Dieser Artikel bietet Antworten auf einige der häufigsten Fragen zur Ausführung von Azure HDInsight.
Erstellen oder Löschen von HDInsight-Clustern
Wie stelle ich einen HDInsight-Cluster bereit?
Die verfügbaren HDInsight-Clustertypen und die Bereitstellungsmethoden finden Sie unter Einrichten von Clustern in HDInsight mit Apache Hadoop, Apache Spark, Apache Kafka usw.
Wie lösche ich einen vorhandenen HDInsight-Cluster?
Weitere Informationen zum Löschen eines Clusters, der nicht mehr verwendet wird, finden Sie unter Löschen eines HDInsight-Clusters.
Versuchen Sie, zwischen Erstell- und Löschvorgängen mindestens 30 bis 60 Minuten zu warten. Andernfalls tritt bei dem Vorgang unter Umständen ein Fehler mit der folgenden Fehlermeldung auf:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
Wie wähle ich die richtige Anzahl von Kernen oder Knoten für meine Workload aus?
Die geeignete Anzahl von Kernen und weitere Konfigurationsoptionen hängen von verschiedenen Faktoren ab.
Weitere Informationen finden Sie unter Kapazitätsplanung für HDInsight-Cluster.
Welche unterschiedlichen Knotentypen gibt es in einem HDInsight-Cluster?
Lesen Sie dazu Ressourcentypen in Azure HDInsight-Clustern.
Wie lauten die bewährten Methoden zur Erstellung von großen HDInsight-Clustern?
- Wir empfehlen Ihnen, HDInsight-Cluster mit einer benutzerdefinierten Ambari-Datenbank einzurichten, um die Clusterskalierbarkeit zu verbessern.
- Verwenden Sie Azure Data Lake Storage Gen2 für die Erstellung von HDInsight-Clustern, um die höhere Bandbreite und weitere Leistungsmerkmale von Azure Data Lake Storage Gen2 zu nutzen.
- Hauptknoten sollten eine ausreichende Größe haben, um mehrere Masterdienste abdecken zu können, die auf diesen Knoten ausgeführt werden.
- Für einige spezifische Workloads, z. B. Interactive Query, werden ebenfalls größere Zookeeper-Knoten benötigt. Beachten Sie die Mindestanzahl von acht Kern-VMs.
- Verwenden Sie bei Hive und Spark den externen Hive-Metastore.
Einzelne Komponenten
Kann ich weitere Komponenten in meinem Cluster installieren?
Ja. Zum Installieren zusätzlicher Komponenten oder zum Anpassen der Clusterkonfiguration können Sie Folgendes verwenden:
Skripts während oder nach der Erstellung. Skripts werden über Skriptaktion aufgerufen. „Skriptaktion“ ist eine Konfigurationsoption, die im Azure-Portal, in HDInsight Windows PowerShell-Cmdlets oder beim HDInsight .NET SDK verwendet werden kann. Diese Konfigurationsoption kann im Azure-Portal, in HDInsight Windows PowerShell-Cmdlets oder mit dem HDInsight .NET SDK verwendet werden.
HDInsight-Anwendungsplattform zur Installation von Anwendungen.
Eine Liste mit den unterstützten Komponenten finden Sie unter Verfügbare Apache Hadoop-Komponenten in verschiedenen Versionen von HDInsight.
Kann ich die einzelnen Komponenten aktualisieren, die im Cluster vorinstalliert sind?
Wenn Sie integrierte Komponenten oder Anwendungen aktualisieren, die in Ihrem Cluster vorinstalliert sind, wird die resultierende Konfiguration von Microsoft nicht unterstützt. Diese Systemkonfigurationen wurden nicht von Microsoft getestet. Versuchen Sie, eine andere Version des HDInsight-Clusters zu verwenden, in der die aktualisierte Version der Komponente möglicherweise bereits vorinstalliert ist.
Beispielsweise wird das Aktualisieren von Hive als einzelne Komponente nicht unterstützt. HDInsight ist ein verwalteter Dienst, und viele Dienste sind in den Ambari-Server integriert und wurden getestet. Wenn Hive eigenständig aktualisiert wird, werden die indizierten Binärdateien anderer Komponenten geändert. Das führt zu Integrationsproblemen mit Komponenten in Ihrem Cluster.
Können Spark und Kafka im selben HDInsight-Cluster ausgeführt werden?
Nein, Apache Kafka und Apache Spark können nicht im selben HDInsight-Cluster ausgeführt werden. Erstellen Sie separate Cluster für Kafka und Spark, um Probleme aufgrund von Ressourcenkonflikten zu vermeiden.
Wie ändere ich die Zeitzone in Ambari?
Öffnen Sie die Ambari-Webbenutzeroberfläche unter
https://CLUSTERNAME.azurehdinsight.net. Dabei entspricht CLUSTERNAME dem Namen Ihres Clusters.Wählen Sie oben rechts „Admin (Administrator) | Settings (Einstellungen)“ aus.
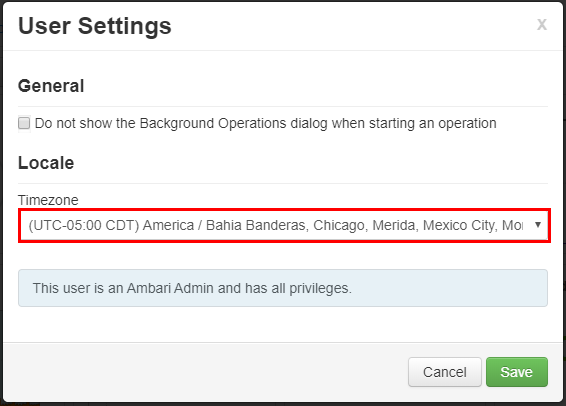
Wählen Sie im Fenster „User Settings“ (Benutzereinstellungen) die neue Zeitzone aus der Dropdownliste „Timezone“ (Zeitzone) aus, und wählen Sie „Save“ (Speichern) aus.
Metastore
Wie kann ich vom vorhandenen Metastore zu Azure SQL-Datenbank migrieren?
Informationen zum Migrieren von SQL Server zu Azure SQL-Datenbank finden Sie unter Tutorial: Offlinemigration von SQL Server zu einer Einzel- oder Pooldatenbank in Azure SQL-Datenbank mit DMS.
Wird der Hive-Metastore zusammen mit dem Cluster gelöscht?
Dies hängt vom Typ des Metastores ab, der für den Cluster konfiguriert ist.
Standardmetastore: Der Standardmetastore ist Teil des Clusterlebenszyklus. Wenn Sie einen Cluster löschen, werden der entsprechende Metastore und die jeweiligen Metadaten ebenfalls gelöscht.
Benutzerdefinierter Metastore: Der Lebenszyklus des Metastores ist nicht an den Lebenszyklus eines Clusters gebunden. Deshalb können Sie Cluster erstellen und löschen, ohne Metadaten zu verlieren. Metadaten, wie z. B. Ihre Hive-Schemas, bleiben auch erhalten, nachdem der HDInsight-Cluster gelöscht und neu erstellt wurde.
Weitere Informationen finden Sie unter Verwenden von externen Metadatenspeichern in Azure HDInsight.
Werden bei der Migration eines Hive-Metastores auch die Standardrichtlinien der Ranger-Datenbank migriert?
Nein, die Richtliniendefinition ist in der Ranger-Datenbank enthalten. Daher wird die Richtlinie bei der Migration der Ranger-Datenbank migriert.
Kann ich einen Hive-Metastore von einem Cluster mit Enterprise-Sicherheitspaket (ESP) zu einem Cluster ohne ESP migrieren und umgekehrt?
Ja, Sie können eine Hive-Metastore von einem Cluster mit Enterprise-Sicherheitspaket zu einem Cluster ohne ESP migrieren.
Wie kann ich die Größe einer Hive-Metastore-Datenbank schätzen?
In einem Hive-Metastore werden die Metadaten für Datenquellen gespeichert, die vom Hive-Server verwendet werden. Die Größenanforderungen sind teilweise abhängig von der Anzahl und Komplexität Ihrer Hive-Datenquellen. Diese Elemente können nicht vorab geschätzt werden. Wie in den Richtlinien für Hive-Metastore beschrieben, können Sie mit einem S2-Tarif beginnen. Dieser Tarif bietet 50 DTU und 250 GB Speicher, und wenn ein Engpass angezeigt wird, skalieren Sie die Datenbank hoch.
Werden andere Datenbanken als Azure SQL-Datenbank als externer Metastore unterstützt?
Nein, Microsoft unterstützt nur Azure SQL-Datenbank als externen benutzerdefinierten Metastore.
Kann ich einen Metastore für mehrere Cluster verwenden?
Ja, Sie können einen benutzerdefinierten Metastore für mehrere Cluster verwenden, sofern sie dieselbe HDInsight-Version verwenden.
Konnektivität und virtuelle Netzwerke
Was geschieht, wenn ich die Ports 22 und 23 in meinem Netzwerk blockiere?
Wenn Sie die Ports 22 und 23 blockieren, haben Sie keinen SSH-Zugriff auf den Cluster. Diese Ports werden vom HDInsight-Dienst nicht genutzt.
Weitere Informationen finden Sie in den folgenden Dokumenten:
Kann ich weitere virtuelle Computer im selben Subnetz wie einen HDInsight-Cluster bereitstellen?
Ja, Sie können weitere virtuelle Computer im selben Subnetz wie einen HDInsight-Cluster bereitstellen. Die folgenden Konfigurationen sind möglich:
Edgeknoten: Sie können dem Cluster einen weiteren Edgeknoten hinzufügen, wie unter Verwenden leerer Edgeknoten in Apache Hadoop-Clustern in HDInsight beschrieben.
Eigenständige Knoten: Sie können demselben Subnetz einen eigenständigen virtuellen Computer hinzufügen und über diesen virtuellen Computer auf den Cluster zugreifen, indem Sie den privaten Endpunkt
https://<CLUSTERNAME>-int.azurehdinsight.netverwenden. Weitere Informationen finden Sie unter Steuern des Netzwerkdatenverkehrs.
Sollten Daten auf dem lokalen Datenträger eines Edgeknotens gespeichert werden?
Nein, das Speichern von Daten auf einem lokalen Datenträger ist keine gute Idee. Wenn der Knoten ausfällt, gehen alle lokal gespeicherten Daten verloren. Es wird empfohlen, Daten in Azure Data Lake Storage Gen2 oder Azure Blob Storage zu speichern, oder eine Azure Files-Freigabe zum Speichern der Daten bereitzustellen.
Kann ich einen vorhandenen HDInsight-Cluster einem anderen virtuellen Netzwerk hinzufügen?
Nein, das ist nicht möglich. Das virtuelle Netzwerk sollte zum Zeitpunkt der Bereitstellung angegeben werden. Wenn während der Bereitstellung kein virtuelles Netzwerk angegeben wird, wird ein internes Netzwerk erstellt, auf das ein externer Zugriff nicht möglich ist. Weitere Informationen finden Sie unter Hinzufügen von HDInsight zu einem vorhandenen virtuellen Netzwerk.
Sicherheit und Zertifikate
Welche Empfehlungen gibt es für den Schutz vor Schadsoftware in Azure HDInsight-Clustern?
Informationen zum Schutz vor Schadsoftware finden Sie unter Microsoft Antimalware für Azure Cloud Services und Virtual Machines.
Wie erstelle ich eine Schlüsseltabelle für einen HDInsight-Cluster mit Enterprise-Sicherheitspaket?
Erstellen Sie eine Kerberos-Keytab-Datei für Ihren Domänenbenutzernamen. Sie können diese Keytab-Datei später für die kennwortlose Authentifizierung bei Remoteclustern verwenden, die in die Domäne eingebunden sind. Der Domänenname wird in Großbuchstaben angegeben:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Wann ist für die AES256-Verschlüsselung bei der Erstellung der Schlüsseltabelle ein Salting erforderlich?
Wenn Ihr TenantName und DomainName unterschiedlich sind (z. B. TenantName bob@CONTOSO.ONMICROSOFT.COM und DomainName bob@CONTOSOMicrosoft.ONMICROSOFT.COM), müssen Sie mithilfe der Option „-s“ einen SALT-Wert hinzufügen.
Wie bestimme ich den richtigen SALT-Wert?
- Verwenden Sie eine interaktive Kerberos-Anmeldung, um den richtigen Salt-Wert für die Schlüsseltabelle zu ermitteln. Die interaktive Kerberos-Anmeldung verwendet standardmäßig die höchste Verschlüsselung. Die Ablaufverfolgung sollte aktiviert werden, um das Salt zu beobachten. Im Folgenden finden Sie ein Beispiel für die Kerberos-Anmeldung:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- Suchen Sie in der Ausgabe nach der SALT-Linie „......“.
- Verwenden Sie diesen SALT-Wert beim Erstellen der Schlüsseltabelle.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Kann ich einen vorhandenen Microsoft Entra-Mandanten verwenden, um einen HDInsight-Cluster mit ESP zu erstellen?
Aktivieren Sie Microsoft Entra Domain Services, bevor Sie einen HDInsight-Cluster mit ESP erstellen. Open-Source-Hadoop nutzt für die Authentifizierung Kerberos (und nicht OAuth).
Um virtuelle Computer in eine Domäne einzubinden, ist ein Domänencontroller erforderlich. Microsoft Entra Domain Services ist der verwaltete Domänencontroller und gilt als Erweiterung der Microsoft Entra ID. Microsoft Entra Domain Services erfüllt alle Kerberos-Anforderungen zum Erstellen eines sicheren Hadoop-Clusters auf verwaltete Weise. HDInsight wird als verwalteter Dienst in Microsoft Entra Domain Services integriert, um Sicherheit zu gewährleisten.
Kann ich in einem Microsoft Entra Domain Services-Setup mit Secure LDAP ein selbstsigniertes Zertifikat verwenden und einen Cluster mit Enterprise-Sicherheitspaket bereitstellen?
Die Verwendung eines von einer Zertifizierungsstelle ausgestellten Zertifikats wird empfohlen. Doch unter ESP wird auch die Verwendung eines selbstsignierten Zertifikats unterstützt. Weitere Informationen finden Sie unter:
Kann ich Data Analytics Studio (DAS) als ein ESP-Cluster installieren?
Nein, DAS wird auf ESP-Clustern nicht unterstützt.
Wie kann ich in Ranger angezeigte Anmeldeaktivitäten abrufen?
Microsoft empfiehlt, Azure Monitor-Protokolle zu aktivieren, wie in Verwenden von Azure Monitor-Protokollen zum Überwachen von HDInsight-Clustern beschrieben, um Überwachungsanforderungen zu erfüllen.
Kann ich „Clamscan“ in meinem Cluster deaktivieren?
Clamscan ist die im HDInsight-Cluster ausgeführte Antivirensoftware. Sie wird vom Azure-Sicherheitsprozess (azsecd) verwendet, um Ihre Cluster vor Virenangriffen zu schützen. Microsoft rät dringend davon ab, dass Benutzer Änderungen an der Standardkonfiguration von Clamscan vornehmen.
Durch diesen Prozess werden Zyklen anderer Prozesse weder beeinträchtigt noch verbraucht. Der andere Prozess hat immer Vorrang. Durch Clamscan verursachte CPU-Spitzen sollten nur auftreten, wenn sich das System im Leerlauf befindet.
Für Szenarien, die eine zeitliche Kontrolle erfordern, können Sie die folgenden Schritte ausführen:
Deaktivieren Sie die automatische Ausführung mit dem folgenden Befehl:
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restartFügen Sie einen Cron-Auftrag hinzu, der folgenden Befehl als Root ausführt:
/usr/local/bin/azsecd manual -s clamav
Weitere Informationen zum Einrichten und Ausführen eines Cron-Auftrags finden Sie im Thema zum Einrichten eines Cron-Auftrags.
Weshalb ist LLAP in Spark-ESP-Clustern verfügbar?
LLAP ist aus Sicherheitsgründen (Apache Ranger) aktiviert, nicht aus Leistungsgründen. Verwenden Sie virtuelle Computer mit größeren Knoten, um die Ressourcennutzung von LLAP zu berücksichtigen (z. B. mindestens D13V2).
Wie kann ich nach dem Erstellen eines ESP-Clusters zusätzliche Microsoft Entra-Gruppen hinzufügen?
Zur Erreichung dieses Ziels gibt es zwei Möglichkeiten: 1. Sie können den Cluster neu erstellen und die zusätzliche Gruppe bei der Clustererstellung hinzufügen. Wenn Sie die bereichsbezogene Synchronisierung in Microsoft Entra Domain Services verwenden, stellen Sie sicher, dass Gruppe B in dieser Synchronisierung enthalten ist.
2\. Fügen Sie die Gruppe als geschachtelte Untergruppe der vorherigen Gruppe hinzu, die zum Erstellen des ESP-Clusters verwendet wurde. Wenn Sie beispielsweise einen ESP-Cluster mit der Gruppe A erstellt haben, können Sie zu einem späteren Zeitpunkt die Gruppe B als geschachtelte Untergruppe von A hinzufügen. Nach ungefähr einer Stunde wird sie synchronisiert und steht im Cluster automatisch zur Verfügung.
Storage
Kann ich einem vorhandenen HDInsight-Cluster Azure Data Lake Storage Gen2 als zusätzliches Speicherkonto hinzufügen?
Nein, derzeit ist es nicht möglich, einem Cluster, der Blob Storage als primären Speicher nutzt, ein Azure Data Lake Storage Gen2-Speicherkonto hinzuzufügen. Weitere Informationen finden Sie unter Vergleichen von Speicheroptionen.
Wie finde ich den Dienstprinzipal für ein Data Lake-Speicherkonto, der aktuell verknüpft ist?
Sie finden Ihre Einstellungen im Azure-Portal in den Clustereigenschaften unter Data Lake Storage Gen1-Zugriff. Weitere Informationen finden Sie unter Überprüfen des Clustersetups.
Wie berechne ich die Verwendung von Speicherkonten und BLOB-Containern für meine HDInsight-Cluster?
Führen Sie eine der folgenden Aktionen aus:
Ermitteln Sie die Größe des Ordners /user/hive/.Trash/ im HDInsight-Cluster über die folgende Befehlszeile:
hdfs dfs -du -h /user/hive/.Trash/
Wie richte ich die Überwachung für mein BLOB-Speicherkonto ein?
Um Blobspeicherkonten zu überwachen, konfigurieren Sie die Überwachung entsprechend den unter Überwachen eines Speicherkontos im Azure-Portal beschriebenen Schritten. Ein HDFS-Überwachungsprotokoll enthält nur Überwachungsinformationen für das lokale HDFS-Dateisystem (hdfs://mycluster). Im Remotespeicher ausgeführte Vorgänge werden nicht einbezogen.
Wie übertrage ich Dateien zwischen einem Blobcontainer und einem HDInsight-Hauptknoten?
Führen Sie ein mit dem folgenden Shellskript vergleichbares Skript auf dem Hauptknoten aus:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
Hinweis
Die Datei filenames.txt enthält den absoluten Pfad der Dateien in den BLOB-Containern.
Gibt es Ranger-Plug-Ins für den Speicher?
Derzeit sind keine Ranger-Plug-Ins für Blob Storage und Azure Data Lake Storage Gen1 oder Gen2 verfügbar. Bei ESP-Clustern sollten Sie Azure Data Lake Storage verwenden. Auf Dateisystemebene können Sie mithilfe der HDFS-Tools mindestens differenzierte Berechtigungen manuell festlegen. Darüber hinaus wird bei Verwendung von Azure Data Lake Storage der Dateisystemzugriff bei Clustern mit Enterprise-Sicherheitspaket teilweise auch über Microsoft Entra ID auf Clusterebene gesteuert.
Über Azure Storage-Explorer können Sie den Sicherheitsgruppen Ihrer Benutzer Datenzugriffsrichtlinien zuweisen. Weitere Informationen finden Sie unter:
Kann ich den HDFS-Speicher in einem Cluster vergrößern, ohne dass die Datenträgergröße von Workerknoten zunimmt?
Nein. Sie können die Datenträgergröße eines Workerknotens nicht erhöhen. Die Datenträgergröße kann nur erhöht werden, indem der Cluster gelöscht und mit größeren Worker-VMs neu erstellt wird. Verwenden Sie HDFS nicht zum Speichern von HDInsight-Daten, da beim Löschen des Clusters auch die Daten gelöscht werden. Speichern Sie die Daten stattdessen in Azure. Sie können die Kapazität des HDInsight-Clusters auch erweitern, indem Sie den Cluster zentral hochskalieren.
Edgeknoten
Kann ich nach der Erstellung des Clusters einen Edgeknoten hinzufügen?
Wie stelle ich eine Verbindung mit einem Edgeknoten her?
Nachdem Sie einen Edgeknoten erstellt haben, können Sie über SSH an Port 22 eine Verbindung mit dem Edgeknoten herstellen. Den Namen des Edgeknotens finden Sie im Clusterportal. Die Namen enden im Allgemeinen auf -ed.
Warum werden permanente Skripts auf neu erstellten Edgeknoten nicht automatisch ausgeführt?
Sie verwenden permanente Skripts, um mithilfe von Skalierungsvorgängen neue Workerknoten anzupassen, die dem Cluster hinzugefügt wurden. Persistente Skripts gelten nicht für Edgeknoten.
REST-API
Wie lauten die REST-API-Aufrufe zum Abrufen einer Tez Query-Ansicht aus dem Cluster?
Sie können die folgenden REST-Endpunkte verwenden, um die erforderlichen Informationen im JSON-Format abzurufen. Verwenden Sie standardmäßige Authentifizierungsheader, um diese Anforderungen auszuführen.
-
Tez Query View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/ -
Tez Dag View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/
Wie rufe ich die Konfigurationsdetails aus dem HDI-Cluster mithilfe eines Microsoft Entra-Benutzers ab?
Um mit dem Microsoft Entra-Benutzer korrekte Authentifizierungstoken auszuhandeln, verwenden Sie das folgende Format, um das Gateway zu passieren:
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
Wie verwende ich die RESTful-API von Ambari, um die YARN-Leistung zu überwachen?
Wenn Sie den cURL-Befehl im selben virtuellen Netzwerk oder in einem virtuellen Netzwerk mit Peering aufrufen, verwenden Sie folgenden Befehl:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Wenn Sie den Befehl außerhalb des virtuellen Netzwerks oder in einem virtuellen Netzwerk ohne Peering aufrufen, lautet das Befehlsformat wie folgt:
Cluster ohne Enterprise-Sicherheitspaket:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuCluster mit Enterprise-Sicherheitspaket:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Hinweis
cURL fordert Sie zur Eingabe eines Kennworts auf. Sie müssen ein gültiges Kennwort für den Benutzernamen für die Clusteranmeldung eingeben.
Abrechnung
Wie viel kostet die Bereitstellung eines HDInsight-Clusters?
Weitere Informationen zu Preisen und häufig gestellte Fragen zur Abrechnung finden Sie auf der Seite Azure HDInsight: Preise.
Wann beginnt und endet die HDInsight-Abrechnung?
Die Abrechnung für einen HDInsight-Cluster beginnt, sobald der Cluster erstellt wurde, und endet mit dem Löschen des Clusters. Die Abrechnung erfolgt pro Minute.
Wie kann ich mein Abonnement kündigen?
Informationen zum Kündigen Ihres Abonnements finden Sie unter Kündigen Ihres Azure-Abonnements.
Was geschieht bei Abonnements mit nutzungsbasierter Bezahlung, nachdem ich mein Abonnement gekündigt habe?
Informationen zu Ihrem gekündigten Abonnement finden Sie unter Was geschieht, nachdem ich mein Abonnement gekündigt habe?
Hive
Warum wird auf der Ambari-Benutzeroberfläche die Hive-Version 1.2.1000 statt 2.1 angezeigt, obwohl ich einen HDInsight-Cluster der Version 3.6 ausführe?
Obwohl in der Ambari-Benutzeroberfläche nur 1.2 angezeigt wird, umfasst HDInsight 3.6 sowohl Hive 1.2 als auch Hive 2.1.
Weitere häufig gestellte Fragen
Welche Funktionen bietet HDInsight für die Streamverarbeitung in Echtzeit?
Informationen zu den Integrationsfunktionen für die Streamverarbeitung finden Sie unter Auswählen einer Technologie für die Datenstromverarbeitung in Azure.
Gibt es eine Möglichkeit, den Hauptknoten des Clusters dynamisch zu beenden, wenn sich der Cluster eine bestimmte Zeit im Leerlauf befindet?
Diese Aktion ist bei HDInsight-Clustern nicht möglich. Für diese Szenarien können Sie Azure Data Factory verwenden.
Welche Complianceangebote umfasst HDInsight?
Weitere Informationen zur Compliance finden Sie im Microsoft Trust Center.