Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In dieser Schnellstartanleitung verwenden Sie das Azure-Portal, um einen Apache Spark-Cluster in Azure HDInsight zu erstellen. Anschließend erstellen Sie ein Jupyter-Notizbuch und verwenden es zum Ausführen von Spark SQL-Abfragen für Apache Hive-Tabellen. Azure HDInsight ist ein verwalteter, vollständiger, open-source-Analysedienst für Unternehmen. Das Apache Spark-Framework für HDInsight ermöglicht schnelle Datenanalysen und Clustercomputing mit In-Memory-Verarbeitung. Mit Jupyter-Notizbuch können Sie mit Ihren Daten interagieren, Code mit Markdowntext kombinieren und einfache Visualisierungen ausführen.
Ausführliche Erläuterungen der verfügbaren Konfigurationen finden Sie unter Einrichten von Clustern in HDInsight. Weitere Informationen zur Verwendung des Portals zum Erstellen von Clustern finden Sie unter Erstellen von Clustern im Portal.
Wenn Sie mehrere Cluster zusammen verwenden, können Sie ein virtuelles Netzwerk erstellen. Wenn Sie einen Spark-Cluster verwenden, möchten Sie möglicherweise auch den Hive Warehouse Connector verwenden. Weitere Informationen finden Sie unter Planen eines virtuellen Netzwerks für Azure HDInsight sowie unter Integrieren von Apache Spark und Apache Hive per Hive Warehouse Connector.
Von Bedeutung
Unabhängig davon, ob Sie HDInsight-Cluster verwenden oder nicht, erfolgt die Abrechnung auf Minutenbasis anteilig. Stellen Sie sicher, dass Sie Den Cluster löschen, nachdem Sie ihn verwendet haben. Weitere Informationen finden Sie im Abschnitt "Ressourcen bereinigen " in diesem Artikel.
Voraussetzungen
Ein Azure-Konto mit einem aktiven Abonnement. Kostenlos ein Konto erstellen.
Erstellen eines Apache Spark-Clusters in HDInsight
Sie verwenden das Azure-Portal, um einen HDInsight-Cluster zu erstellen, der Azure Storage Blobs als Clusterspeicher verwendet. Weitere Informationen zur Verwendung von Data Lake Storage Gen2 finden Sie in der Schnellstartanleitung: Einrichten von Clustern in HDInsight.
Melden Sie sich beim Azure-Portal an.
Klicken Sie im oberen Menü auf + Ressource erstellen.
Wählen Sie>Azure HDInsight aus, um zur Seite "HDInsight-Cluster erstellen" zu wechseln.
Geben Sie auf der Registerkarte " Grundlagen " die folgenden Informationen an:
Eigentum Description Subscription Wählen Sie in der Dropdownliste das Azure-Abonnement aus, das für den Cluster verwendet wird. Ressourcengruppe Wählen Sie in der Dropdownliste Ihre vorhandene Ressourcengruppe oder die Option Neu erstellen aus. Clustername Geben Sie einen global eindeutigen Namen ein. Region Wählen Sie in der Dropdownliste eine Region aus, in der der Cluster erstellt wird. Verfügbarkeitszone Optional – Angeben einer Verfügbarkeitszone, in der Ihr Cluster bereitgestellt werden soll Clustertyp Wählen Sie den Clustertyp aus, um eine Liste zu öffnen. Wählen Sie in der Liste "Spark" aus. Clusterversion Nach Auswahl des Clustertyps wird dieses Feld automatisch mit der Standardversion gefüllt. Clusteranmeldungs-Benutzername Geben Sie den Benutzernamen für die Clusteranmeldung ein. Der Standardname ist Administrator. Sie verwenden dieses Konto, um sich später in der Schnellstartanleitung beim Jupyter-Notizbuch anzumelden. Clusteranmeldungskennwort Geben Sie das Clusteranmeldungskennwort ein. SSH-Benutzername (Secure Shell) Geben Sie den SSH-Benutzernamen ein. Der für diese Schnellstartanleitung verwendete SSH-Benutzername ist sshuser. Standardmäßig verwendet dieses Konto dasselbe Kennwort wie das Benutzernamenkonto für die Clusteranmeldung . 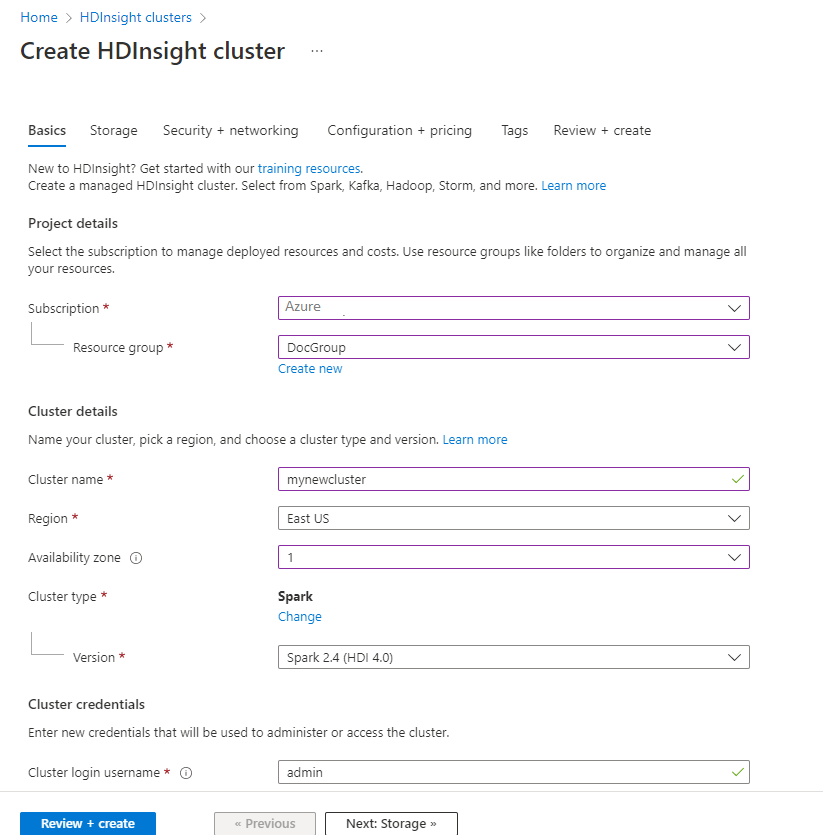
Wählen Sie "Weiter" aus: "Speicher >> ", um mit der Seite " Speicher " fortzufahren.
Geben Sie unter Speicher die folgenden Werte an:
Eigentum Description Primärer Speichertyp Verwenden Sie den Standardwert Azure Storage. Auswahlmethode Verwenden Sie den Standardwert "Aus Liste auswählen". Primäres Speicherkonto Verwenden Sie den automatisch ausgefüllten Wert. Container Verwenden Sie den automatisch ausgefüllten Wert. 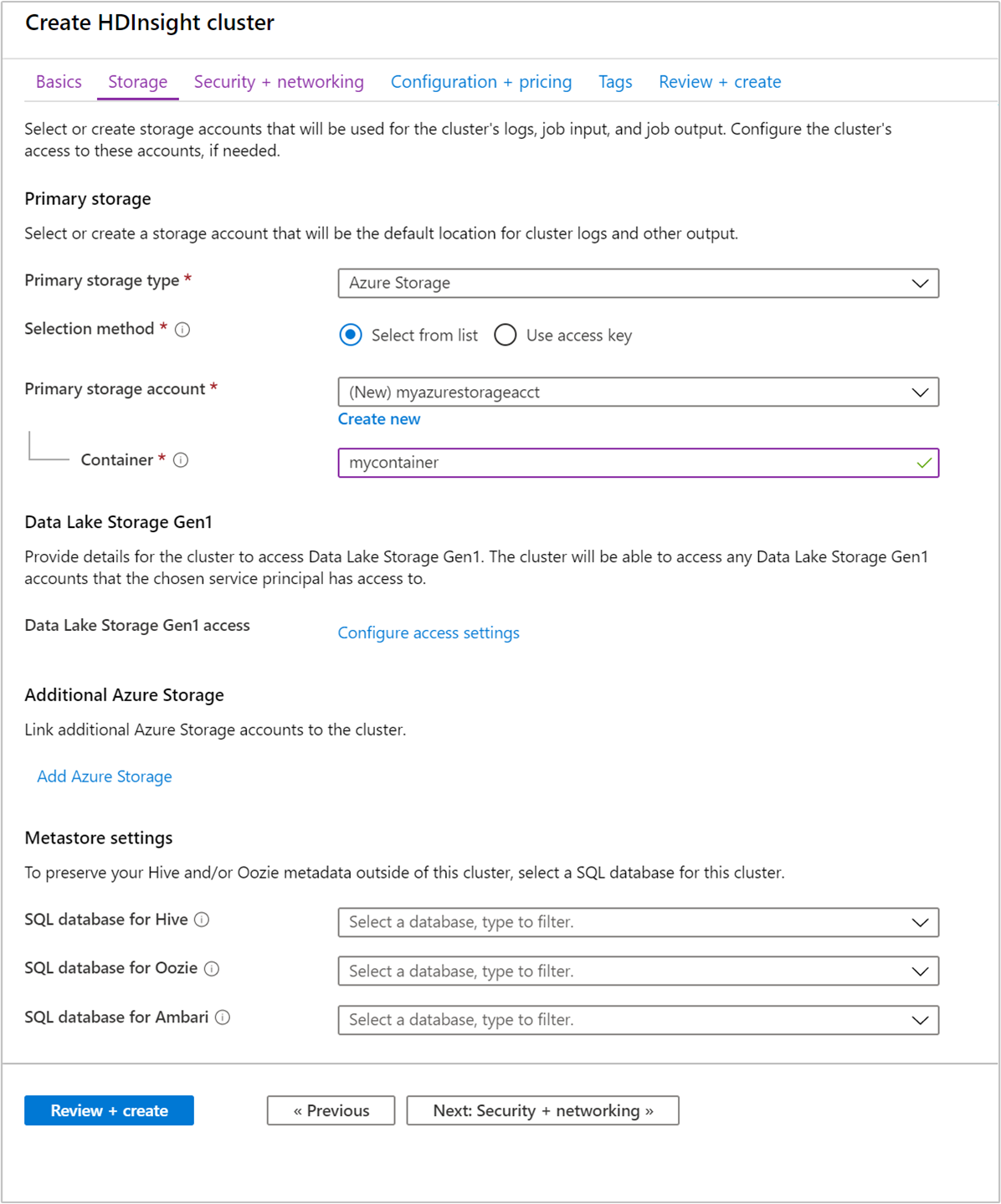
Wählen Sie zum Fortfahren Überprüfen + erstellen aus.
Wählen Sie unter Überprüfen + erstellen die Option Erstellen aus. Das Erstellen des Clusters dauert ca. 20 Minuten. Der Cluster muss erstellt werden, bevor Sie mit dem nächsten Abschnitt fortfahren können.
Wenn beim Erstellen von HDInsight-Clustern ein Problem aufgetreten ist, besteht dies möglicherweise darin, dass Sie nicht über die richtigen Berechtigungen verfügen. Weitere Informationen finden Sie unter Zugriffssteuerungsanforderungen.
Erstellen eines Jupyter-Notizbuchs
Jupyter Notebook ist eine interaktive Notizbuchumgebung, die verschiedene Programmiersprachen unterstützt. Mit dem Notizbuch können Sie mit Ihren Daten interagieren, Code mit Markdowntext kombinieren und einfache Visualisierungen ausführen.
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobeiCLUSTERNAMEder Name Ihres Clusters ist. Wenn Sie dazu aufgefordert werden, geben Sie die Anmeldeinformationen für den Cluster ein.Wählen Sie Neuer>PySpark aus, um ein Notizbuch zu erstellen.
Ein neues Notizbuch wird erstellt und mit dem Namen "Unbenannt (Untitled.pynb)" geöffnet.
Ausführen von Apache Spark SQL-Anweisungen
SQL (Structured Query Language) ist die am weitesten verbreitete Sprache zum Abfragen und Definieren von Daten. Spark SQL fungiert als Erweiterung für Apache Spark zur Verarbeitung strukturierter Daten mithilfe der vertrauten SQL-Syntax.
Überprüfen Sie, ob der Kernel bereit ist. Der Kernel ist bereit, wenn ein hohler Kreis neben dem Kernelnamen im Notizbuch angezeigt wird. Voller Kreis zeigt an, dass der Kernel ausgelastet ist.

Wenn Sie das Notizbuch zum ersten Mal starten, führt der Kernel einige Aufgaben im Hintergrund aus. Warten Sie, bis der Kernel bereit ist.
Fügen Sie den folgenden Code in eine leere Zelle ein, und drücken Sie dann UMSCHALT+EINGABETASTE , um den Code auszuführen. Der Befehl listet die Hive-Tabellen auf dem Cluster auf.
%%sql SHOW TABLESWenn Sie ein Jupyter-Notizbuch mit Ihrem HDInsight-Cluster verwenden, erhalten Sie eine Voreinstellung
sqlContext, die Sie zum Ausführen von Hive-Abfragen mit Spark SQL verwenden können.%%sqlweist Jupyter Notebook an, die VoreinstellungsqlContextzum Ausführen der Hive-Abfrage zu verwenden. Die Abfrage ruft die obersten 10 Zeilen aus einer Hive-Tabelle (hivesampletable) ab, die standardmäßig in allen HDInsight-Clustern enthalten ist. Es dauert etwa 30 Sekunden, um die Ergebnisse zu erhalten. Die Ausgabe sieht wie folgt aus: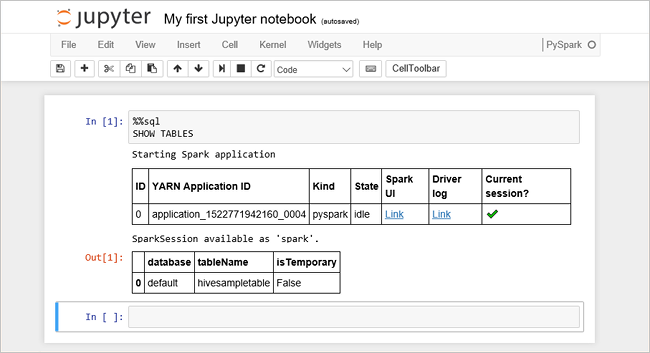 ist Schnellstart." border="true":::
ist Schnellstart." border="true":::Jedes Mal, wenn Sie eine Abfrage in Jupyter ausführen, zeigt der Titel des Webbrowserfensters zusammen mit dem Notizbuchtitel einen Status (Beschäftigt) an. Außerdem sehen Sie in der rechten oberen Ecke einen ausgefüllten Kreis neben dem Text PySpark.
Führen Sie eine weitere Abfrage aus, um die Daten in
hivesampletableanzuzeigen.%%sql SELECT * FROM hivesampletable LIMIT 10Der Bildschirm muss aktualisiert werden, um die Abfrageausgabe anzuzeigen.
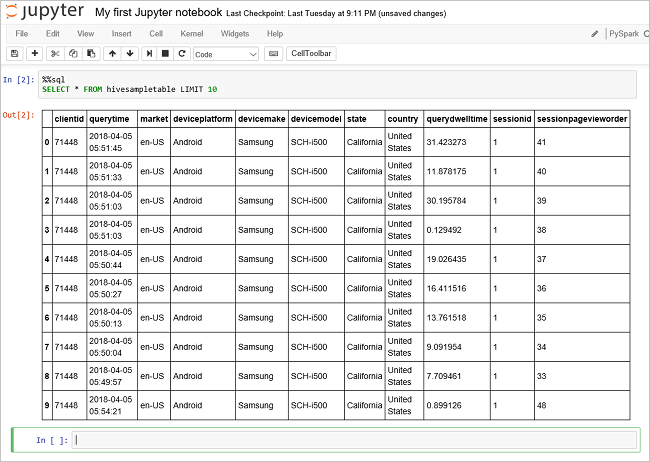 Insight" border="true":::
Insight" border="true":::Wählen Sie im Menü Datei auf dem Notebook Schließen und Anhalten aus. Durch das Herunterfahren des Notebooks werden die Clusterressourcen freigegeben.
Bereinigen von Ressourcen
HDInsight speichert Ihre Daten in Azure Storage oder Azure Data Lake Storage, sodass Sie einen Cluster sicher löschen können, wenn er nicht verwendet wird. Für einen HDInsight-Cluster fallen auch dann Gebühren an, wenn er nicht verwendet wird. Da die Gebühren für den Cluster erheblich höher sind als die Kosten für den Speicher, ist es sinnvoll, nicht verwendete Cluster zu löschen. Wenn Sie beabsichtigen, sofort an dem in den nächsten Schritten aufgeführten Lernprogramm zu arbeiten, sollten Sie den Cluster beibehalten.
Wechseln Sie zurück zum Azure-Portal, und wählen Sie "Löschen" aus.
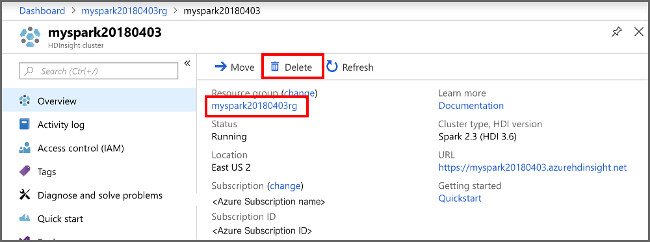 sight cluster" border="true":::
sight cluster" border="true":::
Sie können auch den Ressourcengruppennamen auswählen, um die Ressourcengruppenseite zu öffnen, und dann " Ressourcengruppe löschen" auswählen. Durch Löschen der Ressourcengruppe löschen Sie sowohl den HDInsight-Cluster als auch das Standardspeicherkonto.
Nächste Schritte
In dieser Schnellstartanleitung haben Sie erfahren, wie Sie einen Apache Spark-Cluster in HDInsight erstellen und eine einfache Spark SQL-Abfrage ausführen. Im nächsten Tutorial erfahren Sie, wie Sie mithilfe eines HDInsight-Clusters interaktive Abfragen für Beispieldaten ausführen.