Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erstellen Sie einen intelligenten HR-Assistenten mit LangChain.js und Azure-Diensten. Dieser Agent hilft Mitarbeitern im fiktiven NorthWind-Unternehmen, Antworten auf Personalfragen zu finden, indem sie die Unternehmensdokumentation durchsuchen.
Sie verwenden Azure KI-Suche , um relevante Dokumente und Azure OpenAI zu finden, um genaue Antworten zu generieren. Das LangChain.js Framework behandelt die Komplexität der Agent-Orchestrierung, sodass Sie sich auf Ihre spezifischen Geschäftsanforderungen konzentrieren können.
Sie lernen Folgendes:
- Bereitstellen von Azure-Ressourcen mithilfe der Azure Developer CLI
- Erstellen eines LangChain.js-Agents, der in Azure-Dienste integriert ist
- Implementierung von Retrieval-Augmented Generation (RAG) für die Dokumentsuche
- Testen und Debuggen Ihres Agents lokal und in Azure
Am Ende dieses Lernprogramms haben Sie eine funktionierende REST-API, die HR-Fragen mithilfe der Dokumentation Ihres Unternehmens beantwortet.
Architekturübersicht
NorthWind basiert auf zwei Datenquellen:
- Personaldokumentation für alle Mitarbeiter zugänglich
- Vertrauliche HR-Datenbank mit vertraulichen Mitarbeiterdaten.
Dieses Lernprogramm konzentriert sich auf die Erstellung eines LangChain.js Agenten, der bestimmt, ob die Frage eines Mitarbeiters mithilfe der öffentlichen PERSONALdokumente beantwortet werden kann. Wenn ja, stellt der LangChain.js Agent die Antwort direkt bereit.
Voraussetzungen
Um dieses Beispiel im Codespace - oder lokalen Entwicklungscontainer zu verwenden, einschließlich des Erstellens und Ausführens des LangChain.js-Agents, benötigen Sie Folgendes:
- Ein aktives Azure-Konto. Erstellen Sie ein kostenloses Konto , wenn Sie kein Konto haben.
Wenn Sie den Beispielcode lokal ohne Einen Entwicklungscontainer ausführen, benötigen Sie auch Folgendes:
- Node.js LTS auf Ihrem System installiert.
- TypeScript zum Schreiben und Kompilieren von TypeScript-Code.
- Azure Developer CLI (azd) installiert und konfiguriert.
- LangChain.js Bibliothek zum Erstellen des Agents.
- Optional: LangSmith zur Überwachung der KI-Nutzung. Sie benötigen den Projektnamen, den Schlüssel und den Endpunkt.
- Optional: LangGraph Studio zum Debuggen von LangGraph-Ketten und LangChain.js-Agents.
Azure-Ressourcen
Die folgenden Azure-Ressourcen sind erforderlich. Sie werden für Sie in diesem Artikel mithilfe der Azure Developer CLI - und Bicep-Vorlagen mit Azure Verified Modules(AVM) erstellt. Die Ressourcen werden sowohl mit kennwortlosem als auch mit schlüsselfreiem Zugriff für Lernzwecke erstellt. In diesem Lernprogramm wird Ihr lokales Entwicklerkonto für die kennwortlose Authentifizierung verwendet:
- Verwaltete Identität für die kennwortlose Authentifizierung bei Azure-Diensten.
- Azure Container Registry zum Speichern des Docker-Images für den Node.js Fastify-API-Server.
- Azure Container-App zum Hosten des Node.js Fastify-API-Servers.
- Azure KI-Suche-Ressource für die Vektorsuche.
-
Azure OpenAI-Ressource mit den folgenden Modellen:
- Ein Einbettungsmodell wie
text-embedding-3-small. - Ein großes Sprachmodell (LLM) wie
'gpt-4.1-mini.
- Ein Einbettungsmodell wie

Agentarchitektur
Das LangChain.js Framework bietet einen Entscheidungsfluss für die Erstellung intelligenter Agenten als LangGraph. In diesem Lernprogramm erstellen Sie einen LangChain.js Agent, der in Azure KI-Suche und Azure OpenAI integriert ist, um HR-bezogene Fragen zu beantworten. Die Architektur des Agents ist dafür konzipiert, um die folgenden Aufgaben zu erfüllen:
- Ermitteln Sie, ob eine Frage für die allgemeine Personaldokumentation, die für alle Mitarbeiter verfügbar ist, relevant ist.
- Abrufen relevanter Dokumente aus Azure KI-Suche basierend auf der Benutzerabfrage.
- Verwenden Sie Azure OpenAI, um eine Antwort basierend auf den abgerufenen Dokumenten und dem LLM-Modell zu generieren.
Schlüsselkomponenten:
Diagrammstruktur: Der LangChain.js Agent wird als Diagramm dargestellt, wobei:
- Knoten führen bestimmte Aufgaben aus, z. B. Entscheidungsfindung oder Abrufen von Daten.
- Edges definieren den Fluss zwischen Knoten und bestimmen die Abfolge von Vorgängen.
Azure KI-Suche Integration:
- Verwendet ein Einbettungsmodell zum Erstellen von Vektoren.
- Fügt HR-Dokumente (*.md, *.pdf) in den Vektorspeicher ein. Zu den Dokumenten gehören:
- Unternehmensinformationen
- Mitarbeiterhandbuch
- Handbuch "Vorteile"
- Mitarbeiterrollenbibliothek
- Ruft relevante Dokumente basierend auf der Benutzeraufforderung ab.
Azure OpenAI-Integration:
- Verwendet ein großes Sprachmodell für Folgendes:
- Bestimmt, ob eine Frage aus unpersönlichen HR-Dokumenten beantwortet werden kann.
- Erstellt eine Antwort basierend auf einer Aufforderung, mithilfe des Kontexts aus Dokumenten und der Benutzerfrage.
- Verwendet ein großes Sprachmodell für Folgendes:
Die folgende Tabelle enthält Beispiele für Benutzerfragen, die sowohl relevant und beantwortbar sind, als auch solche, die nicht aus allgemeinen Personaldokumenten beantwortet werden können.
| Frage | Relevante | Explanation |
|---|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
Yes | Die Hr-Dokumente, z. B. das Mitarbeiterhandbuch, sollten eine Antwort geben. |
How much of my perks + benefits have I spent? |
Nein | Diese Frage erfordert Zugriff auf vertrauliche Mitarbeiterdaten, die sich außerhalb des Umfangs dieses Agents befinden. |
Mithilfe des LangChain.js-Frameworks vermeiden Sie einen Großteil des agentischen Codebausteines, der in der Regel für Agents und die Azure-Dienstintegration erforderlich ist, sodass Sie sich auf Ihre Geschäftsanforderungen konzentrieren können.
Klonen des Beispielcode-Repositorys
Klonen Sie in einem neuen Verzeichnis das Beispiel-Code-Repository, und wechseln Sie in das neue Verzeichnis:
git clone https://github.com/Azure-Samples/azure-typescript-langchainjs.git
cd azure-typescript-langchainjs
Dieses Beispiel enthält den Code, den Sie zum Erstellen sicherer Azure-Ressourcen benötigen, den LangChain.js-Agent mit Azure KI-Suche und Azure OpenAI erstellen und den Agent von einem Node.js Fastify-API-Server verwenden.
Authentifizieren bei der Azure CLI und der Azure Developer CLI
Melden Sie sich mit der Azure Developer CLI bei Azure an, erstellen Sie die Azure-Ressourcen, und stellen Sie den Quellcode bereit. Da der Bereitstellungsprozess sowohl Azure CLI als auch Azure Developer CLI verwendet, melden Sie sich bei Azure CLI an, und konfigurieren Sie dann die Azure Developer CLI so, dass Ihre Authentifizierung über Azure CLI verwendet wird:
az login
azd config set auth.useAzCliAuth true
Erstellen von Ressourcen und Bereitstellen von Code mit azure Developer CLI
Starten Sie den Bereitstellungsprozess, indem Sie den azd up Befehl ausführen:
azd up
Beantworten Sie während des azd up Befehls die Fragen:
-
Neuer Umgebungsname: Geben Sie einen eindeutigen Umgebungsnamen ein, wie z.B.
langchain-agent. Dieser Umgebungsname wird als Teil der Azure-Ressourcengruppe verwendet. - Wählen Sie ein Azure-Abonnement aus: Wählen Sie das Abonnement aus, in dem die Ressourcen erstellt werden.
-
Wählen Sie eine Region aus: z. B.
eastus2.
Die Bereitstellung dauert ungefähr 10-15 Minuten. Die Azure Developer CLI koordiniert den Prozess mithilfe von Phasen und Hooks, die in der azure.yaml Datei definiert sind:
Bereitstellungsphase (entspricht azd provision):
- Erstellt Azure-Ressourcen, die in
infra/main.bicepdefiniert sind- Azure-Container-App
- OpenAI
- KI-Suche
- Containerregistrierung
- Verwaltete Identität
-
Hook nach der Bereitstellung: Überprüft, ob der Azure KI-Suche-Index
northwindbereits vorhanden ist- Wenn der Index nicht vorhanden ist, führen
npm installundnpm run load_dataden Upload von HR-Dokumenten mithilfe des LangChain.js PDF-Loaders und des Embedding-Klienten aus. - Wenn der Index vorhanden ist: Überspringt das Laden von Daten, um Duplikate zu vermeiden (Sie können manuell neu laden, indem Sie den Index löschen oder
npm run load_dataausführen) Bereitstellungsphase (entsprichtazd deploy):
- Wenn der Index nicht vorhanden ist, führen
- Hook vor der Bereitstellung: Erstellt das Docker-Image für den Fastify-API-Server und pusht es in die Azure-Containerregistrierung.
- Stellt den containerisierten API-Server in Azure-Container-Apps bereit.
Nach Abschluss der Bereitstellung werden Umgebungsvariablen und Ressourceninformationen in der .env Datei im Repositorystamm gespeichert. Sie können die Ressourcen im Azure-Portal anzeigen.
Die Ressourcen werden sowohl mit kennwortlosem als auch mit schlüsselfreiem Zugriff für Lernzwecke erstellt. In diesem Einführungslernprogramm wird Ihr lokales Entwicklerkonto für die kennwortlose Authentifizierung verwendet. Verwenden Sie für Produktionsanwendungen nur kennwortlose Authentifizierung mit verwalteten Identitäten. Erfahren Sie mehr über die kennwortlose Authentifizierung.
Lokales Verwenden des Beispielcodes
Nachdem die Azure-Ressourcen erstellt wurden, können Sie den LangChain.js-Agent lokal ausführen.
Installieren von Abhängigkeiten
Installieren Sie die Node.js Pakete für dieses Projekt.
npm installMit diesem Befehl werden die in den beiden
package.jsonDateien impackages-v1Verzeichnis definierten Abhängigkeiten installiert, darunter:-
./packages-v1/server-api:- Fastify für den Webserver
-
./packages-v1/langgraph-agent:- LangChain.js zum Erstellen des Agents
- Azure SDK-Clientbibliothek
@azure/search-documentsfür die Integration mit einer Azure KI-Suche-Ressource. Die Referenzdokumentation ist hier.
-
Erstellen Sie die beiden Pakete: den API-Server und den KI-Agent.
npm run buildDieser Befehl erstellt eine Verknüpfung zwischen den beiden Paketen, damit der API-Server den KI-Agent aufrufen kann.
Lokales Ausführen des API-Servers
Die Azure Developer CLI hat die erforderlichen Azure-Ressourcen erstellt und die Umgebungsvariablen in der Stammdatei .env konfiguriert. Diese Konfiguration umfasste einen Post-Provision-Hook, um die Daten in den Vektorspeicher hochzuladen. Jetzt können Sie den Fastify-API-Server ausführen, auf dem der LangChain.js-Agent gehostet wird. Starten Sie den Fastify-API-Server.
npm run dev
Der Server startet und lauscht auf Port 3000. Sie können den Server testen, indem Sie in Ihrem Webbrowser zu [http://localhost:3000] navigieren. Es sollte eine Willkommensmeldung angezeigt werden, die darauf hinweist, dass der Server läuft.
Verwenden der API zum Stellen von Fragen
Sie können ein Tool wie REST-Client verwenden oder curl eine POST-Anforderung an den Endpunkt mit einem JSON-Text senden, der /ask Ihre Frage enthält.
Rest-Clientabfragen sind im packages-v1/server-api/http Verzeichnis verfügbar.
Beispiel für die Verwendung von curl:
curl -X POST http://localhost:3000/answer -H "Content-Type: application/json" -d "{\"question\": \"Does the NorthWind Health Plus plan cover eye exams?\"}"
Sie sollten eine JSON-Antwort mit der Antwort vom LangChain.js-Agent erhalten.
{
"answer": "Yes, the NorthWind Health Plus plan covers eye exams. According to the Employee Handbook, employees enrolled in the Health Plus plan are eligible for annual eye exams as part of their vision benefits."
}
Im Verzeichnis stehen mehrere Beispielfragen zur Verfügung packages-v1/server-api/http . Öffnen Sie die Dateien in Visual Studio Code mit REST-Client , um sie schnell zu testen.
Grundlegendes zum Anwendungscode
In diesem Abschnitt wird erläutert, wie der LangChain.js-Agent in Azure-Dienste integriert wird. Die Anwendung des Repositorys ist als npm-Arbeitsbereich mit zwei Hauptpaketen organisiert:
Project Root
│
├── packages-v1/
│ │
│ ├── langgraph-agent/ # Core LangGraph agent implementation
│ │ ├── src/
│ │ │ ├── azure/ # Azure service integrations
│ │ │ │ ├── azure-credential.ts # Centralized auth with DefaultAzureCredential
│ │ │ │ ├── embeddings.ts # Azure OpenAI embeddings + PDF loading + rate limiting
│ │ │ │ ├── llm.ts # Azure OpenAI chat completion (key-based & passwordless)
│ │ │ │ └── vector_store.ts # Azure AI Search vector store + indexing + similarity search
│ │ │ │
│ │ │ ├── langchain/ # LangChain agent logic
│ │ │ │ ├── node_get_answer.ts # RAG: retrieves docs + generates answers
│ │ │ │ ├── node_requires_hr_documents.ts # Determines if HR docs needed
│ │ │ │ ├── nodes.ts # LangGraph node definitions + state management
│ │ │ │ └── prompt.ts # System prompts + conversation templates
│ │ │ │
│ │ │ └── scripts/ # Utility scripts
│ │ │ └── load_vector_store.ts # Uploads PDFs to Azure AI Search
│ │ │
│ │ └── data/ # Source documents (PDFs) for vector store
│ │
│ └── server-api/ # Fastify REST API server
│ └── src/
│ └── server.ts # HTTP server with /answer endpoint
│
├── infra/ # Infrastructure as Code
│ └── main.bicep # Azure resources: Container Apps, OpenAI, AI Search, ACR, managed identity
│
├── azure.yaml # Azure Developer CLI config + deployment hooks
├── Dockerfile # Multi-stage Docker build for containerized deployment
└── package.json # Workspace configuration + build scripts
Wichtige Architekturentscheidungen:
- Monorepo-Struktur: npm-Arbeitsbereiche ermöglichen gemeinsame Abhängigkeiten und verlinkte Pakete
-
Trennung von Bedenken: Agentlogik (
langgraph-agent) ist unabhängig vom API-Server (server-api) -
Zentrale Authentifizierung: Dateien in
./langgraph-agent/src/azureunterstützen den schlüsselbasierten und kennwortlosen Authentifizierungsprozess sowie die Azure-Dienstintegration
Authentifizierung bei Azure Services
Die Anwendung unterstützt sowohl schlüsselbasierte als auch kennwortlose Authentifizierungsmethoden, die von der SET_PASSWORDLESS Umgebungsvariable gesteuert werden. Die DefaultAzureCredential-API aus der Azure Identity-Bibliothek wird für die kennwortlose Authentifizierung verwendet, sodass die Anwendung nahtlos in lokalen Entwicklungs- und Azure-Umgebungen ausgeführt werden kann. Sie können diese Authentifizierung im folgenden Codeausschnitt sehen:
import { DefaultAzureCredential } from "@azure/identity";
export const CREDENTIAL = new DefaultAzureCredential();
export const SCOPE_OPENAI = "https://cognitiveservices.azure.com/.default";
export async function azureADTokenProvider_OpenAI() {
const tokenResponse = await CREDENTIAL.getToken(SCOPE_OPENAI);
return tokenResponse.token;
}
Wenn Sie Drittanbieterbibliotheken wie LangChain.js oder die OpenAI-Bibliothek für den Zugriff auf Azure OpenAI verwenden, benötigen Sie eine Tokenanbieterfunktion , anstatt ein Anmeldeinformationsobjekt direkt zu übergeben. Die getBearerTokenProvider-Funktion aus der Azure Identity-Bibliothek löst dieses Problem, indem ein Tokenanbieter erstellt wird, der OAuth 2.0-Bearertoken für einen bestimmten Azure-Ressourcenbereich automatisch abruft und aktualisiert (z. B. "https://cognitiveservices.azure.com/.default"). Sie konfigurieren den Bereich einmal während des Setups, und der Tokenanbieter verarbeitet automatisch alle Tokenverwaltung. Dieser Ansatz funktioniert mit allen Anmeldeinformationen der Azure Identity-Bibliothek, einschließlich verwalteter Identität und Azure CLI-Anmeldeinformationen. Während Azure SDK-Bibliotheken direkt akzeptieren DefaultAzureCredential , erfordern Drittanbieterbibliotheken wie LangChain.js dieses Tokenanbietermuster, um die Authentifizierungslücke zu überbrücken.
Azure KI-Suche-Integration
Die Azure KI-Suche-Ressource speichert Dokumenteinbettungen und ermöglicht die semantische Suche nach relevanten Inhalten. Die Anwendung verwendet LangChains zum Verwalten des Vektorspeichers AzureAISearchVectorStore , ohne dass Sie das Indexschema definieren müssen.
Der Vektorspeicher wird mit Konfiguration für Administratorvorgänge (Schreiben) und Abfragen (Lesen) erstellt, sodass das Laden und Abfragen von Dokumenten unterschiedliche Konfigurationen verwenden kann. Dies ist wichtig, unabhängig davon, ob Sie Schlüssel oder kennwortlose Authentifizierung mit verwalteten Identitäten verwenden.
Die Azure Developer CLI-Bereitstellung enthält einen Hook nach der Bereitstellung, der die Dokumente mit LangChain.js PDF-Ladeprogramm und Einbettungsclient in den Vektorspeicher hochlädt. Dieser Hook nach der Bereitstellung ist der letzte Schritt des azd up Befehls, nachdem die Azure KI-Suche-Ressource erstellt wurde. Das Dokumentladeskript verwendet Batchverarbeitungs- und Wiederholungslogik, um Dienstratengrenzwerte zu verarbeiten.
postdeploy:
posix:
sh: bash
run: |
echo "Checking if vector store data needs to be loaded..."
# Check if already loaded
INDEX_CREATED=$(azd env get-values | grep INDEX_CREATED | cut -d'=' -f2 || echo "false")
if [ "$INDEX_CREATED" = "true" ]; then
echo "Index already created. Skipping data load."
echo "Current document count: $(azd env get-values | grep INDEX_DOCUMENT_COUNT | cut -d'=' -f2)"
else
echo "Loading vector store data..."
npm install
npm run build
npm run load_data
# Get document count from the index
SEARCH_SERVICE=$(azd env get-values | grep AZURE_AISEARCH_ENDPOINT | cut -d'/' -f3 | cut -d'.' -f1)
DOC_COUNT=$(az search index show --service-name $SEARCH_SERVICE --name northwind --query "documentCount" -o tsv 2>/dev/null || echo "0")
# Mark as loaded
azd env set INDEX_CREATED true
azd env set INDEX_DOCUMENT_COUNT $DOC_COUNT
echo "Data loading complete! Indexed $DOC_COUNT documents."
