Tutorial 1: Vorhersagen des Kreditrisikos: Machine Learning Studio (Classic)
GILT FÜR:  Machine Learning Studio (klassisch)
Machine Learning Studio (klassisch)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Dieses Tutorial befasst sich eingehend mit der Entwicklung einer Predictive Analytics-Lösung. Hierzu wird in Machine Learning Studio (klassisch) ein einfaches Modell entwickelt. Stellen Sie das Model anschließend als Machine Learning-Webdienst bereit. Dieses bereitgestellte Modell kann auf der Grundlage neuer Daten Vorhersagen generieren. Dieses Tutorial ist der erste Teil einer dreiteiligen Reihe.
Stellen Sie sich vor, Sie müssen das Kreditrisiko von Personen anhand der Daten auf einem Kreditantrag vorhersagen.
Die Bewertung des Kreditrisikos ist allerdings ein komplexes Problem und wurde daher in diesem Tutorial etwas vereinfacht. Diese Aufgabenstellung dient als Beispiel dafür, wie Sie eine Predictive Analytics-Lösung mit Machine Learning Studio (Classic) erstellen können. Für diese Lösung werden Sie Machine Learning Studio (Classic) und ein Machine Learning-Webdienst verwendet.
In diesem dreiteiligen Tutorial werden zunächst öffentlich verfügbare Kreditrisikodaten verwendet. Als Nächstes entwickeln und trainieren Sie ein Vorhersagemodell. Abschließend stellen Sie das Modell als Webdienst bereit.
In diesem Teil des Tutorials führen Sie die folgenden Schritte aus:
- Erstellen eines (klassischen) Machine Learning Studio-Arbeitsbereichs
- Hochladen vorhandener Daten
- Erstellen eines Experiments
Sie können dieses Experiment dann nutzen, um in Teil 2 Modelle zu trainieren und diese dann in Teil 3 bereitzustellen.
Voraussetzungen
In diesem Tutorial wird vorausgesetzt, dass Sie Machine Learning Studio (klassisch) bereits mindestens einmal verwendet haben und über Grundkenntnisse in Bezug auf Machine Learning-Konzepte verfügen. Es wird aber nicht davon ausgegangen, dass Sie Experte in diesen Bereichen sind.
Wenn Sie Machine Learning Studio (Classic) zuvor noch nicht verwendet haben, sollten Sie mit der Schnellstartanleitung Erstellen Ihres ersten Data Science-Experiments in Machine Learning Studio (Classic) beginnen. In dieser Schnellstartanleitung wird die erstmalige Verwendung von Machine Learning Studio (klassisch) Schritt für Schritt beschrieben. Es vermittelt die Grundlagen, wie Sie Module per Drag & Drop in Ihr Experiment aufnehmen, sie miteinander verbinden, das Experiment ausführen und die Ergebnisse anzeigen.
Tipp
Eine Arbeitskopie des Experiments, das Sie in diesem Tutorial entwickeln, finden Sie im Azure KI-Katalog. Navigieren Sie zu Tutorial – Predict credit risk (Tutorial: Vorhersagen des Kreditrisikos), und klicken Sie auf Open in Studio (In Studio öffnen), um eine Kopie des Experiments in Ihren Arbeitsbereich von Machine Learning Studio (klassisch) herunterzuladen.
Erstellen eines (klassischen) Machine Learning Studio-Arbeitsbereichs
Um Machine Learning Studio (Classic) verwenden zu können, benötigen Sie einen Machine Learning Studio (Classic)-Arbeitsbereich. Dieser Arbeitsbereich enthält die Tools, die zum Erstellen, Verwalten und Veröffentlichen von Experimenten erforderlich sind.
Informationen zum Erstellen eines Arbeitsbereichs finden Sie unter Erstellen und Freigeben eines Machine Learning Studio-Arbeitsbereichs (Classic).
Nachdem Ihr Arbeitsbereich erstellt wurde, öffnen Sie Machine Learning Studio (klassisch) unter https://studio.azureml.net/Home. Wenn Sie über mehrere Arbeitsbereiche verfügen, können Sie den Arbeitsbereich im Fenster oben rechts auf der Symbolleiste auswählen.
Tipp
Wenn Sie der Besitzer des Arbeitsbereichs sind, können Sie die Experimente, an denen Sie arbeiten, mit anderen Personen teilen. Laden Sie diese Personen hierfür in den Arbeitsbereich ein. Dies können Sie in Machine Learning Studio (klassisch) auf der Seite EINSTELLUNGEN vornehmen. Sie benötigen nur das Microsoft-Konto oder Organisationskonto des betreffenden Benutzers.
Klicken Sie auf der Seite EINSTELLUNGEN auf BENUTZER und dann unten in Fenster auf INVITE MORE USERS (WEITERE BENUTZER EINLADEN).
Hochladen vorhandener Daten
Um ein Vorhersagemodell für Kreditrisiken zu entwickeln, benötigen Sie Daten, die Sie zum Trainieren und anschließenden Testen des Modells verwenden können. In diesem Tutorial verwenden Sie den Datensatz „UCI Statlog (German Credit Data)“ aus dem UC Irvine Machine Learning-Repository. Sie finden den Datensatz unter folgender URL:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Sie verwenden die Datei mit dem Namen german.data. Laden Sie die Datei auf Ihre lokale Festplatte herunter.
Das Dataset german.data enthält Zeilen mit 20 Variablen für 1.000 Kreditantragsteller aus der Vergangenheit. Diese 20 Variablen stellen den Featuresatz (Featurevektor) des Datasets dar, der Identifikationseigenschaften für die einzelnen Kreditantragsteller enthält. Eine zusätzliche Spalte in jeder Zeile enthält das berechnete Kreditrisiko der Antragsteller. 700 der Antragsteller wurden mit niedrigem Risiko klassifiziert und 300 mit hohem Risiko.
Auf der UCI-Website finden Sie eine Beschreibung der Attribute des Funktionsvektors für diese Daten. Diese Daten umfassen beispielsweise Finanzinformationen, Bonitätsgeschichte, Beschäftigungsstatus und persönliche Daten. Für jeden Antragsteller wurde eine binäre Bewertung vergeben, um zwischen niedrigem und hohem Kreditrisiko zu unterscheiden.
Sie trainieren ein Vorhersageanalytikmodell anhand dieser Daten. Anschließend sollte Ihr Modell einen Funktionsvektor für neue Personen akzeptieren und vorhersagen können, ob diese ein niedriges oder hohes Kreditrisiko darstellen.
Hier ein interessantes Extra.
In der Beschreibung des Datasets auf der UCI-Website wird auf die Kosten einer Fehlklassifizierung des Kreditrisikos einer Person hingewiesen. Wenn mit dem Modell ein hohes Kreditrisiko für eine Person vorhergesagt wird, die eigentlich ein niedriges Kreditrisiko aufweist, liegt eine Fehlklassifizierung des Modells vor.
Die umgekehrte Fehlklassifizierung, d.h. die Vorhersage eines niedrigen Kreditrisikos für eine Person, die eigentlich ein hohes Kreditrisiko aufweist, ist jedoch fünfmal so teuer für die Finanzinstitution.
Ihr Modell sollte daher so trainiert werden, dass die Kosten dieser letzteren Fehlklassifizierung fünfmal höher als die der Fehlklassifizierung in der anderen Richtung ausfallen.
Dies kann beim Trainieren des Modells in Ihrem Experiment auf einfache Weise berücksichtigt werden, indem die entsprechenden Einträge von Personen mit einem hohen Kreditrisiko (fünffach) dupliziert werden.
Wenn mit dem Modell eine Person dann fälschlicherweise als Person mit einem niedrigen Kreditrisiko klassifiziert wird, wird diese Fehlklassifizierung im Modell fünfmal ausgeführt, d.h. einmal pro Duplikat. Auf diese Weise werden die Kosten für diesen Fehler in den Trainingsergebnissen erhöht.
Konvertieren des Datensatzformats
Der Originaldatensatz verwendet ein Format mit Trennung durch Leerzeichen. Machine Learning Studio (klassisch) funktioniert besser mit durch Trennzeichen getrennten Dateien (CSV). Daher konvertieren Sie den Datensatz, indem Sie die Leerzeichen durch Kommas ersetzen.
Es gibt viele Möglichkeiten zum Konvertieren dieser Daten. Eine ist die Verwendung des folgenden Windows PowerShell-Befehls:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Eine andere ist die Verwendung des sed-Befehls unter Unix:
sed 's/ /,/g' german.data > german.csv
In beiden Fällen haben Sie eine durch Kommas getrennte Version der Daten in der Datei german.csv erstellt, die Sie in Ihrem Experiment verwenden können.
Hochladen des Datasets in Machine Learning Studio (klassisch)
Nach dem Konvertieren der Daten in das CSV-Format müssen Sie sie in Machine Learning Studio (klassisch) hochladen.
Öffnen Sie die Startseite von Machine Learning Studio (klassisch) unter https://studio.azureml.net.
Klicken Sie in der oberen linken Ecke des Fensters auf das Menü
 , klicken Sie auf Azure Machine Learning, wählen Sie Studio aus, und melden Sie sich an.
, klicken Sie auf Azure Machine Learning, wählen Sie Studio aus, und melden Sie sich an.Klicken Sie im unteren Seitenbereich auf +NEU .
Wählen Sie DATASET.
Klicken Sie auf AUS LOKALER DATEI.
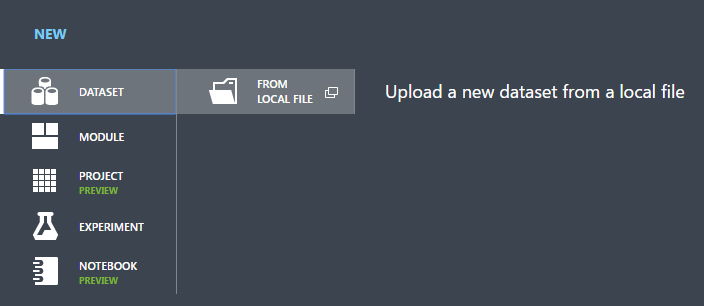
Klicken Sie im Dialogfeld Neuen Datensatz hochladen auf „Durchsuchen“, und suchen Sie nach der zuvor erstellten Datei german.csv.
Geben Sie einen Namen für das Dataset ein. Nennen Sie es in diesem Tutorial „UCI German Credit Card Data“.
Wählen Sie den Datentyp Generic CSV File With no header (.nh.csv)aus.
Fügen Sie bei Bedarf eine Beschreibung hinzu.
Klicken Sie auf das Häkchen OK.
Daraufhin werden die Daten in ein Datasetmodul hochgeladen, das Sie in einem Experiment verwenden können.
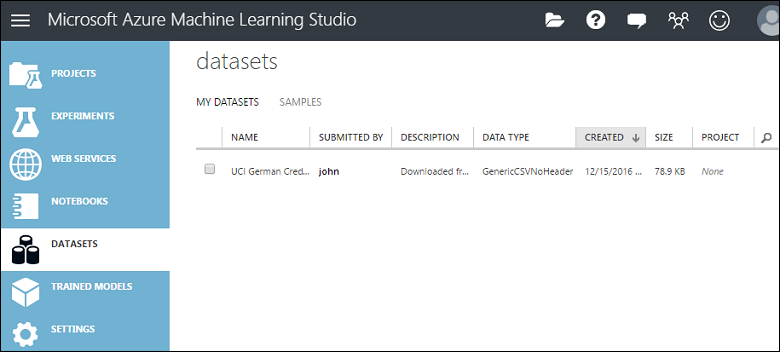
Zum Verwalten von Datasets, die Sie in Studio (klassisch) hochgeladen haben, klicken Sie auf der linken Seite des Fensters von Studio (klassisch) auf die Registerkarte DATASETS.
Weitere Informationen zum Importieren anderer Datentypen in ein Experiment finden Sie unter Importieren von Trainingsdaten in Machine Learning Studio (Classic).
Erstellen eines Experiments
Der nächste Schritt in diesem Tutorial ist die Erstellung eines Experiments in Machine Learning Studio (klassisch), in dem das von Ihnen hochgeladene Dataset verwendet wird.
Klicken Sie in Studio (klassisch) unten auf der Seite auf +NEW.
Wählen Sie EXPERIMENTund anschließend "Blank Experiment" aus.
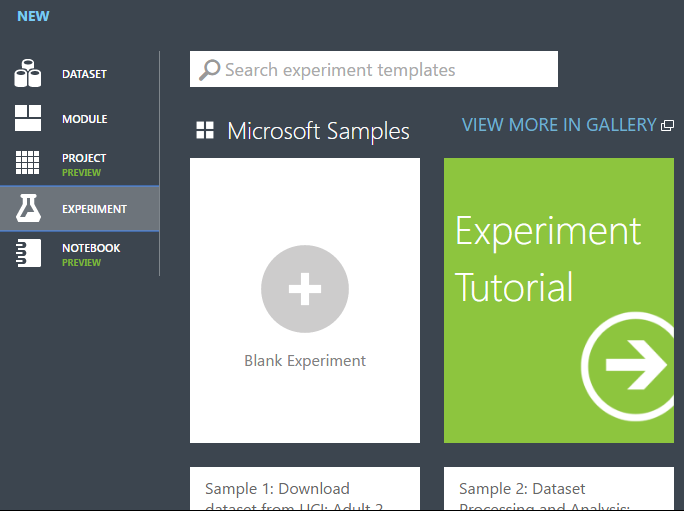
Wählen Sie oben in der Canvas den Namen des Standardexperiments aus, und geben Sie einen aussagekräftigen Namen ein.

Tipp
Es ist eine bewährte Methode, die Felder Summary und Description für das Experiment im Bereich Properties auszufüllen. Diese Eigenschaften geben Ihnen die Möglichkeit, das Experiment zu dokumentieren. Wenn Benutzer später darauf zugreifen, können sie Ihre Ziele und die Methodik verstehen.

Erweitern Sie in der Modulpalette links vom Experimentbereich Gespeicherte Datasets.
Suchen Sie das Dataset, das Sie unter Meine Datasets erstellt haben, und ziehen Sie es in den Bereich. Sie können auch nach dem Dataset suchen, indem Sie den Namen in das Feld Suchen oberhalb der Palette eingeben.
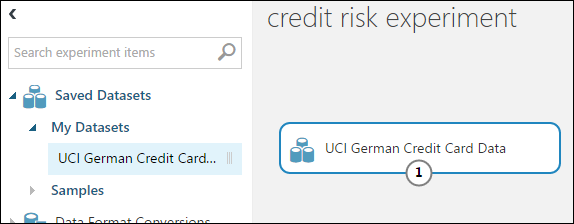
Vorbereiten der Daten
Sie können die ersten 100 Datenzeilen sowie einige statistische Informationen für das ganze Dataset anzeigen: Klicken Sie hierzu auf den Ausgabeport des Datasets (den kleinen Kreis unten), und wählen Sie die Option Visualize.
Da die Datendatei keine Spaltenüberschriften aufweist, hat Studio (klassisch) allgemeine Überschriften (Col1, Col2 usw.) bereitgestellt. Aussagekräftige Überschriften haben keine Bedeutung für die Erstellung eines Modells, erleichtern aber die Arbeit mit den Daten im Experiment. Wenn Sie dieses Modell später in einem Webdienst veröffentlichen, kann der Benutzer des Diensts die Spalten anhand der Überschriften außerdem leichter identifizieren.
Verwenden Sie das Modul Edit Metadata, um Spaltenüberschriften hinzuzufügen.
Sie verwenden das Modul Edit Metadata zum Ändern der Metadaten, die einem Dataset zugeordnet sind. In diesem Fall nutzen Sie es, um aussagekräftigere Namen für die Spaltenüberschriften anzugeben.
Um Metadaten bearbeiten zu können, geben Sie zuerst an, welche Spalten geändert werden sollen (in diesem Fall alle).) Als Nächstes geben Sie die Aktion an, die für diese Spalten ausgeführt werden soll (in diesem Fall das Ändern von Spaltenüberschriften.)
Geben Sie in der Modulpalette „Metadaten“ in das Feld Suchen ein. Edit Metadata wird in der Modulliste angezeigt.
Klicken und ziehen Sie das Modul Edit Metadata in den Experimentbereich, und legen Sie es unter dem zuvor hinzugefügten Dataset ab.
Verbinden Sie das Dataset mit Edit Metadata: Klicken Sie auf den Ausgabeport des Datasets (den kleinen Kreis unten im Dataset), ziehen Sie ihn zum Eingabeport von Edit Metadata (den kleinen Kreis oben im Modul), und lassen Sie die Maustaste los. Das Dataset und das Modul bleiben verbunden, auch wenn Sie diese im Bereich verschieben.
Das Experiment sollte in etwa wie folgt aussehen:
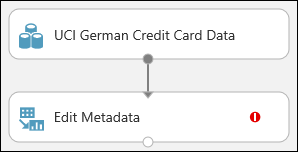
Das rote Ausrufezeichen gibt an, dass Sie die Eigenschaften für dieses Modul noch nicht festgelegt haben. Das machen Sie als Nächstes.
Tipp
Sie können einen Kommentar zu einem Modul eingeben, indem Sie auf das Modul doppelklicken und Text eingeben. Auf diese Weise können Sie mit einem Blick sehen, welche Funktion das Modul in Ihrem Experiment erfüllt. Doppelklicken Sie hierfür auf das Modul Edit Metadata, und geben Sie den Kommentar „Spaltenüberschriften hinzufügen“ ein. Klicken Sie auf eine Stelle des Experimentbereichs, um das Textfeld zu schließen. Klicken Sie auf den nach unten zeigenden Pfeil für das Modul, um den Kommentar anzuzeigen.
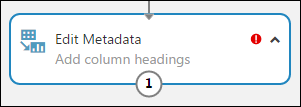
Wählen Sie Edit Metadata aus, und klicken Sie im Bereich Properties rechts neben dem Experimentbereich auf Launch column selector.
Wählen Sie im Dialogfeld Select columns in Available Columns alle Zeilen aus, und klicken Sie auf >, um sie in Selected Columns zu verschieben. Das Dialogfeld sollte wie folgt aussehen:
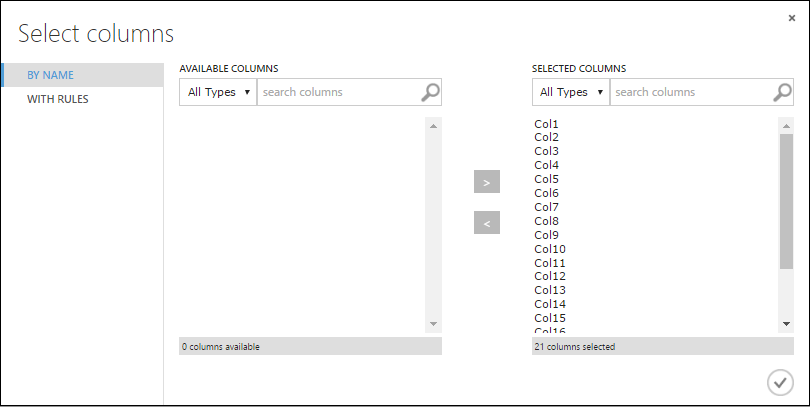
Klicken Sie auf das Häkchen OK.
Suchen Sie im Bereich Properties nach dem Parameter New column name. Geben Sie in diesem Feld eine Liste der Namen für die 21 Spalten im Dataset ein, durch Kommas getrennt und in der Reihenfolge der Spalten. Die Spaltennamen können Sie der Datasetdokumentation auf der UCI-Website entnehmen, oder Sie können einfach die folgende Liste kopieren und einfügen:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskDer Bereich „Eigenschaften“ sieht wie folgt aus:
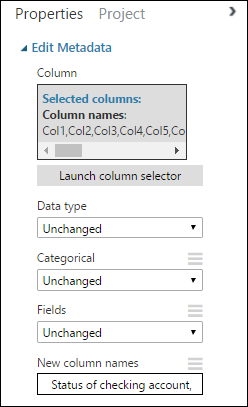
Tipp
Wenn Sie die Spaltenüberschriften überprüfen möchten, führen Sie das Experiment aus (klicken Sie unter dem Experimentbereich auf RUN ). Wenn die Ausführung abgeschlossen ist (in Edit Metadata wird ein grünes Häkchen angezeigt), klicken Sie auf den Ausgabeport des Moduls Edit Metadata, und wählen Sie Visualize aus. Auf die gleiche Weise können Sie die Ausgabe jedes anderen Moduls anzeigen, um den Datenfortschritt im Experiment zu sehen.
Erstellen von Trainings- und Testdatasets
Sie benötigen Daten zum Trainieren des Modells und Daten zum Testen des Modells. Daher unterteilen Sie das Dataset im nächsten Schritt des Experiments in zwei separate Datasets: eines zum Trainieren und das andere zum Testen des Modells.
Hierfür verwenden Sie das Modul Split Data.
Wechseln Sie zum Modul Split Data, ziehen Sie es in den Experimentbereich, und verbinden Sie es mit dem Modul Edit Metadata.
Standardmäßig beträgt das Aufteilungsverhältnis 0,5, und der Parameter Zufällige Aufteilung ist festgelegt. Dies bedeutet, dass eine zufällig ausgewählte Hälfte der Daten über einen Port des Moduls Split Data und die andere Hälfte über den anderen Port ausgegeben wird. Sie können diese Parameter und den Parameter Random seed anpassen, um die Aufteilung zwischen Trainings- und Bewertungsdaten zu ändern. Für dieses Beispiel lassen Sie die Werte unverändert.
Tipp
Die Eigenschaft Fraction of rows in the first output dataset bestimmt, welcher Anteil der Daten über den linken Ausgabeport ausgegeben wird. Wenn Sie z. B. ein Aufteilungsverhältnis von 0,7 festlegen, werden 70 % der Daten über den linken Port und 30 % der Daten über den rechten Port ausgegeben.
Doppelklicken Sie auf das Modul Split Data, und geben Sie den Kommentar „Aufteilung zwischen Trainings- und Testdaten 50 %“ ein.
Sie können die Ausgaben des Moduls Split Data beliebig verwenden. In diesem Fall wählen wir die linke Ausgabe als Trainingsdaten und die rechte Ausgabe als Testdaten.
Wie im vorherigen Schritt erwähnt, sind die Kosten einer Fehlklassifizierung eines hohen Kreditrisikos als niedriges Risiko fünfmal höher als die Kosten einer Fehlklassifizierung eines niedrigen Kreditrisikos als hohes Risiko. Um dies zu berücksichtigen, generieren Sie ein neues Dataset, das diese Kostenfunktion darstellt. Im neuen Dataset wird jedes Hochrisikobeispiel fünfmal repliziert, während keines der Niedrigrisikobeispiele repliziert wird.
Für diese Replikation können Sie den R-Code verwenden:
Suchen Sie nach dem Modul Execute R Script, und ziehen Sie es in den Experimentbereich.
Verbinden Sie den linken Ausgabeport des Moduls Split Data mit dem ersten Eingabeport („Dataset1“) des Moduls Execute R Script.
Doppelklicken Sie auf das Modul Execute R Script, und geben Sie den Kommentar „Kostenanpassung festlegen“ ein.
Löschen Sie im Bereich mit den Eigenschaften den Standardtext im Parameter R Script, und geben Sie dieses Skript ein:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")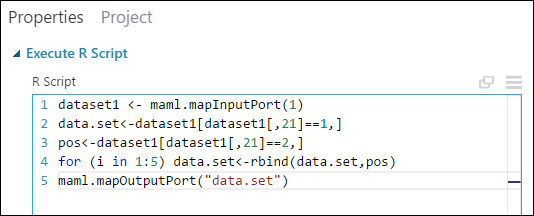
Sie müssen den gleichen Replikationsvorgang für jede Ausgabe des Moduls Split Data durchführen, damit die Trainings- und die Testdaten die gleiche Kostenanpassung aufweisen. Dies erfolgt am einfachsten durch das Duplizieren des eben erstellten Moduls Execute R Script und das Verbinden dieses Moduls mit dem anderen Ausgabeport des Moduls Split Data.
Klicken Sie mit der rechten Maustaste auf das Modul Execute R Script, und wählen Sie die Option Kopieren aus.
Klicken Sie mit der rechten Maustaste in den Experimentbereich, und wählen Sie Einfügenaus.
Ziehen Sie das neue Modul an die richtige Position, und verbinden Sie den rechten Ausgabeport des Moduls Split Data dann mit dem ersten Eingabeport des neuen Moduls Execute R Script.
Klicken Sie am unteren Rand des Experimentbereichs auf Run.
Tipp
Die Kopie des Moduls "Execute R Script" enthält das gleiche Skript wie das Originalmodul. Wenn Sie ein Modul kopieren und im Bereich einfügen, behält die Kopie alle Eigenschaften des Originals bei.
Unser Experiment sieht nun in etwa wie folgt aus:
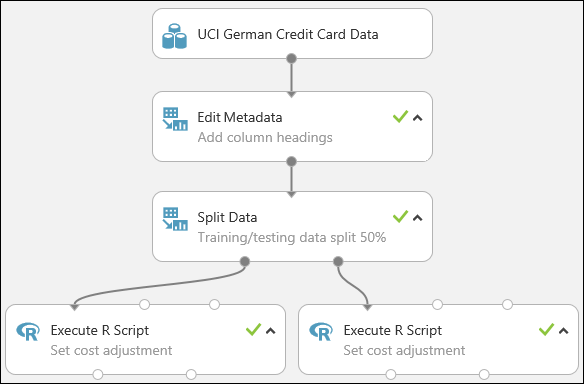
Weitere Informationen zum Verwenden von R-Skripts in Ihren Experimenten finden Sie unter Erweitern Sie Ihr Experiment mit R.
Bereinigen von Ressourcen
Wenn Sie die in diesem Artikel erstellten Ressourcen nicht mehr benötigen, löschen Sie sie, um eventuell anfallende Kosten zu vermeiden. Informationen dazu finden Sie im Artikel Exportieren und Löschen von im Produkt enthaltenen Benutzerdaten.
Nächste Schritte
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Erstellen eines (klassischen) Machine Learning Studio-Arbeitsbereichs
- Hochladen vorhandener Daten in den Arbeitsbereich
- Erstellen eines Experiments
Sie können jetzt Modelle für diese Daten trainieren und bewerten.