Abfragen von Apache Hive über den JDBC-Treiber in HDInsight
Erfahren Sie, wie Sie den JDBC-Treiber aus einer Java-Anwendung heraus verwenden, um Apache Hive-Abfragen an Apache Hadoop in Azure HDInsight zu übermitteln. Die Informationen in diesem Dokument veranschaulichen, wie eine Verbindung programmgesteuert und mithilfe des SQuirreL SQL-Clients hergestellt wird.
Weitere Informationen zur Hive-JDBC-Schnittstelle finden Sie unter HiveJDBCInterface.
Voraussetzungen
- einen HDInsight Hadoop-Cluster. Hinweise zum Erstellen finden Sie unter Erste Schritte mit Azure HDInsight. Stellen Sie sicher, dass der Dienst HiveServer2 ausgeführt wird.
- Java Developer Kit (JDK) Version 11 oder höher.
- SQuirreL SQL. SQuirreL ist eine JDBC-Clientanwendung.
Verbindungszeichenfolge für JDBC
JDBC-Verbindungen mit einem HDInsight-Cluster unter Azure werden über Port 443 hergestellt, und der Datenverkehr wird per TLS/SSL geschützt. Das öffentliche Gateway, hinter dem sich die Cluster befinden, leitet den Datenverkehr an den Port um, auf dem von HiveServer2 gelauscht wird. Die folgende Verbindungszeichenfolge zeigt das für HDInsight zu verwendende Format:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Ersetzen Sie CLUSTERNAME durch den Namen Ihres HDInsight-Clusters.
Hostname in der Verbindungszeichenfolge
Der Hostname „CLUSTERNAME.azurehdinsight.net“ in der Verbindungszeichenfolge ist mit der Cluster-URL identisch. Sie können sie über das Azure-Portal abrufen.
Port in der Verbindungszeichenfolge
Sie können nur über Port 443 eine Verbindung mit dem Cluster von Orten außerhalb des virtuellen Azure-Netzwerks herstellen. HDInsight ist ein verwalteter Dienst. Das bedeutet, dass alle Verbindungen mit dem Cluster über ein sicheres Gateway verwaltet werden. Es ist nicht möglich, direkt über die Ports 10001 oder 10000 eine Verbindung mit HiveServer 2 herzustellen. Diese Ports werden nicht nach außen verfügbar gemacht.
Authentifizierung
Verwenden Sie beim Herstellen der Verbindung den Administratornamen und das Kennwort für den HDInsight-Cluster, um sich zu authentifizieren. Geben Sie in JDBC-Clients, z. B. SQuirreL SQL, den Administratornamen und das Kennwort in den Clienteinstellungen ein.
In einer Java-Anwendung müssen Sie den Namen und das Kennwort beim Herstellen einer Verbindung eingeben. Der folgende Java-Code öffnet z. B. eine neue Verbindung:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Herstellen einer Verbindung mit dem SQuirreL SQL-Client
SQuirreL SQL ist ein JDBC-Client, der für die Remoteausführung von Hive-Abfragen mit Ihrem HDInsight-Cluster verwendet werden kann. Bei den folgenden Schritten wird davon ausgegangen, dass Sie SQuirreL SQL bereits installiert haben.
Erstellen Sie ein Verzeichnis zur Aufnahme bestimmter Dateien, die aus Ihrem Cluster kopiert werden müssen.
Ersetzen Sie im folgenden Skript
sshuserdurch den Namen des SSH-Benutzerkontonamens für den Cluster. Ersetzen SieCLUSTERNAMEdurch den Namen des HDInsight-Clusters. Ändern Sie an einer Befehlszeile Ihre Arbeitsverzeichnis in das, das Sie im vorherigen Schritt erstellt haben, und geben Sie dann den folgenden Befehl ein, um Dateien aus einem HDInsight-Cluster zu kopieren:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Starten Sie die SQuirreL SQL-Anwendung. Wählen Sie auf der linken Seite des Fensters Drivers aus.

Wählen Sie unter den Symbolen oben im Dialogfeld Treiber das Symbol +, um einen Treiber zu erstellen.
Fügen Sie im Dialogfeld „Treiber hinzufügen“ die folgenden Informationen ein:
Eigenschaft Wert Name Hive Beispiel-URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Zusätzlicher Klassenpfad Fügen Sie mit der Schaltfläche Add alle JAR-Dateien hinzu, die Sie zuvor heruntergeladen haben. Klassenname org.apache.hive.jdbc.HiveDriver 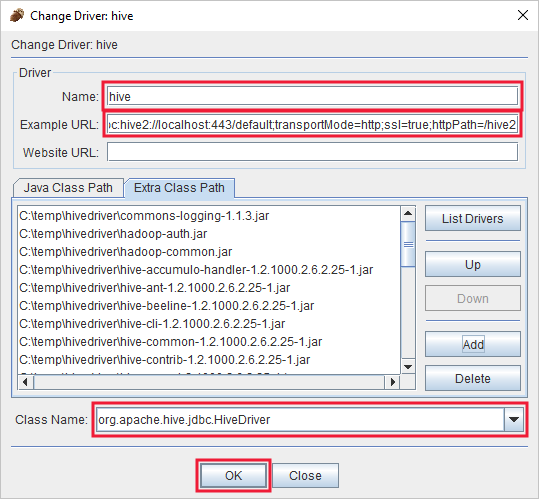
Wählen Sie auf OK aus, um die Einstellungen zu speichern.
Wählen Sie auf der linken Seite des Fensters „SQuirreL SQL“ die Option Aliases aus. Wählen Sie dann das Symbol + aus, um einen Verbindungsalias zu erstellen.
Verwenden Sie für das Dialogfeld Add Alias die folgenden Werte:
Eigenschaft Wert Name Hive in HDInsight Treiber Wählen Sie in der Dropdownliste den Hive-Treiber aus. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Ersetzen Sie CLUSTERNAME durch den Namen Ihres HDInsight-Clusters.Benutzername Der Name des Clusteranmeldekontos für den HDInsight-Cluster. Der Standardname lautet admin. Kennwort Das Kennwort für das Clusteranmeldekonto. 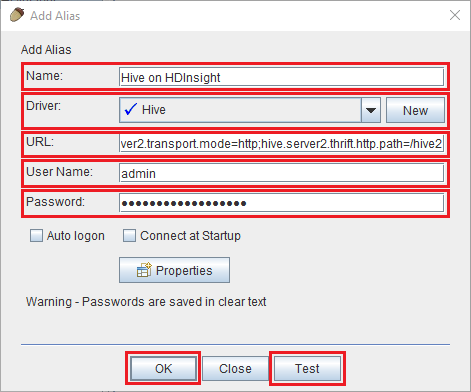
Wichtig
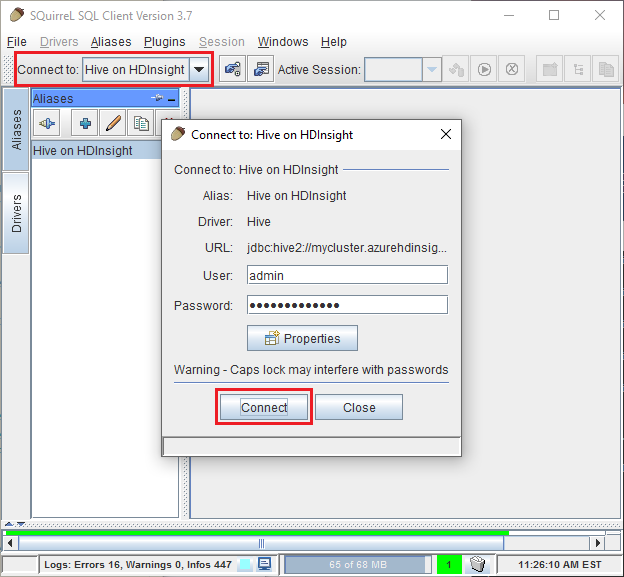
Überprüfen Sie mithilfe der Schaltfläche Test, ob die Verbindung funktioniert. Wenn das Dialogfeld Connect to: Hive on HDInsight angezeigt wird, wählen Sie Connect aus, um den Test durchzuführen. Wenn der Test erfolgreich ist, wird das Dialogfeld Connection successful (Verbindung erfolgreich) angezeigt. Wenn ein Fehler auftritt, finden Sie Informationen unter Problembehandlung.
Verwenden Sie die Schaltfläche OK unten im Dialogfeld Add Alias (Alias hinzufügen), um den Verbindungsalias zu speichern.
Wählen Sie oben in SQuirreL SQL in der Dropdownliste Connect to die Option Hive on HDInsight aus. Wenn Sie dazu aufgefordert werden, wählen Sie Connect aus.
Nachdem die Verbindung hergestellt wurde, geben Sie im Dialogfeld für die SQL-Abfrage die folgende Abfrage ein, und wählen Sie das Symbol Run (ein laufender Mensch) aus. Die Ergebnisse der Abfrage sollten im Ergebnisbereich angezeigt werden.
select * from hivesampletable limit 10;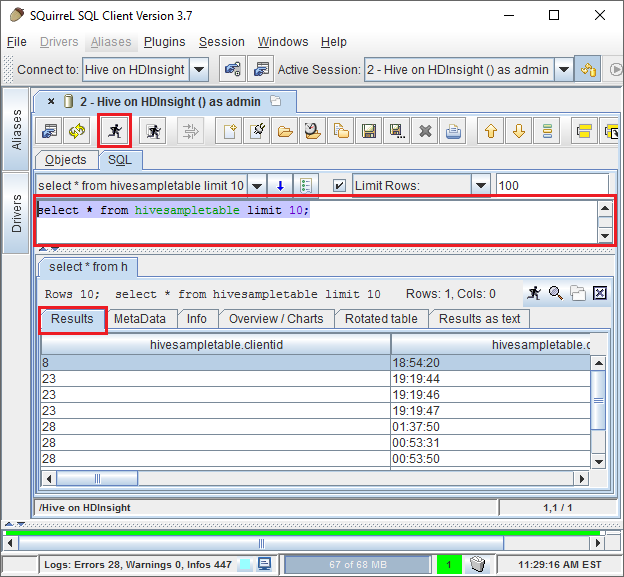
Herstellen einer Verbindung von einer Beispiel-Java-Anwendung aus
Ein Beispiel der Verwendung eines Java-Clients zur Hive-Abfrage in HDInsight finden Sie unter https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Befolgen Sie die Anleitung im Repository, um das Beispiel zu erstellen und auszuführen.
Problembehandlung
Unerwarteter Fehler beim Versuch, eine SQL-Verbindung zu öffnen
Symptome: Beim Herstellen einer Verbindung mit einem HDInsight-Cluster der Version 3.3 oder höher erhalten Sie möglicherweise die Meldung, dass ein unerwarteter Fehler aufgetreten ist. Die Stapelüberwachung für diesen Fehler beginnt mit folgenden Zeilen:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Ursache: Dieser Fehler wird durch eine ältere Version der in SQuirreL enthaltenen commons-codec.jar-Datei verursacht.
Lösung: Führen Sie zum Beheben dieses Fehlers die folgenden Schritte aus:
Beenden Sie SQuirreL, und wechseln Sie zu dem Verzeichnis, in dem SQuirreL in Ihrem System installiert ist, beispielsweise
C:\Program Files\squirrel-sql-4.0.0\lib. Ersetzen Sie im SquirreL-Verzeichnis, unterhalb deslib-Verzeichnisses, die vorhandene commons-codec.jar-Datei durch die Datei, die Sie aus dem HDInsight-Cluster heruntergeladen haben.Starten Sie SQuirreL neu. Dieser Fehler sollte jetzt nicht mehr auftreten, wenn Sie eine Verbindung mit Hive in HDInsight herstellen.
Verbindung von HDInsight getrennt
Symptome: HDInsight trennt die Verbindung unerwartet, wenn versucht wird, eine große Menge an Daten (z. B. mehrere GB) über JDBC/ODBC herunterzuladen.
Ursache: Dieser Fehler wird durch die Einschränkung für Gatewayknoten verursacht. Beim Abrufen von Daten über JDBC/ODBC müssen alle Daten über den Gatewayknoten übergeben werden. Ein Gateway ist jedoch nicht für das Herunterladen einer großen Datenmenge konzipiert, sodass die Verbindung möglicherweise vom Gateway geschlossen wird, wenn es den Datenverkehr nicht verarbeiten kann.
Lösung: Vermeiden Sie die Verwendung des JDBC-/ODBC-Treibers zum Herunterladen großer Datenmengen. Kopieren Sie Daten stattdessen direkt aus dem Blobspeicher.
Nächste Schritte
Nachdem Sie erfahren haben, wie Sie JDBC mit Hive verwenden, können Sie mithilfe der nachfolgenden Links andere Möglichkeiten für die Arbeit mit Azure HDInsight untersuchen.
- Visualisieren von Apache Hive-Daten mit Microsoft Power BI in Azure HDInsight
- Visualisieren von Interactive Query-Hive-Daten mit Power BI in Azure HDInsight
- Verbinden von Excel mit Hadoop in Azure HDInsight mithilfe des Microsoft Hive ODBC-Treibers.
- Verbinden von Excel mit Apache Hadoop mithilfe von Power Query
- Verwenden von Apache Hive mit HDInsight
- Verwenden von Apache Pig mit HDInsight
- Verwenden von MapReduce-Aufträgen mit HDInsight