Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden Visualisierungen von früheren Versionen von Azure Databricks beschrieben. Informationen zur aktuellen Unterstützung für Visualisierungen finden Sie im SQL-Editor oder einem Notebook unter "Visualisierungen in Databricks-Notebooks und dem SQL-Editor". Informationen zum Arbeiten mit Visualisierungen in AI/BI-Dashboards finden Sie unter AI/BI-Dashboardvisualisierungstypen.
Azure Databricks unterstützt außerdem nativ Visualisierungsbibliotheken in Python und R und ermöglicht Ihnen das Installieren und Verwenden von Bibliotheken von Drittanbietern.
Erstellen einer Legacyvisualisierung
Klicken Sie auf +, und wählen Sie Legacy Visualization (Legacyvisualisierung) aus, um eine Legacyvisualisierung aus einer Ergebniszelle zu erstellen.
Legacyvisualisierungen unterstützen zahlreiche Plotarten:
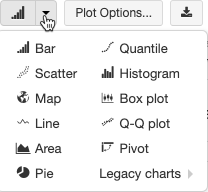
Auswählen und Konfigurieren eines Legacydiagrammtyps
Wählen Sie zum Auswählen eines Balkendiagramms das Balkendiagrammsymbol  aus:
aus:
Um einen anderen Plottyp auszuwählen, wählen Sie ![]() rechts neben dem Balkendiagramm und dann den Plottyp aus.
rechts neben dem Balkendiagramm und dann den Plottyp aus.
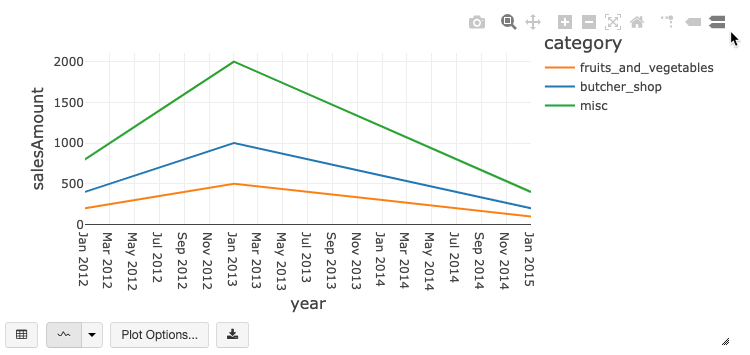
Symbolleiste für Legacydiagramme
Linien- und Balkendiagramme verfügen über eine integrierte Symbolleiste, die einen umfangreichen Satz von Interaktionen auf der Clientseite unterstützt.
Klicken Sie zum Konfigurieren eines Diagramms auf Diagrammoptionen....
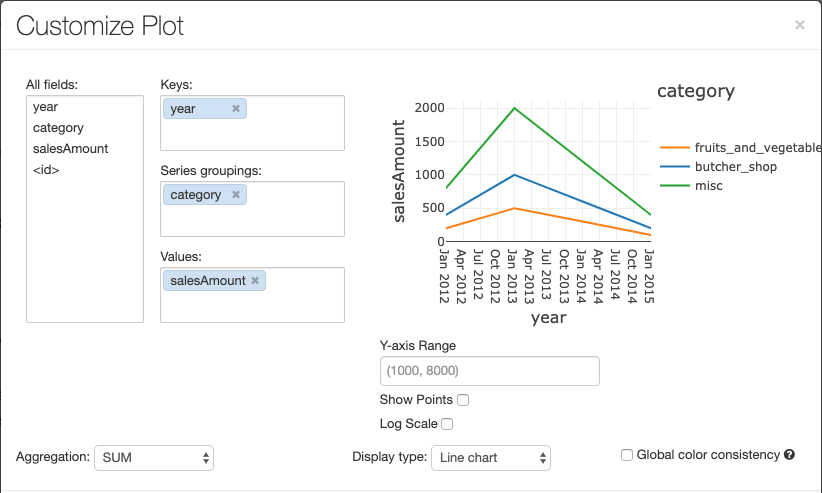
Das Liniendiagramm bietet einige benutzerdefinierte Diagrammoptionen: Festlegen des Bereichs der y-Achse, Anzeigen und Ausblenden von Punkten und Anzeigen der y-Achse mit logarithmischer Skalierung.
