Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Azure Machine Learning-Integration mit Azure Synapse Analytics bietet einfachen Zugriff auf das Apache Spark-Framework, um interaktives Data Wrangling mithilfe von Azure Machine Learning-Notebooks zu handhaben. Dieser Zugriff ermöglicht Data Wrangling mithilfe von Azure Machine Learning Notebooks.
In dieser Schnellstartanleitung erfahren Sie, wie Sie interaktives Data Wrangling mithilfe eines Azure Machine Learning Serverless Spark Compute, eines Azure Data Lake Storage (ADLS) Gen 2-Speicherkontos und eines Passthrough für die Benutzeridentität durchführen.
Voraussetzungen
- Ein Azure-Abonnement: Sollten Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Ein Azure Machine Learning-Arbeitsbereich. Besuchen Sie Erstellen von Arbeitsbereichsressourcen.
- Ein ADLS Gen2-Speicherkonto (Azure Data Lake Storage). Besuchen Sie Erstellen eines Azure Data Lake Storage (ADLS) Gen 2-Speicherkontos.
Speichern von Anmeldeinformationen für Azure-Speicherkonten als Geheimnisse in Azure Key Vault
So speichern Sie Anmeldeinformationen für Azure-Speicherkonten über die Benutzeroberfläche des Azure-Portals als Geheimnisse mit der Azure Key Vault-Instanz:
Navigieren Sie im Azure-Portal zu Ihrer Azure Key Vault-Instanz
Wählen Sie im linken Bereich Geheimnisse aus
Wählen Sie die Option + Generieren/Importieren aus.
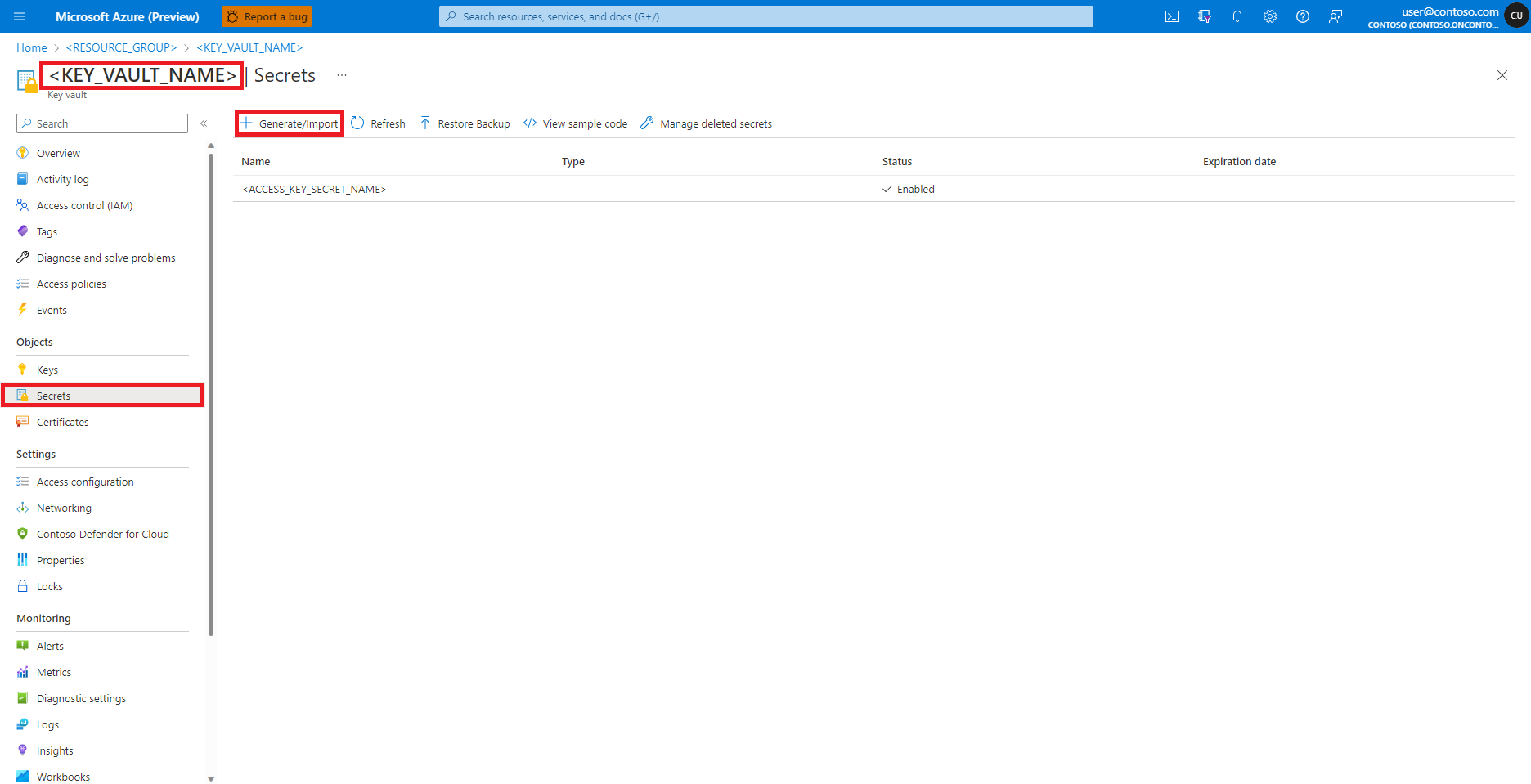
Geben Sie auf dem Bildschirm Geheimnis erstellen einen Namen für das zu erstellende Geheimnis ein
Navigieren Sie im Azure-Portal wie unten im Bild dargestellt zum Azure Blob Storage-Konto:
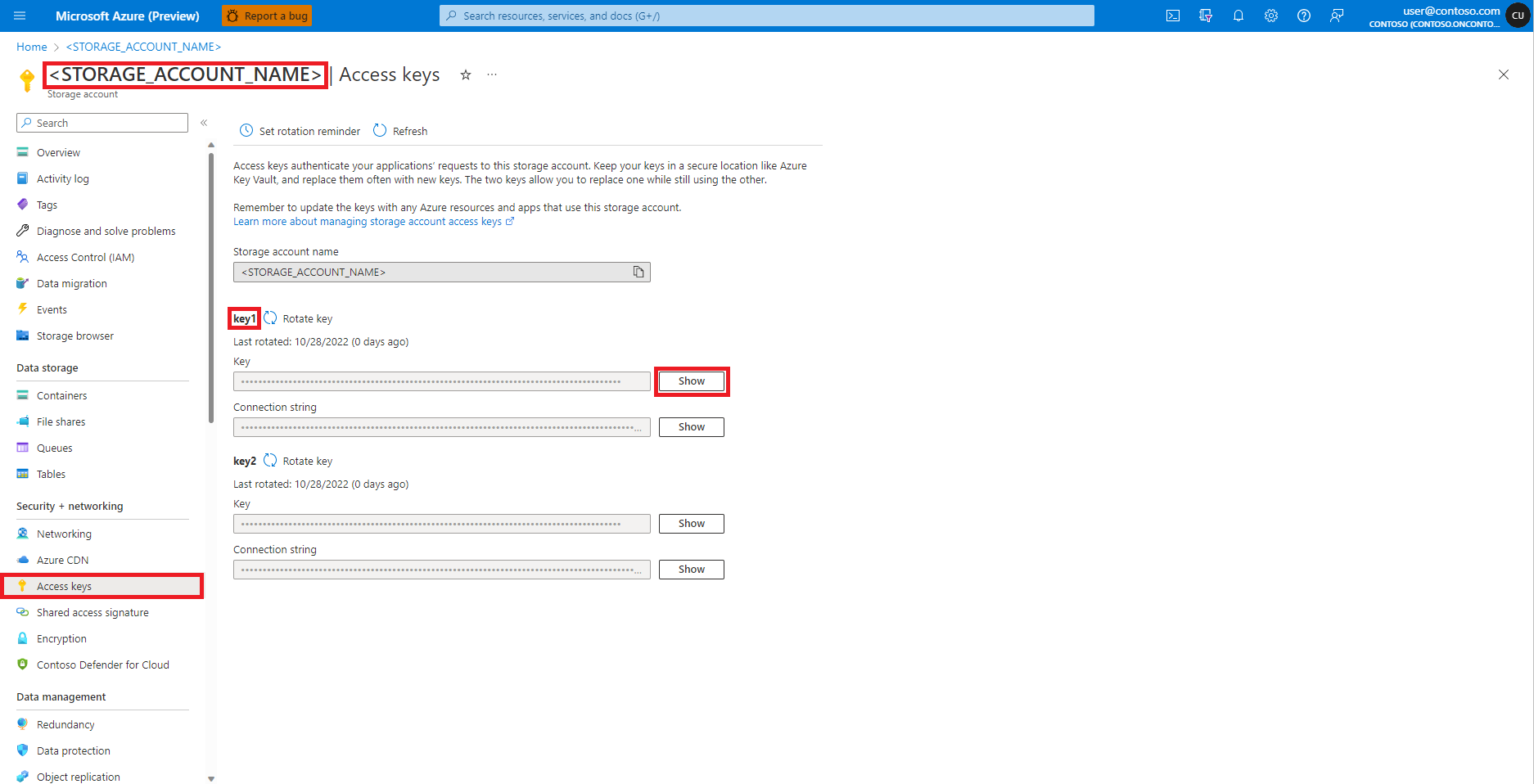
Wählen Sie im linken Bereich der Seite des Azure Blob Storage-Kontos die Option Zugriffsschlüssel aus
Wählen Sie neben Schlüssel 1 die Option Anzeigen und dann In Zwischenablage kopieren aus, um den Zugriffsschlüssel des Speicherkontos abzurufen
Hinweis
Wählen Sie die entsprechenden Optionen zum Kopieren
- SAS-Token (Shared Access Signature) für Azure Blob Storage-Container
- Anmeldeinformationen des Dienstprinzipals für ADLS Gen2-Speicherkonten (Azure Data Lake Storage)
- Mandanten-ID
- Client-ID und
- geheim
auf den jeweiligen Benutzeroberflächen aus, während Sie Azure Key Vault-Geheimnisse für diese erstellen
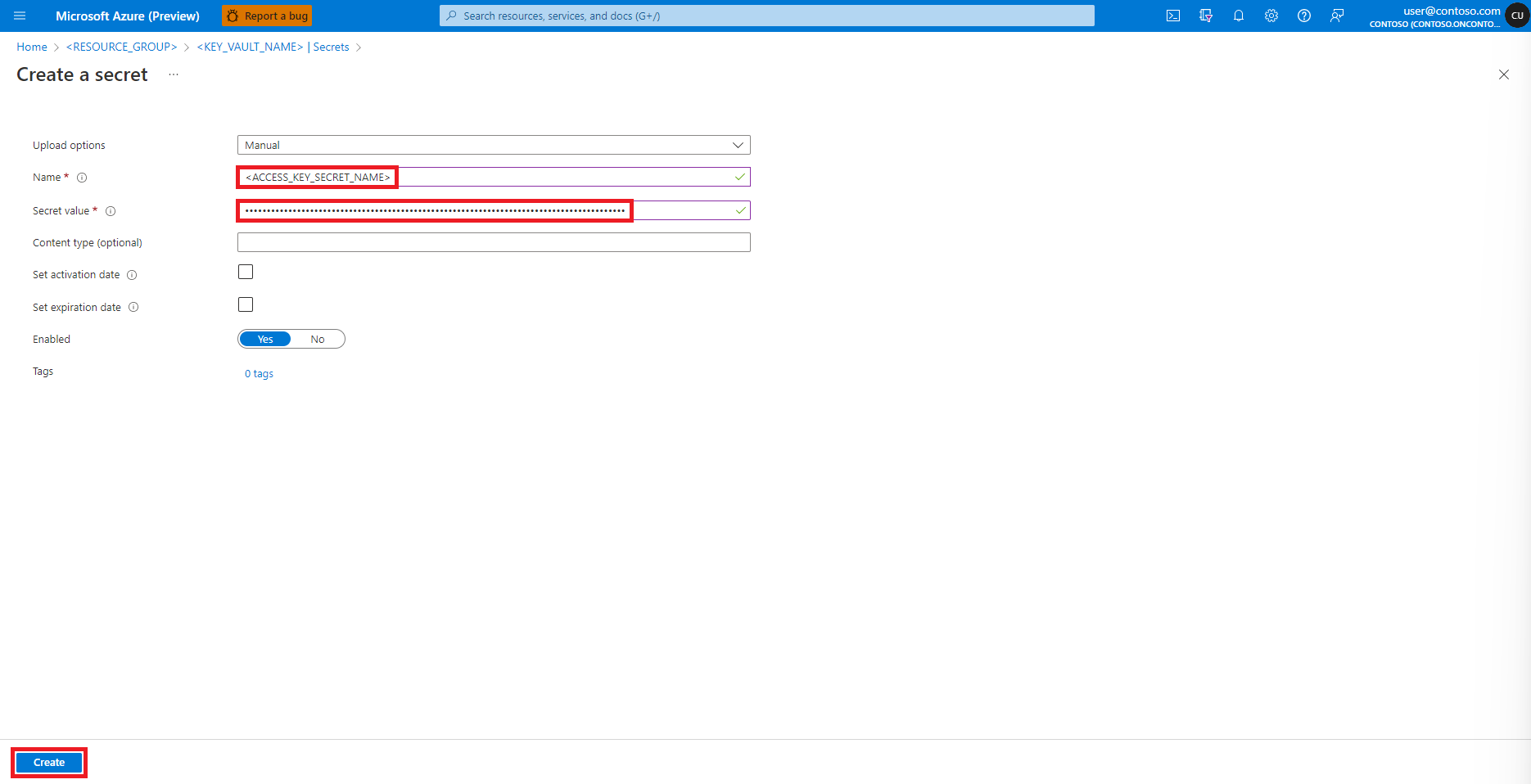
Navigieren Sie zurück zum Bildschirm Geheimnis erstellen
Geben Sie im Textfeld Geheimniswert die Anmeldeinformationen für den Zugriffsschlüssel für das Azure-Speicherkonto ein, der im vorherigen Schritt in die Zwischenablage kopiert wurde
Klicken Sie auf Erstellen
Tipp
Azure CLI und die Clientbibliothek mit Azure Key Vault-Geheimnissen für Python können auch Azure Key Vault-Geheimnisse erstellen.
Hinzufügen von Rollenzuweisungen in Azure-Speicherkonten
Wir müssen sicherstellen, dass auf die Eingabe- und Ausgabedatenpfade zugegriffen werden kann, bevor wir mit dem interaktiven Data Wrangling beginnen. Zunächst müssen wir
der Benutzeridentität des angemeldeten Notebooks-Sitzungsbenutzers
oder
einem Dienstprinzipal
Weisen Sie der Benutzeridentität des angemeldeten Benutzers die Rollen Leser und Leser von Speicher-BLOB-Daten zu. In bestimmten Szenarios sollten wir die aufbereiteten Daten jedoch zurück in das Azure-Speicherkonto schreiben. Die Rollen Leser und Storage-Blobdatenleser bieten schreibgeschützten Zugriff für die Benutzeridentität oder den Dienstprinzipal. Wenn Sie den Lese- und Schreibzugriff aktivieren möchten, weisen Sie der Benutzeridentität oder dem Dienstprinzipal die Rollen Mitwirkender und Mitwirkender an Storage-Blobdaten zu. So weisen Sie der Benutzeridentität geeignete Rollen zu
Öffnen Sie das Microsoft Azure-Portal
Suchen Sie nach dem Dienst Speicherkonten, und wählen Sie ihn aus

Wählen Sie auf der Seite Speicherkonten in der Liste das Speicherkonto Azure Data Lake Storage Gen 2 (ADLS) aus. Eine Seite mit der Übersicht für das Speicherkonto öffnet sich
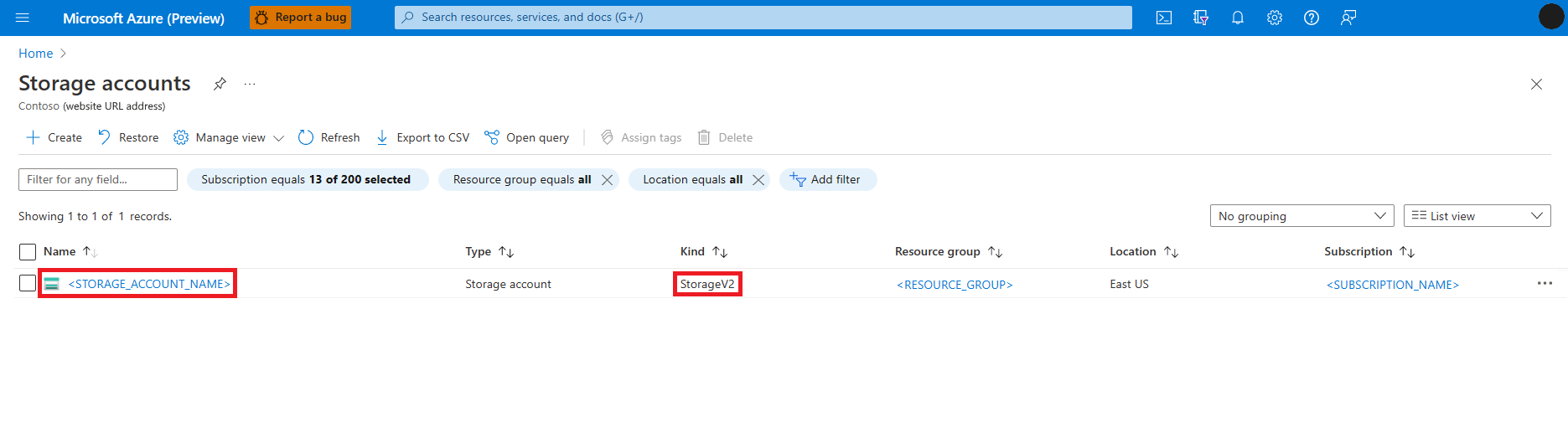
Wählen Sie im linken Bereich Zugriffssteuerung (IAM) aus.
Wählen Sie Rollenzuweisung hinzufügen aus.
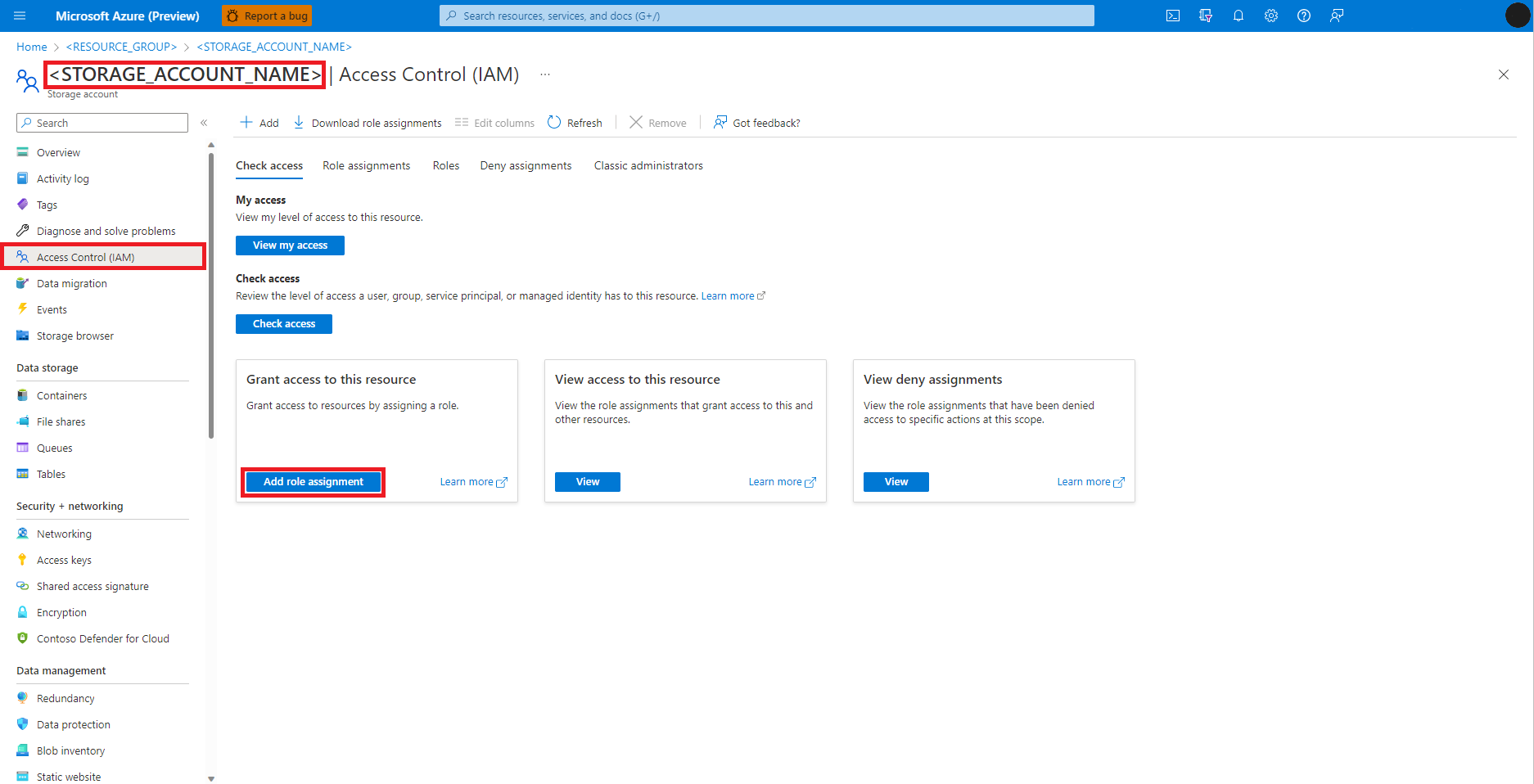
Wählen Sie die Rolle Mitwirkender an Storage-Blobdaten aus.
Wählen Sie Weiter aus.
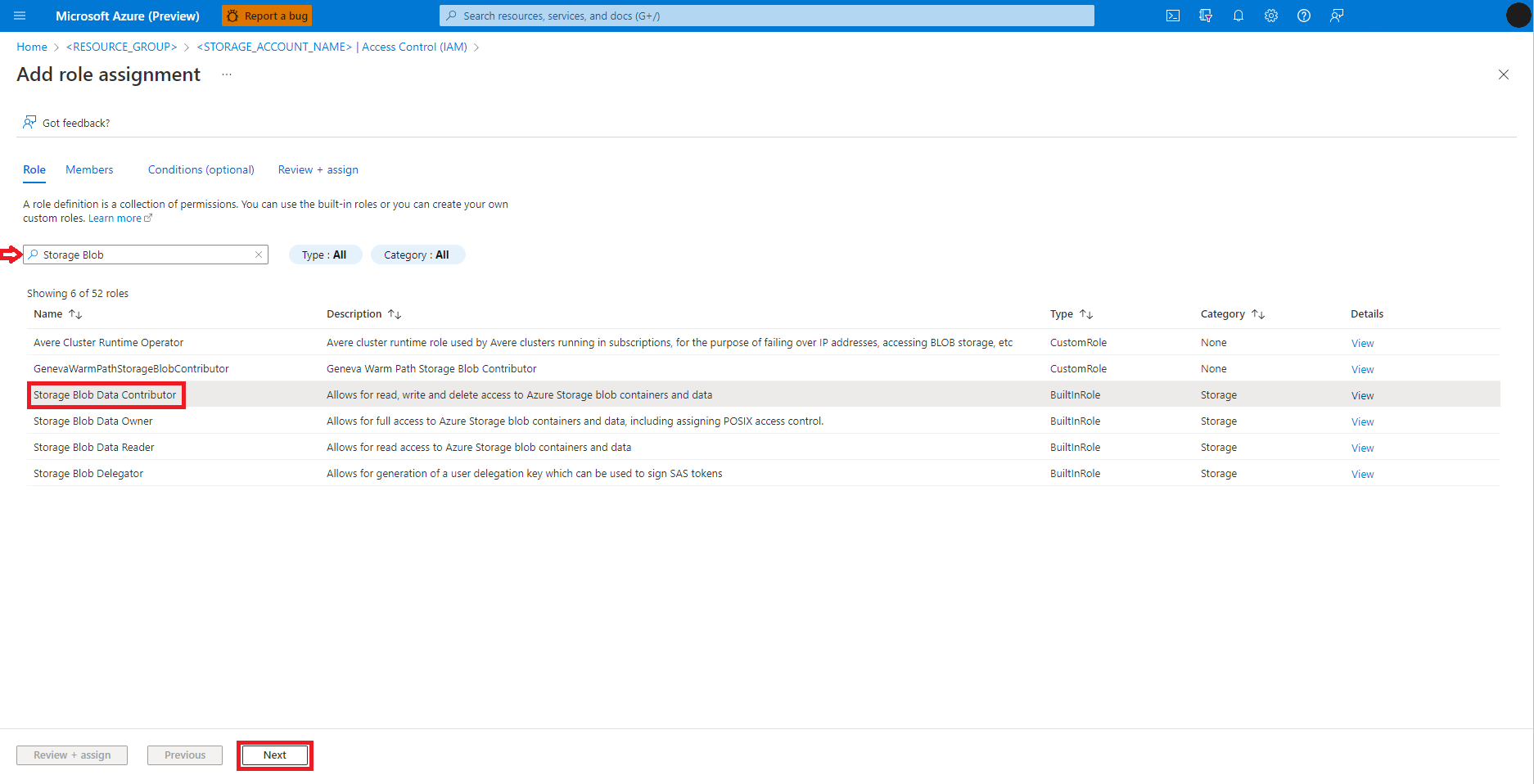
Wählen Sie User, group, or service principal (Benutzer, Gruppe oder Dienstprinzipal) aus
Wählen Sie + Mitglieder auswählen aus
Suchen Sie unter Auswählen nach der Benutzeridentität.
Wählen Sie die Benutzeridentität in der Liste aus, sodass sie unter Ausgewählte Mitglieder angezeigt wird.
Wählen Sie die entsprechende Benutzeridentität aus.
Wählen Sie Weiter aus.
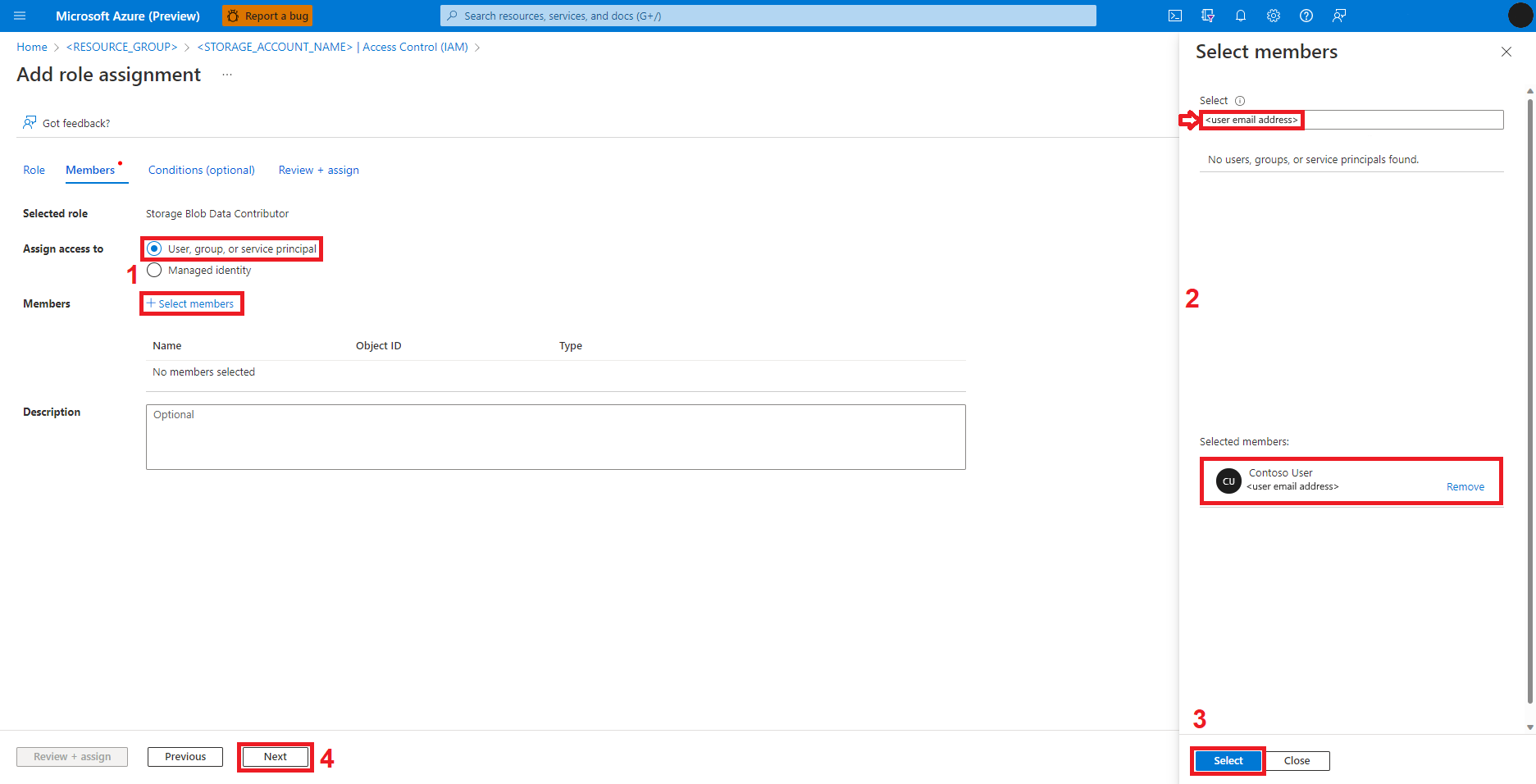
Wählen Sie Überprüfen und zuweisen aus.
Wiederholen Sie die Schritte 2 bis 13 für die Zuweisung der Rolle Mitwirkender






Sobald der Benutzeridentität oder dem Dienstprinzipal die entsprechenden Rollen zugewiesen wurden, sollten die Daten im Azure-Speicherkonto zugänglich sein.
Hinweis
Wenn ein angefügter Synapse Spark-Pool auf einen Synapse Spark-Pool in einem Azure Synapse-Arbeitsbereich verweist, dem ein verwaltetes virtuelles Netzwerk zugeordnet ist, sollten Sie ein verwalteter privater Endpunkt für das Speicherkonto konfigurieren, um den Zugriff auf die Daten sicherzustellen.
Sicherstellen des Ressourcenzugriffs für Spark-Aufträge
Spark-Aufträge können entweder eine verwaltete Identität oder einen Passthrough für die Benutzeridentität verwenden, um auf Daten und andere Ressourcen zuzugreifen. In der folgenden Tabelle sind die verschiedenen Mechanismen für den Ressourcenzugriff bei der Verwendung des serverlosen Spark Compute von Azure Machine Learning und des angeschlossenen Synapse Spark-Pools zusammengefasst.
| Spark-Pool | Unterstützte Identitäten | Standardidentität |
|---|---|---|
| Serverloses Spark Compute | Benutzeridentität, benutzerseitig zugewiesene verwaltete Identität, die dem Arbeitsbereich zugeordnet ist | Benutzeridentität |
| Angefügter Synapse Spark-Pool | Benutzeridentität, benutzerseitig zugewiesene verwaltete Identität, die dem angefügten Synapse Spark-Pool zugeordnet ist, systemseitig zugewiesene verwaltete Identität des angefügten Synapse Spark-Pools | Vom System zugewiesene verwaltete Identität des angefügten Synapse Spark-Pools |
Wenn der CLI- oder SDK-Code eine Option für die Verwendung einer verwalteten Identität definiert, stützt sich das serverlose Spark Compute von Azure Machine Learning auf eine vom Benutzer zugewiesene verwaltete Identität, die dem Arbeitsbereich zugeordnet ist. Sie können mithilfe von Azure Machine Learning CLI v2 oder mit ARMClient eine benutzerseitig zugewiesene verwaltete Identität an einen vorhandenen Azure Machine Learning-Arbeitsbereich anfügen.
Nächste Schritte
- Apache Spark in Azure Machine Learning
- Anfügen und Verwalten eines Synapse Spark-Pools in Azure Machine Learning
- Interaktives Data Wrangling mit Apache Spark in Azure Machine Learning
- Übermitteln von Spark-Aufträgen in Azure Machine Learning
- Codebeispiele für Spark-Aufträge mithilfe der Azure Machine Learning-CLI
- Codebeispiele für Spark-Aufträge mit dem Azure Machine Learning Python-SDK