Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird die Erstellung einer produktionsfähigen RAG-Lösung (Retrieval Augmented Generation, RAG) erläutert.
Informationen zu zwei Möglichkeiten zum Erstellen einer App "Chat über Ihre Daten" – einer der wichtigsten generativen KI-Anwendungsfälle für Unternehmen – finden Sie unter Augment LLMs mit RAG oder Feinabstimmung.
Das folgende Diagramm zeigt die wichtigsten Schritte der RAG:
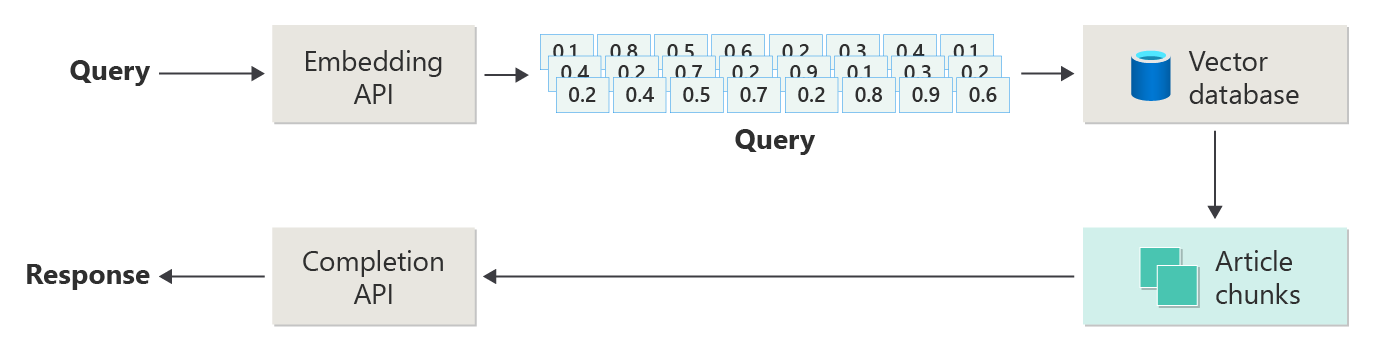
Dieser Prozess wird als naive RAG bezeichnet. Es hilft Ihnen, die grundlegenden Teile und Rollen in einem RAG-basierten Chatsystem zu verstehen.
Reale RAG-Systeme benötigen mehr Vorverarbeitung und Nachbearbeitung, um Artikel, Abfragen und Antworten zu verarbeiten. Das nächste Diagramm zeigt eine realistischere Einrichtung, die als erweiterte RAG bezeichnet wird:

Dieser Artikel bietet Ihnen ein einfaches Framework, um die Wichtigsten Phasen in einem echten RAG-basierten Chatsystem zu verstehen:
- Aufnahmephase
- Inferenz-Pipeline-Phase
- Auswertungsphase
Datenerfassung
Die Aufnahme bedeutet, die Dokumente Ihrer Organisation zu speichern, damit Sie schnell Antworten für Benutzer finden können. Die wichtigste Herausforderung besteht darin, die Teile der Dokumente zu finden und zu verwenden, die den einzelnen Fragen am besten entsprechen. Die meisten Systeme verwenden Vektoreinbettungen und Kosinusgleichheitssuche, um Fragen an Inhalte abzugleichen. Sie erhalten bessere Ergebnisse, wenn Sie den Inhaltstyp (z. B. Muster und Format) verstehen und Ihre Daten gut in der Vektordatenbank organisieren.
Konzentrieren Sie sich beim Einrichten der Aufnahme auf die folgenden Schritte:
- Vorverarbeitung und Extraktion von Inhalten
- Chunking-Strategie
- Abteilungsorganisation
- Updatestrategie
Vorverarbeitung und Extraktion von Inhalten
Der erste Schritt in der Aufnahmephase besteht darin, den Inhalt aus Ihren Dokumenten vorzuverarbeiten und zu extrahieren. Dieser Schritt ist entscheidend, da sichergestellt wird, dass der Text sauber, strukturiert und bereit für die Indizierung und den Abruf ist.
Saubere und genaue Inhalte sorgen dafür, dass ein RAG-basiertes Chatsystem besser funktioniert. Betrachten Sie zunächst die Form und den Stil der Dokumente, die Sie indizieren möchten. Folgen sie einem Setmuster, z. B. der Dokumentation? Wenn nicht, welche Fragen könnten diese Dokumente beantworten?
Richten Sie mindestens Die Aufnahmepipeline für Folgendes ein:
- Standardisieren von Textformaten
- Behandeln von Sonderzeichen
- Entfernen von nicht verknüpften oder alten Inhalten
- Nachverfolgen verschiedener Inhaltsversionen
- Behandeln von Inhalten mit Registerkarten, Bildern oder Tabellen
- Extrahieren von Metadaten
Einige dieser Informationen, z. B. Metadaten, können während des Abrufs und der Auswertung hilfreich sein, wenn Sie sie mit dem Dokument in der Vektordatenbank beibehalten. Sie können ihn auch mit dem Textabschnitt kombinieren, um die Vektoreinbettung des Abschnitts zu verbessern.
Chunking-Strategie
Entscheiden Sie als Entwickler, wie sie große Dokumente in kleinere Abschnitte aufteilen. Durch Blockierung können Sie die relevantesten Inhalte an das LLM senden, damit sie Benutzerfragen besser beantworten kann. Denken Sie auch darüber nach, wie Sie die Blöcke verwenden werden, nachdem Sie sie erhalten haben. Probieren Sie gängige Branchenmethoden aus, und testen Sie Ihre Blockierungsstrategie in Ihrer Organisation.
Denken Sie bei der Blöcke an Folgendes:
- Optimierung der Blockgröße: Wählen Sie die beste Blockgröße aus, und teilen Sie sie – nach Abschnitt, Absatz oder Satz.
- Überlappende und gleitende Fensterblöcke: Entscheiden Sie, ob Blöcke getrennt oder überlappen sollen. Sie können auch einen Gleitfensteransatz verwenden.
- Small2Big: Wenn Sie nach Satz geteilt werden, ordnen Sie den Inhalt so an, dass Sie in der Nähe Sätze oder den vollständigen Absatz finden können. Wenn Sie diesem zusätzlichen Kontext für die LLM geben, kann dies dazu beitragen, besser zu antworten. Weitere Informationen finden Sie im nächsten Abschnitt.
Abteilungsorganisation
In einem RAG-System erleichtert ihnen die Organisation Ihrer Daten in der Vektordatenbank das Auffinden der richtigen Informationen. Hier sind einige Möglichkeiten zum Einrichten ihrer Indizes und Suchvorgänge:
- Hierarchische Indizes: Verwenden Sie Ebenen von Indizes. Ein Zusammenfassungsindex der obersten Ebene findet schnell einen kleinen Satz wahrscheinlicher Blöcke. Ein Index der zweiten Ebene verweist auf die genauen Daten. Diese Einrichtung beschleunigt Suchvorgänge, indem die Optionen eingegrenzt werden, bevor sie im Detail angezeigt werden.
- Spezielle Indizes: Wählen Sie Indizes aus, die Ihren Daten entsprechen. Verwenden Sie z. B. graphbasierte Indizes, wenn Sich Ihre Blöcke miteinander verbinden, z. B. in Zitatnetzwerken oder Wissensdiagrammen. Verwenden Sie relationale Datenbanken, wenn sich Ihre Daten in Tabellen befinden, und filtern Sie mit SQL-Abfragen.
- Hybridindizes: Kombinieren verschiedener Indizierungsmethoden. Verwenden Sie beispielsweise zuerst einen Zusammenfassungsindex, dann einen diagrammbasierten Index, um Verbindungen zwischen Blöcken zu untersuchen.
