Leitfaden zur Größenanpassung des Azure HDInsight Interactive Query-Clusters (Hive LLAP)
In diesem Dokument wird die Größenanpassung des HDInsight Interactive Query-Clusters (Hive LLAP-Clusters) für eine typische Workload beschrieben, um eine angemessene Leistung zu erzielen. Beachten Sie, dass die Empfehlungen in diesem Dokument allgemeine Richtlinien sind und bestimmte Workloadseine spezifische Optimierung erfordern.
Standardmäßige Azure-VM-Typen für HDInsight Interactive Query-Cluster (LLAP)
| Knotentyp | Instanz | Size |
|---|---|---|
| Head | D13 v2 | 8 vcpus, 56 GB RAM, 400 GB SSD |
| Worker | D14 v2 | 16 vcpus, 112 GB RAM, 800 GB SSD |
| ZooKeeper | A4 v2 | 4 vcpus, 8 GB RAM, 40 GB SSD |
Hinweis: Alle empfohlenen Konfigurationswerte basieren auf dem Workerknoten des Typs D14 v2.
Konfiguration:
| Konfigurationsschlüssel | Empfohlener Wert | BESCHREIBUNG |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 102400 (MB) | Gesamter festgelegter Speicher in MB für alle YARN-Container in einem Knoten |
| yarn.scheduler.maximum-allocation-mb | 102400 (MB) | Maximale Zuordnung für jede Containeranforderung in Resource Manager in MB. Speicheranforderungen, die diesen Wert übersteigen, werden nicht wirksam. |
| yarn.scheduler.maximum-allocation-vcores | 12 | Maximale Anzahl der CPU-Kerne für jede Containeranforderung in Resource Manager. Anforderungen, die diesen Wert übersteigen, werden nicht wirksam. |
| yarn.nodemanager.resource.cpu-vcores | 12 | Anzahl der CPU-Kerne pro NodeManager, die für Container zugeordnet werden können |
| yarn.scheduler.capacity.root.llap.capacity | 85 (%) | YARN-Kapazitätszuordnung für LLAP-Warteschlange |
| tez.am.resource.memory.mb | 4096 (MB) | Der von Tez-AppMaster zu verwendende Speicher in MB |
| hive.server2.tez.sessions.per.default.queue | <number_of_worker_nodes> | Anzahl der Sitzungen für jede Warteschlange, die in „hive.server2.tez.default.queues“ benannt wird. Diese Anzahl entspricht der Anzahl der Abfragekoordinatoren (Tez-AMs). |
| hive.tez.container.size | 4096 (MB) | Angegebene Tez-Containergröße in MB |
| hive.llap.daemon.num.executors | 19 | Anzahl der Executors pro LLAP-Daemon |
| hive.llap.io.threadpool.size | 19 | Threadpoolgröße für Executors |
| hive.llap.daemon.yarn.container.mb | 81920 (MB) | Gesamter Speicher in MB, der von einzelnen LLAP-Daemons verwendet wird (Speicher pro Daemon) |
| hive.llap.io.memory.size | 242688 (MB) | Cachegröße in MB pro LLAP-Daemon, bereitgestellter SSD-Cache ist aktiviert |
| hive.auto.convert.join.noconditionaltask.size | 2048 (MB) | Speichergröße in MB für Map Join |
LLAP-Architektur/Komponenten:
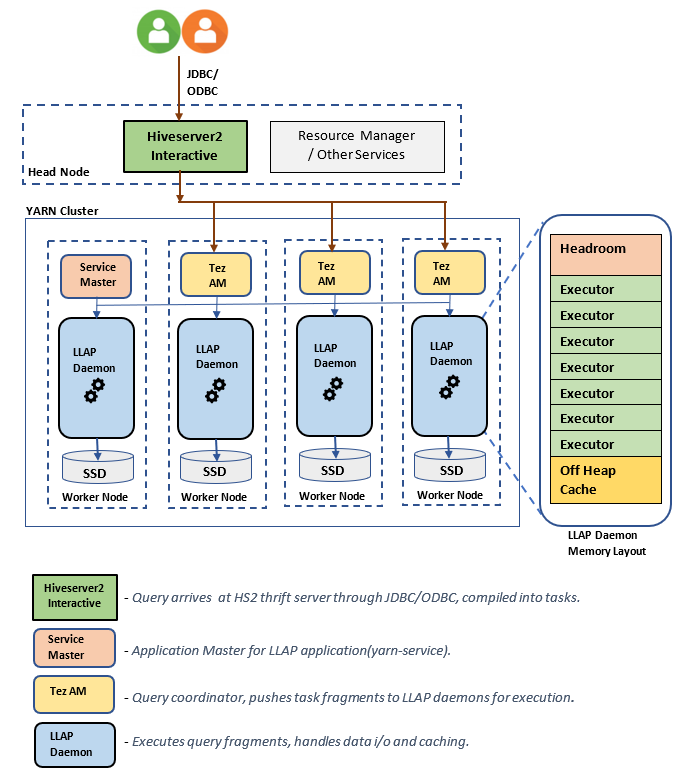
Größenschätzungen für LLAP-Daemon:
1. Festlegen der gesamten YARN-Speicherbelegung für alle Container in einem Knoten
Konfiguration: yarn.nodemanager.resource.memory-mb
Dieser Wert gibt eine maximale Speichermenge in MB an, die in den YARN-Containern in jedem Knoten verwendet werden kann. Der angegebene Wert muss kleiner sein als die Gesamtmenge des physischen Speichers im jeweiligen Knoten.
Gesamtspeicher für alle YARN-Container in einem Knoten = (Gesamter physischer Arbeitsspeicher – Arbeitsspeicher für Betriebssystem und andere Dienste)
Legen Sie diesen Wert auf ca. 90 % der verfügbaren RAM-Größe fest.
Für D14 v2 lautet der empfohlene Wert 102.400 MB.
2. Festlegen der maximalen Speichermenge pro YARN-Containeranforderung
Konfiguration: yarn.scheduler.maximum-allocation-mb
Dieser Wert gibt die maximale Zuordnung für jede Containeranforderung in Resource Manager in MB an. Speicheranforderungen, die den angegebenen Wert übersteigen, werden nicht wirksam. In Resource Manager kann Speicher in Schritten von yarn.scheduler.minimum-allocation-mb zu Containern zugeordnet werden. Dabei darf die durch yarn.scheduler.maximum-allocation-mb angegebene Größe nicht überschritten werden. Der angegebene Wert darf nicht größer sein als der gesamte angegebene Speicher für alle Container im Knoten, der durch yarn.nodemanager.resource.memory-mb angegeben wird.
Für D14 v2-Workerknoten wird der Wert 102400 MB empfohlen.
3. Festlegen der maximalen Anzahl der vcores pro YARN-Containeranforderung
Konfiguration: yarn.scheduler.maximum-allocation-vcores
Dieser Wert gibt die maximale Anzahl der virtuellen CPU-Kerne für jede Containeranforderung in Resource Manager an. Die Anforderung einer höheren Anzahl von vcores als dieser Wert wird nicht wirksam. Dabei handelt es sich um eine globale Eigenschaft des YARN-Schedulers. Für den LLAP-Daemon-Container kann dieser Wert auf 75 % der insgesamt verfügbaren vcores festgelegt werden. Die restlichen 25 % müssen für NodeManager, DataNode und andere in den Workerknoten ausgeführte Dienste reserviert werden.
Bei virtuellen D14 v2-Computern stehen 16 vcores zur Verfügung. 75 % der insgesamt 16 vcores können vom LLAP-Daemon-Container verwendet werden.
Für D14 v2 wird der Wert 12 empfohlen.
4. Anzahl gleichzeitiger Abfragen
Konfiguration: hive.server2.tez.sessions.per.default.queue
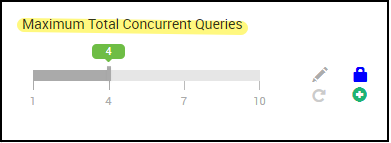
Dieser Konfigurationswert legt die Anzahl der Tez-Sitzungen fest, die parallel gestartet werden können. Diese Tez-Sitzungen werden für die einzelnen Warteschlangen gestartet, die durch „hive.server2.tez.default.queues“ angegeben werden. Dies entspricht der Anzahl der Tez-AMs (Abfragekoordinatoren). Es wird empfohlen, dass diese Anzahl der Anzahl der Workerknoten entspricht. Die Anzahl der Tez-AMs kann die Anzahl der LLAP-Daemon-Knoten übersteigen. Die primäre Zuständigkeit des Tez-AM besteht darin, die Abfrageausführung zu koordinieren und Abfrageplanfragmente den entsprechenden LLAP-Daemons zur Ausführung zuzuweisen. Behalten Sie diesen Wert als Vielfaches der Anzahl von LLAP-Daemonknoten bei, um einen höheren Durchsatz zu erzielen.
Im HDInsight-Standardcluster werden vier LLAP-Daemons in vier Workerknoten ausgeführt, als Wert wird daher 4 empfohlen.
Schieberegler der Ambari-Benutzeroberfläche für Hive-Konfigurationsvariable hive.server2.tez.sessions.per.default.queue:
5. Größe des Tez-Containers und des Tez-Application Master
Konfiguration: tez.am.resource.memory.mb, hive.tez.container.size
tez.am.resource.memory.mb: definiert die Größe des Tez-Application Master.
Es wird der Wert 4096 MB empfohlen.
hive.tez.container.size: definiert die vorgegebene Speichermenge für Tez-Container. Dieser Wert muss zwischen der minimalen YARN-Containergröße (yarn.scheduler.minimum-allocation-mb) und der maximalen YARN-Containergröße (yarn.scheduler.maximum-allocation-mb) festgelegt werden. Die LLAP-Daemon-Executors verwenden diesen Wert, um die Speicherauslastung pro Executor einzuschränken.
Es wird der Wert 4096 MB empfohlen.
6. Kapazitätszuordnung für LLAP-Warteschlange
Konfiguration: yarn.scheduler.capacity.root.llap.capacity
Dieser Wert gibt einen Prozentsatz der für die LLAP-Warteschlange zugewiesenen Kapazität an. Je nach Konfiguration der YARN-Warteschlangen können die Kapazitätszuordnungen unterschiedliche Werte für verschiedene Workloads aufweisen. Wenn es sich bei der Workload um schreibgeschützte Vorgänge handelt, eignet sich eine Einstellung von bis zu 90 % der Kapazität. Wenn die Workload jedoch eine Mischung aus Update-/Lösch-/Zusammenführungsvorgängen unter Verwendung verwalteter Tabellen ist, empfiehlt es sich, 85 % der Kapazität an die LLAP-Warteschlange zuzuweisen. Die verbleibende Kapazität von 15 % kann für andere Aufgaben verwendet werden, z. B. Komprimierung, um Container aus der Standardwarteschlange zuzuordnen. Auf diese Weise gehen den Tasks in der Standardwarteschlange nicht die YARN-Ressourcen aus.
Für D14v2-Workerknoten beträgt der empfohlene Wert für die LLAP-Warteschlange 85.
(Bei schreibgeschützten Workloads kann er je nach Bedarf auf bis zu 90 erhöht werden.)
7. Größe des LLAP-Daemon-Containers
Konfiguration: hive.llap.daemon.yarn.container.mb
Der LLAP-Daemon wird in jedem Workerknoten als YARN-Container ausgeführt. Die Gesamtspeichergröße des LLAP-Daemon-Containers hängt von folgenden Faktoren ab:
- Konfigurationen der YARN-Containergröße (yarn.scheduler.minimum-allocation-mb, yarn.scheduler.maximum-allocation-mb, yarn.nodemanager.resource.memory-mb)
- Anzahl der Tez-AMs in einem Knoten
- Konfigurierter Gesamtspeicher für alle Container in einem Knoten und Kapazität der LLAP-Warteschlange
Der von Tez-Application Masters (Tez-AMs) benötigte Speicher kann wie folgt berechnet werden.
Tez AM fungiert als Abfragekoordinator, und die Anzahl der Tez AM-Instanzen sollte entsprechend der Anzahl der gleichzeitig zu bedienenden Abfragen konfiguriert werden. Theoretisch können wir von einem Tez AM pro Workerknoten ausgehen. Es ist aber möglich, dass Sie mehr als eine Tez AM-Instanz auf einem Workerknoten finden werden. Zum Zweck der Berechnung wird von einer einheitlichen Verteilung von Tez AMs über alle LLAP Daemonknoten/Workerknoten ausgegangen.
Es wird empfohlen, pro Tez-AM 4 GB Speicher bereitzustellen.
Anzahl der Tez AMs = in der Hive-Konfiguration angegebener Wert hive.server2.tez.sessions.per.default.queue.
Anzahl der LLAP-Daemonknoten = angeben durch die env-Variable num_llap_nodes_for_llap_daemons in der Ambari-Benutzeroberfläche.
Tez AM-Containergröße = in der Tez-Konfiguration angegebener Wert tez.am.resource.memory.mb.
Speicher für Tez AM pro Knoten = (ceil (Anzahl der Tez-AMs / Anzahl der LLAP-Daemonknoten) × Tez-AM-Containergröße**)**
Für D14 v2 umfasst die Standardkonfiguration vier Tez-AMs und vier LLAP-Daemon-Knoten.
Speicher für Tez-AM pro Knoten = (ceil(4/4) × 4 GB) = 4 GB
Der verfügbare Gesamtspeicher für die LLAP-Warteschlange pro Workerknoten kann wie folgt berechnet werden:
Dieser Wert hängt von der Gesamtmenge des verfügbaren Arbeitsspeichers für alle YARN-Container in einem Knoten (yarn.nodemanager.resource.memory-mb) und dem Prozentsatz der für die LLAP-Warteschlange konfigurierten Kapazität (yarn.scheduler.capacity.root.llap.capacity) ab.
Arbeitsspeicher insgesamt für die LLAP-Warteschlange im Workerknoten = Verfügbarer Arbeitsspeicher insgesamt für alle YARN-Container in einem Knoten x Prozentsatz der Kapazität für die LLAP-Warteschlange.
Für D14 v2 beträgt dieser Wert (100 GB x 0,85) = 85 GB.
Die Größe des LLAP-Daemon-Containers wird wie folgt berechnet:
LLAP-Daemon-Containergröße = (Arbeitsspeicher gesamt für LLAP-Warteschlange auf einem Workerknoten) – (Tez-AM-Arbeitsspeicher pro Knoten) - (Service Master-Containergröße)
Es gibt nur einen Service Master (Application Master für den LLAP-Dienst) auf dem Cluster, der auf einem der Workerknoten erzeugt wird. Zu Berechnungszwecken gehen wir von einem Service Master pro Workerknoten aus.
Für D14 v2-Workerknoten mit HDI 4.0 wird der Wert (85 GB - 4 GB - 1 GB)) = 80 GB empfohlen.
8. Festlegen der Anzahl der Executors pro LLAP-Daemon
Konfiguration: hive.llap.daemon.num.executors, hive.llap.io.threadpool.size
hive.llap.daemon.num.executors:
Diese Konfiguration steuert die Anzahl der Executors pro LLAP-Daemon, die Tasks parallel ausführen können. Dieser Wert richtet sich nach der Anzahl der virtuellen Kerne, der pro Executor genutzten Speichermenge und der für den LLAP-Daemoncontainer verfügbaren Gesamtspeichermenge. Die Anzahl der Executors kann bis zu 120 % der verfügbaren virtuellen Kerne pro Workerknoten überbucht werden. Sie sollte jedoch angepasst werden, wenn sie die Anforderungen an den Arbeitsspeicher nicht erfüllt, ausgehend vom pro Executor benötigten Arbeitsspeicher und der Größe des LLAP-Containers.
Jeder Executor entspricht einem Tez-Container und kann bis zu 4 GB (Tez-Containergröße) Arbeitsspeicher verbrauchen. Alle Executors im LLAP-Daemon nutzen denselben Heap-Speicher. Ausgehend von der Annahme, dass nicht alle Executors zur gleichen Zeit speicherintensive Vorgänge ausführen, können Sie 75 % der Tez-Containergröße (4 GB) pro Executor veranschlagen. Auf diese Weise können Sie die Anzahl der Executors heraufsetzen und so eine höhere Parallelität erreichen, indem Sie jedem Executor weniger Arbeitsspeicher zuweisen (beispielsweise 3 GB). Es wird jedoch empfohlen, diese Einstellung für Ihre Zielworkload zu optimieren.
Bei virtuellen D14 v2-Computern stehen 16 virtuelle Kerne zur Verfügung. Bei D14v2 lautet der empfohlene Wert für die Anzahl von Executors (16 virtuelle Kerne × 120 %) ~= 19 auf jedem Workerknoten, wenn von 3 GB pro Executor ausgegangen wird.
hive.llap.io.threadpool.size:
Dieser Wert gibt die Threadpoolgröße für Executors an. Da Executors wie angegeben festgelegt sind, entspricht er der Anzahl von Executors pro LLAP-Daemon.
Für D14 v2 wird der Wert 19 empfohlen.
9. Festlegen der LLAP-Daemon-Cachegröße
Konfiguration: hive.llap.io.memory.size
Der Speicher des LLAP-Daemon-Containers besteht aus folgenden Komponenten:
- Toleranzbereich
- Von Executors verwendeter Heapspeicher (Xmx)
- In-Memory-Cache pro Daemon (Größe des Off-Heapspeichers; nicht zutreffend, wenn der SSD-Cache aktiviert ist)
- Metadatengröße des In-Memory-Caches (nur zutreffend, wenn der SSD-Cache aktiviert ist)
Größe des Toleranzbereichs: Diese Größe gibt einen Teil des Off-Heapspeichers an, der für den Java-VM-Overhead (Metaspace, Threadstapel, gc-Datenstrukturen usw.) verwendet wird. Im Allgemeinen beträgt dieser Overhead etwa 6 % der Heapgröße (Xmx). Sicherheitshalber kann der Wert als 6 % der gesamten LLAP-Daemon-Speichergröße berechnet werden.
Für D14 v2 wird ein Wert von ca. 4 GB (ceil(80 GB · 0,06)) empfohlen.
Heapgröße (Xmx): Menge des für alle Executors verfügbaren Heapspeichers.
Gesamte Heapgröße = Anzahl der Executors × 3 GB
Für D14 v2 beträgt dieser Wert 19 × 3 GB = 57 GB.
Ambari environment variable for LLAP heap size:

Wenn der SSD-Cache deaktiviert ist, entspricht der In-Memory-Cache der Speichermenge, die nach Abzug der Größe des Toleranzbereichs und der Heapgröße von der Größe des LLAP-Daemon-Containers verbleibt.
Die Berechnung der Cachegröße unterscheidet sich, wenn der SSD-Cache aktiviert ist.
Durch Festlegen von hive.llap.io.allocator.mmap auf TRUE wird SSD-Caching aktiviert.
Wenn der SSD-Cache aktiviert ist, wird ein Teil des Speichers zum Speichern der Metadaten für den SSD-Cache verwendet. Die Metadaten werden im Speicher gespeichert. Ihre Größe beläuft sich erwartungsgemäß auf ca. 8 % der SSD-Cachegröße.
Größe der In-Memory-Metadaten des SSD-Caches = Größe des LLAP-Daemon-Containers – (Toleranzbereich + Heapgröße)
Für D14 v2 mit HDI 4.0 beträgt die Größe der In-Memory-Metadaten des SSD-Caches 80 GB – (4 GB + 57 GB) = 19 GB.
Angesichts der Größe des verfügbaren Speichers zum Speichern der Metadaten des SSD-Caches kann die unterstützbare Größe des SSD-Caches berechnet werden.
Größe der In-Memory-Metadaten des SSD-Caches = Größe des LLAP-Daemon-Containers – (Toleranzbereich + Heapgröße) = 19 GB
Größe des SSD-Caches = Größe der In-Memory-Metadaten für den SSD-Cache (19 GB) / 0,08 (8 Prozent)
Für D14 v2 und HDI 4.0 werden 19 GB / 0,08 = 237 GB als SSD-Cachegröße empfohlen.
10. Anpassen des Map Join-Speichers
Konfiguration: hive.auto.convert.join.noconditionaltask.size
Achten Sie darauf, dass hive.auto.convert.join.noconditionaltask aktiviert ist, damit dieser Parameter wirksam wird.
Mit dieser Konfiguration wird der Schwellenwert für die MapJoin-Auswahl durch den Hive-Optimierer festgelegt, der die Überbelegung von Arbeitsspeicher durch die anderen Executors berücksichtigt, um mehr Platz für speicherinterne Hash-Tabellen zu haben und mehr MapJoin-Konvertierungen zu ermöglichen. Wenn Sie 3 GB pro Executor zugrunde legen, kann diese Größe bis auf 3 GB überbelegt werden, es kann aber auch ein Teil des Heap-Arbeitsspeichers für Sortierpuffer, Shuffle-Puffer usw. von anderen Vorgängen verwendet werden.
Für D14 v2 mit 3 GB Speicher pro Executor empfiehlt es sich, diesen Wert auf 2048 MB festzulegen.
(Hinweis: Dieser Wert muss möglicherweise entsprechend der Workload angepasst werden. Wenn Sie ihn zu niedrig festlegen, wird die Funktion für die automatische Konvertierung ggf. nicht verwendet. Wenn er zu hoch festgelegt wird, kann dies Ausnahmen wegen unzureichenden Speichers oder GC-Pausen zur Folge haben und so zu Leistungsbeeinträchtigungen führen.)
11. Anzahl von LLAP-Daemons
Ambari-Umgebungsvariablen: num_llap_nodes, num_llap_nodes_for_llap_daemons
num_llap_nodes: gibt die Anzahl der vom Hive-LLAP-Dienst verwendeten Knoten an. Diese schließt Knoten ein, die den LLAP-Daemon, LLAP Service Master und Tez Application Master(Tez AM) ausführen.
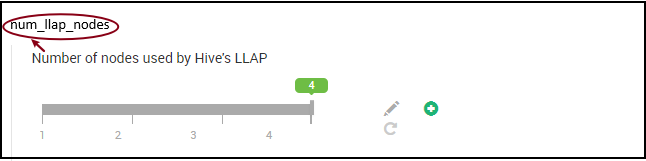
num_llap_nodes_for_llap_daemons: angegebene Anzahl der Knoten, die nur für LLAP-Daemons verwendet werden. Die Containergrößen für den LLAP-Daemon sind auf den maximalen Wert pro Knoten festgelegt, das Ergebnis ist also ein llap-Daemon pro Knoten.

Es wird empfohlen, beide Werte gleich der Anzahl der Workerknoten im Interactive Query-Cluster zu halten.
Überlegungen zur Workloadverwaltung
Wenn Sie die Workloadverwaltung für LLAP aktivieren möchten, sollten Sie sicherstellen, dass Sie ausreichend Kapazität für die Workloadverwaltung reservieren, damit diese erwartungsgemäß funktioniert. Die Workloadverwaltung erfordert die Konfiguration einer benutzerdefinierten YARN-Warteschlange, zusätzlich zur llap-Warteschlange. Achten Sie darauf, die gesamte Ressourcenkapazität des Clusters gemäß Ihren Workloadanforderungen zwischen der llap-Warteschlange und der Warteschlange der Workloadverwaltung aufzuteilen.
Bei der Workloadverwaltung werden Tez Application Master (TEZ AMs) erzeugt, wenn ein Ressourcenplan aktiviert wird.
Hinweis:
- TEZ AMs, die durch Aktivieren eines Ressourcenplans erzeugt werden, beanspruchen Ressourcen aus der Warteschlange zur Workloadverwaltung, wie in
hive.server2.tez.interactive.queueangegeben. - Die Anzahl der Tez AMs hängt dann vom Wert von
QUERY_PARALLELISMab, der im Ressourcenplan angegeben ist. - Sobald die Workloadverwaltung aktiv ist, werden Tez AM-Instanzen in der LLAP-Warteschlange nicht mehr verwendet. Nur TEZ AMs aus der Warteschlange der Workloadverwaltung-werden für die Abfragekoordinierung verwendet. TEZ AMs in der
llap-Warteschlange werden verwendet, wenn die Workloadverwaltung deaktiviert ist.
Beispiel: Cluster-Gesamtkapazität = 100 GB Arbeitsspeicher, wie folgt aufgeteilt auf LLAP, Workloadverwaltung und Standardwarteschlangen:
- Kapazität der LLAP-Warteschlange = 70 GB
- Kapazität der Warteschlange der Workloadverwaltung = 20 GB
- Kapazität der Standardwarteschlange = 10 GB
Bei einer Kapazität der Warteschlange der Workloadverwaltung von 20 GB kann ein Ressourcenplan den Wert für QUERY_PARALLELISM mit fünf angeben, was bedeutet, dass die Workloadverwaltung fünf Tez-AMs mit einer Containergröße von jeweils 4 GB starten kann. Wenn QUERY_PARALLELISM höher als die Kapazität ist, kann es vorkommen, dass einige Tez AMs im Status ACCEPTED nicht mehr reagieren. Der Hive-Server 2 Interactive kann keine Abfragefragmente an die Tez-AMs senden, die sich nicht im Status RUNNING befinden.
Nächste Schritte
Wenn sich das Problem durch Festlegen dieser Werte nicht beheben lässt, haben Sie folgende Möglichkeiten:
Nutzen Sie den Azure-Communitysupport, um Antworten von Azure-Experten zu erhalten.
Mit @AzureSupport verbinden – das offizielle Microsoft Azure-Konto für die Verbesserung der Kundenzufriedenheit durch Verbinden der Azure-Community mit den richtigen Ressourcen: Antworten, Support und Experten.
Sollten Sie weitere Unterstützung benötigen, senden Sie eine Supportanfrage über das Azure-Portal. Wählen Sie dazu auf der Menüleiste die Option Support aus, oder öffnen Sie den Hub Hilfe und Support. Ausführlichere Informationen hierzu finden Sie unter Erstellen einer Azure-Supportanfrage. Zugang zu Abonnementverwaltung und Abrechnungssupport ist in Ihrem Microsoft Azure-Abonnement enthalten. Technischer Support wird über einen Azure-Supportplan bereitgestellt.
Andere Referenzen:
- Configure other LLAP properties (Konfigurieren anderer LLAP-Eigenschaften)
- Configure the HiveServer heap size (Konfigurieren der HiveServer-Heapgröße)
- Map Join Memory Sizing for LLAP (Map Join-Speicheranpassung für LLAP)
- Tez Execution Engine Properties (Eigenschaften der Tez-Ausführungs-Engine)
- Hive LLAP deep dive (Tieferer Einblick in Hive LLAP)