Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:
 Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum zu Azure Machine Learning zu wechseln.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
- Informationen zum Verschieben von Machine Learning-Projekten von ML Studio (klassisch) zu Azure Machine Learning.
- Weitere Informationen zu Azure Machine Learning
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
In diesem Artikel erhalten Sie weitere Informationen zu den Metriken, die Sie verwenden können, um die Modellleistung in Machine Learning Studio (Classic) zu überwachen. Die Auswertung der Leistung eines Modells ist eine der wesentlichen Phasen im Datenanalyseprozess. Sie gibt an, wie erfolgreich die Bewertung (die Vorhersagen) eines Datasets eines trainierten Modells war. In Machine Learning Studio (Classic) wird die Auswertung von Modellen durch zwei der wichtigsten Machine Learning-Module unterstützt:
Mit diesen Modulen können Sie die Leistung Ihres Modells im Hinblick auf verschiedene Kennzahlen anzeigen, die beim maschinellen Lernen und in der Statistik häufig verwendet werden.
Beim Auswerten von Modellen sollte außerdem Folgendes berücksichtigt werden:
Es werden drei häufig eingesetzte Szenarios des beaufsichtigten Lernens vorgestellt:
- Regression
- Binäre Klassifizierung
- Multiklassenklassifizierung
Auswertung und Kreuzvalidierung im Vergleich
Die Auswertung und die Kreuzvalidierung sind Standardmethoden zum Messen der Leistung von Modellen. Bei beiden Methoden werden Auswertungskennzahlen generiert, die mit denen anderer Modelle geprüft oder verglichen werden können.
Das Auswertungsmodell erwartet ein bewertetes Dataset als Eingabe (oder zwei für den Fall, dass Sie die Leistung von zwei verschiedenen Modellen vergleichen möchten). Daher müssen Sie Ihr Modell mithilfe des Train-Modellmoduls trainieren und Vorhersagen für einige Datasets mithilfe des Score Model-Moduls erstellen, bevor Sie die Ergebnisse auswerten können. Die Auswertung basiert auf den bewerteten Bezeichnungen/Wahrscheinlichkeiten zusammen mit den tatsächlichen Beschriftungen, die alle vom Score Model-Modul ausgegeben werden.
Alternativ können Sie mithilfe der Kreuzvalidierung automatisch mehrere Trainings-/Bewertungs-/Auswertungsvorgänge (Aufteilung in 10 Teildatensätze) für verschiedene Teilmengen der Eingabedaten durchführen. Die Eingabedaten werden in 10 Teilmengen aufgeteilt, wobei eine Teilmenge zum Testen und die anderen 9 zum Trainieren vorgesehen sind. Dieser Vorgang wird 10-mal wiederholt, und die Auswertungskennzahlen werden gemittelt. Damit lässt sich feststellen, wie gut ein Modell neue Datasets verallgemeinert. Das Modul Cross-Validate Model verwendet ein untrainiertes Modell und einige markierte Datensätze und gibt die Bewertungsergebnisse jeder der 10 Faltungen neben den durchschnittlichen Ergebnissen aus.
In den folgenden Abschnitten erstellen wir einfache Regressions- und Klassifikationsmodelle und bewerten ihre Leistung unter Verwendung der Module "Evaluate Model " und " Cross-Validate Model ".
Auswerten eines Regressionsmodells
Angenommen, wir möchten den Preis eines Fahrzeugs anhand von Eigenschaften wie Abmessungen, PS, Motorisierung usw. vorhersagen. Dies ist ein typisches Regressionsproblem, bei dem die Zielvariable (Preis) ein fortlaufender numerischer Wert ist. Dazu kann ein lineares Regressionsmodell angepasst werden, das mit den Eigenschaftenwerten eines bestimmten Fahrzeugs den Preis des Fahrzeugs vorhersagen kann. Mit diesem Regressionsmodell kann das gleiche Dataset bewertet werden, das für das Training verwendet wurde. Wenn die vorhergesagten Fahrzeugpreise vorliegen, kann die Modellleistung ausgewertet werden, indem wir uns ansehen, inwieweit die Vorhersagen im Durchschnitt von den tatsächlichen Preisen abweichen. Um dies zu veranschaulichen, verwenden wir den Datensatz "Automobilpreisdaten (Rohdaten)", der im Abschnitt "Gespeicherte Datasets" in Machine Learning Studio (klassisch) verfügbar ist.
Erstellen des Experiments
Fügen Sie Ihrem Arbeitsbereich in Machine Learning Studio (Classic) die folgenden Module hinzu:
- Automobile Preisdaten (Rohdaten)
- Lineare Regression
- Modell trainieren
- Bewertungsmodell
- Modell auswerten
Verbinden Sie die Ports, wie in Abbildung 1 unten dargestellt, und legen Sie die Spalte "Label" des Train Model-Moduls auf price fest.
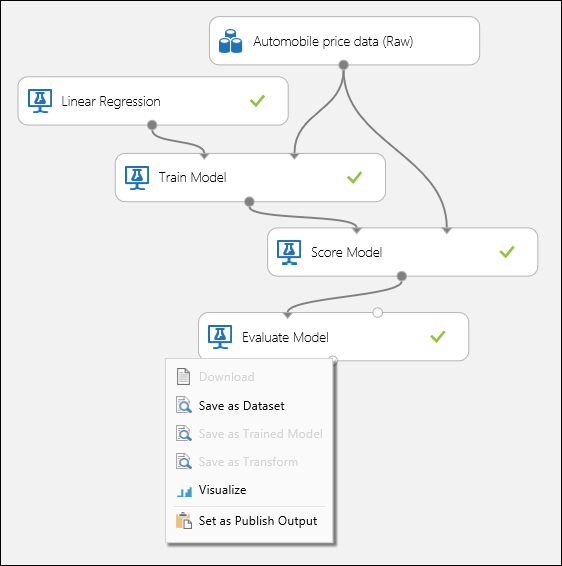
Abbildung 1. Auswerten eines Regressionsmodells.
Überprüfen der Auswertungsergebnisse
Nachdem Sie das Experiment ausgeführt haben, können Sie auf den Ausgabeport des Moduls "Evaluate Model " klicken und "Visualisieren" auswählen, um die Auswertungsergebnisse anzuzeigen. Die für Regressionsmodelle verfügbaren Auswertungsmetriken sind: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Relativer quadratischer Fehler und der Bestimmtheitskoeffizient.
Der Begriff "Fehler" gibt hier die Differenz zwischen dem vorhergesagten und dem tatsächlichen Wert an. Normalerweise wird der absolute Wert oder das Quadrat dieser Differenz berechnet, um die gesamte Fehlerabweichung in allen Fällen zu erfassen, da die Differenz zwischen dem vorhergesagten und dem tatsächlichen Wert in einigen Fällen auch negativ sein kann. Die Fehlerkennzahlen messen die Vorhersageleistung eines Regressionsmodells im Hinblick auf die mittlere Abweichung seiner Vorhersagen von den tatsächlichen Werten. Kleinere Fehlerwerte bedeuten, dass das Modell bei Vorhersagen genauer ist. Die Fehlerkennzahl null bedeutet, dass das Modell perfekt mit den Daten übereinstimmt.
Das Bestimmtheitsmaß, das auch als "R-Quadrat" notiert wird, ist ebenfalls eine Standardmethode für die Berechnung, wie gut das Vorhersagemodell mit den Daten übereinstimmt. Es kann als der Anteil der Abweichung interpretiert werden, der durch das Modell beschrieben wird. In diesem Fall ist ein höherer Anteil besser, wobei "1" eine perfekte Übereinstimmung angibt.
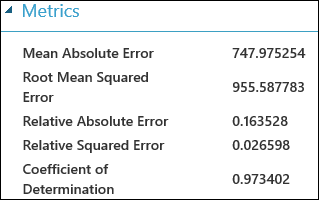
Abbildung 2. Auswertungskennzahlen bei der linearen Regression.
Verwenden der Kreuzvalidierung
Wie bereits erwähnt, können Sie wiederholte Schulungen, Bewertungen und Auswertungen automatisch mithilfe des Moduls "Cross-Validate Model " durchführen. Alles, was Sie in diesem Fall benötigen, ist ein Dataset, ein untrainiertes Modell und ein Cross-Validate-Modellmodul (siehe Abbildung unten). Sie müssen die Bezeichnungsspalte auf "Preis " in den Eigenschaften des Cross-Validate-Modellmoduls festlegen.
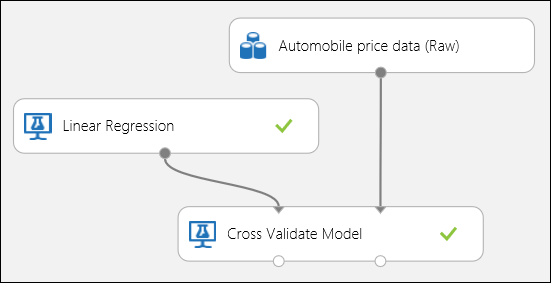
Abbildung 3. Kreuzvalidierung eines Regressionsmodells.
Nach dem Ausführen des Experiments können Sie die Auswertungsergebnisse überprüfen, indem Sie auf den rechten Ausgabeport des Cross-Validate-Modellmoduls klicken. Dadurch werden eine Detailansicht der Kennzahlen für jede Iteration (Aufteilung) und die gemittelten Ergebnisse aller Kennzahlen angezeigt (Abbildung 4).
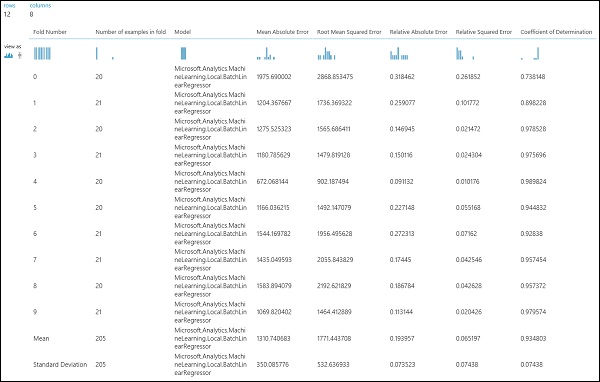
Abbildung 4. Ergebnisse der Kreuzvalidierung eines Regressionsmodells.
Auswerten eines binären Klassifizierungsmodells
Bei der binären Klassifizierung hat die Zielvariable nur zwei mögliche Ergebnisse, z. B.: {0, 1} oder {falsch, wahrt}, {negativ, positiv}. Angenommen, Sie erhalten ein Dataset mit Mitarbeiterdaten, das verschiedene Variablen zu Demografie und Beschäftigung enthält, und Sie werden gebeten, das Einkommensniveau (eine binäre Variable mit den Werten {"<=50 K", ">50 K"}) vorherzusagen. Anders gesagt: Die negative Klasse gibt die Mitarbeiter an, deren Einkommen pro Jahr kleiner oder gleich 50 K (50.000) ist, und die positive Klasse alle anderen Mitarbeiter. Wie beim Regressionsszenario werden ein Modell trainiert, einige Daten bewertet und die Ergebnisse ausgewertet. Der Hauptunterschied besteht hier in der Auswahl der Metriken, die in Machine Learning Studio (Classic) berechnet und ausgegeben werden. Zur Veranschaulichung des Szenarios für die Einkommensstufe verwenden wir das Dataset "Adult ", um ein Studio-Experiment (klassisch) zu erstellen und die Leistung eines zweistufigen Logistischen Regressionsmodells zu bewerten, einem häufig verwendeten binären Klassifizierer.
Erstellen des Experiments
Fügen Sie Ihrem Arbeitsbereich in Machine Learning Studio (Classic) die folgenden Module hinzu:
- Dataset "Adult Census Income Binary Classification"
- Two-Class Logistische Regression
- Modell trainieren
- Bewertungsmodell
- Modell auswerten
Verbinden Sie die Ports wie unten in Abbildung 5 dargestellt, und legen Sie die Spalte "Bezeichnung" des Train-Modellmoduls auf Einkommen fest.
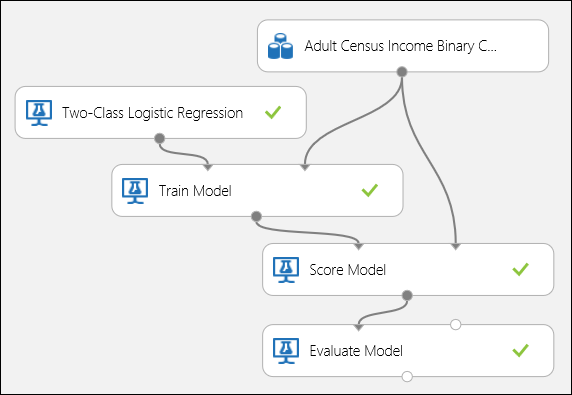
Abbildung 5. Auswerten eines binären Klassifizierungsmodells.
Überprüfen der Auswertungsergebnisse
Nachdem Sie das Experiment ausgeführt haben, können Sie auf den Ausgabeport des Moduls "Evaluate Model " klicken und "Visualisieren" auswählen, um die Auswertungsergebnisse anzuzeigen (Abbildung 7). Die für binäre Klassifizierungsmodelle verfügbaren Auswertungsmetriken sind: Genauigkeit, Genauigkeit, Rückruf, F1 Bewertung und AUC. Darüber hinaus gibt das Modul eine Verwirrungsmatrix mit der Anzahl wahrer Positiver, falsch negativer Ergebnisse, falsch positiver Ergebnisse und wahrer Negativer sowie ROC-, Präzisions-/Rückruf- und Liftkurven aus.
Genauigkeit (Accuracy) ist dabei der Anteil der richtig klassifizierten Fälle. Sie ist normalerweise die erste Kennzahl, die Sie sich bei der Auswertung eines Klassifikators ansehen. Wenn die Testdaten jedoch unausgeglichen sind (also die meisten Fälle einer einzelnen Klasse angehören) oder Sie sich überwiegend für eine einzelne Klasse interessieren, wird mit der Genauigkeit die Effektivität eines Klassifikators nicht wirklich erfasst. Angenommen, beim Klassifizierungsszenario für das Einkommensniveau testen Sie Daten, bei denen 99 % der Fälle Mitarbeiter angeben, deren Einkommen pro Jahr kleiner oder gleich 50K ist. Bei der Vorhersage der Klasse „<=50.000“ für alle Fälle kann eine Genauigkeit von 0,99 erreicht werden. Der Klassifikator scheint in diesem Fall eine durchweg solide Leistung zu liefern, in Wirklichkeit werden aber alle Personen mit höherem Einkommen (die 1 %) nicht richtig klassifiziert.
Aus diesem Grund ist es nützlich, weitere Kennzahlen zu berechnen, die die spezifischeren Aspekte der Auswertung erfassen. Bevor die Einzelheiten dieser Kennzahlen besprochen werden, ist es wichtig, die Wahrheitsmatrix der Auswertung einer binären Klassifizierung zu verstehen. Die Klassen in den Trainingsdaten können nur zwei mögliche Werte annehmen, die normalerweise positiv oder negativ ausfallen. Die positiven und negativen Fälle, die ein Klassifikator richtig vorhersagt, werden als "richtig positiv" (RP) bzw. "richtig negativ" (RN) bezeichnet. Dementsprechend werden die falsch klassifizierten Fälle als "falsch positiv" (FP) und "falsch negativ" (FN) bezeichnet. Bei der Wahrheitsmatrix handelt es sich um eine tabellarische Aufstellung der Anzahl der Fälle, die sich in eine dieser vier Kategorien einordnen lassen. In Machine Learning Studio (Classic) wird automatisch festgelegt, welche der beiden Klassen im Dataset als positive Klasse eingeordnet wird. Wenn es sich bei den Klassenwerten um boolesche Werte oder ganze Zahlen handelt, werden die mit „Richtig“ oder „1“ kategorisierten Fälle der positiven Klasse zugewiesen. Wenn die Bezeichner wie beim Dataset zur Einkommenserhebung Zeichenfolgen sind, werden sie alphabetisch sortiert. Die erste Ebene wird als negative Klasse eingestuft und die zweite Ebene als positive Klasse.
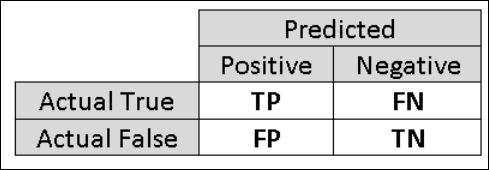
Abbildung 6. Wahrheitsmatrix der binären Klassifizierung.