Informationen zu älteren Diagrammtypen finden Sie unter folgendem Link:
Diagrammübergreifende Farbkonsistenz
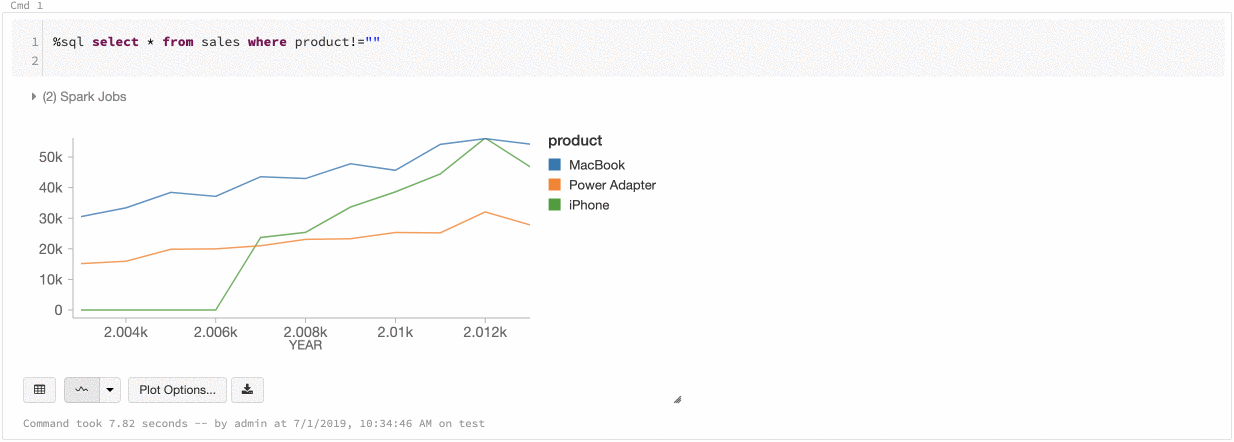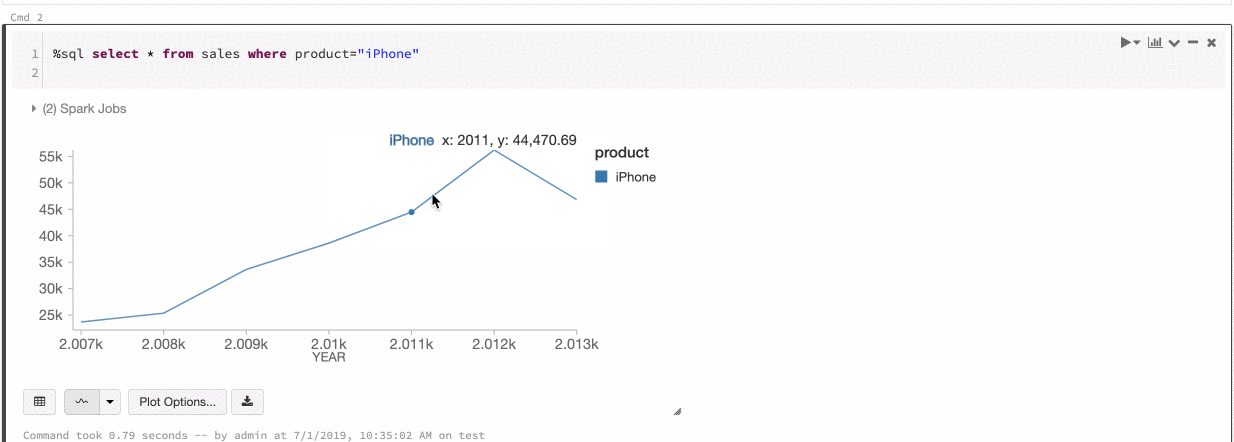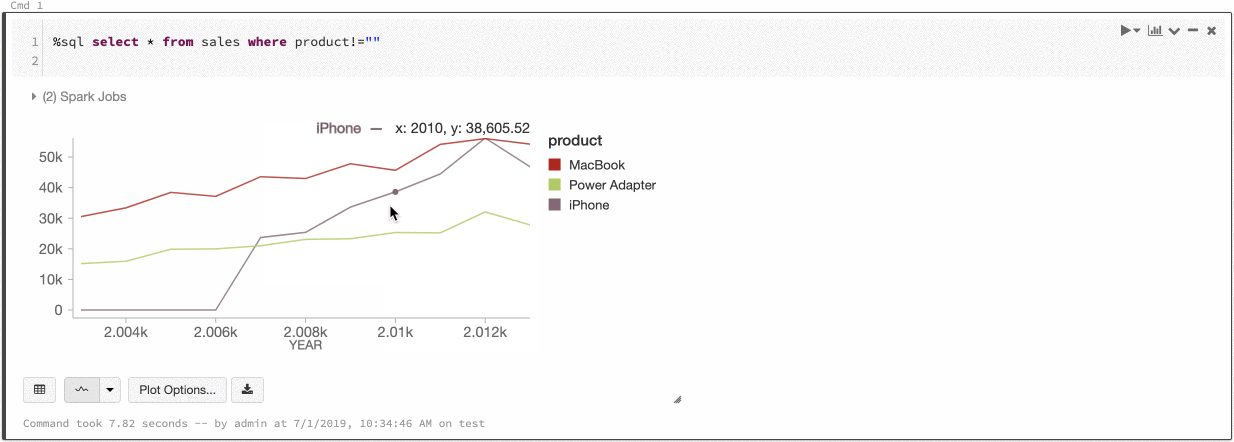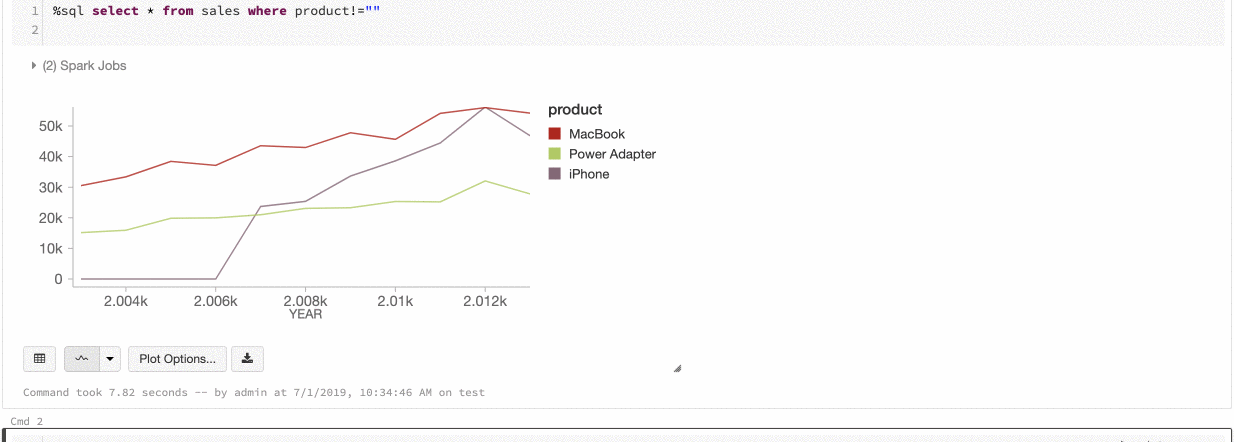
Azure Databricks unterstützt zwei Arten von Farbkonsistenzen in Legacydiagrammen: „series set“ und „global“.
Durch die Farbkonsistenz series set wird dieselbe Farbe demselben Wert zugewiesen, wenn Sie über Reihen mit denselben Werten verfügen, die jedoch unterschiedlich angeordnet sind (Beispiel: A = ["Apple", "Orange", "Banana"] und B = ["Orange", "Banana", "Apple"]). Die Werte werden vor dem Zeichnen sortiert, sodass beide Legenden auf die gleiche Weise sortiert werden (["Apple", "Banana", "Orange"]) und dieselben Werte dieselben Farben erhalten. Wenn Sie jedoch eine Datenreihe C = ["Orange", "Banana"]haben, wäre die Farbe nicht mit dem Satz A konsistent, da der Satz nicht identisch ist. Der Sortierungsalgorithmus würde die erste Farbe „Banana“ in Gruppe C zuweisen, die zweite Farbe aber „Banana“ in Gruppe A. Wenn diese Reihen farblich konsistent sein sollen, können Sie angeben, dass Diagramme eine globale Farbkonsistenz aufweisen sollen.
Durch die Farbkonsistenz global wird jeder Wert immer derselben Farbe zugeordnet, unabhängig davon, welche Werte in den Reihen enthalten sind. Um diese Eigenschaft für alle Diagramme zu aktivieren, wählen Sie das Kontrollkästchenfür die globale Farbkonsistenz aus.
Hinweis
Um diese Konsistenz zu erreichen, wendet Azure Databricks ein direktes Hashing zwischen Werten und Farben an. Um Konflikte zu vermeiden (bei denen zwei Werte exakt dieselbe Farbe haben), entspricht der Hash einer umfangreichen Farbpalette. Dies hat jedoch den Nebeneffekt, dass keine brillanten oder leicht unterscheidbaren Farben garantiert werden können. Bei Verwendung einer großen Farbpalette gibt es immer Farben, die ziemlich ähnlich aussehen.
Machine Learning-Visualisierungen
Zusätzlich zu den Standarddiagrammtypen unterstützen Legacyvisualisierungen die folgenden Machine Learning-Trainingsparameter und -Trainingsergebnisse:
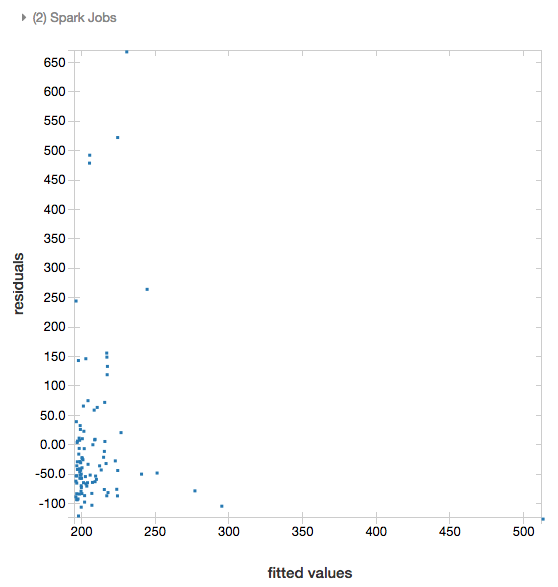
Residualdaten
Für lineare und logistische Regressionen können Sie einen Plot mit angepassten Daten und Restdaten rendern. Stellen Sie das Modell und den DataFrame bereit, um diesen Plot zu erhalten.
Im folgenden Beispiel wird mit einer linearen Regression der Zusammenhang zwischen der Stadtbevölkerung und den Immobilienpreisen hergestellt. Anschließend werden die Restdaten im Vergleich zu den angepassten Daten dargestellt.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
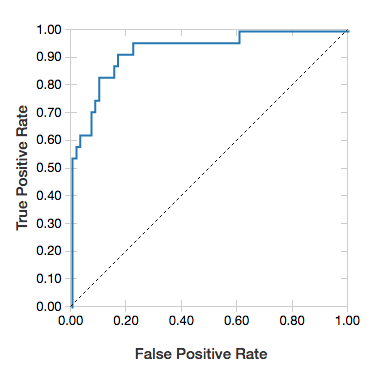
ROC-Kurven
Für logistische Regressionen können Sie eine ROC-Kurve rendern. Wenn Sie diesen Plot erhalten möchten, geben Sie das Modell, die aufbereiteten Eingabedaten für die fit-Methode und den Parameter "ROC" an.
Im folgenden Beispiel wird eine Klassifizierung entwickelt, die anhand verschiedener Attribute einer Person vorhersagt, ob deren Jahreseinkommen <=50.000 oder >50.000 beträgt. Das Dataset „adult“ ist von Volkszählungsdaten abgeleitet und umfasst Daten zu 48.842 Personen und deren Jahreseinkommen.
Im Beispielcode dieses Abschnitts wird die One-Hot-Codierung verwendet.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
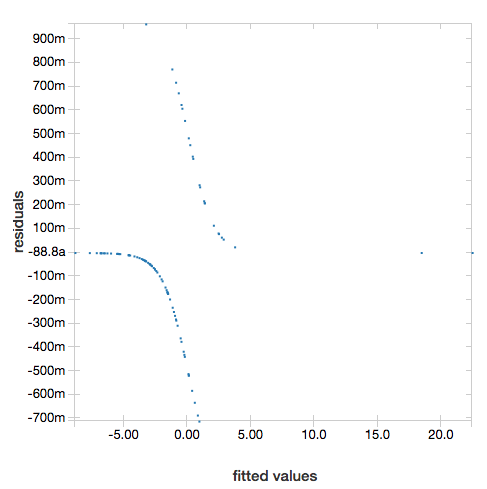
Um die Restdaten anzuzeigen, lassen Sie den "ROC"-Parameter weg:
display(lrModel, preppedDataDF)
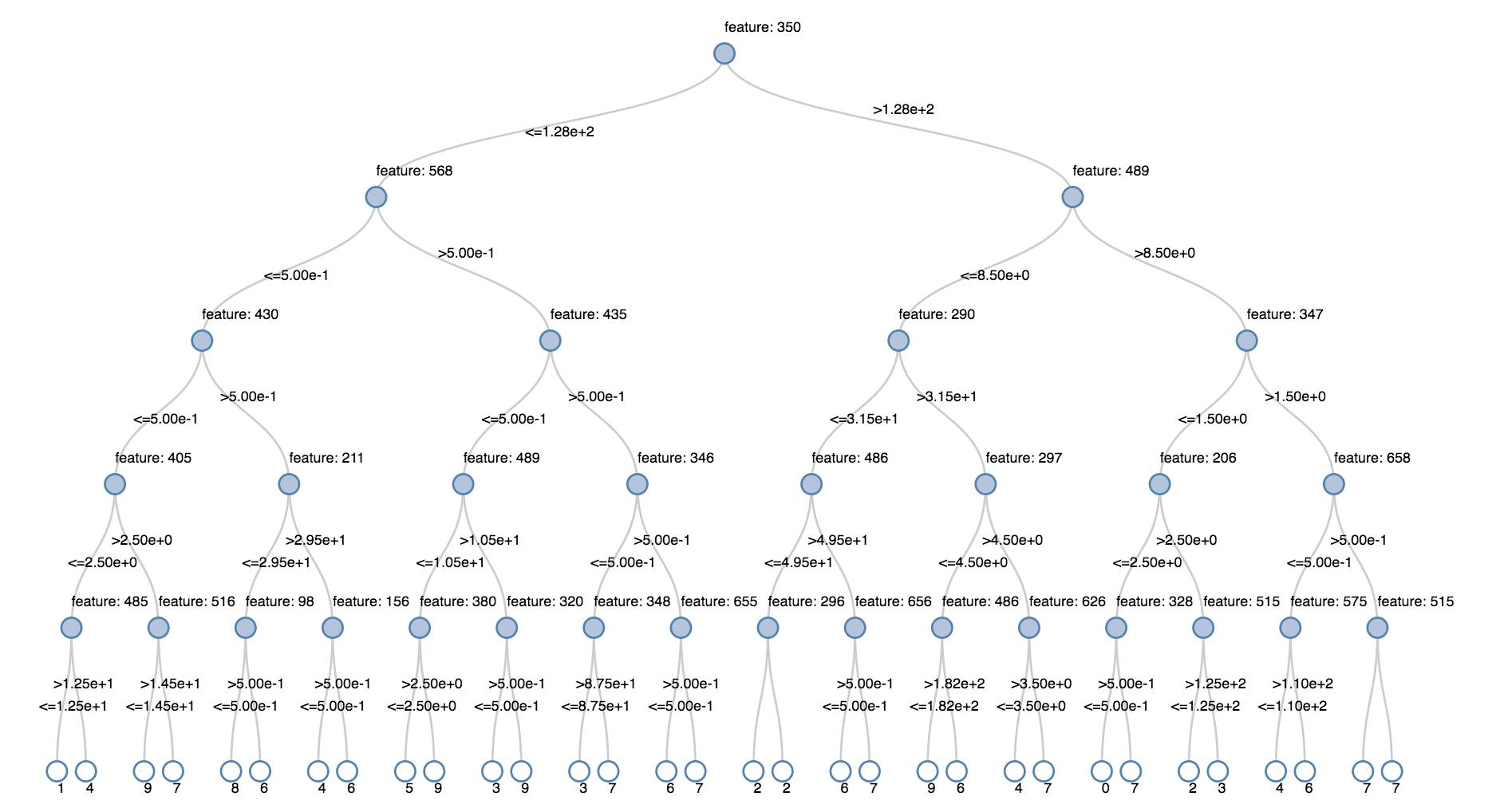
Entscheidungsbäume
Legacy-Visualisierungen unterstützen das Rendern eines Entscheidungsbaums.
Geben Sie das Entscheidungsstrukturmodell an, um diese Visualisierung zu erhalten.
