Schnellstart: Erstellen eines Apache Kafka-Clusters in Azure HDInsight im Azure-Portal
Apache Kafka ist eine verteilte Open Source-Streamingplattform. Sie wird häufig als Nachrichtenbroker eingesetzt, da sie eine ähnliche Funktionalität wie eine Veröffentlichen-Abonnieren-Nachrichtenwarteschlange aufweist.
In dieser Schnellstartanleitung lernen Sie, wie Sie mithilfe des Azure-Portals einen Apache Kafka-Cluster erstellen. Außerdem erfahren Sie, wie Sie mithilfe von enthaltenen Hilfsprogrammen Nachrichten mit Apache Kafka senden und empfangen. Eine ausführliche Beschreibung der verfügbaren Konfigurationen finden Sie unter Einrichten von Clustern in HDInsight. Weitere Informationen zur Nutzung des Portals zum Erstellen von Clustern finden Sie unter Erstellen von Clustern im Portal.
Warnung
Die Abrechnung für die HDInsight-Cluster erfolgt anteilsmäßig auf Minutenbasis und ist unabhängig von der Verwendung. Daher sollten Sie Ihren Cluster nach der Verwendung unbedingt wieder löschen. Sehen Sie sich die Informationen zum Löschen eines HDInsight-Clusters an.
Auf die Apache Kafka-API kann nur von Ressourcen im gleichen virtuellen Netzwerk zugegriffen werden. In dieser Schnellstartanleitung greifen Sie über SSH direkt auf den Cluster zu. Wenn Sie eine Verbindung zwischen anderen Diensten, Netzwerken und virtuellen Computern und Apache Kafka herstellen möchten, müssen Sie zunächst ein virtuelles Netzwerk und anschließend die Ressourcen in diesem Netzwerk erstellen. Weitere Informationen finden Sie im Dokument Herstellen einer Verbindung mit Apache Kafka in HDInsight über ein virtuelles Azure-Netzwerk. Allgemeine Informationen zum Planen von virtuellen Netzwerken für HDInsight finden Sie unter Planen eines virtuellen Netzwerks für Azure HDInsight.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Einen SSH-Client. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit HDInsight (Hadoop) per SSH.
Erstellen eines Apache Kafka-Clusters
Gehen Sie wie folgt vor, um einen Apache Kafka-Cluster in HDInsight zu erstellen:
Melden Sie sich beim Azure-Portal an.
Klicken Sie im oberen Menü auf + Ressource erstellen.
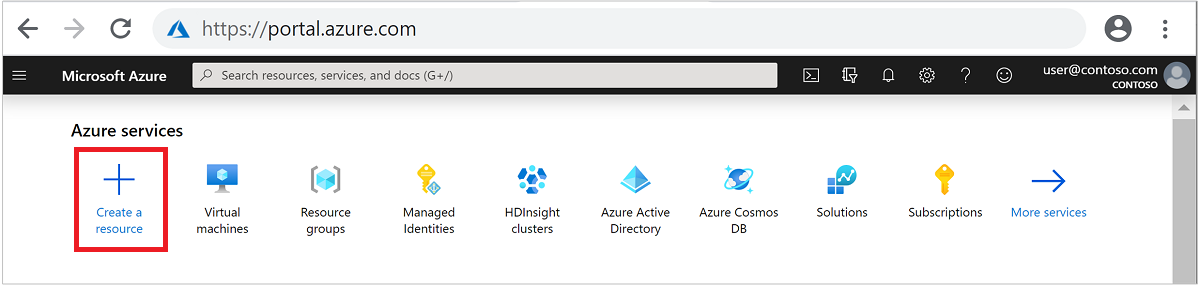
Wählen Sie Analytics>Azure HDInsight aus, um die Seite HDInsight-Cluster erstellen zu öffnen.
Geben Sie auf der Registerkarte Grundlagen die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Subscription Wählen Sie in der Dropdownliste das Azure-Abonnement aus, das für den Cluster verwendet wird. Resource group Erstellen Sie eine Ressourcengruppe, oder wählen Sie eine vorhandene Ressourcengruppe aus. Bei einer Ressourcengruppe handelt es sich um einen Container mit Azure-Komponenten. In diesem Fall enthält die Ressourcengruppe den HDInsight-Cluster und das abhängige Azure Storage-Konto. Clustername Geben Sie einen global eindeutigen Namen ein. Der Name kann aus bis zu 59 Zeichen mit Buchstaben, Zahlen und Bindestrichen bestehen. Das erste und das letzte Zeichen des Namens dürfen keine Bindestriche sein. Region Wählen Sie in der Dropdownliste eine Region für die Erstellung des Clusters aus. Je weniger weit entfernt die Region ist, desto besser ist die Leistung. Clustertyp Wählen Sie Clustertyp auswählen aus, um eine Liste zu öffnen. Wählen Sie in der Liste Kafka als Clustertyp aus. Version Die Standardversion für den Clustertyp wird angegeben. Wenn Sie eine andere Version angeben möchten, wählen Sie diese in der Dropdownliste aus. Anmeldebenutzernamen und Kennwort für den Cluster Der Standardanmeldename lautet admin. Das Kennwort muss mindestens zehn Zeichen lang sein und mindestens eine Ziffer, einen Groß- und einen Kleinbuchstaben sowie ein nicht alphanumerisches Zeichen enthalten (mit Ausnahme folgender Zeichen:' ` "). Stellen Sie sicher, dass Sie keine häufig verwendeten Kennwörter wiePass@word1angeben.SSH-Benutzername (Secure Shell) Der Standardbenutzername lautet sshuser. Sie können einen anderen SSH-Benutzernamen angeben.Verwenden Sie ein Clusteranmeldekennwort für SSH Aktivieren Sie dieses Kontrollkästchen, um das gleiche Kennwort für den SSH-Benutzer zu verwenden, das Sie für den Clusteranmeldebenutzer angegeben haben. 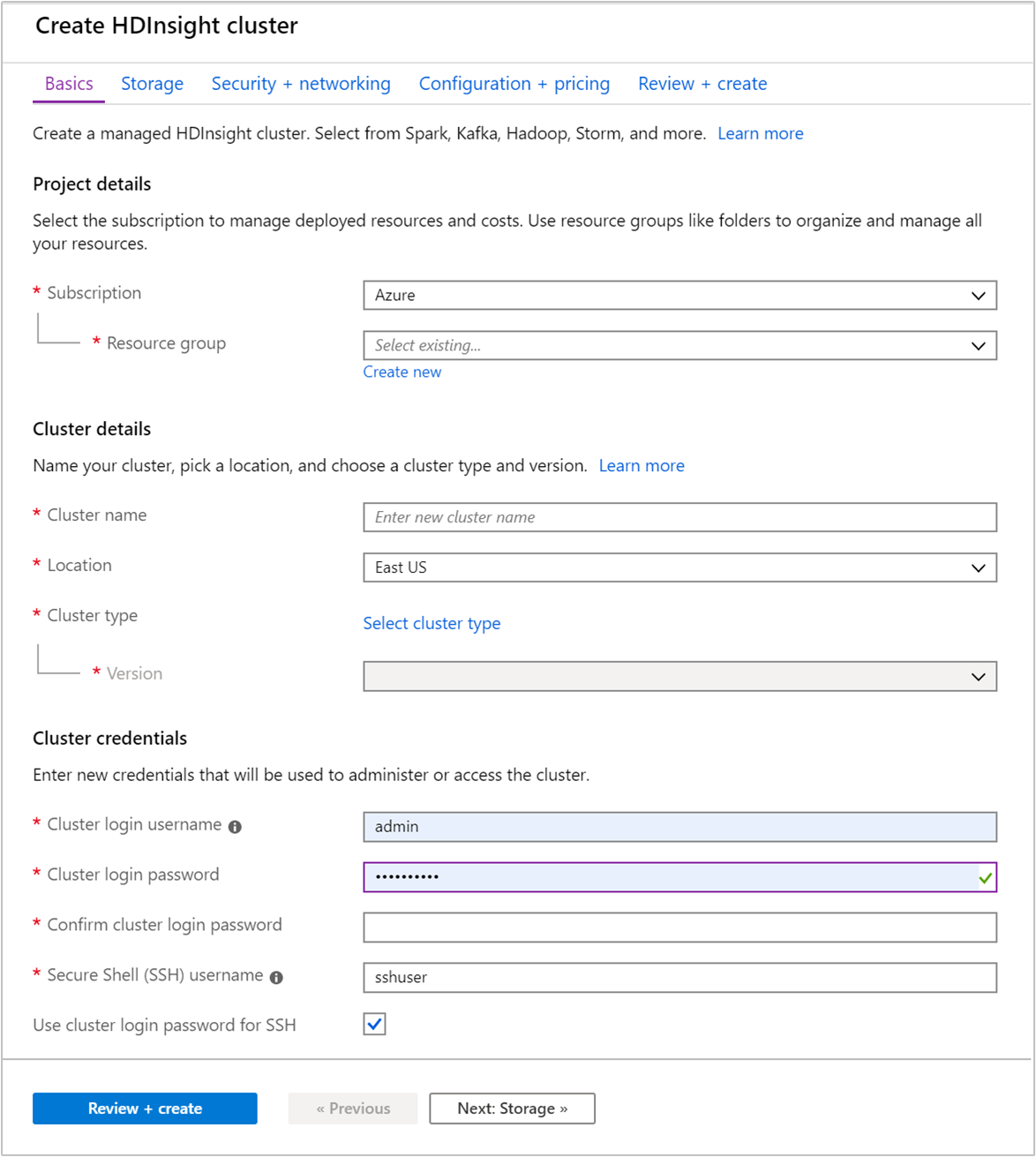
Jede Azure-Region (Standort) verfügt über Fehlerdomänen. Eine Fehlerdomäne ist eine logische Gruppierung von zugrundeliegender Hardware in einem Azure-Rechenzentrum. Jede Fehlerdomäne verwendet eine Stromquelle und einen Netzwerkswitch gemeinsam. Die virtuellen Computer und verwalteten Datenträger, die die Knoten innerhalb eines HDInsight-Clusters implementieren, werden auf diese Fehlerdomänen verteilt. Diese Architektur schränkt die potenziellen Auswirkungen physischer Hardwarefehler ein.
Für Hochverfügbarkeit von Daten wählen Sie eine Region (Speicherort) mit drei Fehlerdomänen. Informationen zur Anzahl von Fehlerdomänen in einer Region finden Sie im Dokument Verwalten der Verfügbarkeit virtueller Linux-Computer.
Wählen Sie die Registerkarte Next: Storage >> (Weiter: Speicher) aus, um zu den Speichereinstellungen fortzufahren.
Geben Sie auf der Registerkarte Speicher die folgenden Werte ein:
Eigenschaft BESCHREIBUNG Primärer Speichertyp Übernehmen Sie den Standardwert Azure Storage. Auswahlmethode Übernehmen Sie den Standardwert Aus Liste auswählen. Primäres Speicherkonto Wählen Sie in der Dropdownliste ein vorhandenes Speicherkonto aus, oder wählen Sie Neu erstellen aus. Wenn Sie ein neues Konto erstellen, muss der Name zwischen 3 und 24 Zeichen lang sein und darf nur Zahlen und Kleinbuchstaben enthalten. Container Verwenden Sie den automatisch ausgefüllten Wert. 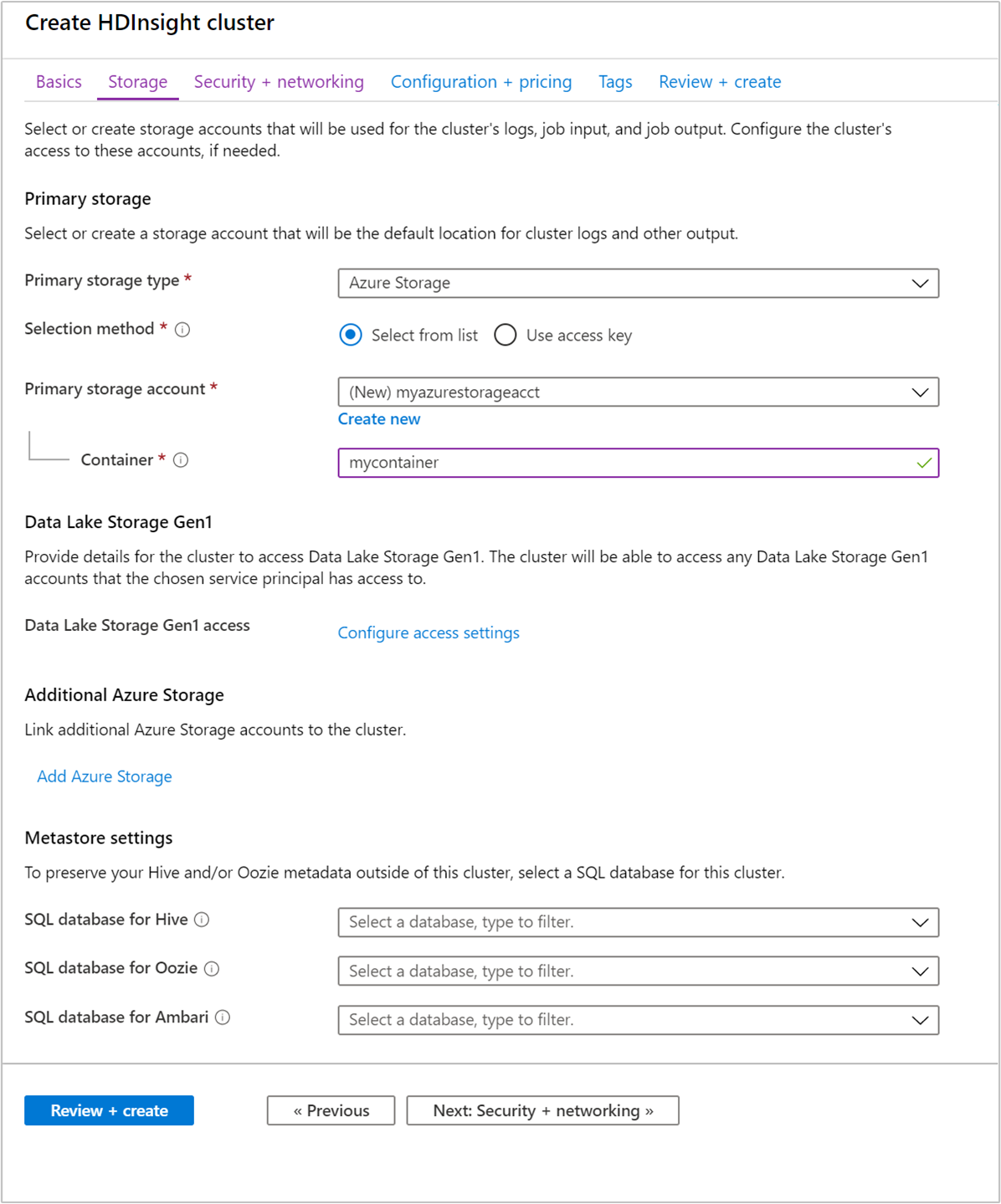
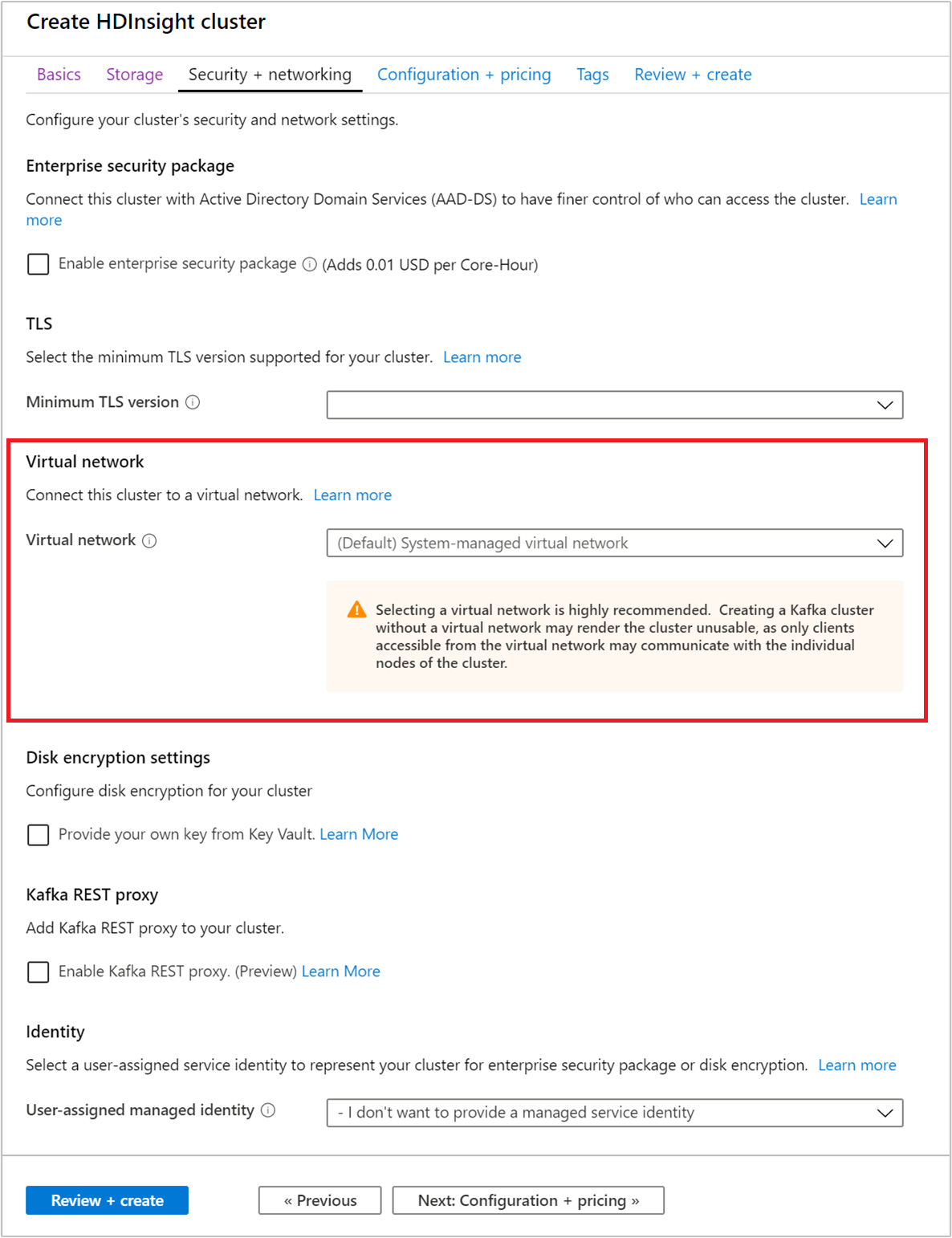
Wählen Sie die Registerkarte Sicherheit + Netzwerkbetrieb aus.
Übernehmen Sie im Rahmen dieser Schnellstartanleitung die Standardsicherheitseinstellungen. Weitere Informationen zum Enterprise-Sicherheitspaket finden Sie unter Konfigurieren eines HDInsight-Clusters mit Enterprise-Sicherheitspaket (Enterprise Security Package, ESP) mithilfe von Microsoft Entra Domain Services. Wenn Sie Ihren eigenen Schlüssel für die Apache Kafka-Datenträgerverschlüsselung verwenden möchten, lesen Sie Datenträgerverschlüsselung mit kundenseitig verwalteten Schlüsseln.
Wenn Sie Ihren Cluster mit einem virtuellen Netzwerk verbinden möchten, wählen Sie ein virtuelles Netzwerk aus der Dropdownliste Virtuelles Netzwerk aus.
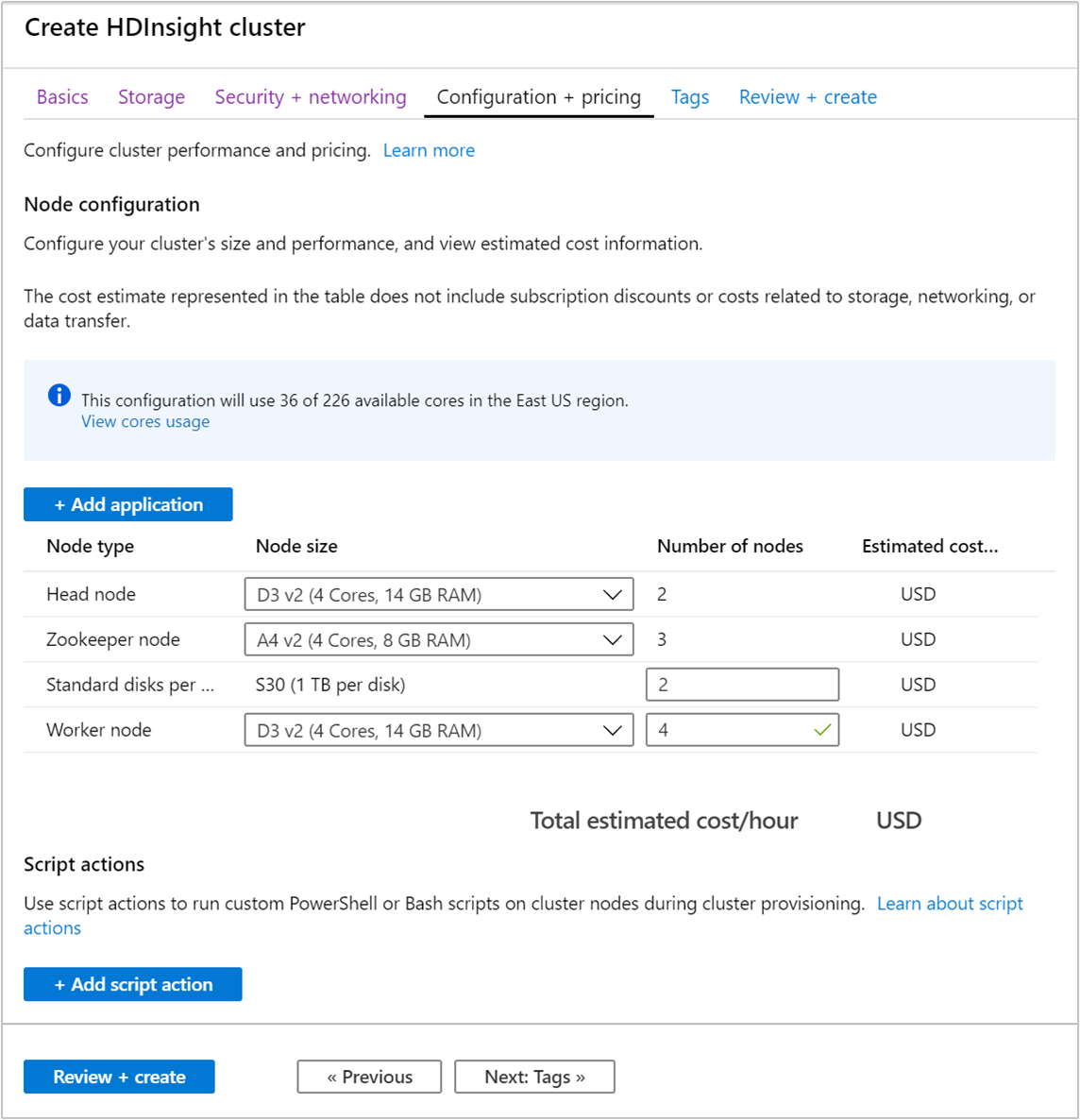
Wählen Sie die Registerkarte Konfiguration + Preise aus.
Um die Verfügbarkeit von Apache Kafka in HDInsight zu gewährleisten, muss der Eintrag Knotenanzahl für Workerknoten mindestens auf 3 festgelegt werden. Der Standardwert ist 4.
Der Eintrag für Standard-Datenträger pro Workerknoten konfiguriert die Skalierbarkeit von Apache Kafka in HDInsight. Apache Kafka in HDInsight verwendet den lokalen Datenträger der virtuellen Computer im Cluster, um Daten zu speichern. Da Apache Kafka sehr E/A-intensiv ist, wird Azure Managed Disks verwendet, um einen hohen Durchsatz zu ermöglichen und mehr Speicher pro Knoten bereitzustellen. Der Typ des verwalteten Datenträgers kann entweder Standard (HDD) oder Premium (SSD) sein. Die Art des Datenträgers hängt von der VM-Größe ab, die von den Workerknoten (Apache Kafka-Broker) verwendet wird. Premium-Datenträger werden automatisch mit virtuellen Computern der DS- und GS-Serie verwendet. Alle anderen virtuellen Computertypen verwenden den Standardtyp.
Wählen Sie die Registerkarte Überprüfen + erstellen aus.
Überprüfen Sie die Konfiguration für den Cluster. Ändern Sie ggf. falsche Einstellungen. Wählen Sie zum Schluss Erstellen aus, um den Cluster zu erstellen.
Das Erstellen des Clusters kann bis zu 20 Minuten dauern.
Herstellen einer Verbindung mit dem Cluster
Verwenden Sie einen ssh-Befehl zum Herstellen der Verbindung mit dem Cluster. Bearbeiten Sie den folgenden Befehl, indem Sie CLUSTERNAME durch den Namen Ihres Clusters ersetzen, und geben Sie den Befehl dann ein:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netGeben Sie nach Aufforderung das Kennwort für den SSH-Benutzer ein.
Nach der Verbindungsherstellung sehen die angezeigten Informationen in etwa wie folgt aus:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Beschaffen der Apache Zookeeper- und Broker-Hostinformationen
Bei der Verwendung von Kafka müssen Ihnen die Apache Zookeeper- und die Broker-Hosts bekannt sein. Diese Hosts werden zusammen mit der Apache Kafka-API und vielen Hilfsprogrammen verwendet, die in Kafka enthalten sind.
In diesem Abschnitt rufen Sie die Hostinformationen aus der Apache Ambari-REST-API im Cluster ab.
Installieren Sie den JSON-Befehlszeilenprozessor jq. Dieses Hilfsprogramm wird verwendet, um JSON-Dokumente zu analysieren, und es ist beim Analysieren der Hostinformationen hilfreich. Geben Sie über die geöffnete SSH-Verbindung den folgenden Befehl ein, um
jqzu installieren:sudo apt -y install jqRichten Sie eine Kennwortvariable ein. Ersetzen Sie
PASSWORDdurch das Kennwort für die Clusteranmeldung, und geben Sie dann den folgenden Befehl ein:export PASSWORD='PASSWORD'Extrahieren Sie den Clusternamen mit korrekter Groß-/Kleinschreibung. Die tatsächliche Schreibweise des Clusternamens kann je nach Clustererstellung anders sein als erwartet. Mit diesem Befehl wird die tatsächliche Schreibweise abgerufen und in einer Variable gespeichert. Geben Sie den folgenden Befehl ein:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Hinweis
Falls Sie diesen Vorgang außerhalb des Clusters ausführen, gilt für das Speichern des Clusternamens eine andere Vorgehensweise. Rufen Sie den Clusternamen in Kleinbuchstaben aus dem Azure-Portal ab. Ersetzen Sie dann im folgenden Befehl den Clusternamen durch
<clustername>, und führen Sie den Befehl aus:export clusterName='<clustername>'.Verwenden Sie den folgenden Befehl, um eine Umgebungsvariable mit Zookeeper-Hostinformationen festzulegen. Dieser Befehl ruft alle Zookeeper-Hosts ab und gibt dann nur die ersten beiden Einträge zurück. Diese Redundanz ist hilfreich, wenn ein Host nicht erreichbar ist.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Hinweis
Für diesen Befehl ist Zugriff auf Ambari erforderlich. Wird Ihr Cluster durch eine NSG geschützt, führen Sie diesen Befehl auf einem Computer aus, über den auf Ambari zugegriffen werden kann.
Vergewissern Sie sich mithilfe des folgenden Befehls, dass die Umgebungsvariable korrekt festgelegt ist:
echo $KAFKAZKHOSTSDie Ausgabe dieses Befehls sieht in etwa wie folgt aus:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Verwenden Sie den folgenden Befehl, um eine Umgebungsvariable mit Apache Kafka-Brokerhostinformationen festzulegen:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Hinweis
Für diesen Befehl ist Zugriff auf Ambari erforderlich. Wird Ihr Cluster durch eine NSG geschützt, führen Sie diesen Befehl auf einem Computer aus, über den auf Ambari zugegriffen werden kann.
Vergewissern Sie sich mithilfe des folgenden Befehls, dass die Umgebungsvariable korrekt festgelegt ist:
echo $KAFKABROKERSDie Ausgabe dieses Befehls sieht in etwa wie folgt aus:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Verwalten von Apache Kafka-Themen
Kafka speichert Datenströme in Themen. Mit dem Hilfsprogramm kafka-topics.sh können Sie Themen verwalten.
Führen Sie folgenden Befehl in der SSH-Verbindung aus, um ein Thema zu erstellen:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --zookeeper $KAFKAZKHOSTSMit diesem Befehl wird unter Verwendung der in
$KAFKAZKHOSTSgespeicherten Informationen eine Verbindung mit Zookeeper hergestellt. Anschließend wird ein Apache Kafka-Thema mit dem Namen test erstellt.In diesem Thema gespeicherte Daten werden auf acht Partitionen aufgeteilt.
Jede Partition wird auf drei Workerknoten im Cluster repliziert.
Wenn Sie den Cluster in einer Azure-Region mit drei Fehlerdomänen erstellt haben, verwenden Sie den Replikationsfaktor 3. Verwenden Sie andernfalls den Replikationsfaktor 4.
In Regionen mit drei Fehlerdomänen ermöglicht der Replikationsfaktor 3 die Verteilung von Replikaten auf die Fehlerdomänen. In Regionen mit zwei Fehlerdomänen ermöglicht der Replikationsfaktor 4 die gleichmäßige Verteilung von Replikaten auf die Domänen.
Informationen zur Anzahl von Fehlerdomänen in einer Region finden Sie im Dokument Verwalten der Verfügbarkeit virtueller Linux-Computer.
Azure-Fehlerdomänen sind Apache Kafka nicht bekannt. Beim Erstellen von Partitionsreplikaten für Themen kann es daher vorkommen, dass die Replikate nicht ordnungsgemäß für Hochverfügbarkeit verteilt werden.
Verwenden Sie das Tool zum Ausgleichen von Apache Kafka-Partitionen, um Hochverfügbarkeit zu gewährleisten. Dieses Tool muss über eine SSH-Verbindung mit dem Hauptknoten des Apache Kafka-Clusters ausgeführt werden.
Um eine möglichst hohe Verfügbarkeit Ihrer Apache Kafka-Daten zu erreichen, sollten Sie in folgenden Fällen die Partitionsreplikate für Ihr Thema ausgleichen:
Wenn ein neues Thema oder eine neue Partition erstellt wird
Wenn Sie einen Cluster hochskalieren
Verwenden Sie den folgenden Befehl, um Themen aufzulisten:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $KAFKAZKHOSTSDieser Befehl listet die für den Apache Kafka-Cluster verfügbaren Themen auf.
Verwenden Sie zum Löschen eines Themas den folgenden Befehl:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --zookeeper $KAFKAZKHOSTSDieser Befehl löscht das Thema
topicname.Warnung
Wenn Sie das zuvor erstellte Thema
testlöschen, müssen Sie es neu erstellen. Es wird weiter unten in diesem Dokument verwendet.
Wenn Sie weitere Informationen zu den mit dem Hilfsprogramm kafka-topics.sh verfügbaren Befehlen anzeigen möchten, verwenden Sie den folgenden Befehl:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Erstellen und Nutzen von Datensätzen
Bei Kafka werden Datensätze in Themen gespeichert. Datensätze werden von Producern erstellt und von Consumern genutzt. Producer und Consumer kommunizieren mit dem Kafka-Brokerdienst. Jeder Workerknoten in Ihrem HDInsight-Cluster ist ein Apache Kafka-Brokerhost.
Gehen Sie wie folgt vor, um Datensätze im zuvor erstellten Testthema zu speichern und sie anschließend mithilfe eines Consumers zu lesen:
Verwenden Sie zum Schreiben von Datensätzen in das Thema das Hilfsprogramm
kafka-console-producer.shüber die SSH-Verbindung:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testNach diesem Befehl erreichen Sie eine leere Zeile.
Geben Sie eine Textnachricht in die leere Zeile ein, und drücken Sie die EINGABETASTE. Geben Sie auf diese Weise mehrere Nachrichten ein, und drücken Sie anschließend STRG+C, um zur normalen Eingabeaufforderung zurückzukehren. Die einzelnen Zeilen werden jeweils als separater Datensatz an das Apache Kafka-Thema gesendet.
Verwenden Sie zum Lesen von Datensätzen aus dem Thema das Hilfsprogramm
kafka-console-consumer.shüber die SSH-Verbindung:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningDie Datensätze werden mit dem Befehl aus dem Thema abgerufen und angezeigt. Mit
--from-beginningwird der Consumer angewiesen, am Anfang des Datenstroms zu beginnen, damit alle Datensätze abgerufen werden.Falls Sie eine ältere Version von Kafka verwenden, ersetzen Sie
--bootstrap-server $KAFKABROKERSdurch--zookeeper $KAFKAZKHOSTS.Drücken Sie STRG+C, um den Consumer zu beenden.
Sie können Producer und Consumer auch programmgesteuert erstellen. Ein Beispiel für die Verwendung dieser API finden Sie im Dokument Tutorial: Verwenden der Apache Kafka Producer- und Consumer-APIs.
Bereinigen von Ressourcen
Um die Ressourcen zu bereinigen, die im Rahmen dieser Schnellstartanleitung erstellt wurden, können Sie die Ressourcengruppe löschen. Dadurch werden auch der zugeordnete HDInsight-Cluster sowie alle anderen Ressourcen gelöscht, die der Ressourcengruppe zugeordnet sind.
So entfernen Sie die Ressourcengruppe über das Azure-Portal:
- Erweitern Sie im Azure-Portal das Menü auf der linken Seite, um das Menü mit den Diensten zu öffnen, und klicken Sie auf Ressourcengruppen, um die Liste mit Ihren Ressourcengruppen anzuzeigen.
- Suchen Sie die zu löschende Ressourcengruppe, und klicken Sie mit der rechten Maustaste rechts neben dem Eintrag auf die Schaltfläche Mehr (...).
- Klicken Sie auf Ressourcengruppe löschen, und bestätigen Sie den Vorgang.
Warnung
Wenn Sie einen Apache Kafka-Cluster in HDInsight löschen, werden auch alle in Kafka gespeicherten Daten gelöscht.