Was ist Apache Kafka in Azure HDInsight?
Apache Kafka ist eine verteilte Open Source-Streamingplattform, die zum Erstellen von Datenpipelines und Anwendungen mit Echtzeitstreaming verwendet werden kann. Kafka verfügt auch über Nachrichtenbrokerfunktionen, die einer Nachrichtenwarteschlange ähneln, über die Sie benannte Datenströme veröffentlichen und diese abonnieren können.
Dies sind spezifische Merkmale von Kafka in HDInsight:
Es ist ein verwalteter Dienst, der einen vereinfachten Konfigurationsprozess bietet. Das Ergebnis ist eine von Microsoft getestete und unterstützte Konfiguration.
Microsoft bietet eine 99,9%ige Vereinbarung zum Servicelevel (Service Level Agreement, SLA) für die Kafka-Betriebszeit. Weitere Informationen finden Sie im Dokument SLA für HDInsight.
Azure Managed Disks werden als Sicherungsspeicher für Kafka verwendet. Managed Disks können bis zu 16 TB Speicher pro Kafka-Broker bieten. Informationen zum Konfigurieren von verwalteten Datenträgern mit Kafka in HDInsight finden Sie unter Konfigurieren von Speicher und Skalierbarkeit für Apache Kafka in HDInsight.
Weitere Informationen zu verwalteten Datenträgern finden Sie unter Azure Managed Disks.
Kafka wurde mit einer einzelnen dimensionalen Ansicht eines Racks entworfen. Azure trennt ein Rack in zwei Dimensionen – Updatedomänen (UD) und Fehlerdomänen (FD). Microsoft stellt Tools bereit, die Kafka-Partitionen und -Replikate UDs und FDs übergreifend ausgleichen.
Weitere Informationen finden Sie unter Hochverfügbarkeit Ihrer Daten mit Apache Kafka in HDInsight.
Mit HDInsight können Sie die Anzahl von Workerknoten (zum Hosten des Kafka-Brokers) nach der Clustererstellung ändern. Die Hochskalierung kann über das Azure-Portal, Azure PowerShell und andere Azure-Verwaltungsoberflächen durchgeführt werden. Für Kafka sollten Sie für Partitionsreplikate nach Skalierungsvorgängen einen Ausgleichsvorgang durchführen. Durch das Ausgleichen von Partitionen kann für Kafka die neue Anzahl von Workerknoten genutzt werden.
HDInsight Kafka unterstützt kein Herunterskalieren oder Verringern der Anzahl der Broker innerhalb eines Clusters. Wenn versucht wird, die Anzahl der Knoten zu verringern, wird der Fehler
InvalidKafkaScaleDownRequestErrorCodezurückgegeben.Weitere Informationen finden Sie unter Hochverfügbarkeit Ihrer Daten mit Apache Kafka in HDInsight.
Zur Überwachung von Kafka in HDInsight können Azure Monitor-Protokolle verwendet werden. Azure Monitor-Protokolle enthalten Informationen auf VM-Ebene. Hierzu zählen beispielsweise Datenträger- und NIC-Metriken sowie JMX-Metriken aus Kafka.
Weitere Informationen finden Sie unter Analysieren von Protokollen für Apache Kafka in HDInsight.
Architektur von Apache Kafka in HDInsight
Das folgende Diagramm zeigt eine typische Kafka-Konfiguration, für die Consumergruppen, Partitionierung und Replikation verwendet werden, um eine parallele Ablesung von Ereignissen mit Fehlertoleranz zu ermöglichen:
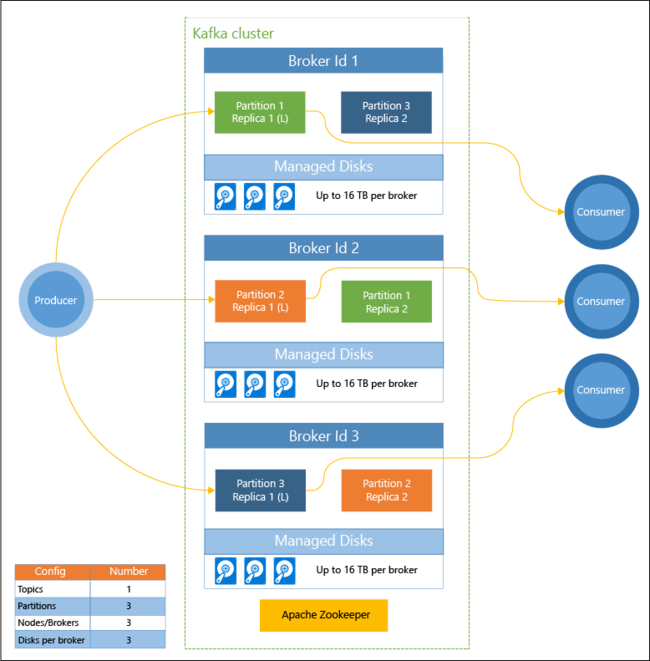
Apache ZooKeeper verwaltet den Zustand des Kafka-Clusters. ZooKeeper ist für gleichzeitige, robuste Transaktionen mit geringer Latenz konzipiert.
Kafka speichert Datensätze (Daten) in Themen. Datensätze werden von Producern erstellt und von Consumern genutzt. Producer senden Datensätze an Kafka-Broker. Jeder Workerknoten in Ihrem HDInsight-Cluster ist ein Kafka-Broker.
Themen partitionieren Datensätze Broker übergreifend. Bei der Nutzung von Datensätzen können Sie bis zu einen Consumer pro Partition einsetzen, um parallele Verarbeitung der Daten zu erzielen.
Die Replikation wird genutzt, um die Partitionen auf Knoten zu duplizieren und für den Schutz vor Ausfällen von Knoten (Brokern) zu sorgen. Eine Partition, die im Diagramm mit einem (L) gekennzeichnet ist, ist jeweils die führende Partition. Producer-Datenverkehr wird an die führende Komponente jedes Knotens weitergeleitet, indem der von ZooKeeper verwaltete Zustand verwendet wird.
Gründe für Apache Kafka in HDInsight
Im Folgenden sind allgemeine Aufgaben und Muster aufgelistet, die mithilfe von Kafka in HDInsight ausgeführt werden können:
| Verwendung | Beschreibung |
|---|---|
| Replikation von Apache Kafka-Daten | Kafka verfügt über das MirrorMaker-Hilfsprogramm, mit dem Daten zwischen Kafka-Clustern repliziert werden. Informationen zur Verwendung von MirrorMaker finden Sie unter Verwenden von MirrorMaker zum Replizieren von Apache Kafka-Themen mit Kafka in HDInsight. |
| Veröffentlichen-Abonnieren-Messagingmuster | Kafka umfasst eine Producer-API zum Veröffentlichen von Datensätzen in einem Kafka-Thema. Die Consumer-API wird verwendet, wenn Sie ein Thema abonnieren. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines Apache Kafka-Clusters in HDInsight. |
| Datenstromverarbeitung | Kafka wird häufig zusammen mit Spark für die Datenstromverarbeitung in Echtzeit eingesetzt. Kafka 2.1.1 und 2.4.1 (HDInsight-Version 4.0 und 5.0) unterstützen eine Streaming-API, mit der Sie Streaminglösungen erstellen können, für die Spark nicht erforderlich ist. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines Apache Kafka-Clusters in HDInsight. |
| Horizontale Skalierung | Bei Kafka werden Streams über die Knoten im HDInsight-Cluster hinweg partitioniert. Consumerprozesse können einzelnen Partitionen zugeordnet werden, um beim Nutzen von Datensätzen für einen Lastenausgleich zu sorgen. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines Apache Kafka-Clusters in HDInsight. |
| Geordnete Bereitstellung | In jeder Partition werden die Datensätze im Stream in der Reihenfolge gespeichert, in der sie empfangen wurden. Indem ein Consumerprozess pro Partition zugeordnet wird, können Sie sicherstellen, dass die Datensätze in der richtigen Reihenfolge verarbeitet werden. Weitere Informationen finden Sie unter Schnellstart: Erstellen eines Apache Kafka-Clusters in HDInsight. |
| Nachrichten | Da das Veröffentlichen-Abonnieren-Messagingmuster unterstützt wird, wird Kafka häufig als Nachrichtenbroker genutzt. |
| Aktivitätsnachverfolgung | Da Kafka die geordnete Protokollierung von Datensätzen unterstützt, kann die Anwendung zum Nachverfolgen und Neuerstellen von Aktivitäten verwendet werden. Beispiele hierfür sind Benutzeraktionen auf einer Website oder in einer Anwendung. |
| Aggregation | Mit der Datenstromverarbeitung können Sie Informationen aus unterschiedlichen Datenströmen aggregieren, um die Informationen zu operativen Daten zu kombinieren und zu zentralisieren. |
| Transformation | Mit der Datenstromverarbeitung können Sie Daten aus mehreren Eingabethemen zu einem oder mehreren Ausgabethemen kombinieren und erweitern. |
Nächste Schritte
Verwenden Sie die folgenden Links, um Informationen zur Verwendung von Apache Kafka unter HDInsight zu erhalten: