Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Das Zwischenspeichern ist ein wichtiges Verfahren zur Verbesserung der Leistung von Data Warehouse-Systemen, da hierdurch vermieden wird, dass dieselben Daten mehrmals neu berechnet oder abgerufen werden müssen. In Databricks SQL kann das Zwischenspeichern die Abfrageausführung erheblich beschleunigen und den benötigten Speicherplatz minimieren, was zu niedrigeren Kosten und einer effizienteren Ressourcennutzung führt. Jede Zwischenspeicherungsebene verbessert die Abfrageleistung, minimiert die Clusternutzung und optimiert die Ressourcennutzung und sorgt so für eine nahtlose Data Warehouse-Erfahrung.
Das Zwischenspeichern bietet zahlreiche Vorteile in Data Warehouses; hierzu zählen:
- Geschwindigkeit: Durch das Speichern von Abfrageergebnissen oder häufig verwendeten Daten im Arbeitsspeicher oder auf anderen schnellen Speichermedien kann das Zwischenspeichern die Ausführungszeiten von Abfragen erheblich reduzieren. Diese Speicherung ist besonders für wiederholte Abfragen von Vorteil, da das System die zwischengespeicherten Ergebnisse schnell abrufen kann, anstatt sie neu berechnen zu müssen.
- Geringere Clusterauslastung: Zwischenspeichern minimiert den Bedarf an zusätzlichen Computeressourcen, da zuvor berechnete Ergebnisse wiederverwendet werden. Dies reduziert die gesamte Warehouse-Uptime und den Bedarf an zusätzlichen Computeclustern, was zu Kosteneinsparungen und einer besseren Ressourcenzuweisung führt.
Abfragecache-Typen in Databricks SQL
Databricks SQL führt verschiedene Arten der Abfragezwischenspeicherung aus.
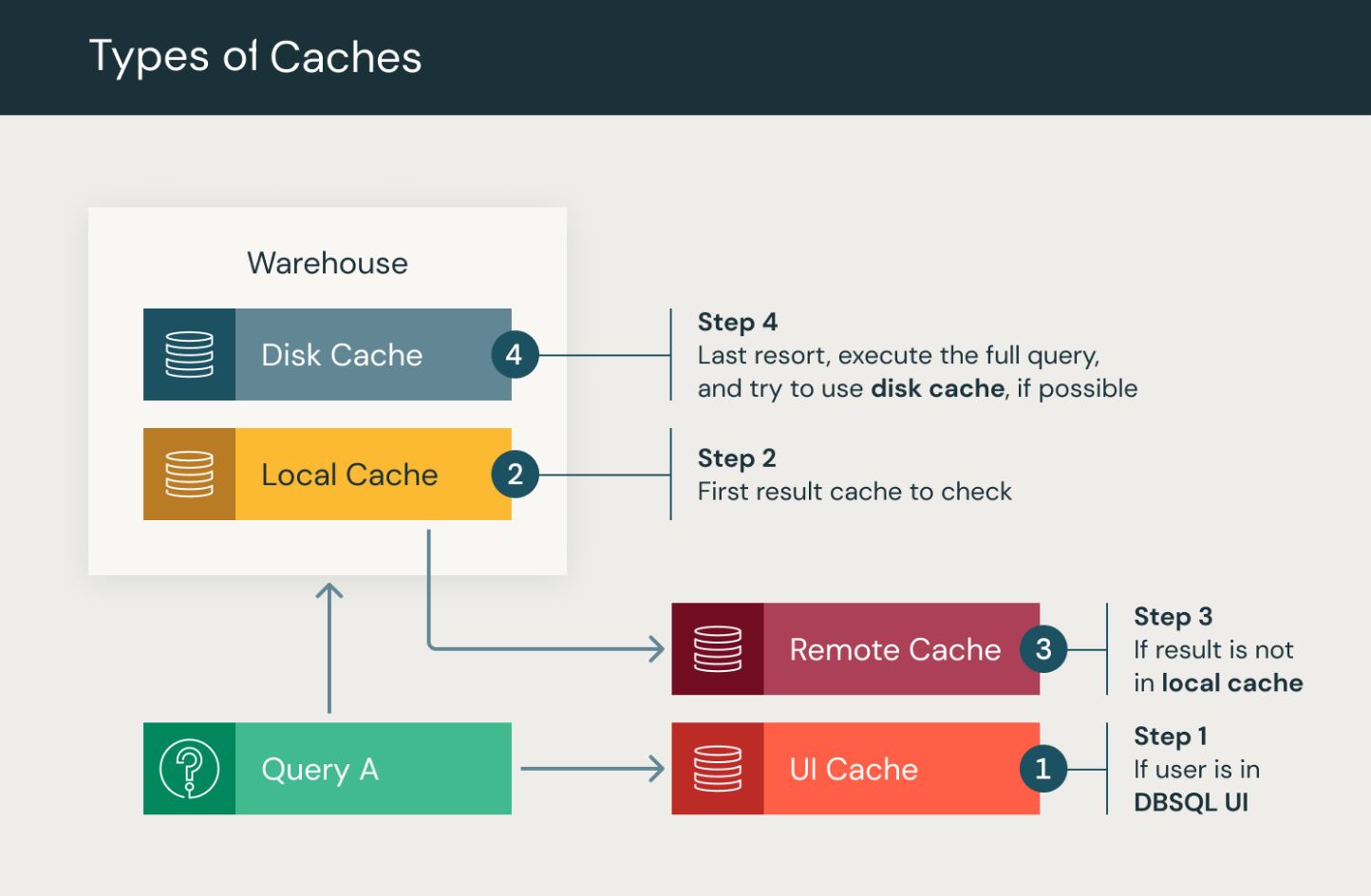
Sql-UI-Cache für Databricks: Zwischenspeichern von Abfrageergebnissen und SQL-Editorvisualisierungen pro Benutzer in der SQL-Benutzeroberfläche von Databricks. Wenn ein Benutzer zuerst eine SQL-Abfrage oder ein älteres SQL-Dashboard öffnet, zeigt der SQL-UI-Cache für Databricks das neueste Abfrageergebnis an, einschließlich der Ergebnisse aus geplanten Ausführungen.