Ausrichtungsoptimierung
Machen Sie abgerufene Blöcke relevanter und genauer, indem Sie sie mit den Arten von Fragen abgleichen, die sie beantworten. Eine Möglichkeit besteht darin, eine Beispielfrage für jeden Block zu erstellen, der zeigt, welche Frage am besten beantwortet wird. Dieser Ansatz hilft auf verschiedene Arten:
- Verbesserte Übereinstimmung: Während des Abrufs vergleicht das System die Frage des Benutzers mit diesen Beispielfragen, um den besten Block zu finden. Diese Technik verbessert die Relevanz der Ergebnisse.
- Schulungsdaten für Machine Learning-Modelle: Diese Frageabschnittspaare helfen dabei, die Machine Learning-Modelle im RAG-System zu trainieren. Die Modelle lernen, welche Blöcke welche Arten von Fragen beantworten.
- Direkte Abfragebehandlung: Wenn die Frage eines Benutzers mit einer Beispielfrage übereinstimmt, kann das System schnell den richtigen Block finden und verwenden, um die Antwort zu beschleunigen.
Jede Beispielfrage des Abschnitts fungiert als Bezeichnung, die den Abrufalgorithmus leitet. Die Suche wird fokussierter und bewusster im Kontext. Diese Methode eignet sich gut, wenn Blöcke viele verschiedene Themen oder Informationstypen abdecken.
Aktualisieren von Strategien
Wenn Ihre Organisation Dokumente häufig aktualisiert, müssen Sie Die Datenbank auf dem neuesten Stand halten, damit der Retriever immer die neuesten Informationen finden kann. Die Retriever-Komponente ist der Teil des Systems, der die Vektordatenbank durchsucht und Ergebnisse zurückgibt. Hier sind einige Möglichkeiten, ihre Vektordatenbank auf dem neuesten Stand zu halten:
Inkrementelle Aktualisierungen:
- Regelmäßige Intervalle: Festlegen von Aktualisierungen für die Ausführung in einem Zeitplan (z. B. täglich oder wöchentlich) basierend auf der Häufigkeit der Änderung von Dokumenten. Diese Aktion hält die Datenbank aktuell.
- Triggerbasierte Updates: Richten Sie automatische Updates ein, wenn jemand ein Dokument hinzufügt oder ändert. Das System indiziert nur die betroffenen Teile neu.
Teilweise Aktualisierungen:
- Selektive Neuindizierung: Aktualisieren Sie nur die Teile der Datenbank, die sich geändert haben, nicht das Ganze. Diese Technik spart Zeit und Ressourcen, insbesondere für große Datasets.
- Delta-Codierung: Speichern Sie nur die Änderungen zwischen alten und neuen Dokumenten, wodurch die Menge der zu verarbeitenden Daten reduziert wird.
Versionsverwaltung:
- Momentaufnahme: Speichern Von Versionen Ihrer Dokumentenmappe zu unterschiedlichen Zeiten. Mit dieser Aktion können Sie bei Bedarf zurückwechseln oder frühere Versionen wiederherstellen.
- Dokumentversionskontrolle: Verwenden Sie ein Versionssteuerungssystem, um Änderungen nachzuverfolgen und den Verlauf Ihrer Dokumente beizubehalten.
Echtzeitupdates:
- Streamverarbeitung: Verwenden Sie die Datenstromverarbeitung, um die Vektordatenbank in Echtzeit zu aktualisieren, während sich Dokumente ändern.
- Liveabfragen: Verwenden Sie Liveabfragen, um up-to-Datumsantworten zu erhalten, manchmal mischen Sie Livedaten mit zwischengespeicherten Ergebnissen zur Geschwindigkeit.
Optimierungstechniken:
- Batchverarbeitung: Gruppieren Sie Änderungen, und wenden Sie sie zusammen, um Ressourcen zu sparen und den Aufwand zu reduzieren.
-
Hybride Ansätze: Verschiedene Strategien kombinieren:
- Verwenden Sie inkrementelle Updates für kleine Änderungen.
- Verwenden Sie die vollständige Neuindizierung für wichtige Updates.
- Verfolgen und dokumentieren Sie wichtige Änderungen an Ihren Daten.
Wählen Sie die Updatestrategie oder die Mischung aus, die Ihren Anforderungen entspricht. Nachdenken:
- Dokumentkorpusgröße
- Aktualisierungshäufigkeit
- Echtzeitdatenanforderungen
- Verfügbare Ressourcen
Überprüfen Sie diese Faktoren für Ihre Anwendung. Jede Methode hat Kompromisse in Komplexität, Kosten und wie schnell Aktualisierungen angezeigt werden.
Rückschlusspipeline
Ihre Artikel werden jetzt in einer Vektordatenbank unterteilt, vektorisiert und gespeichert. Konzentrieren Sie sich als Nächstes darauf, die besten Antworten von Ihrem System zu erhalten.
Um genaue und schnelle Ergebnisse zu erhalten, denken Sie an die folgenden wichtigen Fragen:
- Ist die Frage des Benutzers klar und wahrscheinlich die richtige Antwort?
- Bricht die Frage unternehmensregeln?
- Können Sie die Frage neu schreiben, damit das System bessere Übereinstimmungen finden kann?
- Stimmen die Ergebnisse aus der Datenbank mit der Frage überein?
- Sollten Sie die Ergebnisse ändern, bevor Sie sie an die LLM senden, um sicherzustellen, dass die Antwort relevant ist?
- Adressieren Sie die Antwort des LLM vollständig auf die Frage des Benutzers?
- Entspricht die Antwort den Regeln Ihrer Organisation?
Die gesamte Ableitungspipeline funktioniert in Echtzeit. Es gibt keine möglichkeit, Ihre Vorverarbeitungs- und Nachbearbeitungsschritte einzurichten. Sie verwenden eine Mischung aus Code und LLM-Aufrufen. Einer der größten Trade-Offs ist das Ausgleichsgenauigkeit und die Einhaltung von Kosten und Geschwindigkeit.
Sehen wir uns Strategien für jede Phase der Ableitungspipeline an.
Schritte zur Vorverarbeitung von Abfragen
Die Vorverarbeitung von Abfragen beginnt direkt nach dem Senden einer Frage durch den Benutzer:

Diese Schritte helfen, sicherzustellen, dass die Frage des Benutzers zu Ihrem System passt und bereit ist, die besten Artikelabschnitte mithilfe der Kosinusähnlichkeit oder der Suche "nächster Nachbar" zu finden.
Richtlinienüberprüfung: Verwenden Sie Logik, um unerwünschte Inhalte zu erkennen und zu entfernen oder zu kennzeichnen, z. B. personenbezogene Daten, schlechte Sprache oder Versuche, Sicherheitsregeln zu brechen (als "Jailbreaking" bezeichnet).
Abfrageumschreibung: Ändern Sie die Frage bei Bedarf – erweitern Sie Akronyme, entfernen Sie Slang, oder ändern Sie sie neu, um sich auf größere Ideen zu konzentrieren (Schritt-zurück-Eingabeaufforderung).
Eine spezielle Version der Rückforderung ist hypothetische Dokumenteinbettungen (HyDE). HyDE hat die LLM-Antwort auf die Frage, macht eine Einbettung aus dieser Antwort und durchsucht dann die Vektordatenbank damit.
Unterabfragen
Unterabfragen unterteilen eine lange oder komplexe Frage in kleinere, einfachere Fragen. Das System beantwortet jede kleine Frage und kombiniert dann die Antworten.
Wenn jemand beispielsweise fragt: "Wer hat wichtigere Beiträge zur modernen Physik geleistet, Albert Einstein oder Niels Bohr?" können Sie es in:
- Unterabfrage 1: "Was hat Albert Einstein zur modernen Physik beigetragen?"
- Unterabfrage 2: "Was hat Niels Bohr zur modernen Physik beigetragen?"
Die Antworten können folgendes umfassen:
- Für Einstein: die Theorie der Relativität, der photoelektrische Effekt und E=mc^2.
- Für Bohr: das Wasserstoffatommodell, die Arbeit zur Quantenmechanik und das Prinzip der Komplementarität.
Anschließend können Sie Nachverfolgungsfragen stellen:
- Unterabfrage 3: "Wie änderten Einsteins Theorien die moderne Physik?"
- Unterabfrage 4: "Wie änderten Bohrs Theorien die moderne Physik?"
Diese Nachverfolgungen betrachten den Effekt jedes Wissenschaftlers wie:
- Wie Einsteins Arbeit zu neuen Ideen in der Kosmologie und Quantentheorie führte
- Wie Bohrs Arbeit uns dabei half, Atome und Quantenmechanik zu verstehen
Das System kombiniert die Antworten, um eine vollständige Antwort auf die ursprüngliche Frage zu geben. Diese Methode erleichtert die Beantwortung komplexer Fragen, indem sie in klare, kleinere Teile unterteilt werden.
Abfragerouter
Manchmal befindet sich Ihr Inhalt in mehreren Datenbanken oder Suchsystemen. Verwenden Sie in diesen Fällen einen Abfragerouter. Ein Abfragerouter wählt die beste Datenbank oder den besten Index aus, um jede Frage zu beantworten.
Ein Abfragerouter funktioniert, nachdem der Benutzer eine Frage gestellt hat, aber bevor das System nach Antworten sucht.
So funktioniert ein Abfragerouter:
- Abfrageanalyse: Das LLM oder ein anderes Tool untersucht die Frage, um herauszufinden, welche Art von Antwort erforderlich ist.
- Indexauswahl: Der Router wählt einen oder mehrere Indizes aus, die der Frage entsprechen. Einige Indizes sind besser für Fakten, andere für Meinungen oder spezielle Themen.
- Abfrageversand: Der Router sendet die Frage an den ausgewählten Index oder die Indizes.
- Ergebnisaggregation: Das System sammelt und kombiniert die Antworten aus den Indizes.
- Antwortgenerierung: Das System erstellt eine klare Antwort mithilfe der gefundenen Informationen.
Verwenden Sie unterschiedliche Indizes oder Suchmaschinen für:
- Spezialisierung der Datentypen: Einige Indizes konzentrieren sich auf Nachrichten, andere auf akademische Veröffentlichungen oder auf spezielle Datenbanken wie medizinische oder rechtliche Informationen.
- Abfragetypoptimierung: Einige Indizes sind schnell für einfache Fakten (z. B. Datumsangaben), während andere komplexe oder expertenfragen behandeln.
- Algorithmische Unterschiede: Verschiedene Suchmaschinen verwenden unterschiedliche Methoden, z. B. Vektorsuche, Stichwortsuche oder erweiterte semantische Suche.
Beispielsweise könnten Sie in einem medizinischen Beratungssystem folgendes haben:
- Ein Forschungspapierindex für technische Details
- Ein Fallstudie-Index für praxisnahe Beispiele
- Allgemeiner Integritätsindex für grundlegende Fragen
Wenn jemand nach den Auswirkungen eines neuen Medikaments fragt, sendet der Router die Frage an den Forschungspapierindex. Wenn es um häufige Symptome geht, wird der allgemeine Gesundheitsindex für eine einfache Antwort verwendet.
Schritte nach dem Abrufen von Verarbeitungsschritten
Nach dem Abrufen erfolgt die Verarbeitung nach dem Suchen nach Inhaltsblöcken in der Vektordatenbank:

Überprüfen Sie als Nächstes, ob diese Blöcke für die LLM-Eingabeaufforderung nützlich sind, bevor Sie sie an die LLM senden.
Beachten Sie die folgenden Punkte:
- Zusätzliche Informationen können die wichtigsten Details ausblenden.
- Irrelevante Informationen können die Antwort noch schlimmer machen.
Achten Sie auf die Nadel in einem Heuhaufenproblem : LLMs achten oft mehr auf den Anfang und das Ende einer Eingabeaufforderung als die Mitte.
Denken Sie auch daran, dass das maximale Kontextfenster des LLM und die Anzahl der Token, die für lange Eingabeaufforderungen benötigt werden, insbesondere im Maßstab.
Verwenden Sie zum Behandeln dieser Probleme eine Pipeline nach dem Abruf mit Schritten wie:
- Filterergebnisse: Behalten Sie nur Blöcke bei, die der Abfrage entsprechen. Ignorieren Sie den Rest beim Erstellen der LLM-Eingabeaufforderung.
- Neubewertung: Platzieren Sie die relevantesten Blöcke am Anfang und Ende der Eingabeaufforderung.
- Eingabeaufforderungskomprimierung: Verwenden Sie ein kleines, günstiges Modell, um Blöcke in einer einzigen Eingabeaufforderung zusammenzufassen und zu kombinieren, bevor Sie es an die LLM senden.
Schritte nach abschluss der Verarbeitung
Nach abschluss der Verarbeitung erfolgt nach der Frage des Benutzers, und alle Inhaltsblöcke gehen zur LLM:

Nachdem das LLM eine Antwort gibt, überprüfen Sie die Genauigkeit. Eine Pipeline nach abschluss der Verarbeitung kann Folgendes umfassen:
- Fact check: Look for statements in the answer that claim to be facts, then check if they're true. Wenn eine Faktenüberprüfung fehlschlägt, können Sie die LLM erneut fragen oder eine Fehlermeldung anzeigen.
- Richtlinienüberprüfung: Stellen Sie sicher, dass die Antwort keine schädlichen Inhalte für den Benutzer oder Ihre Organisation enthält.
Auswertung
Die Auswertung eines Systems wie dies ist komplexer als das Ausführen regulärer Komponenten- oder Integrationstests. Überlegen Sie sich diese Fragen:
- Sind die Benutzer mit den Antworten zufrieden?
- Sind die Antworten korrekt?
- Wie sammeln Sie Benutzerfeedback?
- Gibt es Regeln darüber, welche Daten Sie sammeln können?
- Können Sie jeden Schritt sehen, den das System ausgeführt hat, wenn Antworten falsch sind?
- Behalten Sie detaillierte Protokolle für die Ursachenanalyse bei?
- Wie aktualisieren Sie das System, ohne die Dinge noch schlimmer zu machen?
Erfassen und Handeln von Feedback von Benutzern
Arbeiten Sie mit dem Datenschutzteam Ihrer Organisation zusammen, um Feedbackerfassungstools, Systemdaten und Protokollierung für forensische Und Ursachenanalysen einer Abfragesitzung zu entwerfen.
Der nächste Schritt besteht darin, eine Bewertungspipeline zu erstellen. Eine Bewertungspipeline macht es einfacher und schneller, Feedback zu überprüfen und herauszufinden, warum die KI bestimmte Antworten gegeben hat. Überprüfen Sie jede Antwort, um zu sehen, wie die KI sie produziert hat, ob die richtigen Inhaltsblöcke verwendet wurden und wie die Dokumente aufgeteilt wurden.
Suchen Sie außerdem nach zusätzlichen Vorverarbeitungs- oder Nachbearbeitungsschritten, die die Ergebnisse verbessern könnten. Diese enge Überprüfung findet häufig Inhaltslücken, insbesondere, wenn keine gute Dokumentation für die Frage eines Benutzers vorhanden ist.
Sie benötigen eine Bewertungspipeline, um diese Aufgaben im großen Maßstab zu verarbeiten. Eine gute Pipeline verwendet benutzerdefinierte Tools, um die Antwortqualität zu messen. Es hilft Ihnen zu sehen, warum die KI eine bestimmte Antwort gegeben hat, welche Dokumente verwendet wurden und wie gut die Ableitungspipeline funktioniert hat.
Goldenes Dataset
Eine Möglichkeit, zu überprüfen, wie gut ein RAG-Chatsystem funktioniert, ist die Verwendung eines goldenen Datasets. Ein goldenes Dataset ist eine Reihe von Fragen mit genehmigten Antworten, hilfreichen Metadaten (z. B. Thema und Fragetyp), Links zu Quelldokumenten und verschiedene Möglichkeiten, wie Benutzer dasselbe stellen könnten.
Ein goldenes Dataset zeigt das "best case scenario". Entwickler verwenden es, um zu sehen, wie gut das System funktioniert und Tests ausführt, wenn sie neue Features oder Updates hinzufügen.
Bewerten von Schäden
Harms Modeling hilft Ihnen, mögliche Risiken in einem Produkt zu erkennen und Möglichkeiten zu planen, um sie zu reduzieren.
Ein Bewertungstool für Schäden sollte die folgenden wichtigen Features enthalten:
- Identifizierung von Stakeholdern: Hilft Ihnen, alle betroffenen Personen, die von der Technologie betroffen sind, auflisten und zu gruppieren, einschließlich direkter Benutzer, personen, die indirekt, zukünftige Generationen und sogar die Umgebung betroffen sind.
- Schadenkategorien und Beschreibungen: Listet mögliche Schäden auf, z. B. Datenverlust, emotionale Not oder wirtschaftliche Schäden. Führt Sie durch Beispiele und hilft Ihnen, sowohl erwartete als auch unerwartete Probleme zu berücksichtigen.
- Schweregrad- und Wahrscheinlichkeitsbewertungen: Hilft Ihnen zu beurteilen, wie schwerwiegend und wahrscheinlich jeder Schaden ist, damit Sie entscheiden können, was zuerst behoben werden soll. Sie können Daten verwenden, um Ihre Auswahl zu unterstützen.
- Entschärfungsstrategien: Schlägt Möglichkeiten vor, Risiken zu reduzieren, z. B. das Ändern des Systementwurfs, das Hinzufügen von Schutzmaßnahmen oder die Verwendung anderer Technologien.
- Feedbackmechanismen: Ermöglicht Es Ihnen, Feedback von Projektbeteiligten zu sammeln, damit Sie den Prozess weiter verbessern können, während Sie mehr erfahren.
- Dokumentation und Berichterstellung: Erleichtert das Erstellen von Berichten, die zeigen, was Sie gefunden haben und was Sie getan haben, um Risiken zu reduzieren.
Diese Features helfen Ihnen, Risiken zu finden und zu beheben, und sie helfen Ihnen auch, ethischere und verantwortungsvollere KI zu schaffen, indem Sie von Anfang an über alle möglichen Auswirkungen nachdenken.
Weitere Informationen finden Sie in den folgenden Artikeln:
Testen und Überprüfen der Sicherheitsvorkehrungen
Red-Teaming ist entscheidend – es bedeutet, wie ein Angreifer zu handeln, um Schwachstellen im System zu finden. Dieser Schritt ist besonders wichtig, um das Jailbreak zu stoppen. Tipps zum Planen und Verwalten der roten Teamerstellung für verantwortungsvolle KI finden Sie unter Planning red teaming for large language models (LLMs) and their applications.
Entwickler sollten RAG-Systemsicherungen in verschiedenen Szenarien testen, um sicherzustellen, dass sie funktionieren. Dieser Schritt macht das System stärker und hilft auch bei der Feinabstimmung der Reaktionen auf ethische Standards und Regeln.
Abschließende Überlegungen zum Anwendungsdesign
Im Folgenden finden Sie einige wichtige Punkte, die Sie beim Entwerfen Ihrer App berücksichtigen können:
- Generative KI unvorstellbar
- Benutzeraufforderungsänderungen und deren Auswirkungen auf Zeit und Kosten
- Parallele LLM-Anforderungen für eine schnellere Leistung
Um eine generative KI-App zu erstellen, schauen Sie sich "Erste Schritte mit Dem Chat" an, indem Sie Ihr eigenes Datenbeispiel für Python verwenden. Das Lernprogramm ist auch für .NET-, Java-und JavaScript-verfügbar.