In den folgenden Beispielen wird eine Struktur trainiert. Das Ziel ist es, handgeschriebene Ziffern (0–9) aus dem MNIST-Bilddataset zu erkennen und dann die Struktur anzuzeigen.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
DataFrames für strukturiertes Streaming
Wenn Sie das Ergebnis einer Streamingabfrage in Echtzeit visualisieren möchten, können Sie mithilfe von display einen Datenrahmen für strukturiertes Streaming in Scala und Python anzeigen.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display unterstützt die folgenden optionalen Parameter:
-
streamName: der Name der Streamingabfrage -
trigger(Scala) undprocessingTime(Python): Definiert, wie häufig die Streamingabfrage ausgeführt wird. Wird kein Wert angegeben, überprüft das System die Verfügbarkeit neuer Daten, sobald die vorherige Verarbeitung abgeschlossen ist. Um die Kosten für die Produktion zu senken, wird von Databricks empfohlen, immer ein Triggerintervall festzulegen. Das Standardtriggerintervall beträgt 500 ms. -
checkpointLocation: der Speicherort, in den das System alle Prüfpunktinformationen schreibt. Ist kein Wert angegeben, generiert das System automatisch einen temporären Prüfpunktspeicherort auf DBFS. Damit Ihr Stream die Datenverarbeitung an dem Punkt fortsetzen kann, an dem er aufgehört hat, müssen Sie einen Prüfpunktspeicherort angeben. Databricks empfiehlt, in der Produktion immer die OptioncheckpointLocationanzugeben.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Weitere Informationen zu diesen Parametern finden Sie unter Starten von Streamingabfragen.
displayHTML-Funktion
Notebooks in einer Azure Databricks-Programmiersprache (Python, R und Scala) unterstützen HTML-Grafiken mithilfe der displayHTML-Funktion, an die Sie beliebigen HTML-, CSS- oder JavaScript-Code übergeben können. Diese Funktion unterstützt interaktive Grafiken mithilfe von JavaScript-Bibliotheken wie D3.
Beispiele für die Verwendung von displayHTML finden Sie unter:
Hinweis
Der iframe displayHTML wird von der Domäne databricksusercontent.com bereitgestellt, und die iframe-Sandbox enthält das Attribut allow-same-origin. Auf databricksusercontent.com muss über Ihren Browser zugegriffen werden können. Wenn es momentan in Ihrem Unternehmensnetzwerk blockiert ist, muss es auf die Allowlist gesetzt werden.
Bilder
Spalten, die Bilddatentypen enthalten, werden als Rich-HTML gerendert. Azure Databricks versucht, Bildminiaturansichten für DataFrame-Spalten zu rendern, die dem ImageSchema von Spark entsprechen.
Das Rendern von Miniaturbildern wird für Bilder unterstützt, die erfolgreich mit der spark.read.format('image')-Funktion eingelesen wurden. Bei Bildwerten, die auf andere Weise generiert wurden, unterstützt Azure Databricks das Rendern von 1-, 3- oder 4-Kanal-Bildern (wobei jeder Kanal aus einem einzelnen Byte besteht). Dabei gelten folgende Einschränkungen:
-
1-Kanal-Bilder: Das Feld
modemuss „0“ lauten. Die Felderheight,widthundnChannelsmüssen exakte Angaben zu den binären Bilddaten im Felddataenthalten. -
3-Kanal-Bilder: Das Feld
modemuss „16“ lauten. Die Felderheight,widthundnChannelsmüssen exakte Angaben zu den binären Bilddaten im Felddataenthalten. Das Felddatamuss Pixeldaten in 3-Byte-Blöcken enthalten, wobei die Kanalreihenfolge für jedes Pixel(blue, green, red)lautet. -
4-Kanal-Bilder: Das Feld
modemuss gleich 24 sein. Die Felderheight,widthundnChannelsmüssen exakte Angaben zu den binären Bilddaten im Felddataenthalten. Das Felddatamuss Pixeldaten in 4-Byte-Blöcken enthalten, wobei die Kanalreihenfolge für jedes Pixel(blue, green, red, alpha)lautet.
Beispiel
Angenommen, Sie verfügen über einen Ordner mit einigen Bildern:

Wenn Sie die Bilder in einen DataFrame einlesen und dann den DataFrame anzeigen, rendert Azure Databricks Miniaturansichten der Bilder:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualisierungen in Python
Inhalt dieses Abschnitts:
Seegeboren
Sie können auch andere Python-Bibliotheken verwenden, um Plots zu generieren. Databricks Runtime umfasst die Seaborn-Visualisierungsbibliothek. Importieren Sie die Bibliothek, erstellen Sie einen Plot, und übergeben Sie den Plot an die display-Funktion, um einen Seaborn-Plot zu erstellen.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
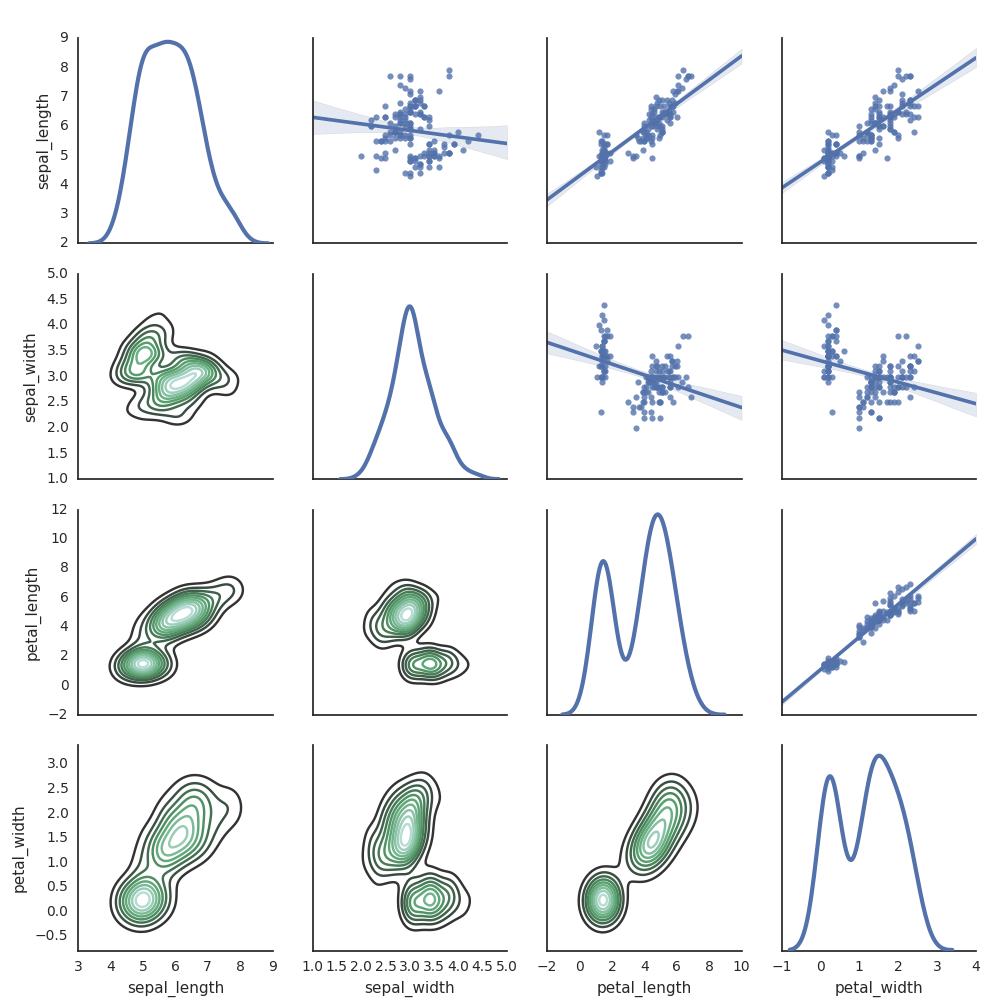
Andere Python-Bibliotheken
Visualisierungen in R
Verwenden Sie die display-Funktion wie folgt, um Daten in R darzustellen:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Sie können die plot-Standardfunktion in R verwenden.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
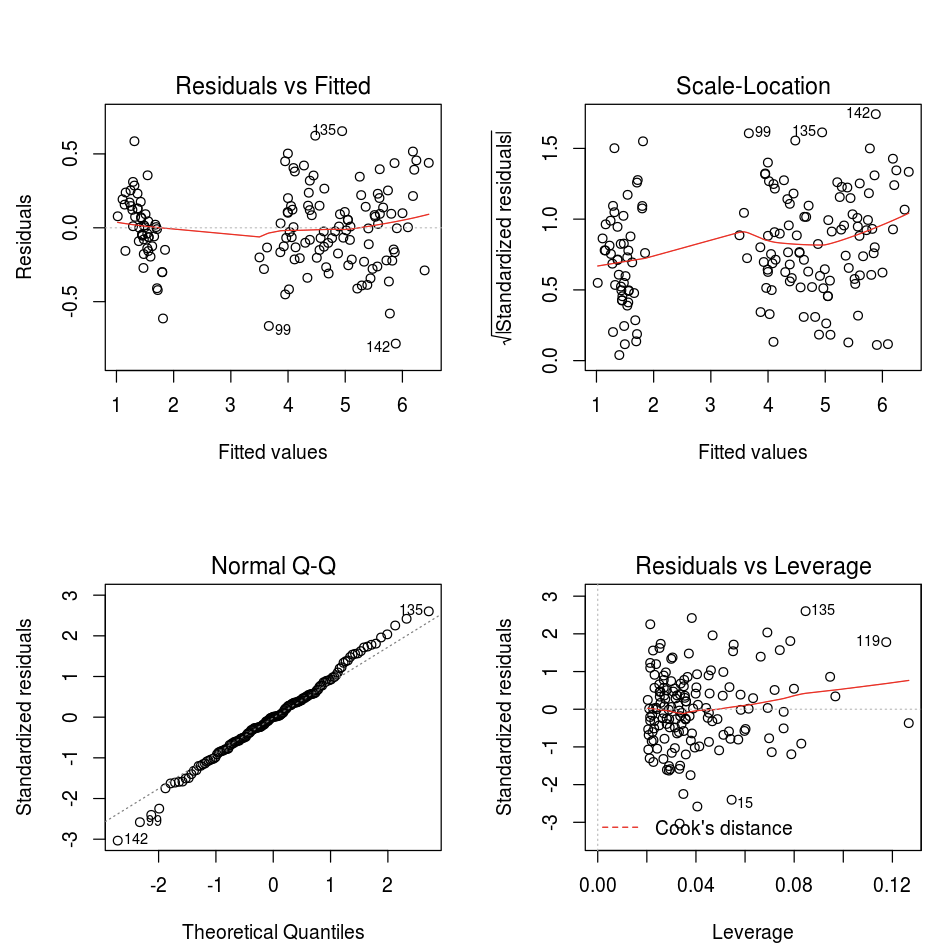
Sie können auch ein beliebiges R-Visualisierungspaket verwenden. Das R-Notebook erfasst den resultierenden Plot als .png und zeigt ihn inline an.