Note
Der SQL-UI-Cache für Databricks gilt nicht für AI/BI-Dashboards (früher Lakeview-Dashboards). AI/BI-Dashboards haben ein eigenes Cacheverhalten. Siehe Optimierung und Zwischenspeicherung von Datensätzen.
Der Databricks SQL-UI-Cache verfügt über einen Lebenszyklus von maximal 7 Tagen. Der Cache befindet sich in Ihrem Azure Databricks-Dateisystem in Ihrem Konto. Sie können Abfrageergebnisse löschen, indem Sie die Abfrage, die nicht mehr gespeichert werden soll, erneut ausführen. Nach der erneuten Ausführung werden die alten Abfrageergebnisse aus dem Cache entfernt. Darüber hinaus wird der Cache ungültig, nachdem die zugrunde liegenden Tabellen aktualisiert wurden.
Ergebniscache: Zwischenspeichern von Abfrageergebnissen jedes Clusters für alle Abfragen über SQL-Warehouses. Das Zwischenspeichern von Ergebnissen umfasst sowohl lokale als auch Remoteergebniscaches, die zusammenarbeiten, um die Abfrageleistung zu verbessern, indem Abfrageergebnisse im Arbeitsspeicher oder in Remotespeichermedien gespeichert werden.
- Lokaler Cache: Der lokale Cache ist ein Speichercache, der Abfrageergebnisse für die Lebensdauer des Clusters speichert oder bis der Cache voll ist, je nachdem, was zuerst kommt. Dieser Cache ist nützlich, um sich wiederholende Abfragen zu beschleunigen, sodass die gleichen Ergebnisse nicht erneut berechnet werden müssen. Sobald der Cluster jedoch beendet oder neu gestartet wurde, wird der Cache bereinigt, und alle Abfrageergebnisse werden entfernt.
- Remoteergebniscache: Der Remoteergebniscache ist ein serverloses Cachesystem, das Abfrageergebnisse speichert, indem sie als Arbeitsbereichssystemdaten gespeichert werden. Daher wird dieser Cache nicht durch das Beenden oder Neustarten eines SQL-Warehouses ungültig. Der Remoteergebniscache behebt einen häufigen Problempunkt beim Zwischenspeichern von Abfrageergebnissen im Arbeitsspeicher, der nur verfügbar bleibt, solange die Computeressourcen ausgeführt werden. Der Remote-Cache ist ein persistenter, gemeinsam genutzter Cache über alle Warehouses hinweg in einem Databricks-Arbeitsbereich.
Für den Zugriff auf den Remote-Ergebniscache ist ein laufendes Warehouse erforderlich. Beim Verarbeiten einer Abfrage sucht ein Cluster zunächst in seinem lokalen Cache und dann bei Bedarf im Remoteergebniscache. Nur wenn das Abfrageergebnis nicht im Cache zwischengespeichert wird, wird die Abfrage ausgeführt. Sowohl der lokale als auch der Remotecache haben einen Lebenszyklus von 24 Stunden, der mit dem Cacheeintrag beginnt. Der Remoteergebniscache wird durch das Beenden oder Neustarten eines SQL-Warehouses beibehalten. Beide Caches werden ungültig, wenn die zugrunde liegenden Tabellen aktualisiert werden.
Der Remote-Ergebniscache ist für Abfragen verfügbar, die ODBC-/JDBC-Clients und die SQL-Statement-API verwenden.
Um das Zwischenspeichern von Abfrageergebnissen zu deaktivieren, können Sie
SET use_cached_result = falseim SQL-Editor ausführen.Wichtig
Sie sollten diese Option nur für Tests oder Benchmarktests verwenden.
Festplatten-Cache: Lokale SSD-Zwischenspeicherung von Daten aus dem Datenspeicher für Abfragen über SQL-Warehouses. Der Datenträgercache wurde entwickelt, um die Abfrageleistung zu verbessern, indem Daten auf dem Datenträger gespeichert werden, sodass beschleunigte Datenlesevorgänge ermöglicht werden. Daten werden automatisch zwischengespeichert, wenn Dateien abgerufen werden, wobei ein schnelles Zwischenformat verwendet wird. Indem Kopien der Dateien im lokalen Speicher gespeichert werden, der an Computeknoten angefügt ist, wird durch den Datenträgercache sichergestellt, dass sich die Daten näher bei den Workern befinden, was zu einer verbesserten Abfrageleistung führt. Siehe Optimieren der Leistung mit Caching in Azure Databricks.
Neben seiner primären Funktion erkennt der Datenträgercache automatisch Änderungen an den zugrunde liegenden Datendateien. Wenn Änderungen erkannt werden, wird der Cache ungültig. Der Datenträgercache verwendet dieselben Lebenszyklusmerkmale wie der lokale Ergebniscache. Das bedeutet, dass der Cache beim Beenden oder Neustarten des Clusters bereinigt wird und neu gefüllt werden muss.
Das Zwischenspeichern der Abfrageergebnisse und der Datenträgercache wirken sich auf Abfragen auf der Databricks SQL-Benutzeroberfläche sowie bei BI und anderen externen Clients aus.