Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden einige der gängigsten Leistungsoptimierungen beschrieben, mit denen Sie die Leistung Ihrer Apache Hive-Abfragen verbessern können.
Auswahl des Clustertyps
In Azure HDInsight können Sie Apache Hive-Abfragen auf verschiedene Clustertypen anwenden.
Wählen Sie den geeigneten Clustertyp zum Optimieren der Leistung für Ihre Workloadanforderungen aus:
- Wählen Sie z. B. den Clustertyp Interaktive Abfrage für die Optimierung interaktiver
ad hoc-Abfragen aus. - Wählen Sie den Apache Hadoop-Clustertyp zur Optimierung für Hive-Abfragen zur Batchverarbeitung aus.
- Die Clustertypen Spark und HBase können auch Hive-Abfragen ausführen und sind möglicherweise geeignet, wenn Sie diese Workloads ausführen.
Weitere Informationen zum Ausführen von Hive-Abfragen auf verschiedenen Typen von HDInsight-Clustern finden Sie unter Was sind Apache Hive und HiveQL in Azure HDInsight?.
Aufskalieren der Workerknoten
In einem HDInsight-Cluster, dem mehr Workerknoten zur Verfügung stehen, können für die Arbeit mehr Mapper und Reducer parallel ausgeführt werden. In HDInsight können Sie die Aufskalierung auf zwei Weisen erhöhen:
Beim Bereitstellen eines Clusters können Sie die Anzahl der Workerknoten im Azure-Portal, in Azure PowerShell oder über die Befehlszeilenschnittstelle angeben. Weitere Informationen finden Sie unter Erstellen von HDInsight-Clustern. Der folgende Screenshot zeigt die Konfiguration der Workerknoten im Azure-Portal:
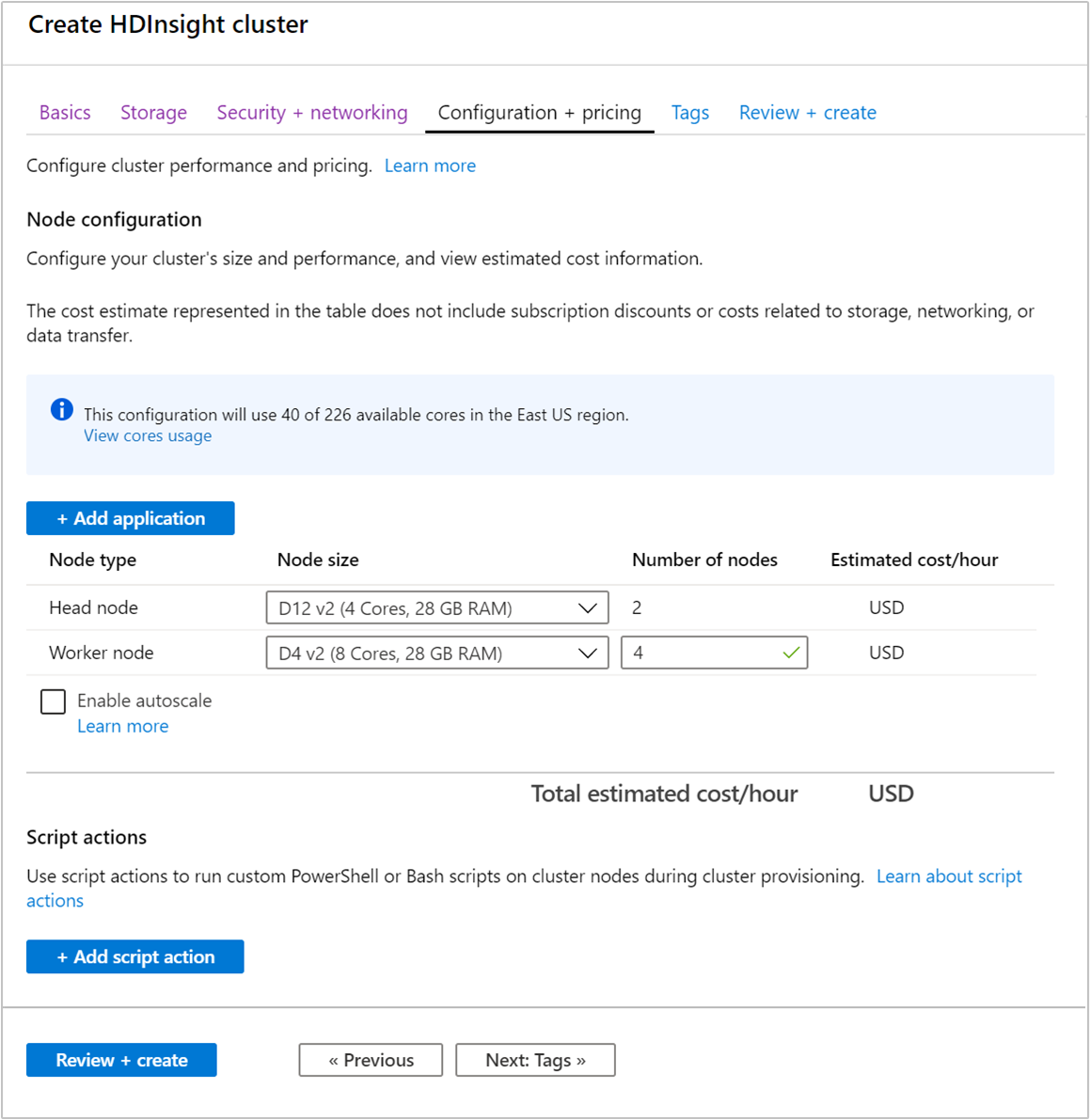
Nach dem Erstellen können Sie auch die Anzahl der Workerknoten zum weiteren Aufskalieren eines Clusters bearbeiten, ohne die Erstellung zu wiederholen:
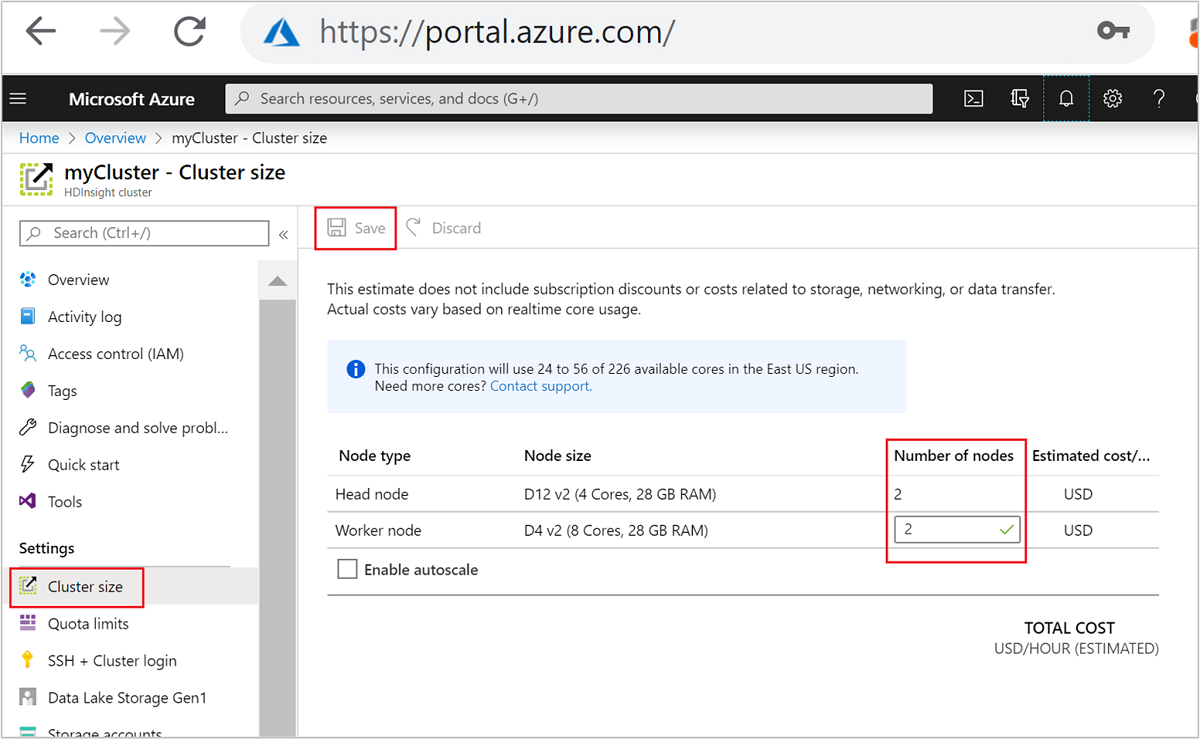
Weitere Informationen zum Skalieren von HDInsight finden Sie unter Skalieren von HDInsight-Clustern.
Verwenden von Apache Tez anstelle von MapReduce
Apache Tez ist eine Alternative zur Ausführungs-Engine MapReduce. Linux-basierte HDInsight-Cluster haben Tez standardmäßig aktiviert.
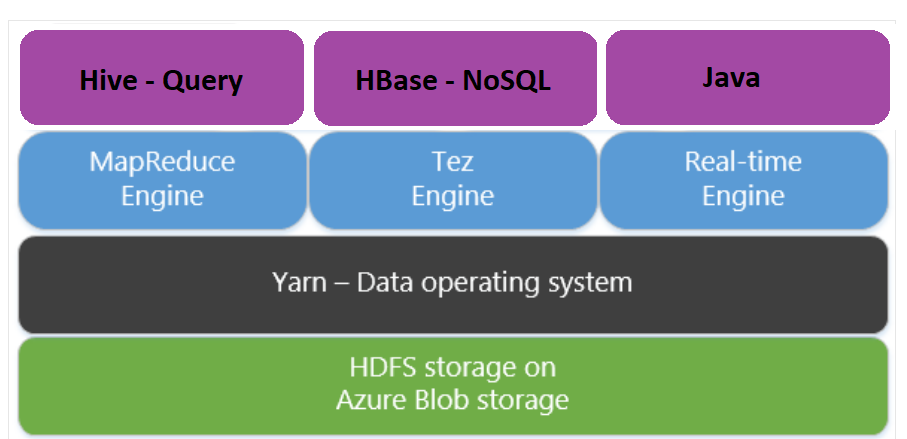
Tez ist jedoch aus folgenden Gründen schneller:
- Ausführen eines gerichteten azyklischen Graphen als einzelnen Auftrag in der MapReduce-Engine. Der gerichtete azyklische Graph erfordert, dass auf jede Gruppe von Mappern eine Gruppe von Reducern folgt. Aufgrund dieser Anforderung werden für jede Hive-Abfrage mehrere MapReduce-Aufträge gestartet. Für Tez gilt diese Einschränkung nicht. Tez kann auch einen komplexen gerichteten azyklischen Graphen in einem Auftrag verarbeiten, sodass weniger Aufträge gestartet werden müssen.
- Vermeiden unnötiger Schreibvorgänge. Es werden mehrere Aufträge verwendet, um die Hive-Abfrage in der MapReduce-Engine zu verarbeiten. Die Ausgabe der einzelnen MapReduce-Aufträge wird in HDFS-Zwischenspeicher geschrieben. Tez hingegen minimiert die Anzahl der Aufträge für jede Hive-Abfrage und vermeidet so unnötige Schreibvorgänge.
- Minimierung von Startverzögerungen. Tez minimiert Startverzögerungen durch Reduzierung der Anzahl der für den Start erforderlichen Mapper sowie durch eine insgesamt bessere Optimierung.
- Wiederverwendung von Containern. Tez versucht, Container möglichst wiederzuverwenden, und verringert so Latenzzeiten aufgrund von Containerstarts.
- Techniken für die fortlaufende Optimierung. Bislang erfolgte die Optimierung in der Regel in der Kompilierungsphase. Nun aber stehen mehr Informationen zu den Eingaben zur Verfügung, die auch während der Laufzeit eine Optimierung ermöglichen. Tez verwendet fortlaufende Optimierungstechniken, durch die der Plan noch weit in der Laufzeitphase optimiert werden kann.
Weitere Informationen zu diesen Konzepten finden unter Apache Tez.
Sie können jede Hive-Abfrage Tez-kompatibel machen, indem Sie der Abfrage den folgenden Festlegungsbefehl voranstellen:
set hive.execution.engine=tez;
Partitionierung in Hive
E/A-Vorgänge sind bei der Ausführung von Hive-Abfragen der größte Leistungsengpass. Die Leistung lässt sich durch Reduzierung der einzulesenden Daten verbessern. Hive-Abfragen durchsuchen standardmäßig gesamte Hive-Tabellen. Doch bei Abfragen, die nur einen Auszug der Daten durchsuchen müssen (z. B. bei Abfragen mit Filtern), bedeutet dies hingegen einen unnötigen Mehraufwand. Durch die Partitionierung in Hive beschränkt sich der Zugriff von Hive-Abfragen auf die erforderlichen Teilmengen von Hive-Tabellen.
Die Hive-Partitionierung wird durch Neuorganisation der Rohdaten in neue Verzeichnisse implementiert. Jede Partition weist ein eigenes Verzeichnis auf. Der Benutzer definiert die Partitionierung. Das folgende Diagramm veranschaulicht die Partitionierung einer Hive-Tabelle nach der Spalte Jahr. Für jedes Jahr wird ein neues Verzeichnis erstellt.
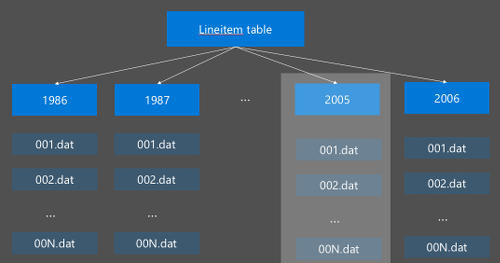
Überlegungen zur Partitionierung:
- Partitionieren Sie großzügig: Wenn Sie die Partitionierung für Spalten mit nur wenigen Werte durchführen, erhalten Sie nur wenige Partitionen. Partitionieren Sie zum Beispiel nach dem Geschlecht, so erhalten Sie nur zwei Partitionen (männlich, weiblich), sodass sich die Latenzzeit also höchstens halbiert.
- Aber nicht zu großzügig: Im anderen Extremfall werden bei Erstellung einer Partition anhand einer Spalte mit einem eindeutigen Wert (z. B. userid) mehrere Partitionen erzeugt. Eine zu großzügige Partitionierung verursacht eine große Belastung für den NameNode des Clusters, da dieser mit einer großen Anzahl von Verzeichnissen zurechtkommen muss.
- Vermeiden Sie zu unterschiedliche Partitionsgrößen – Wählen Sie Ihren Partitionsschlüssel so, dass sich etwa gleich große Partitionen ergeben. Beispielsweise kann die Partitionierung nach der Spalte State möglicherweise die Verteilung der Daten verzerren. Da der Bundesstaat Kalifornien eine Bevölkerung von fast dem 30-Fachen von Vermont aufweist, ist die Größe der Partition möglicherweise verzerrt und die Leistung kann erheblich schwanken.
Zum Erstellen einer Partitionstabelle verwenden Sie die Klausel Partitioned By:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Für die erstellte Partitionstabelle können Sie eine statische oder eine dynamische Partitionierung auswählen.
Statische Partitionierung bedeutet, dass bereits horizontal partitionierte Daten in den entsprechenden Verzeichnissen vorhanden sind. Mit statischen Partitionen fügen Sie Hive-Partitionen manuell basierend auf dem Speicherort des Verzeichnisses hinzu. Der folgende Codeausschnitt ist ein Beispiel.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Dynamische Partitionierung bedeutet, dass Hive die Partitionen automatisch erstellen und anpassen soll. Da Sie die Partitionstabelle bereits anhand der Stagingtabelle erstellt haben, müssen Sie die Tabelle nun nur noch mit Daten füllen:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Weitere Informationen finden Sie unter Partitionierte Tabellen.
Verwenden des Dateiformats ORC
Hive unterstützt verschiedene Dateiformate. Beispiel:
- Text: Das Standarddateiformat, das in den meisten Szenarien funktioniert.
- Avro: Dieses Dateiformat eignet sich besonders für Interoperabilitätsszenarien.
- ORC/Parquet: Dieses Dateiformat ist leistungsorientiert.
Das ORC-Format (Optimized Row Columnar) ist eine sehr effiziente Speichermethode für Hive-Daten. Gegenüber anderen Formaten hat ORC die folgenden Vorteile:
- Unterstützung für komplexe Typen, einschließlich DateTime, und komplexe und teilstrukturierte Typen
- Komprimierung bis zu 70 %
- Indizierung aller 10.000 Zeilen, wodurch das Überspringen von Zeilen möglich wird
- Wesentlich schnellere Laufzeitausführung
Zum Aktivieren von ORC erstellen Sie zunächst eine Tabelle mit der Klausel Stored as ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Danach fügen Sie der ORC-Tabelle Daten aus der Stagingtabelle hinzu. Beispiel:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Weitere Informationen zum ORC-Format finden Sie im Handbuch zur Apache Hive-Sprache.
Vektorisierung
Durch Vektorisierung kann Hive anstatt einzelnen Zeilen Batches mit jeweils 1024 Zeilen gleichzeitig verarbeiten. Einfache Vorgänge erfolgen so schneller, da weniger interner Code ausgeführt werden muss.
Zum Aktivieren der Vektorisierung stellen Sie Ihrer Hive-Abfrage folgende Einstellung voran:
set hive.vectorized.execution.enabled = true;
Weitere Informationen finden Sie unter Vektorisierte Abfrageausführung.
Weitere Optimierungsmethoden
Es gibt noch weitere Optimierungsmethoden, die durchaus erwägenswert sind, zum Beispiel die folgenden:
- Hive-Bucketing: Ein Verfahren, mit dem große Datenmengen zur Optimierung der Abfrageleistung zusammengefasst bzw. segmentiert werden.
- Join-Optimierung: Optimierung des Hive-Abfrageausführungsplans zur Steigerung der Effizienz von Joins. Außerdem sollen dadurch Benutzerhinweise weitgehend unnötig werden. Weitere Informationen finden Sie unter Join-Optimierung.
- Reducer erhöhen.
Nächste Schritte
In diesem Artikel haben Sie mehrere allgemeine Hive-Methoden zur Optimierung von Abfragen kennengelernt. Weitere Informationen erhalten Sie in den folgenden Artikeln: