Vergleich von Deep Learning und Machine Learning in Azure Machine Learning
Dieser Artikel enthält einen Vergleich von Deep Learning und Machine Learning sowie eine Beschreibung, wie dies mit dem weiteren Feld der künstlichen Intelligenz zusammenhängt. Informieren Sie sich über Deep Learning-Lösungen, die Sie unter Azure Machine Learning erstellen können, z. B. Betrugserkennung, Sprach- und Gesichtserkennung, Standpunktanalyse und Zeitreihenvorhersagen.
Eine Anleitung zur Auswahl von Algorithmen für Ihre Lösungen finden Sie unter Spickzettel für Machine Learning-Algorithmen.
Foundation-Modelle in Azure Machine Learning sind vorab trainierte Deep Learning-Modelle, die für bestimmte Anwendungsfälle optimiert werden können. Erfahren Sie mehr über Foundation-Modelle (Vorschau) in Azure Machine Learning und die Verwendung von Foundation-Modellen in Azure Machine Learning (Vorschau).
Deep Learning, maschinelles Lernen und KI
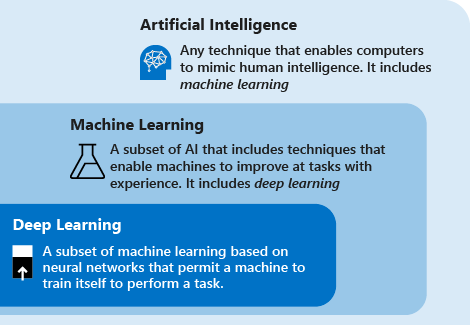
Beachten Sie die folgenden Definitionen, um Deep Learning im Vergleich zu maschinellem Lernen und KI zu verstehen:
Deep Learning ist ein Teilbereich des maschinellen Lernens und basiert auf künstlichen neuronalen Netzen. Der Lernprozess wird als Deep Learning bezeichnet, da die Struktur von künstlichen neuronalen Netzen aus mehreren Eingabe-, Ausgabe-und verborgenen Schichten besteht. Jede Schicht enthält Einheiten, die die Eingabedaten in Informationen transformieren, damit sie von der nächsten Schicht zum Ausführen einer bestimmten Vorhersageaufgabe verwenden können. Dank dieser Struktur kann ein Computer durch seine eigene Datenverarbeitung lernen.
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz, der Techniken (z.B Deep Learning) umfasst, über die Computer sich beim Lösen von Aufgaben durch Erfahrung verbessern können. Der Lernprozess basiert auf den folgenden Schritten:
- Einspeisen von Daten in einen Algorithmus. (In diesem Schritt können Sie zusätzliche Informationen für das Modell bereitstellen, z.B. durch Durchführen einer Merkmalsextraktion.)
- Verwenden dieser Daten zum Trainieren eines Modells
- Testen und Bereitstellen des Modells
- Nutzen des bereitgestellten Modells zum Ausführen einer automatisierten Vorhersageaufgabe. (Mit anderen Worten: Aufrufen und Verwenden des bereitgestellten Modells, um die vom Modell zurückgegebenen Vorhersagen zu empfangen.)
Künstliche Intelligenz (KI) ist ein Verfahren, mit dem Computer menschliche Intelligenz imitieren können. Sie umfasst auch maschinelles Lernen.
Generative KI ist eine Teilmenge der künstlichen Intelligenz, die Techniken (z. B. Deep Learning) zum Generieren neuer Inhalte verwendet. Sie können beispielsweise generative KI verwenden, um Bilder, Text- oder Audiodateien zu erstellen. Diese Modelle nutzen zum Generieren dieser Inhalte umfangreiches vortrainiertes Wissen.
Mithilfe von Machine Learning- und Deep Learning-Techniken können Sie Computersysteme und Anwendungen erstellen, die Aufgaben erledigen, die in der Regel mit menschlicher Intelligenz verbunden werden. Zu diesen Aufgaben gehören Bilderkennung, Spracherkennung und Sprachübersetzung.
Techniken von Deep Learning und maschinellem Lernen
Nachdem Sie sich einen Überblick über maschinelles Lernen und Deep Learning verschafft haben, können wir die beiden Verfahren vergleichen. Beim maschinellen Lernen muss dem Algorithmus mitgeteilt werden, wie er eine genaue Vorhersage treffen kann, indem er zusätzliche Informationen nutzt (z.B. durch Merkmalsextraktion). Beim Deep Learning kann der Algorithmus dank der künstlichen neuronalen Netzstruktur durch eigene Datenverarbeitung lernen, wie eine genaue Vorhersage getroffen werden kann.
In der folgenden Tabelle werden die beiden Verfahren ausführlicher verglichen:
| Vollständig Machine Learning | Nur Deep Learning | |
|---|---|---|
| Anzahl von Datenpunkten | Kann mithilfe kleiner Datenmengen Vorhersagen treffen | Benötigt große Mengen von Trainingsdaten, um Vorhersagen zu treffen |
| Hardwareabhängigkeiten | Kann auf Low-End-Computern ausgeführt werden. Erfordert keine hohe Rechenleistung. | Hängt von High-End-Computern ab. Grundsätzlich wird eine große Zahl von Matrixmultiplikationsvorgängen durchgeführt. Eine GPU kann diese Vorgänge effizient optimieren. |
| Featurebereitstellung | Merkmale müssen von Benutzern genau identifiziert und erstellt werden. | Lernt allgemeine Merkmale aus Daten und erstellt selbstständig neue Merkmale. |
| Lernansatz | Unterteilt den Lernprozess in kleinere Schritte. Anschließend werden die Ergebnisse aus den einzelnen Schritten in einer Ausgabe zusammengefasst. | Durchläuft den Lernprozess durch Lösen des Problems auf Gesamtbasis. |
| Ausführungszeit | Das Training nimmt im Vergleich weniger Zeit in Anspruch: von wenigen Sekunden bis hin zu einigen Stunden. | Das Training dauert meist lange, da ein Deep Learning-Algorithmus viele Schichten aufweist. |
| Ausgabe | Die Ausgabe ist normalerweise ein numerischer Wert, z.B. eine Bewertung oder Klassifizierung. | Die Ausgabe kann mehrere Formate aufweisen, z. B. einen Text, eine Bewertung oder eine Tonausgabe. |
Was ist Übertragungslernen?
Das Training von Deep Learning-Modellen erfordert häufig große Mengen an Trainingsdaten, High-End-Computeressourcen (GPU, TPU) und eine längere Trainingszeit. Wenn diese Voraussetzungen in Ihren Szenarien nicht erfüllt sind, können Sie den Trainingsprozess mithilfe eines als Lerntransfer (Transfer Learning) bezeichneten Verfahrens verkürzen.
Lerntransfer ist ein Verfahren, bei dem das bei der Lösung eines Problems gewonnene Wissen auf ein anderes, aber verwandtes Problem angewandt wird.
Aufgrund der Struktur neuronaler Netze enthalten die ersten Ebenen in der Regel Features der unteren Ebenen, während die letzten Ebenen Features der höheren Ebenen enthalten, die näher an der fraglichen Domäne sind. Wenn Sie die letzten Ebenen für die Verwendung in einer neuen Domäne oder einem neuen Problem umwidmen, können Sie die Zeit, die Daten und die Computeressourcen zum Trainieren des neuen Modells deutlich reduzieren. Wenn Sie z. B. bereits über ein Modell verfügen, mit dem Autos erkannt werden, können Sie dieses Modell durch einen Lerntransfer auch für die Erkennung von Lkw, Motorrädern und andere Fahrzeugtypen verwenden.
Informieren Sie sich über die Anwendung eines Lerntransfers auf die Bildklassifizierung mithilfe eines Open-Source-Frameworks in Azure Machine Learning: Bedarfsgerechtes Trainieren von PyTorch-Modellen mit Azure Machine Learning.
Anwendungsfälle für Deep Learning
Aufgrund der Struktur des künstlichen neuronalen Netzes zeichnet sich Deep Learning dadurch aus, dass Muster in unstrukturierten Daten identifiziert werden, z.B. Bilder, Sound, Video und Text. Aus diesem Grund verändert Deep Learning schnell viele Branchen, darunter Gesundheitswesen, Energie, Finanzwesen und Transportwesen. Diese Branchen überdenken jetzt traditionelle Geschäftsprozesse.
Einige der häufigsten Anwendungen für Deep Learning werden in den folgenden Abschnitten beschrieben. In Azure Machine Learning können Sie ein Modell verwenden, das Sie aus einem Open-Source-Framework erstellt haben, oder das Modell mit den bereitgestellten Tools erstellen.
Named-entity recognition (NER)
Named-entity recognition (Erkennung benannter Entitäten) ist eine Deep Learning-Methode, die einen Text als Eingabe entgegennimmt und in eine vordefinierte Klasse umwandelt. Diese neue Angabe kann etwa eine Postleitzahl, ein Datum oder eine Produkt-ID sein. Die Informationen können dann in einem strukturierten Schema gespeichert werden, um eine Liste von Adressen zu erstellen oder als Benchmark für eine Engine zur Identitätsüberprüfung verwendet zu werden.
Objekterkennung
Deep Learning wird in vielen Anwendungsfällen zur Objekterkennung angewandt. Die Objekterkennung wird verwendet, um Objekte in einem Bild zu identifizieren (z. B. Autos oder Personen) und die genaue Position der einzelnen Objekte mit einem Begrenzungsrahmen anzugeben.
Objekterkennung wird bereits in Branchen wie Gaming, Einzelhandel, Tourismus und selbstfahrenden Autos eingesetzt.
Generierung der Bildbeschriftung
Wie bei der Bilderkennung muss bei der Bildbeschriftung im System für ein bestimmtes Bild eine Beschriftung generiert werden, die den Inhalt des Bilds beschreibt. Wenn Sie Objekte in Fotos erkennen und bezeichnen können, besteht der nächste Schritt darin, diese Bezeichnungen in beschreibende Sätze umzuwandeln.
Im Allgemeinen verwenden Bildbeschriftungsanwendungen Convolutional Neural Networks, um Objekte auf den Fotos zu erkennen, und dann ein Recurrent Neural Network, um die Bezeichnungen in zusammenhängende Sätze umzuwandeln.
Maschinelle Übersetzung
Bei der maschinellen Übersetzung werden Wörter oder Sätze aus einer Sprache automatisch in eine andere Sprache übersetzt. Die maschinelle Übersetzung gibt es schon seit geraumer Zeit, mit Deep Learning werden jedoch beeindruckende Ergebnisse in zwei bestimmten Bereichen erzielt: bei der automatischen Übersetzung von Text (und Spracherkennung) sowie bei der automatischen Übersetzung von Bildern.
Mit der richtigen Datentransformation kann ein neuronales Netz Text-, Audio- und visuelle Signale verstehen. Die maschinelle Übersetzung kann verwendet werden, um Tonausschnitte in größeren Audiodateien zu identifizieren und gesprochenen Text oder Bilder in Text zu transkribieren.
Textanalyse
Die auf Deep Learning-Methoden basierende Textanalyse umfasst das Analysieren großer Mengen von Textdaten (z. B. medizinischen Dokumenten oder Ausgabenbelegen), das Erkennen von Mustern und das Erstellen von organisierten und präzisen Informationen aus diesen.
Unternehmen führen mit Deep Learning Textanalysen durch, um Insidergeschäfte zu erkennen und die Einhaltung gesetzlicher Vorschriften zu gewährleisten. Ein weiteres gängiges Beispiel ist Versicherungsbetrug: Mithilfe von Textanalysen wurden häufig große Mengen von Dokumenten analysiert, um zu ermitteln, mit welcher Wahrscheinlichkeit es sich bei einem Versicherungsanspruch um Betrug handelte.
Künstliche neuronale Netze
Künstliche neuronale Netze setzen sich aus Ebenen verbundener Knoten zusammen. Deep Learning-Modelle verwenden neuronale Netze mit einer sehr großen Anzahl von Schichten.
In den folgenden Abschnitten werden die gängigsten Topologien für künstliche neuronale Netze vorgestellt.
Neuronales feedforward-Netz
Das neuronale Feedforward-Netz ist die einfachste Art von künstlichen neuronalen Netzen. In einem Feedforward-Netz werden Informationen nur in einer Richtung von der Eingabeschicht an die Ausgabeschicht übertragen. In neuronalen feedforward-Netzen werden Eingaben transformiert, indem sie eine Reihe von Zwischenschichten durchlaufen. Jede Schicht besteht aus einer Reihe von Neuronen, wobei jede Schicht vollständig mit allen Neuronen in der vorherigen Schicht verbunden ist. Die letzte vollständig verbundene Schicht (die Ausgabeschicht) stellt die generierten Vorhersagen dar.
Recurrent Neural Network (RNN)
Recurrent Neural Networks sind häufig verwendete künstliche neuronale Netze. Diese Netze speichern die Ausgabe einer Schicht und geben Sie zurück in die Eingabeschicht, um das Ergebnis der Schicht vorherzusagen. Recurrent Neural Networks weisen großartige Lernmöglichkeiten auf. Sie werden häufig für komplexe Aufgaben wie Zeitreihenvorhersagen, das Erlernen von Handschrift und die Spracherkennung verwendet.
Convolutional Neural Network (CNN)
Ein Convolutional Neural Network (faltendes neuronales Netz, CNN) ist ein besonders effektives künstliches neuronales Netz und stellt eine einzigartige Architektur dar. Die Schichten sind in drei Dimensionen organisiert: Breite, Höhe und Tiefe. Die Neuronen in einer Schicht sind nicht mit allen Neuronen in der nächsten Schicht, sondern nur mit einem kleinen Bereich der Neuronen der Schicht verbunden. Die endgültige Ausgabe wird auf einen einzelnen Vektor mit Wahrscheinlichkeitsbewertungen reduziert, der entlang der Tiefendimension organisiert ist.
Convolutional Neural Networks wurden bereits in Bereichen wie Videoerkennung, Bilderkennung und Empfehlungssysteme verwendet.
Generative Adversarial Network (GAN)
Generative Adversarial Networks (generierende gegnerische Netzwerke) sind generative Modelle, die darauf trainiert sind, realistische Inhalte wie z. B. Bilder zu erstellen. Sie besteht aus zwei Netzwerken, die als Generator und Diskriminator bezeichnet werden. Beide Netzwerke werden gleichzeitig trainiert. Während des Trainings verwendet der Generator Zufallsrauschen, um neue synthetische Daten zu erstellen, die echten Daten sehr ähnlich sind. Der Diskriminator nimmt die Ausgabe des Generators als Eingabe und verwendet echte Daten, um zu bestimmen, ob der generierte Inhalt real oder synthetisch ist. Beide Netzwerke konkurrieren miteinander. Der Generator versucht, synthetische Inhalte zu generieren, die nicht von echten Inhalten zu unterscheiden sind, und der Diskriminator versucht, Eingaben ordnungsgemäß als real oder synthetisch zu klassifizieren. Die Ausgabe wird dann verwendet, um die Gewichtungen beider Netzwerke zu aktualisieren, damit sie ihre jeweiligen Ziele besser erreichen können.
Generative Adversarial Networks werden verwendet, um Probleme wie Bild-zu-Bild-Übersetzung und Altersverläufe zu lösen.
Transformatoren
Transformatoren sind eine Modellarchitektur, die sich zum Lösen von Problemen mit Sequenzen wie Text- oder Zeitreihendaten eignet. Sie bestehen aus Encoder- und Decoderebenen. Der Encoder nimmt eine Eingabe und ordnet sie einer numerischen Darstellung zu, die Informationen wie den Kontext enthält. Der Decoder verwendet Informationen vom Encoder, um eine Ausgabe zu erzeugen, z. B. übersetzten Text. Was Transformatoren von anderen Architekturen unterscheidet, die Encoder und Decoder enthalten, sind die untergeordneten Ebenen der Aufmerksamkeit. Als Aufmerksamkeit wird das Konzept bezeichnet, sich auf bestimmte Teile einer Eingabe basierend auf der Wichtigkeit ihres Kontexts im Vergleich zu anderen Eingaben in einer Sequenz zu konzentrieren. Wenn Sie beispielsweise einen Nachrichtenartikel zusammenfassen, sind nicht alle Sätze relevant, um die Kernaussage zu beschreiben. Durch die Konzentration auf Schlüsselwörter im gesamten Artikel kann die Zusammenfassung in einem einzigen Satz erfolgen, der Überschrift.
Transformatoren wurden verwendet, um Probleme bei der Verarbeitung natürlicher Sprache wie Übersetzung, Textgenerierung, Beantwortung von Fragen und Textzusammenfassung zu lösen.
Einige bekannte Implementierungen von Transformatoren sind:
- Bidirektionale Encoderdarstellungen von Transformatoren (Bidirectional Encoder Representations from Transformers, BERT)
- Generativer vortrainierter Transformator 2 (Generative Pre-trained Transformer 2, GPT-2)
- Generativer vortrainierter Transformator 3 (Generative Pre-trained Transformer 3, GPT-3)
Nächste Schritte
Die folgenden Artikel enthalten weitere Optionen zur Verwendung von Open-Source-Deep Learning-Modellen in Azure Machine Learning: