INVALID_INPUT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
-- Two distinct explicit collations result in an error
> SELECT collation(coalesce('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE));
Error: COLLATION_MISMATCH.EXPLICIT
-- The resulting collation between two distinct implicit collations is indeterminate
> SELECT collation(coalesce(c1, c2))
FROM VALUES('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE) AS T(c1, c2);
NULL
-- The resulting collation between a explicit and an implicit collations is the explicit collation.
> SELECT collation(coalesce(c1 COLLATE UTF8_BINARY, c2))
FROM VALUES('hello',
'world' COLLATE UNICODE) AS T(c1, c2);
UTF8_BINARY
-- The resulting collation between an implicit and the default collation is the implicit collation.
> SELECT collation(coalesce(c1, 'world'))
FROM VALUES('hello' COLLATE UNICODE) AS T(c1, c2);
UNICODE
-- The resulting collation between the default collation and the indeterminate collation is the default collation.
> SELECT collation(coalesce(coalesce('hello' COLLATE UTF8_BINARY, 'world' COLLATE UNICODE), 'world'));
UTF8_BINARY
-- Least common type between GEOGRAPHY(srid) and GEOGRAPHY(ANY)
> SELECT typeof(coalesce(st_geogfromtext('POINT(1 2)'), to_geography('POINT(3 4)'), NULL));
geography(any)
-- Least common type between GEOMETRY(srid1) and GEOMETRY(srid2)
> SELECT typeof(coalesce(st_geomfromtext('POINT(1 2)', 4326), st_geomfromtext('POINT(3 4)', 3857), NULL));
geometry(any)
-- Least common type between GEOMETRY(srid1) and GEOMETRY(ANY)
> SELECT typeof(coalesce(st_geomfromtext('POINT(1 2)', 4326), to_geometry('POINT(3 4)'), NULL));
geometry(any)
-- Least common type between DECIMAL(10,2) and DECIMAL(12,5): precision accommodates both
> SELECT typeof(coalesce(CAST(1 AS DECIMAL(10,2)), CAST(1 AS DECIMAL(12,5))));
DECIMAL(15,5)
-- Least common type between TIME(0) and TIME(6) is the wider precision
> SELECT typeof(coalesce(TIME'10:30:00', CAST(TIME'10:30:00.123456' AS TIME(6))));
TIME(6)
Die substring Funktion erwartet Argumente vom Typ STRING für die Zeichenfolge und INTEGER für die Start- und Längenparameter.
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
|| (VERKETTEN) ermöglicht implizites Crosscasting zu Zeichenfolgen.
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
date_add kann aufgrund eines impliziten Downcastings mit einer TIMESTAMP oder BIGINT aufgerufen werden.
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add kann durch implizites Cross-Casting mit STRING aufgerufen werden.
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05