Inhalt dieses Abschnitts:
Gitter
Das Lattice-Paket unterstützt Gitterdiagramme, die eine Variable oder die Beziehung zwischen Variablen auf der Grundlage mindestens einer anderen Variablen darstellen.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
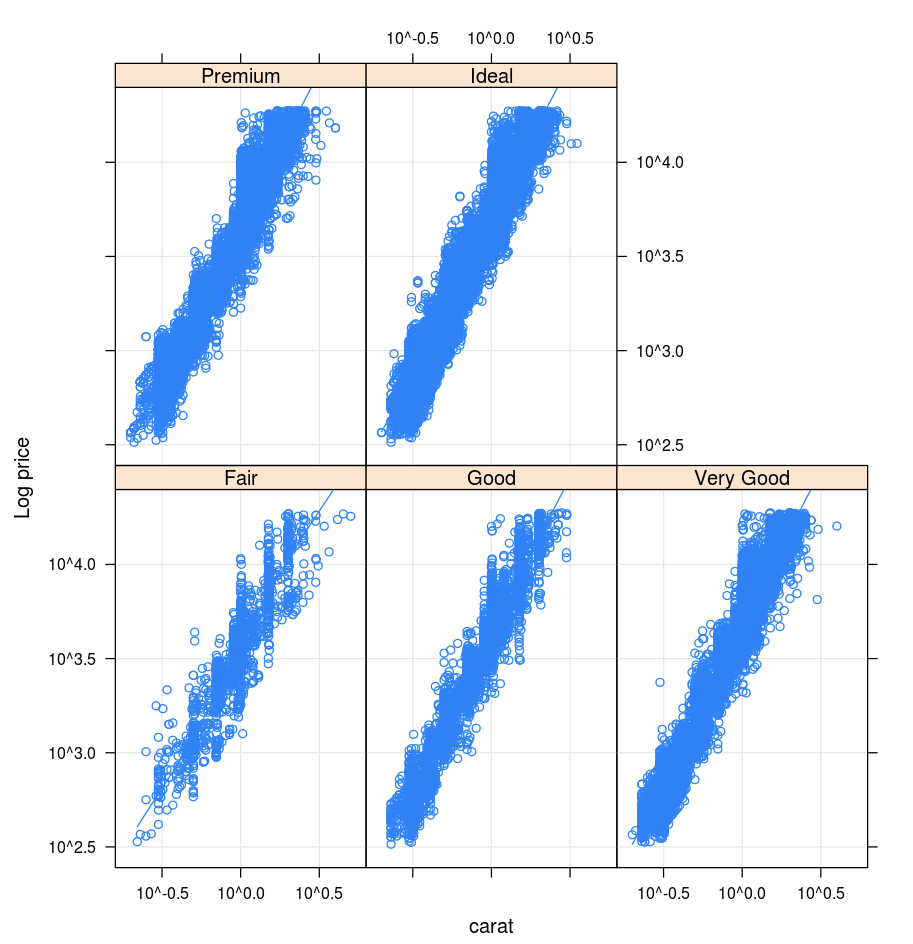
DandEFA
Das DandEFA-Paket unterstützt Dandelion-Plots.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
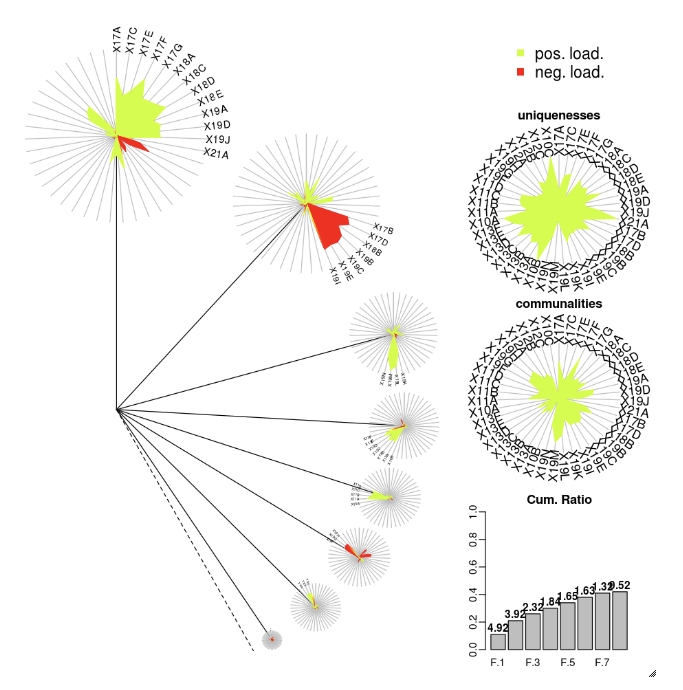
Plotly
Das Plotly-R-Paket nutzt htmlwidgets für R. Installationsanweisungen und ein Notebook finden Sie unter htmlwidgets.
Andere R-Bibliotheken
Visualisierungen in Scala
Verwenden Sie die display-Funktion wie folgt, um Daten in Scala darzustellen:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Deep Dive Notebooks für Python und Scala
Ausführliche Informationen zu Python-Visualisierungen finden Sie im folgenden Notebook:
Ausführliche Informationen zu Scala-Visualisierungen finden Sie im folgenden Notebook: