Verbund: mehrere Standorte und mehrere Regionen
Viele ausgefeilte Lösungen erfordern, dass dieselben Ereignisdatenströme für den Verbrauch an mehreren Standorten zur Verfügung gestellt werden, oder sie erfordern, dass Ereignisdatenströme an mehreren Standorten erfasst und dann an einem bestimmten Standort für die Nutzung konsolidiert werden. Häufig ist es auch erforderlich, Ereignisdatenströme anzureichern oder zu reduzieren oder Ereignisformatkonvertierungen für eine einzelne Region und Lösung durchzuführen.
In der Praxis bedeutet das, dass Ihre Lösung mehrere Event Hubs verwaltet, oft in verschiedenen Regionen und Event Hubs-Namespaces, und dann Ereignisse zwischen ihnen repliziert. Sie können auch Ereignisse mit Quellen und Zielen wie Azure Service Bus, Azure IoT Hub oder Apache Kafka austauschen.
Die Verwaltung mehrerer aktiver Event Hubs in verschiedenen Regionen ermöglicht es Clients auch, zwischen ihnen auszuwählen und zu wechseln, wenn ihre Inhalte zusammengeführt werden, wodurch das Gesamtsystem widerstandsfähiger gegen regionale Verfügbarkeitsprobleme wird.
In diesem Kapitel zum „Verbund“ werden Verbundmuster erläutert und wie diese Muster mithilfe von serverlosem Azure Stream Analytics oder den Azure Functions-Runtimes umgesetzt werden können, wobei die Möglichkeit besteht, eigenen Transformations- oder Anreicherungscode direkt im Ereignis-Datenflusspfad zu verwenden.
Verbundmuster
Es gibt viele mögliche Beweggründe, warum Sie Ereignisse zwischen verschiedenen Event Hubs oder anderen Quellen und Zielen verschieben möchten. Wir beschreiben die wichtigsten Muster in diesem Abschnitt und stellen auch Links zu ausführlicheren Anleitungen für das jeweilige Muster bereit.
- Resilienz bei regionalen Verfügbarkeitsereignissen
- Latenzoptimierung
- Validierung, Reduzierung und Anreicherung
- Integration in Analysedienste
- Konsolidierung und Normalisierung von Ereignisdatenströmen
- Aufteilen und Routing von Ereignisdatenströmen
- Protokollprojektionen
Resilienz bei regionalen Verfügbarkeitsereignissen
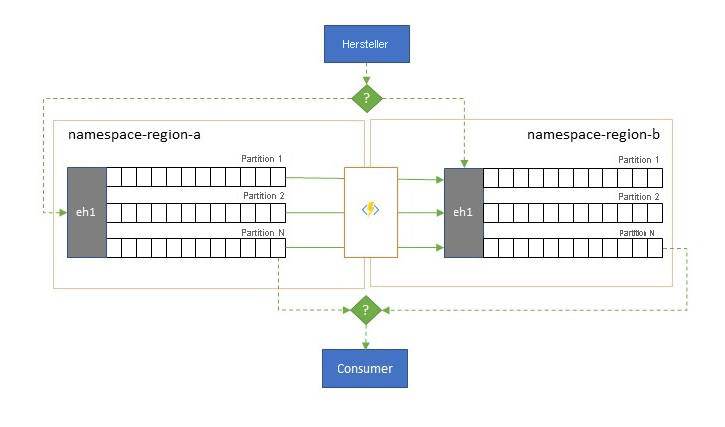
Auch wenn maximale Verfügbarkeit und Zuverlässigkeit die obersten Betriebsprioritäten für Event Hubs sind, gibt es dennoch viele Möglichkeiten, bei denen ein Producer oder Consumer aufgrund von Netzwerk- oder Namensauflösungsproblemen daran gehindert werden könnte, mit dem ihm zugewiesenen „primären“ Event Hub zu kommunizieren, oder bei denen ein Event Hub tatsächlich vorübergehend nicht antwortet oder Fehler zurückgibt.
Solche Bedingungen sind nicht so „katastrophal“, dass Sie die regionale Bereitstellung ganz aufgeben würden, wie es vielleicht in einer Notfallwiederherstellungssituation der Fall wäre, aber das Geschäftsszenario einiger Anwendungen könnte bereits durch Verfügbarkeitsereignisse beeinträchtigt werden, die nicht länger als einige Minuten oder sogar Sekunden dauern.
Es gibt zwei grundlegende Muster für solche Szenarien:
- Beim Replikationsmuster geht es darum, den Inhalt eines primären Event Hubs auf einen sekundären Event Hub zu replizieren, wobei der primäre Event Hub in der Regel von der Anwendung sowohl zum Generieren als auch zum Nutzen von Ereignissen verwendet wird und der sekundäre Event Hub als Rückfalloption dient, falls der primäre Event Hub nicht mehr verfügbar ist. Da die Replikation unidirektional ist und vom primären zum sekundären Event Hub erfolgt, bewirkt eine Umschaltung von Producern und Consumern von einem nicht verfügbaren primären zum sekundären Event Hub, dass er alte primäre Event Hub keine neuen Ereignisse mehr empfängt und daher nicht mehr aktuell ist. Reine Replikation eignet sich daher nur für unidirektionale Failoverszenarien. Nachdem das Failover durchgeführt wurde, wird der alte primäre Event Hub verworfen, und ein neuer sekundärer Event Hub muss in einer anderen Zielregion erstellt werden.
- Das Mergemuster erweitert das Replikationsmuster, indem eine fortlaufende Zusammenführung der Inhalte von mindestens zwei Event Hubs durchgeführt wird. Jedes Ereignis, das ursprünglich in einem der im Schema enthaltenen Event Hubs generiert wurde, wird auf den anderen Event Hub repliziert. Wenn Ereignisse repliziert werden, werden Sie mit einer Anmerkung versehen, damit sie anschließend vom Replikationsprozess des Replikationsziels ignoriert werden. Die Ergebnisse der Verwendung des Mergemusters sind mindestens zwei Event Hubs, die den gleichen Satz von Ereignissen in einer letztlich konsistenten Weise enthalten.
In beiden Fällen ist der Inhalt der Event Hubs nicht identisch. Ereignisse von einem beliebigen Producer, die anhand des gleichen Partitionsschlüssels gruppiert werden, werden in derselben relativen Reihenfolge wie ursprünglich übermittelt angezeigt, die absolute Reihenfolge der Ereignisse kann aber abweichen. Dies gilt insbesondere für Szenarien, in denen die Partitionsanzahl von Quell- und Ziel-Event Hubs abweicht, was für mehrere der hier beschriebenen erweiterten Muster wünschenswert ist. Ein Splitter oder Router kann einen Slice eines viel größeren Event Hubs mit Hunderten von Partitionen abrufen und in einen kleineren Event Hub mit nur wenigen Partitionen einschleusen, was für die Verarbeitung der Teilmenge mit begrenzten Verarbeitungsressourcen geeigneter ist. Im Gegensatz dazu kann eine Konsolidierung Daten aus mehreren kleineren Event Hubs in einem einzigen, größeren Event Hub mit mehr Partitionen übernehmen, um die konsolidierten Durchsatz- und Verarbeitungsanforderungen zu bewältigen.
Das Kriterium für die Konsolidierung von Ereignissen ist der Partitionsschlüssel und nicht die ursprüngliche Partitions-ID. Weitere Überlegungen zur relativen Reihenfolge und zur Durchführung eines Failovers von einem Event Hub zum nächsten Event Hub, ohne dass derselbe Bereich von Datenstromoffsets verwendet wird, finden Sie in der Beschreibung des Replikationsmusters.
Leitfaden:
Latenzoptimierung
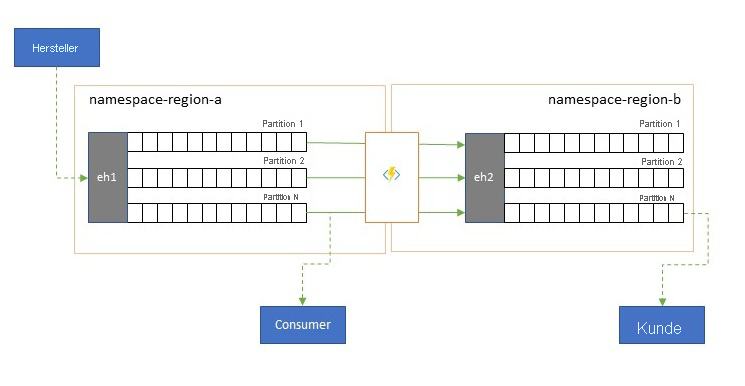
Ereignisdatenströme werden von Producern ein Mal geschrieben, können aber beliebig oft von Ereignisconsumern gelesen werden. In Szenarien, in denen ein Ereignisdatenstrom in einer Region von mehreren Consumern gemeinsam genutzt wird und auf ihn während der Analyseverarbeitung in einer anderen Region oder bei Durchsatzanforderungen, die gleichzeitige Consumer behindern würden, wiederholt zugegriffen werden muss, kann es von Vorteil sein, eine Kopie des Ereignisdatenstroms in der Nähe des Analyseprozessors zu platzieren, um die Roundtriplatenz zu reduzieren.
Gute Beispiele dafür, wann die Replikation der Remotenutzung von Ereignissen aus anderen Regionen vorgezogen werden sollte, sind vor allem solche, bei denen die Regionen extrem weit voneinander entfernt sind, z. B. Europa und Australien, die geografisch gesehen fast Antipoden sind und bei denen die Netzwerklatenzen bei jedem Roundtrip leicht 250 ms überschreiten können. Sie können die Geschwindigkeit des Lichts nicht beschleunigen, aber Sie können die Anzahl der Roundtrips mit hoher Latenz verringern, um mit Daten zu interagieren.
Leitfaden:
Validierung, Reduzierung und Anreicherung
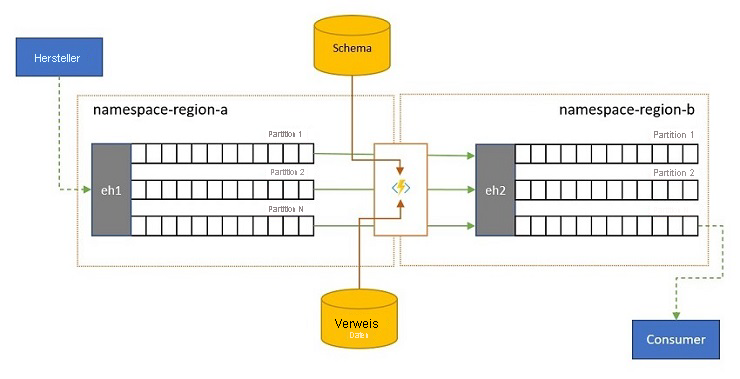
Ereignisdatenströme können von Clients außerhalb Ihrer eigenen Lösung an einen Event Hub übermittelt werden. Solche Ereignisdatenströme können erfordern, dass extern übermittelte Ereignisse auf Konformität mit einem bestimmten Schema geprüft werden und nicht konforme Ereignisse verworfen werden.
In Szenarien, in denen Clients extrem bandbreitenbeschränkt sind, wie es in vielen „Internet der Dinge“-Szenarien mit gemessener Bandbreite der Fall ist, oder in denen Ereignisse ursprünglich über Nicht-IP-Netzwerke mit eingeschränkten Paketgrößen gesendet werden, müssen die Ereignisse möglicherweise mit Verweisdaten angereichert werden, um weiteren Kontext hinzuzufügen, damit sie von Downstreamereignisprozessoren verwendet werden können.
In anderen Fällen, insbesondere wenn Datenströme konsolidiert werden, muss die Komplexität oder die reine Größe von Ereignisdaten möglicherweise reduziert werden, indem einige Details ausgelassen werden.
Jeder dieser Vorgänge kann im Rahmen der Replikations-, Konsolidierungs- oder Mergedatenflüsse auftreten.
Leitfaden:
Integration in Analysedienste
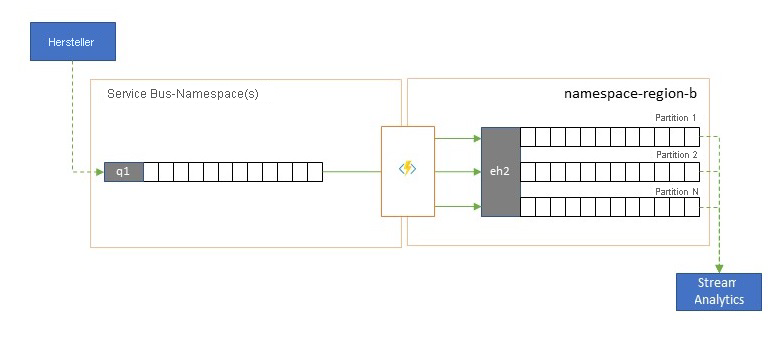
Einige der cloudnativen Analysedienste von Azure (z. B. Azure Stream Analytics oder Azure Synapse) funktionieren am besten mit gestreamten oder vorab in Batches zusammengefassten Daten, die von Azure Event Hubs bereitgestellt werden, und Azure Event Hubs ermöglicht außerdem die Integration in mehrere Open-Source-Analysepakete wie Apache Samza, Apache Flink, Apache Spark und Apache Storm.
Wenn Ihre Lösung hauptsächlich Service Bus oder Event Grid verwendet, können Sie diese Ereignisse leicht für solche Analysesysteme und auch für die Archivierung mit Event Hubs Capture zugänglich machen, wenn Sie sie in Event Hub integrieren. Event Grid kann dies nativ mit der Event Hub-Integration durchführen, für Service Bus befolgen Sie die Anweisungen im Service Bus-Replikationsleitfaden.
Azure Stream Analytics ist direkt in Event Hubs integriert.
Leitfaden:
Konsolidierung und Normalisierung von Ereignisdatenströmen
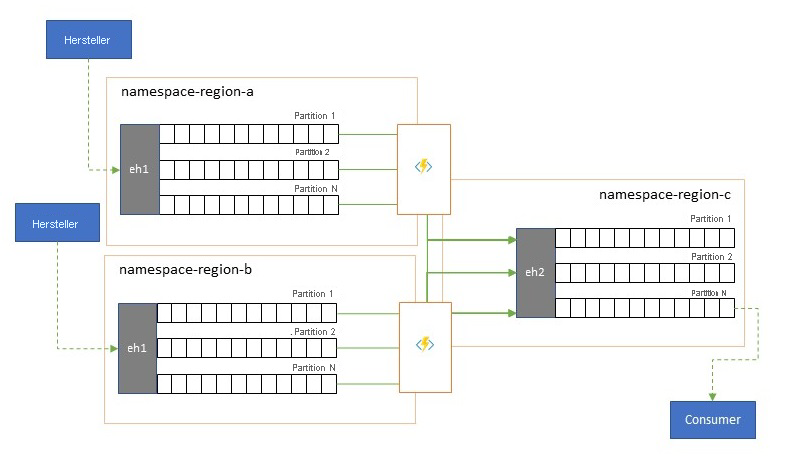
Globale Lösungen setzen sich oft aus regionalen Ressourcen zusammen, die weitgehend unabhängig sind und auch über eigene Analysemöglichkeiten verfügen. Überregionale und globale Analyseperspektiven erfordern jedoch eine integrierte Perspektive. Dies ist der Grund dafür, dass eine zentrale Zusammenführung der gleichen Ereignisdatenströme erfolgt, die in den jeweiligen regionalen Ressourcen für die lokale Perspektive ausgewertet werden.
Normalisierung ist eine Variante des Konsolidierungsszenarios, bei der mindestens zwei eingehende Ereignisdatenströme die gleiche Art von Ereignissen tragen, aber mit unterschiedlichen Strukturen oder unterschiedlichen Codierungen, und die Ereignisse müssen transcodiert oder transformiert werden, bevor sie genutzt werden können.
Normalisierung kann auch kryptografische Aufgaben beinhalten, etwa das Entschlüsseln von End-to-End-verschlüsselten Nutzlasten und das erneute Verschlüsseln mit anderen Schlüsseln und Algorithmen für die Downstreamzielgruppe der Consumer.
Leitfaden:
Aufteilen und Routing von Ereignisdatenströmen
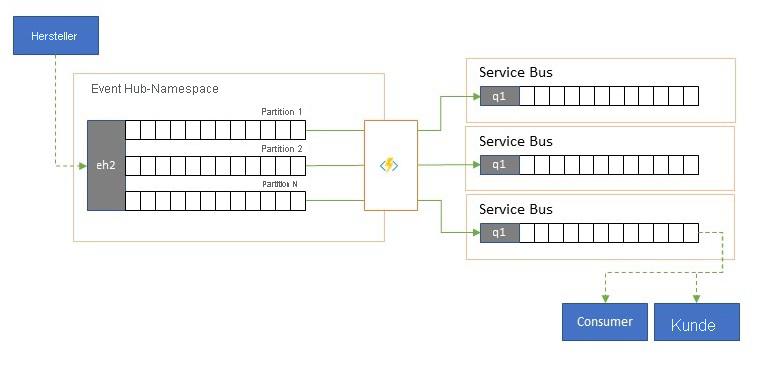
Azure Event Hubs wird gelegentlich in Szenarien im „Veröffentlichen-Abonnieren“-Stil verwendet, in denen eine eingehende Flut von erfassten Ereignissen die Kapazität von Azure Service Bus oder Azure Event Grid bei weitem übersteigt, die beide über native Veröffentlichen-Abonnieren-Filter- und Verteilungsfunktionen verfügen und für dieses Muster bevorzugt werden.
Während eine echte „Veröffentlichen-Abonnieren“-Funktion es den Abonnenten ermöglicht, die gewünschten Ereignisse auszuwählen, muss der Producer beim Aufteilungsmuster Ereignisse durch ein vordefiniertes Verteilungsmodell Partitionen zuordnen, und bestimmte Consumer pullen diese Ereignisse dann exklusiv von „ihrer“ Partition. Da der Event Hub den gesamten Datenverkehr puffert, kann der Inhalt einer bestimmten Partition, der einen Bruchteil des ursprünglichen Durchsatzvolumens darstellt, dann für die zuverlässige, transaktionale, konkurrierende Consumernutzung in eine Warteschlange repliziert werden.
In vielen Szenarien, in denen Event Hubs in erster Linie zum Verschieben von Ereignissen innerhalb einer Anwendung in einer Region eingesetzt wird, gibt es Fälle, in denen ausgewählte Ereignisse, vielleicht nur aus einer einzelnen Partition, auch an anderer Stelle zur Verfügung gestellt werden müssen. Dieses Szenario ähnelt dem Aufteilungsszenario, kann aber einen skalierbaren Router verwenden, der alle in einem Event Hub eingehenden Nachrichten berücksichtigt, nur einige wenige per Cherrypicking für das Weiterleiten auswählt und Routingziele nach Ereignismetadaten oder Inhalten unterscheiden kann.
Leitfaden:
Protokollprojektionen
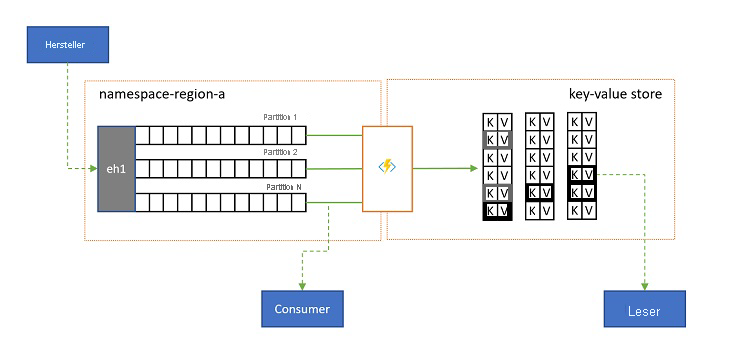
In einigen Szenarien möchten Sie Zugriff auf den letzten gesendeten Wert für einen beliebigen Teildatenstrom eines Ereignisses besitzen, der üblicherweise durch den Partitionsschlüssel unterschieden wird. In Apache Kafka wird dies häufig durch Aktivieren von „Protokollkomprimierung“ in einem Thema erzielt, die alle Ereignisse mit Ausnahme des letzten Ereignisses verwirft, das mit einem eindeutigen Schlüssel gekennzeichnet ist. Der Protokollkomprimierungsansatz hat drei entscheidende Nachteile:
- Die Komprimierung erfordert eine fortlaufende Neuorganisation des Protokolls. Dies ist ein übermäßig kostspieliger Vorgang für einen Broker, der nur für Anfügevorgänge optimiert ist.
- Komprimierung ist destruktiv und ermöglicht keine komprimierte und nicht komprimierte Darstellung desselben Datenstroms.
- Ein komprimierter Datenstrom besitzt immer noch ein sequenzielles Zugriffsmodell, was bedeutet, dass das Auffinden des gewünschten Werts im Protokoll im schlimmsten Fall das Lesen des gesamten Protokolls erfordert, was typischerweise zu Optimierungen führt, die genau das hier vorgestellte Muster implementieren: das Projizieren der Protokollinhalte in eine Datenbank oder einen Cache.
Letztendlich handelt es sich bei einem komprimierte Protokoll um einen Schlüssel-Wert-Speicher, also um die schlechtestmögliche Implementierungsoption für einen solchen Speicher. Es ist weitaus effizienter für Suchvorgänge und für Abfragen, eine permanente Projektion des Protokolls in einem richtigen Schlüssel-Wert-Speicher oder in einer anderen Datenbank zu erstellen und zu verwenden.
Da Ereignisse unveränderlich sind und die Reihenfolge in einem Protokoll immer beibehalten wird, wird jede Projektion eines Protokolls in einen Schlüssel-Wert-Speicher für denselben Bereich von Ereignissen immer identisch sein, was bedeutet, dass eine Projektion, die Sie auf dem neuesten Stand halten, immer eine maßgebliche Ansicht bietet und es nie einen guten Grund gibt, sie aus den einmal erstellten Protokollinhalten neu zu erstellen.
Leitfaden:
Replikationsanwendungstechnologien
Die Implementierung der oben genannten Muster erfordert eine skalierbare und zuverlässige Ausführungsumgebung für die Replikationstasks, die Sie konfigurieren und ausführen möchten. In Azure sind die Laufzeitumgebungen, die sich am besten für solche Aufgaben eignen, Azure Stream Analytics für zustandsbehaftete Datenstrom-Replikationstasks und Azure Functions für zustandslose Replikationstasks.
Zustandsahaftete Replikations Anwendungen in Azure Stream Analytics
Für zustandsbehaftete Replikationsanwendungen, die Beziehungen zwischen Ereignissen berücksichtigen, zusammengesetzte Ereignisse erstellen, Ereignisse anreichern oder reduzieren, Datenaggregationen erstellen und Ereignisnutzlasten transformieren müssen, ist Azure Stream Analytics die beste Implementierungsoption.
In Azure Stream Analytics erstellen Sie Aufträge, die Eingaben und Ausgaben integrieren und die Daten aus den Eingaben über Abfragen integrieren, die ein Ergebnis liefern, das dann für die Ausgaben zur Verfügung gestellt wird.
Abfrage basieren auf der SQL-Abfragesprache und können zum einfachen Filtern,Sortieren,Aggregieren und Verknüpfen von Streamingdaten über einen bestimmten Zeitraum verwendet werden. Sie können diese SQL-Sprache auch mit JavaScript und benutzerdefinierten C#-Funktionen (UDFs) erweitern. Sie können die Optionen für die Ereignisreihenfolge und die Dauer der Zeitfenster bei der Durchführung von Aggregationsvorgängen mithilfe einfacher Sprachkonstrukte und/oder Konfigurationen einfach anpassen.
Zu jedem Auftrag gehören eine oder mehrere Ausgaben für die transformierten Daten. Sie können die Reaktion auf die analysierten Informationen steuern. Beispielsweise können Sie folgende Aktionen ausführen:
- Senden von Daten an Dienste wie Azure Functions, Service Bus Topics oder Queues, um Kommunikation oder benutzerdefinierte Workflows nachgelagert auszulösen.
- Senden von Daten an ein Power BI-Dashboard für die Echtzeitvisualisierung
- Speichern von Daten in anderen Azure-Speicherdiensten (z. B. Azure Data Lake, Azure Synapse Analytics usw.), um Batchanalysen durchzuführen oder Modelle für Machine Learning zu trainieren, die auf sehr großen, indizierten Pools historischer Daten basieren.
- Speichern von Projektionen (auch als „materialisierte Sichten“ bezeichnet) in Datenbanken (SQL-Datenbank, Azure Cosmos DB).
Zustandslose Replikationsanwendungen in Azure Functions
Für zustandslose Replikationstasks, bei denen Sie Ereignisse weiterleiten möchten, ohne deren Nutzlast zu berücksichtigen, oder sie einzeln verarbeiten möchten, ohne die Beziehungen der Ereignisse (außer ihrer relativen Reihenfolge) berücksichtigen zu müssen, können Sie die enorme Flexibilität von Azure Functions verwenden.
Azure Functions bietet vordefinierte, skalierbare Trigger und Ausgabebindungen für Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid und Azure Queue Storage sowie benutzerdefinierte Erweiterungen für RabbitMQ und Apache Kafka. Die meisten Trigger werden dynamisch an die Durchsatzanforderungen angepasst, indem die Anzahl der gleichzeitig ausgeführten Instanzen basierend auf dokumentierten Metriken zentral hoch- oder herunterskaliert wird.
Zum Erstellen von Protokollprojektionen unterstützt Azure Functions Ausgabebindungen für Azure Cosmos DB und Azure Table Storage.
Azure Functions kann unter einer verwalteten Azure-Identität ausgeführt werden und daher die Konfigurationswerte für Anmeldeinformationen in einem Speicher innerhalb von Azure Key Vault enthalten, auf den der Zugriff streng reglementiert wird.
Azure Functions ermöglicht den Replikationstasks außerdem die direkte Integration in virtuelle Azure-Netzwerke und Dienstendpunkte für alle Azure-Messagingdienste und ist bereits in Azure Monitor integriert.
Mit dem Azure Functions-Verbrauchsplan können die vordefinierten Trigger sogar auf null skaliert werden, wenn keine Nachrichten für die Replikation verfügbar sind. Dies bedeutet, dass keine Kosten verursacht werden, obwohl die Konfiguration für die erneute Hochskalierung bereit ist. Der wichtigste Nachteil bei Verwendung des Verbrauchsplans besteht darin, dass die Latenzzeit für Replikationstasks, die sich aus diesem Zustand „reaktivieren“, deutlich höher ist als bei den Hostingplänen, in denen die Infrastruktur weiterhin ausgeführt wird.
Im Gegensatz dazu müssen Sie bei den meisten gängigen Replikations-Engines für Messaging und Ereignisse (z. B. MirrorMaker von Apache Kafka) selbst eine Hostingumgebung bereitstellen und die Replikations-Engine skalieren. Das beinhaltet die Konfiguration und Integration der Sicherheits- und Netzwerkfunktionen und das Ermöglichen des Datenflusses von Überwachungsdaten. Selbst dann haben Sie immer noch keine Möglichkeit, benutzerdefinierte Replikations-Tasks in den Datenfluss zu injizieren.
Wählen zwischen Azure Functions und Azure Stream Analytics
Azure Stream Analytics (ASA) ist die beste Option, wenn Sie die Nutzlast Ihrer Ereignisse beim Replizieren verarbeiten müssen. ASA kann Ereignisse nacheinander kopieren oder Aggregate erstellen, mit denen die Informationen von Ereignisdatenströmen vor der Weiterleitung kondensiert werden. ASA kann sich problemlos auf ergänzende Verweisdaten stützen, die in Azure Blob Storage oder Azure SQL Database gespeichert werden, ohne dass solche Daten in einen Datenstrom importiert werden müssen.
Mit ASA können Sie auf einfache Weise persistente, materialisierte Sichten von Datenströmen in Datenbanken mit Hyperskalierung erstellen. Dies ist ein weitaus besserer Ansatz als das klobige „Protokollkomprimierungsmodell“ von Apache Kafka und die flüchtigen, clientseitigen Tabellenprojektionen von Kafka Streams.
ASA kann problemlos Ereignisse verarbeiten, deren Nutzlast in den Formaten CSV, JSON und Apache Avro codiert ist, und Sie können eigene Deserialisierer für jedes andere Format einbinden.
Für alle Replikationstasks, bei denen Sie Ereignisdatenströme „im Ist-Zustand“ und ohne Berührung der Nutzlasten kopieren möchten, oder wenn Sie einen Router implementieren, kryptografische Arbeiten durchführen, die Codierung der Nutzlasten ändern oder anderweitig vollständige Kontrolle über die Datenstrominhalte benötigen, ist Azure Functions die beste Option.
Nächste Schritte
In diesem Artikel haben wir eine Reihe von Verbundmustern untersucht und die Rolle von Azure Functions als Ereignis- und Messaging-Replikationslaufzeit in Azure erläutert.
Als nächstes sollten Sie sich darüber informieren, wie Sie eine Replikatoranwendung mit Azure Stream Analytics und Azure Functions einrichten und dann die Ereignisdatenflüsse zwischen Event Hubs und verschiedenen anderen Ereignis- und Messagingsystemen replizieren: