Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wenn eine Anwendung, die Daten auf einem HDInsight-Cluster verarbeitet, entweder langsam ist oder ein Fehlercode angezeigt wird, haben Sie mehrere Möglichkeiten, die Problembehandlung durchzuführen. Falls die Ausführung Ihrer Aufträge länger als erwartet dauert oder es generell zu langsamen Reaktionszeiten kommt, liegen unter Umständen im Bereich vor Ihrem Cluster Fehler vor, z.B. für die Dienste, unter denen der Cluster ausgeführt wird. Die häufigste Ursache dieser Verlangsamungen ist aber eine unzureichende Skalierung. Wählen Sie beim Erstellen eines neuen HDInsight-Clusters die geeigneten VM-Größen aus.
Sammeln Sie zum Diagnostizieren eines langsamen oder fehlerhaften Clusters Informationen zu allen Aspekten der Umgebung, z. B. zugeordnete Azure-Dienste, Clusterkonfiguration und Auftragsausführung. Ein hilfreicher Diagnosevorgang ist der Versuch, den Fehlerzustand in einem anderen Cluster zu reproduzieren.
- Schritt 1: Sammeln von Daten zum Problem
- Schritt 2: Überprüfen der HDInsight-Clusterumgebung
- Schritt 3: Anzeigen der Integrität des Clusters
- Schritt 4: Überprüfen der Umgebungsstapel und Versionen
- Schritt 5: Überprüfen der Clusterprotokolldateien
- Schritt 6: Überprüfen der Konfigurationseinstellungen
- Schritt 7: Reproduzieren des Fehlers in einem anderen Cluster
Schritt 1: Sammeln von Daten zum Problem
HDInsight umfasst viele Tools, die Sie zum Identifizieren und Behandeln von Problemen mit Clustern verwenden können. In den folgenden Schritten werden diese Tools beschrieben, und Sie erhalten Vorschläge für die genaue Ermittlung des Problems.
Identifizieren des Problems
Beantworten Sie die folgenden Fragen zur Identifizierung des Problems:
- Was wurde erwartet? Wie hat er sich stattdessen verhalten?
- Wie lange hat die Durchführung des Prozesses gedauert? Wie lange hätte die Ausführung dauern sollen?
- Wurden meine Tasks in diesem Cluster schon immer langsam durchgeführt? Ist die Ausführung in einem anderen Cluster schneller?
- Wann ist dieses Problem zum ersten Mal aufgetreten? Wie häufig ist es seitdem aufgetreten?
- Hat sich an meiner Clusterkonfiguration etwas geändert?
Clusterdetails
Wichtige Clusterinformationen sind:
- Clustername.
- Clusterregion – Prüfung auf Regionsausfälle durchführen
- Typ und Version des HDInsight-Clusters
- Typ und Anzahl von HDInsight-Instanzen, die für die Haupt- und Workerknoten angegeben wurden
Im Azure-Portal können diese Informationen bereitgestellt werden:
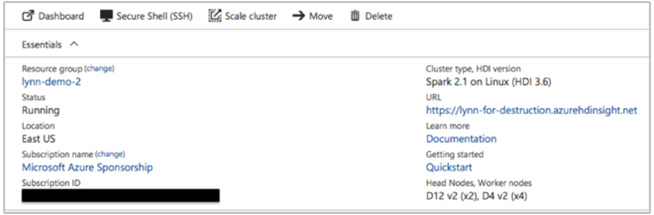
Sie können auch die Azure CLI verwenden:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Eine andere Möglichkeit ist die Verwendung von PowerShell. Weitere Informationen finden Sie unter Verwalten von Apache Hadoop-Clustern in HDInsight mit Azure PowerShell.
Schritt 2: Überprüfen der HDInsight-Clusterumgebung
Jeder HDInsight-Cluster basiert auf verschiedenen Azure-Diensten und auf Open-Source-Software, z.B. Apache HBase und Apache Spark. HDInsight-Cluster können auch für andere Azure-Dienste aufgerufen werden, z.B. Azure Virtual Networks. Ein Clusterfehler kann durch alle Dienste, die im Cluster ausgeführt werden, oder einen externen Dienst verursacht werden. Außerdem kann auch eine Änderung der Clusterdienstkonfiguration zu einem Clusterfehler führen.
Dienstdetails
- Überprüfen der Releaseversionen von Open-Source-Bibliotheken
- Durchführen einer Prüfung auf Ausfälle von Azure-Diensten
- Überprüfen der Nutzungseinschränkungen von Azure-Diensten
- Überprüfen der Subnetzkonfiguration für virtuelle Azure-Netzwerke
Anzeigen von Einstellungen zur Clusterkonfiguration mit der Ambari-Benutzeroberfläche
Apache Ambari ermöglicht die Verwaltung und Überwachung eines HDInsight-Clusters mit einer Webbenutzeroberfläche und einer REST-API. Ambari ist in Linux-basierten HDInsight-Clustern enthalten. Wählen Sie im Azure-Portal auf der Seite „HDInsight“ den Bereich Cluster-Dashboard. Wählen Sie den Bereich HDInsight-Cluster-Dashboard, um die Ambari-Benutzeroberfläche zu öffnen, und geben Sie die Anmeldeinformationen für die Anmeldung am Cluster ein.
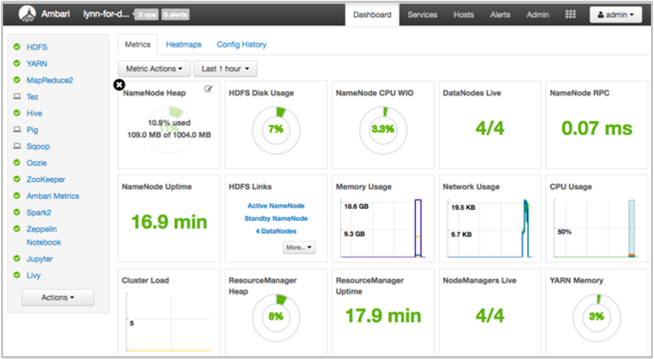
Wählen Sie zum Öffnen einer Liste mit den Dienstansichten auf der Azure-Portalseite die Option Ambari Views. Der Inhalt dieser Liste richtet sich danach, welche Bibliotheken installiert sind. Beispielsweise werden ggf. YARN Queue Manager, Hive View und Tez View angezeigt. Wählen Sie einen Dienstlink aus, um die Konfigurations- und Dienstinformationen anzuzeigen.
Durchführen einer Prüfung auf Ausfälle von Azure-Diensten
HDInsight basiert auf mehreren Azure-Diensten. Virtuelle Server werden in Azure HDInsight ausgeführt, Daten und Skripts werden in Azure Blob Storage oder Azure Data Lake Storage gespeichert, und Protokolldateien werden in Azure Table Storage indiziert. Störungen dieser Dienste sind zwar selten, können aber zu Problemen in HDInsight führen. Überprüfen Sie den Azure-Status im entsprechenden Dashboard, falls für Ihren Cluster unerwartete Verlangsamungen oder Fehler auftreten. Der Status der einzelnen Dienste ist nach Region aufgeführt. Überprüfen Sie die Region Ihres Clusters und die Regionen für alle dazugehörigen Dienste.
Überprüfen der Nutzungseinschränkungen von Azure-Diensten
Wenn Sie einen großen Cluster starten oder viele Cluster gleichzeitig gestartet haben, kann es für einen Cluster zu einem Fehler kommen, wenn Sie eine Azure-Diensteinschränkung überschritten haben. Diensteinschränkungen variieren je nach Azure-Abonnement. Weitere Informationen finden Sie unter Grenzwerte für Azure-Abonnements, -Dienste und -Kontingente sowie allgemeine Beschränkungen. Sie können anfordern, dass Microsoft die Anzahl von verfügbaren HDInsight-Ressourcen erhöht (z.B. VM-Kerne und VM-Instanzen), indem Sie eine Anforderung zur Erhöhung des Resource Manager-Kernkontingents erstellen.
Überprüfen der Releaseversion
Vergleichen Sie die Clusterversion mit dem aktuellen HDInsight-Release. Jedes HDInsight-Release umfasst Verbesserungen, z. B. neue Anwendungen, Features, Patches und Fehlerbehebungen. Unter Umständen wurde das Problem, das Ihren Cluster beeinträchtigt, in der letzten Releaseversion behoben. Führen Sie Ihren Cluster nach Möglichkeit erneut aus, indem Sie die aktuelle Version von HDInsight und die dazugehörigen Bibliotheken wie Apache HBase, Apache Spark oder andere verwenden.
Neustarten Ihrer Clusterdienste
Falls es in Ihrem Cluster zu Verlangsamungen kommt, können Sie erwägen, Ihre Dienste über die Ambari-Benutzeroberfläche oder die klassische Azure-Befehlszeilenschnittstelle neu zu starten. Unter Umständen kommt es im Cluster zu vorübergehenden Fehlern, und ein Neustart ist die schnellste Möglichkeit, die Umgebung zu stabilisieren und ggf. die Leistung zu verbessern.
Schritt 3: Anzeigen der Integrität des Clusters
HDInsight-Cluster bestehen aus unterschiedlichen Arten von Knoten, die auf VM-Instanzen ausgeführt werden. Jeder Knoten kann auf ungenügende Ressourcen, Probleme mit der Netzwerkkonnektivität und andere Probleme überwacht werden, die den Cluster verlangsamen können. Jeder Cluster enthält zwei Hauptknoten, und die meisten Clustertypen enthalten eine Kombination aus Worker- und Edgeknoten.
Eine Beschreibung der verschiedenen Knoten, die jeder Clustertyp verwendet, finden Sie unter Einrichten von Clustern in HDInsight mit Hadoop, Spark, Kafka usw.
In den folgenden Abschnitten wird beschrieben, wie Sie die Integrität der einzelnen Knoten und des gesamten Clusters überprüfen.
Abrufen einer Momentaufnahme der Clusterintegrität über das Dashboard der Ambari-Benutzeroberfläche
Das Dashboard der Ambari-Benutzeroberfläche (https://<clustername>.azurehdinsight.net) enthält eine Übersicht über die Clusterintegrität, z.B. zu Betriebszeit, Arbeitsspeicher, Netzwerk- und CPU-Auslastung, Hadoop Distributed File System-Datenträgerauslastung usw. Verwenden Sie den Abschnitt „Hosts“ von Ambari, um die Ressourcen auf Hostebene anzuzeigen. Sie können Dienste auch beenden und neu starten.
Überprüfen Ihres WebHCat-Diensts
Ein allgemeines Szenario für Fehler bei Apache Hive-, Apache Pig- oder Apache Sqoop-Aufträgen ist ein Ausfall des WebHCat-Diensts (oder Templeton). WebHCat ist eine REST-Schnittstelle für die Remoteausführung von Aufträgen, z.B. Hive, Pig, Scoop und MapReduce. WebHCat übersetzt die Anforderungen zur Auftragsübermittlung in Apache Hadoop-YARN-Anwendungen und gibt einen Status zurück, der vom YARN-Anwendungsstatus abgeleitet wird. In den folgenden Abschnitten werden allgemeine WebHCat-HTTP-Statuscodes beschrieben.
BadGateway (Statuscode 502)
Dieser Code ist eine generische Meldung von Gatewayknoten und der häufigste Fehlerstatuscode. Eine mögliche Ursache ist, dass der WebHCat-Dienst auf dem aktiven Hauptknoten ausgefallen ist. Verwenden Sie den folgenden CURL-Befehl, um dies zu prüfen:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
In Ambari wird eine Warnung angezeigt, und es werden die Hosts angegeben, auf denen der WebHCat-Dienst ausgefallen ist. Sie können versuchen, den WebHCat-Dienst wieder verfügbar zu machen, indem Sie den Dienst auf seinem Host neu starten.
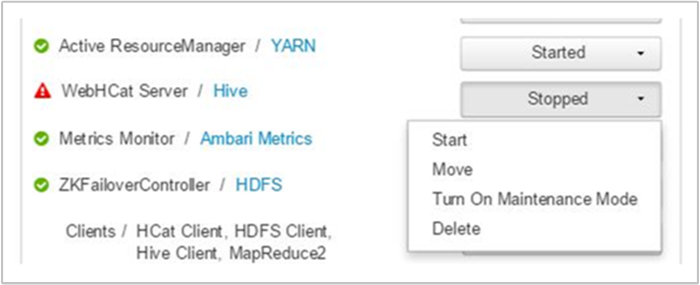
Wenn ein WebHCat-Server immer noch nicht verfügbar ist, sollten Sie das Vorgangsprotokoll auf Fehlermeldungen prüfen. Ausführlichere Informationen erhalten Sie, indem Sie die Dateien stderr und stdout überprüfen, auf die auf den Knoten verwiesen wird.
WebHCat-Timeout
Für ein HDInsight-Gateway tritt für Antworten, die länger als zwei Minuten dauern, ein Timeout auf, und es wird 502 BadGateway zurückgegeben. WebHCat fragt den Auftragsstatus von YARN-Diensten ab, und wenn YARN mehr als zwei Minuten für die Antwort benötigt, kann für diese Anforderung ein Timeout auftreten.
Überprüfen Sie in diesem Fall die folgenden Protokolle im Verzeichnis /var/log/webhcat:
- webhcat.log ist das Log4j-Protokoll, in das der Server Protokolle schreibt
- webhcat-console.log ist das stdout-Element des Servers beim Starten.
- webhcat-console-error.log ist das stderr-Element des Serverprozesses.
Hinweis
Für jede webhcat.log-Datei wird täglich ein Rollover durchgeführt, und es werden Dateien mit Namen wie webhcat.log.YYYY-MM-DD generiert. Wählen Sie die Datei für den gewünschten Zeitraum aus, den Sie untersuchen.
In den folgenden Abschnitten werden einige mögliche Ursachen für WebHCat-Timeouts beschrieben.
Timeout auf WebHCat-Ebene
Wenn WebHCat mit mehr als zehn geöffneten Sockets ausgelastet ist, dauert die Herstellung neuer Socketverbindungen länger, und dies kann zu einem Timeout führen. Verwenden Sie zum Auflisten der ein- und ausgehenden Netzwerkverbindungen für WebHCat auf dem aktuellen aktiven Hauptknoten netstat:
netstat | grep 30111
30111 ist der Port, über den WebHCat lauscht. Es sollten weniger als zehn Sockets geöffnet sein.
Wenn keine Sockets geöffnet sind, führt der obige Befehl nicht zu einem Ergebnis. Verwenden Sie Folgendes, um zu überprüfen, ob Templeton aktiv ist und über Port 30111 lauscht:
netstat -l | grep 30111
Timeout auf YARN-Ebene
Templeton ruft YARN zur Ausführung von Aufträgen auf, und die Kommunikation zwischen Templeton und YARN kann zu einem Timeout führen.
Auf YARN-Ebene gibt es zwei Arten von Timeouts:
Die Übermittlung eines YARN-Auftrags kann ggf. so lange dauern, dass es zu einem Timeout kommt.
Wenn Sie die Protokolldatei
/var/log/webhcat/webhcat.logöffnen und nach „queued job“ (Auftrag in Warteschlange) suchen, werden ggf. mehrere Einträge mit sehr langer Ausführungsdauer (>2000 ms) und Einträge mit immer längeren Wartezeiten angezeigt.Die Dauer für die Aufträge in der Warteschlange nimmt weiter zu, da die Rate, mit der neue Aufträge übermittelt werden, höher als die Rate ist, mit der alte Aufträge abgeschlossen werden. Wenn der YARN-Arbeitsspeicher zu 100% ausgelastet ist, kann
joblauncher queuekeine Kapazität mehr von der Standardwarteschlange ausleihen. Aus diesem Grund können für die Auftragsstartprogramm-Warteschlange keine neuen Aufträge mehr akzeptiert werden. Dieses Verhalten kann dazu führen, dass die Wartezeit immer länger wird und ein Timeoutfehler auftritt, auf den normalerweise viele weitere Fehler folgen.Die folgende Abbildung zeigt die Auftragsstartprogramm-Warteschlange mit einer Überlastung von 714,4%. Dies ist akzeptabel, solange die Standardwarteschlange noch über freie Kapazität verfügt, die ausgeliehen werden kann. Wenn der Cluster aber vollständig ausgelastet ist und der YARN-Arbeitsspeicher eine Kapazitätsauslastung von 100% aufweist, müssen neue Aufträge warten. Dies führt letztendlich zu Timeouts.

Es gibt zwei Möglichkeiten, dieses Problem zu beheben: Reduzieren Sie entweder die Geschwindigkeit der neuen Aufträge, oder erhöhen Sie die Verbrauchsgeschwindigkeit alter Aufträge, indem Sie den Cluster zentral hochskalieren.
Die YARN-Verarbeitung kann lange dauern, sodass sich Timeouts ergeben können.
Auflisten aller Aufträge: Dies ist ein zeitaufwändiger Aufruf. Dieser Aufruf listet die Anwendungen vom YARN-Resource Manager auf und ruft für jede abgeschlossene Anwendung den Status vom YARN-JobHistoryServer ab. Bei einer höheren Auftragsanzahl kann es für diesen Aufruf zu einem Timeout kommen.
Auflisten von Aufträgen, die älter als sieben Tage sind: Der HDInsight YARN JobHistoryServer ist so konfiguriert, dass Informationen zu abgeschlossenen Aufträgen sieben Tage lang aufbewahrt werden (Wert
mapreduce.jobhistory.max-age-ms). Der Versuch, endgültig gelöschte Auftragsergebnisse zu enumerieren, führt zu einem Timeout.
Gehen Sie wie folgt vor, um diese Probleme zu diagnostizieren:
- Ermitteln des UTC-Zeitraums für die Problembehandlung
- Auswählen der entsprechenden
webhcat.log-Dateien - Suchen nach WARN- und ERROR-Meldungen für diesen Zeitraum
Weitere WebHCat-Fehler
HTTP-Statuscode 500
In den meisten Fällen, in denen WebHCat „500“ zurückgibt, enthält die Fehlermeldung Details zum Fehler. Suchen Sie andernfalls in
webhcat.lognach WARN- und ERROR-Meldungen.Auftragsfehler
Es kann Fälle geben, in denen Interaktionen mit WebHCat erfolgreich sind, während für die Aufträge Fehler auftreten.
Templeton sammelt die Ausgabe der Auftragskonsole als
stderrinstatusdir. Dies ist häufig hilfreich für die Problembehandlung.stderrenthält den YARN-Anwendungsbezeichner der eigentlichen Abfrage.
Schritt 4: Überprüfen der Umgebungsstapel und Versionen
Die Seite Stack and Versions (Stapel und Versionen) der Ambari-Benutzeroberfläche enthält Informationen zur Konfiguration und zum Dienstversionsverlauf von Clusterdiensten. Fehlerhafte Hadoop-Dienstbibliotheksversionen können eine Ursache für einen Clusterfehler sein. Wählen Sie in der Ambari-Benutzeroberfläche das Menü Admin und dann die Option Stack and Versions (Stapel und Versionen) aus. Wählen Sie auf der Seite die Registerkarte Versions (Versionen), um Informationen zur Dienstversion anzuzeigen:
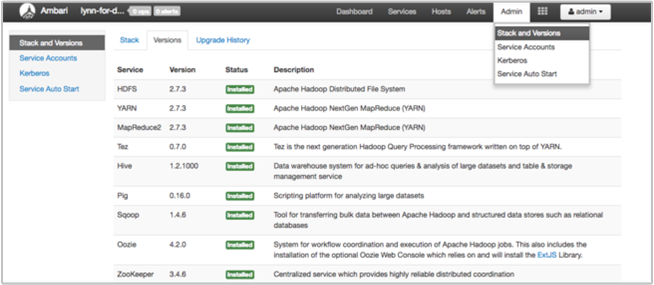
Schritt 5: Untersuchen der Protokolldateien
Es gibt viele Arten von Protokollen, die von den vielen Diensten und Komponenten generiert werden, aus denen ein HDInsight-Cluster besteht. WebHCat-Protokolldateien wurden bereits beschrieben. Es gibt noch mehrere andere nützliche Protokolldateien, die Sie untersuchen können, um Probleme mit Ihrem Cluster einzugrenzen. Dies wird in den folgenden Abschnitten beschrieben.
HDInsight-Cluster bestehen aus mehreren Knoten, von denen die meisten für die Ausführung von übermittelten Aufträgen bestimmt sind. Aufträge werden gleichzeitig ausgeführt, aber Protokolldateien können Ergebnisse nur linear anzeigen. HDInsight führt neue Tasks aus und beendet zuerst andere Tasks, die nicht abgeschlossen werden können. Alle Aktivitäten werden in den Dateien
stderrundsyslogprotokolliert.In den Skriptaktion-Protokolldateien werden während der Erstellung des Clusters Fehler oder unerwartete Konfigurationsänderungen angezeigt.
In den Hadoop-Schrittprotokollen werden Hadoop-Aufträge identifiziert, die im Rahmen eines Schritts mit Fehlern gestartet wurden.
Überprüfen der Skriptaktionsprotokolle
Mit HDInsight-Skriptaktionen werden Skripts im Cluster manuell oder wie angegeben ausgeführt. Skriptaktionen können beispielsweise verwendet werden, um zusätzliche Software im Cluster zu installieren oder für Konfigurationseinstellungen die Standardwerte zu ändern. Durch das Überprüfen der Skriptaktionsprotokolle können Sie Erkenntnisse zu Fehlern erhalten, die während der Einrichtung und Konfiguration des Clusters aufgetreten sind. Sie können den Status einer Skriptaktion anzeigen, indem Sie auf der Ambari-Benutzeroberfläche die Schaltfläche ops (Vorgänge) wählen oder auf die Protokolle des Standardspeicherkontos zugreifen.
Die Skriptaktionsprotokolle befinden sich im Verzeichnis \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE.
Anzeigen von HDInsight-Protokollen mit Ambari-Quicklinks
Die HDInsight Ambari-Benutzeroberfläche enthält mehrere Abschnitte mit Quicklinks. Öffnen Sie zum Zugreifen auf die Protokolllinks für einen bestimmten Dienst in Ihrem HDInsight-Cluster die Ambari-Benutzeroberfläche für den Cluster, und wählen Sie anschließend in der Liste auf der linken Seite den Dienstlink aus. Wählen Sie das Dropdownmenü Quicklinks, den gewünschten HDInsight-Knoten und dann den Link für das zugeordnete Protokoll aus.
Beispiel für Hadoop Distributed File System-Protokolle:
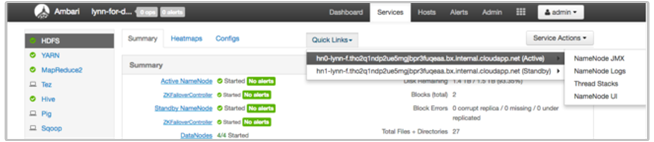
Anzeigen der von Hadoop-generierten Protokolldateien
Ein HDInsight-Cluster generiert Protokolle, die in Azure Tables und Azure Blob Storage geschrieben werden. YARN erstellt eigene Ausführungsprotokolle. Weitere Informationen finden Sie unter Verwalten von Protokollen für einen HDInsight-Cluster.
Überprüfen von Heapdumps
Heapdumps (Heap-Speicherabbilder) enthalten eine Momentaufnahme des Anwendungsarbeitsspeichers, einschließlich der Werte von Variablen zum entsprechenden Zeitpunkt. Dies ist hilfreich beim Diagnostizieren von Problemen, die zur Laufzeit auftreten. Weitere Informationen finden Sie unter Aktivieren von Heapdumps für Apache Hadoop-Dienste in Linux-basiertem HDInsight.
Schritt 6: Überprüfen der Konfigurationseinstellungen
HDInsight-Cluster sind mit Standardeinstellungen für verwandte Dienste vorkonfiguriert, z.B. Hadoop, Hive, HBase usw. Es kann sein, dass Sie je nach Clustertyp, Hardwarekonfiguration, Knotenanzahl, Arten von ausgeführten Aufträgen und den verwendeten Daten (sowie der Verarbeitungsweise der Daten) die Konfiguration optimieren müssen.
Detaillierte Anleitungen zum Optimieren von Leistungskonfigurationen für die meisten Szenarios finden Sie unter Verwenden von Apache Ambari zum Optimieren von HDInsight-Clusterkonfigurationen. Wenn Sie Spark verwenden, erfahren Sie mehr unter Optimieren von Apache Spark-Aufträgen.
Schritt 7: Reproduzieren des Fehlers in einem anderen Cluster
Als Hilfe beim Diagnostizieren der Quelle eines Clusterfehlers können Sie einen neuen Cluster mit der gleichen Konfiguration starten und dann die Schritte des fehlgeschlagenen Auftrags einzeln nacheinander erneut übermitteln. Überprüfen Sie die Ergebnisse der einzelnen Schritte, bevor Sie mit der Verarbeitung des nächsten Schritts beginnen. Mit diesem Verfahren erhalten Sie die Möglichkeit, einen einzelnen fehlgeschlagenen Schritt zu korrigieren und erneut auszuführen. Außerdem hat dieses Verfahren den Vorteil, dass Ihre Eingabedaten nur einmal geladen werden.
- Erstellen Sie einen neuen Testcluster mit der gleichen Konfiguration wie für den fehlgeschlagenen Cluster.
- Übermitteln Sie den ersten Auftragsschritt an den Testcluster.
- Nachdem die Verarbeitung des Schritts abgeschlossen wurde, können Sie die Schrittprotokolldateien auf Fehler prüfen. Stellen Sie eine Verbindung mit dem Masterknoten des Testclusters her, und zeigen Sie die Protokolldateien dafür an. Die Schrittprotokolldateien werden erst angezeigt, nachdem der Schritte einige Zeit ausgeführt wurde, beendet wurde oder fehlgeschlagen ist.
- Führen Sie den nächsten Schritt aus, wenn der erste Schritt erfolgreich war. Falls Fehler auftreten, können Sie diese in den Protokolldateien untersuchen. Wenn ein Fehler in Ihrem Code aufgetreten ist, können Sie die Korrektur vornehmen und den Schritt dann erneut ausführen.
- Setzen Sie diese Vorgehensweise fort, bis alle Schritte fehlerlos ausgeführt wurden.
- Wenn Sie mit dem Debuggen des Testclusters fertig sind, können Sie ihn löschen.
Nächste Schritte
- Verwalten von HDInsight-Clustern mithilfe der Apache Ambari-Webbenutzeroberfläche
- Analysieren von HDInsight-Protokollen
- Zugreifen auf die Apache Hadoop YARN-Anwendungsanmeldung unter Linux-basiertem HDInsight
- Aktivieren von Heapdumps für Apache Hadoop-Dienste in Linux-basiertem HDInsight
- Bekannte Probleme bei Apache Spark-Clustern unter HDInsight