Beheben eines Fehlers vom Typ „Nicht genügend Apache Hive-Arbeitsspeicher“ in Azure HDInsight
Erfahren Sie, wie Sie einen Fehler vom Typ „Nicht genügend Apache Hive-Arbeitsspeicher (OOM)“, der beim Verarbeiten großer Tabellen auftreten kann, durch Konfigurieren der Hive-Arbeitsspeichereinstellungen beheben.
Ausführen einer Apache Hive-Abfrage für große Tabellen
Ein Kunde hat die folgende Hive-Abfrage ausgeführt:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Bestimmte Aspekte dieser Abfrage:
- T1 ist ein Alias für eine große Tabelle, TABLE1, die viele STRING-Spaltentypen enthält.
- Andere Tabellen sind nicht so groß, enthalten aber viele Spalten.
- Alle Tabellen sind miteinander verbunden, in einigen Fällen mit mehreren Spalten in TABLE1 und anderen.
Die Ausführung der Hive-Abfrage in einem HDInsight-A3-Cluster mit 24 Knoten dauerte 26 Minuten. Der Kunde erhielt die folgenden Warnmeldungen:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Bei Verwendung der Apache Tez-Ausführungs-Engine. Die gleiche Abfrage wurde 15 Minuten ausgeführt, und dann wurde die folgende Fehlermeldung ausgegeben:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
Bei Verwendung eines größeren virtuellen Computers (wie z. B. D12) wird die Fehlermeldung weiterhin angezeigt.
Debuggen des Fehlers „Nicht genügend Arbeitsspeicher“
Unsere Support- und Entwicklerteams fanden heraus, dass eines der Probleme, das den Fehler vom Typ „Nicht genügend Arbeitsspeicher“ verursacht, ein in der Apache JIRA beschriebenes bekanntes Problem war:
„Wenn hive.auto.convert.join.noconditionaltask = true lautet, überprüfen wir noconditionaltask.size. Wenn die Summe der Tabellengrößen im Kartenjoin kleiner ist als noconditionaltask.size, würde der Plan einen Kartenjoin generieren. Das Problem dabei ist, dass bei der Berechnung der Mehraufwand, der durch unterschiedliche HashTable-Implementierungen als Ergebnisse verursacht wird, nicht berücksichtigt wird, da bei Abfragen ein OOM-Zustand auftritt, wenn die Summe der Eingabegrößen noconditionaltask.size geringfügig überschreitet.“
In der Datei „hive-site.xml“ war hive.auto.convert.join.noconditionaltask auf true festgelegt:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Wahrscheinlich war der Kartenjoin die Ursache für den OOM-Fehler im Java-Heapspeicher. Wie im Blogbeitrag Hadoop Yarn memory settings in HDInsight (Hadoop Yarn-Arbeitsspeichereinstellungen in HDInsight) erläutert, gehört der bei Einsatz der Tez-Ausführungs-Engine verwendete Heapspeicher tatsächlich zum Tez-Container. In der folgenden Abbildung ist der Tez-Containerspeicher dargestellt.
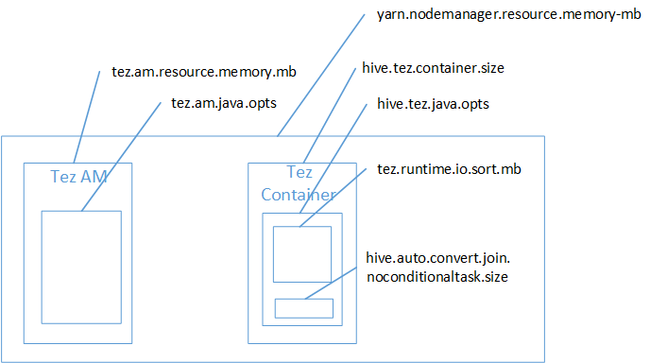
Wie im Blogbeitrag schon erwähnt, definieren die folgenden zwei Einstellungen den Containerspeicher für den Heap: hive.tez.container.size und hive.tez.java.opts. Nach unserer Erfahrung bedeutet die Ausnahme „Nicht genügend Arbeitsspeicher“ nicht, dass der Container zu klein ist. Es bedeutet, dass der Java-Heap (hive.tez.java.opts) zu klein ist. Wenn Sie also eine Fehlermeldung vom Typ „Nicht genügend Arbeitsspeicher“ erhalten, können Sie versuchen, hive.tez.java.opts heraufzusetzen. Ggf. müsse Sie hive.tez.container.size heraufsetzen. Die Einstellung java.opts sollte ungefähr 80 Prozent von container.size betragen.
Hinweis
Die Einstellung hive.tez.java.opts muss stets kleiner sein als hive.tez.container.size.
Da ein D12-Computer über einen Arbeitsspeicher von 28 GB verfügt, haben wir beschlossen, eine Containergröße von 10 GB (10.240 MB) zu verwenden und java.opts 80 % zuzuweisen:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Mit den neuen Einstellungen wurde die Abfrage in weniger als 10 Minuten erfolgreich ausgeführt.
Nächste Schritte
Eine OOM-Fehlermeldung zu erhalten, bedeutet nicht unbedingt, dass der Container zu klein ist. Konfigurieren Sie stattdessen die Einstellungen für den Arbeitsspeicher, sodass die Heapgröße erhöht wird und mindestens 80 % der Größe des Containerspeichers entspricht. Informationen zum Optimieren von Hive-Abfragen finden Sie unter Optimieren von Apache Hive-Abfragen für Apache Hadoop in HDInsight.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für