Im Hinblick auf die Klassifizierung des Einkommens in unserem Beispiel sollen mehrere Auswertungsfragen gestellt werden, mit denen die Leistung des verwendeten Klassifikators bewertet werden kann. Eine nahe liegende Frage ist: „Wie viele der Personen, für die im Modell vorhergesagt wurde, dass ihr Einkommen >50K beträgt (RP+FP), wurden richtig klassifiziert (RP)?“ Diese Frage kann beantwortet werden, indem sie sich die Genauigkeit des Modells ansehen, bei dem es sich um den Anteil positiver Ergebnisse handelt, die richtig klassifiziert werden: TP/(TP+FP). Eine weitere Frage lautet: „Wie viele aller besserverdienenden Mitarbeiter mit einem Einkommen von >50.000 (RP+FN) wurden mit dem Klassifikator richtig klassifiziert (RP)?“ Dies ist tatsächlich der Rückruf oder die wahre positive Rate: TP/(TP+FN) des Klassifizierers. Sie können feststellen, dass ein offensichtlicher Zusammenhang zwischen Präzision und Sensitivität besteht. Ein relativ ausgeglichenes Dataset vorausgesetzt, weist ein Klassifikator, der überwiegend positive Fälle vorhersagt, eine hohe Sensitivität, jedoch eine eher geringe Präzision auf, da viele der negativen Fälle falsch klassifiziert werden, was zu einer hohen Anzahl falsch-negativer Fälle führt. Wenn Sie sehen möchten, wie diese beiden Metriken variieren, können Sie auf der Ausgabeseite des Auswertungsergebnisses (oben links in Abbildung 7) auf die PRECISION/RECALL-Kurve klicken.
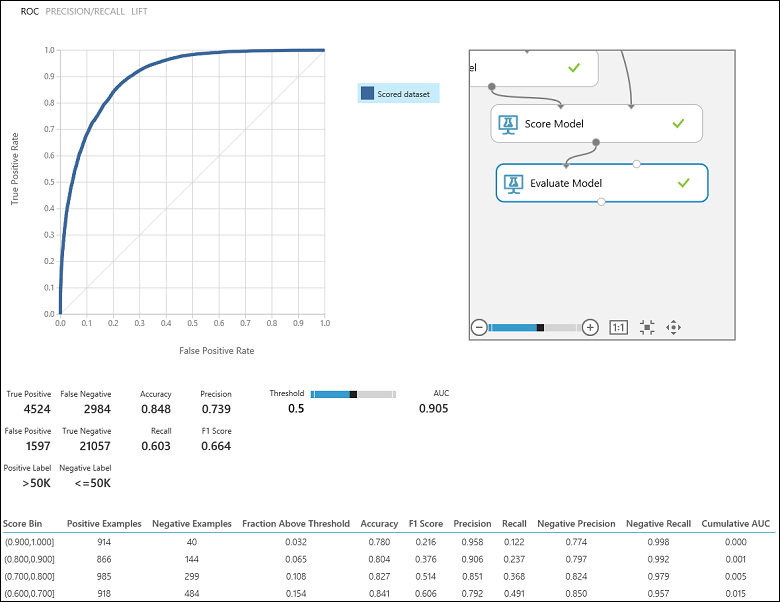
Abbildung 7. Auswertungsergebnisse der binären Klassifizierung.
Eine weitere verwandte Metrik, die häufig verwendet wird, ist der F1-Score, der sowohl Präzision als auch Erinnerungsvermögen berücksichtigt. Es ist das harmonische Mittel dieser beiden Metriken und wird wie folgt berechnet: F1 = 2 (Genauigkeit x Rückruf) / (Genauigkeit + Rückruf). Der F1-Score ist eine gute Methode, um die Auswertung in einer einzelnen Zahl zusammenzufassen. Es empfiehlt sich jedoch auch immer, die Präzision und Sensitivität zusammen zu betrachten, um das Verhalten eines Klassifikators besser einschätzen zu können.
Darüber hinaus kann man die wahre positive Rate im Vergleich zur falsch positiven Rate in der RoC-Kurve (Receiver Operating Characteristic) und den entsprechenden AUC-Wert (Area Under the Curve) prüfen. Je stärker sich diese Kurve der linken oberen Ecke annähert, desto besser ist die Leistung des Klassifikators (d. h., die Richtig-Positiv-Rate wird maximiert, während die Falsch-Positiv-Rate minimiert wird). Kurven, die sich der Diagonale in der Darstellung nähern, sind auf Klassifikatoren zurückzuführen, deren Vorhersagen auf bloßes Raten hinauslaufen.
Verwenden der Kreuzvalidierung
Wie im Regressionsbeispiel kann die Kreuzvalidierung durchgeführt werden, um verschiedene Teilmengen der Daten automatisch mehrmals zu trainieren, zu bewerten und auszuwerten. Ebenso können wir das Cross-Validate-Modellmodul , ein untrainiertes logistisches Regressionsmodell und ein Dataset verwenden. Die Bezeichnungsspalte muss auf Einkommen in den Eigenschaften des Cross-Validate Model-Moduls festgelegt werden. Nachdem Sie das Experiment ausgeführt und auf den richtigen Ausgabeport des Moduls "Cross-Validate Model " geklickt haben, können wir die Metrikwerte der binären Klassifizierung für jede Faltung sowie die Mittel- und Standardabweichung der einzelnen Elemente anzeigen.
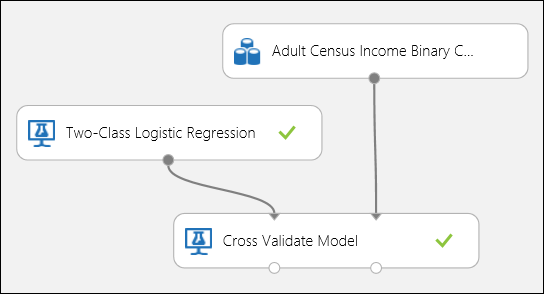
Abbildung 8. Kreuzvalidierung eines binären Klassifizierungsmodells.
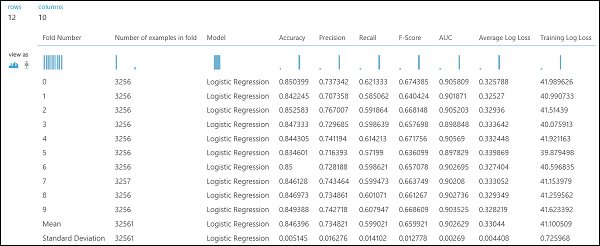
Abbildung 9. Ergebnisse der Kreuzvalidierung eines binären Klassifikators.
Auswerten eines Modells für die Multiklassenklassifizierung
In diesem Experiment verwenden wir das beliebte , das Instanzen von drei verschiedenen Typen (Klassen) der Irispflanze enthält. Für jeden Fall sind vier Funktionswerte (Länge/Breite des Kelchblatts und Länge/Breite des Blütenblatts) definiert. In den vorhergehenden Experimenten wurden die Modelle mit den gleichen Datasets trainiert und getestet. Hier verwenden wir das Modul Split Data, um zwei Teilmengen der Daten zu erstellen, auf der ersten zu trainieren und auf der zweiten zu bewerten und zu evaluieren. Das Iris-Dataset ist öffentlich im UCI Machine Learning Repository verfügbar und kann mit einem Import Data-Modul heruntergeladen werden.
Erstellen des Experiments
Fügen Sie Ihrem Arbeitsbereich in Machine Learning Studio (Classic) die folgenden Module hinzu:
- Importieren von Daten
- Mehrklassige Entscheidungsstruktur
- Daten teilen
- Modell trainieren
- Bewertungsmodell
- Modell auswerten
Verbinden Sie die Ports wie unten in Abbildung 10 dargestellt.
Legen Sie den Spaltenindex "Bezeichnung" des Train-Modellmoduls auf 5 fest. Das Dataset verfügt über keinen Header, wir wissen jedoch, dass sich die Klassenbezeichner in der fünften Spalte befinden.
Klicken Sie auf das Importdaten-Modul und setzen Sie die Datenquelle auf Web-URL über HTTP und die URL auf http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Legen Sie den Bruchteil der Instanzen fest, die für die Schulung im Modul "Geteilte Daten " verwendet werden sollen (z. B. 0,7).
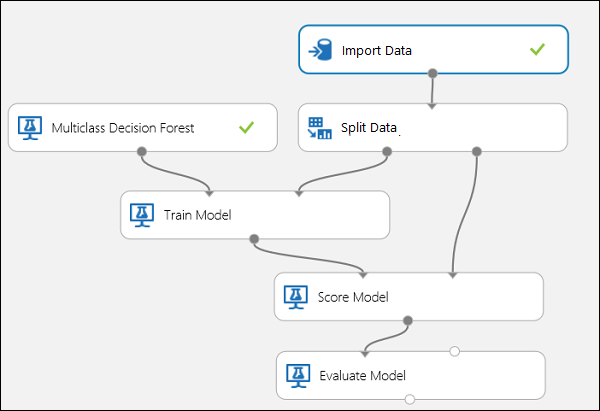
Abbildung 10. Auswerten eines Multiklassenklassifikators
Überprüfen der Auswertungsergebnisse
Führen Sie das Experiment aus, und klicken Sie auf den Ausgabeport von Evaluate Model. Die Auswertungsergebnisse werden in diesem Beispiel in Form einer Wahrheitsmatrix angezeigt. In der Matrix sind die tatsächlichen und vorhergesagten Fälle für alle drei Klassen aufgeführt.
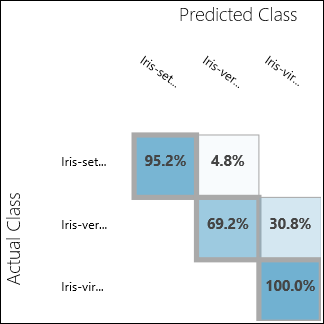
Abbildung 11. Auswertungsergebnisse der Multiklassenklassifizierung.
Verwenden der Kreuzvalidierung
Wie bereits erwähnt, können Sie wiederholte Schulungen, Bewertungen und Auswertungen automatisch mithilfe des Moduls "Cross-Validate Model " durchführen. Sie benötigen ein Dataset, ein nicht trainiertes Modell und ein Cross-Validate-Modellmodul (siehe abbildung unten). Erneut müssen Sie die Beschriftungsspalte des Moduls "Cross-Validate Model " festlegen (in diesem Fall Spaltenindex 5). Nachdem Sie das Experiment ausgeführt und auf den richtigen Ausgabeport des Cross-Validate-Modells geklickt haben, können Sie die Metrikwerte für jede Faltung sowie die Mittel- und Standardabweichung prüfen. Die hier aufgeführten Kennzahlen sind denen sehr ähnlich, die zuvor im Beispiel für die binäre Klassifizierung erörtert wurden. Bei der Multiklassenklassifizierung erfolgt die Berechnung der Fälle "Richtig positiv/negativ" und "Falsch positiv/negativ" jedoch klassenspezifisch, da es keine allgemeine positive oder negative Klasse gibt. Wenn beispielsweise die Präzision oder die Sensitivität der Klasse „Iris-setosa“ berechnet wird, wird davon ausgegangen, dass es sich dabei um die positive Klasse handelt und dass alle anderen Klassen negativ sind.
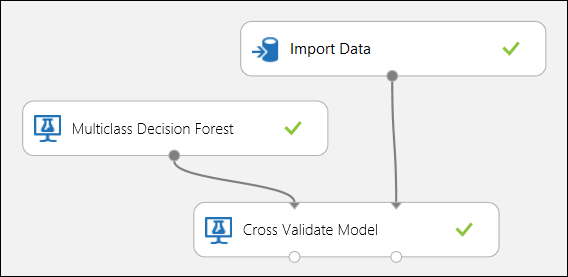
Abbildung 12. Kreuzvalidierung eines Modells für die Multiklassenklassifizierung
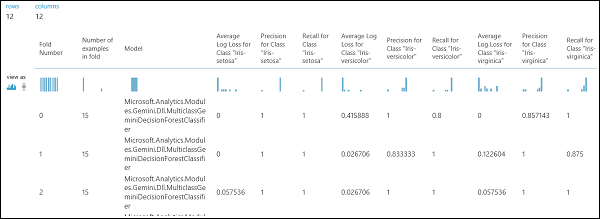
Abbildung 13. Ergebnisse der Kreuzvalidierung eines Modells für die Multiklassenklassifizierung.