fi
Verwenden Sie die Stammdatei .env , die von der Azure Developer CLI erstellt wird, können Sie sich bei der Azure KI-Suche-Ressource authentifizieren und den AzureAISearchVectorStore-Client erstellen:
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
export const QUERY_DOC_COUNT = 3;
const MAX_INSERT_RETRIES = 3;
const shared_admin = {
endpoint,
indexName,
};
export const VECTOR_STORE_ADMIN_KEY: AzureAISearchConfig = {
...shared_admin,
key: adminKey,
};
export const VECTOR_STORE_ADMIN_PASSWORDLESS: AzureAISearchConfig = {
...shared_admin,
credentials: CREDENTIAL,
};
export const VECTOR_STORE_ADMIN_CONFIG: AzureAISearchConfig =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_ADMIN_PASSWORDLESS
: VECTOR_STORE_ADMIN_KEY;
const shared_query = {
endpoint,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
// Key-based config
export const VECTOR_STORE_QUERY_KEY: AzureAISearchConfig = {
key: queryKey,
...shared_query,
};
export const VECTOR_STORE_QUERY_PASSWORDLESS: AzureAISearchConfig = {
credentials: CREDENTIAL,
...shared_query,
};
export const VECTOR_STORE_QUERY_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_QUERY_PASSWORDLESS
: VECTOR_STORE_QUERY_KEY;
Wenn Sie abfragen, konvertiert der Vektorspeicher die Abfrage des Benutzers in eine Einbettung, sucht nach Dokumenten mit ähnlichen Vektordarstellungen und gibt die relevantesten Blöcke zurück.
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY_CONFIG);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, QUERY_DOC_COUNT);
return store.similaritySearch(query, QUERY_DOC_COUNT);
}
Da der Vektorspeicher auf LangChain.jsaufbaut, wird die Komplexität der direkten Interaktion mit dem Vektorspeicher abstrahiert. Sobald Sie die LangChain.js Vektorspeicherschnittstelle kennen gelernt haben, können Sie in Zukunft ganz einfach zu anderen Vektorspeicherimplementierungen wechseln.
Azure OpenAI-Integration
Die Anwendung verwendet Azure OpenAI sowohl für Einbettungen als auch für LLM-Funktionen (Large Language Model). Die AzureOpenAIEmbeddings Klasse aus LangChain.js wird verwendet, um Einbettungen für Dokumente und Abfragen zu generieren. Nachdem Sie den Einbettungsclient erstellt haben, verwendet LangChain.js ihn zum Erstellen der Einbettungen.
Azure OpenAI-Integration für Einbettungen
Verwenden Sie die von der Azure Developer CLI erstellte Stammdatei .env , um sich bei der Azure OpenAI-Ressource zu authentifizieren und den AzureOpenAIEmbeddings-Client zu erstellen:
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
dimensions: 1536, // for text-embedding-3-small
batchSize: EMBEDDING_BATCH_SIZE,
maxRetries: 7,
timeout: 60000,
};
export const EMBEDDINGS_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const EMBEDDINGS_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const EMBEDDINGS_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? EMBEDDINGS_CONFIG_PASSWORDLESS
: EMBEDDINGS_KEY_CONFIG;
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG });
}
Azure OpenAI-Integration für LLM
Verwenden Sie die stammdatei .env , die von der Azure Developer CLI erstellt wurde, um sich bei der Azure OpenAI-Ressource zu authentifizieren und den AzureChatOpenAI-Client zu erstellen:
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 1000,
maxRetries: 7,
timeout: 60000,
temperature: 0,
};
export const LLM_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const LLM_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const LLM_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? LLM_CONFIG_PASSWORDLESS
: LLM_KEY_CONFIG;
Die Anwendung verwendet die AzureChatOpenAI Klasse von LangChain.js @langchain/openai für die Interaktion mit Azure OpenAI-Modellen.
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
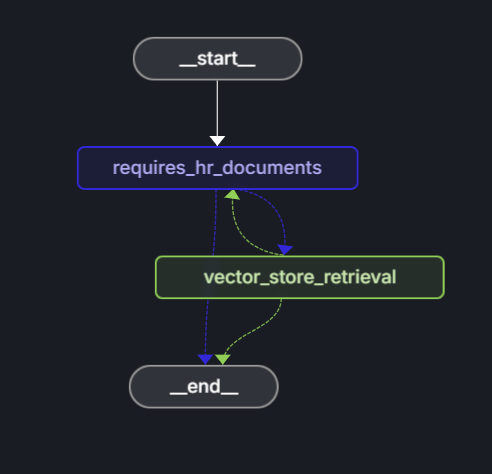
LangGraph-Agent-Workflow
Der Agent verwendet LangGraph, um einen Entscheidungsworkflow zu definieren, der bestimmt, ob eine Frage mithilfe von HR-Dokumenten beantwortet werden kann.
Diagrammstruktur:
import { StateGraph } from "@langchain/langgraph";
import {
START,
ANSWER_NODE,
DECISION_NODE,
route as endRoute,
StateAnnotation,
} from "./langchain/nodes.js";
import { getAnswer } from "./langchain/node_get_answer.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./langchain/node_requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
Dieser Workflow besteht aus den folgenden Schritten:
- Start: Der Benutzer sendet eine Frage.
- requires_hr_documents Knoten: LLM bestimmt, ob die Frage anhand allgemeiner HR-Dokumente beantwortet werden kann.
-
Bedingtes Routing:
- Wenn ja, fahren Sie mit dem Knoten
get_answerfort. - Wenn nein, wird eine Nachricht zurückgegeben, dass für diese Frage persönliche Personaldaten erforderlich sind.
- Wenn ja, fahren Sie mit dem Knoten
- get_answer Knoten: Ruft Dokumente ab und generiert Antwort.
- Ende: Gibt Antwort an den Benutzer zurück.
Diese Relevanzüberprüfung ist wichtig, da nicht alle Hr-Fragen aus allgemeinen Dokumenten beantwortet werden können. Persönliche Fragen wie "Wie viel PTO habe ich?" benötigen Zugriff auf Mitarbeiterdatenbanken, die einzelne Mitarbeiterdaten enthalten. Durch die Überprüfung der Relevanz vermeidet der Agent die Halluzinierung von Antworten auf Fragen, die persönliche Informationen benötigen, auf die er keinen Zugriff hat.
Entscheiden Sie, ob für die Frage die HR-Dokumente erforderlich sind.
Der requires_hr_documents Knoten verwendet eine LLM, um zu ermitteln, ob die Frage des Benutzers mithilfe allgemeiner HR-Dokumente beantwortet werden kann. Es verwendet eine Eingabeaufforderungsvorlage, die das Modell anweist, mit YES oder NO basierend auf der Relevanz der Frage zu antworten. Sie gibt die Antwort in einer strukturierten Nachricht zurück, die entlang des Workflows übergeben werden kann. Der nächste Knoten verwendet diese Antwort, um den Workflow entweder an den END oder den ANSWER_NODE weiterzuleiten.
// @ts-nocheck
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "./nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
Abrufen der erforderlichen HR-Dokumente
Nachdem festgestellt wurde, dass für die Frage HR-Dokumente erforderlich sind, verwendet getAnswer der Workflow zum Abrufen der relevanten Dokumente aus dem Vektorspeicher, fügt sie dem Kontext der Eingabeaufforderung hinzu und übergibt die gesamte Eingabeaufforderung an die LLM.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "./nodes.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "../azure/vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
const llm = getLlmChatClient();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const docs = await vectorStore.similaritySearch(userInput, 3);
if (docs.length === 0) {
const noDocMessage = new AIMessage(
"I'm sorry, I couldn't find any relevant information to answer your question.",
);
return {
messages: [...state.messages, noDocMessage],
};
}
const formattedDocs = docs.map((doc) => doc.pageContent).join("\n\n");
const prompt = ChatPromptTemplate.fromTemplate(`
Use the following context to answer the question:
{context}
Question: {question}
`);
const ragChain = prompt.pipe(llm);
const result = await ragChain.invoke({
context: formattedDocs,
question: userInput,
});
const assistantMessage = new AIMessage(result.text);
return {
messages: [...state.messages, assistantMessage],
};
}
Wenn keine relevanten Dokumente gefunden werden, gibt der Agent eine Meldung zurück, die angibt, dass es keine Antwort in den HR-Dokumenten finden konnte.
Problembehandlung
Erstellen Sie bei Problemen mit der Prozedur ein Problem im Beispielcode-Repository.
Bereinigen von Ressourcen
Sie können die Ressourcengruppe löschen, die die Azure KI-Suche-Ressource und die Azure OpenAI-Ressource enthält, oder die Azure Developer CLI verwenden, um sofort alle von diesem Lernprogramm erstellten Ressourcen zu löschen.
azd down --purge