Verwenden von Open Source-Basismodellen, die von Azure Machine Learning kuratiert wurden
In diesem Artikel erfahren Sie, wie Sie Foundation-Modelle im Modellkatalog optimieren, auswerten und bereitstellen.
Sie können jedes vortrainierte Modell schnell testen, indem Sie das Formular für Stichprobenrückschlüsse auf der Modellkarte verwenden und Ihre eigenen Beispieleingaben zum Testen des Ergebnisses bereitstellen. Außerdem enthält die Modellkarte für jedes Modell eine kurze Beschreibung des Modells und Links zu Beispielen für codebasierte Rückschlüsse sowie für die Optimierung und Auswertung des Modells.
Auswerten von Basismodellen mit eigenen Testdaten
Sie können ein Basismodell für Ihr Testdataset mithilfe des Formulars zum Auswerten der Benutzeroberfläche oder mithilfe der codebasierten Stichproben auswerten, die über die Modellkarte verknüpft sind.
Auswerten mithilfe von Studio
Sie können das Modellformular „Auswerten“ aufrufen, indem Sie auf der Modellkarte eines beliebigen Basismodells die Schaltfläche Auswerten auswählen.
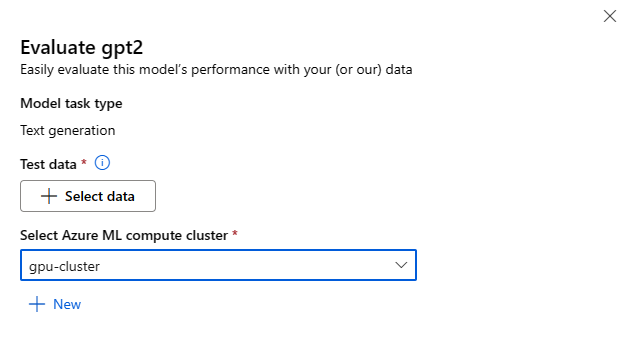
Jedes Modell kann hinsichtlich der spezifischen Rückschlussaufgabe ausgewertet werden, für die das Modell verwendet wird.
Testdaten:
- Übergeben Sie die Testdaten, die Sie zum Auswerten Ihres Modells verwenden möchten. Sie können entweder eine lokale Datei (im JSONL-Format) hochladen oder ein vorhandenes registriertes Dataset aus Ihrem Arbeitsbereich auswählen.
- Nachdem Sie das Dataset ausgewählt haben, müssen Sie die Spalten aus Ihren Eingabedaten auf der Grundlage des für die Aufgabe benötigten Schemas zuordnen. Ordnen Sie z. B. die Spaltennamen zu, die den Schlüsseln „Satz“ und „Bezeichnung“ für Textklassifizierung entsprechen.

Compute:
Geben Sie den Azure Machine Learning Compute-Cluster an, den Sie für die Optimierung des Modells verwenden möchten. Die Auswertung muss auf einer GPU-Compute-Instanz ausgeführt werden. Stellen Sie sicher, dass Sie über ein ausreichendes Computekontingent für die Compute-SKUs verfügen, die Sie verwenden möchten.
Wählen Sie im Formular für die Auswertung die Option Fertigstellen aus, um Ihren Auswertungsauftrag zu übermitteln. Nach Abschluss des Auftrags können Sie Auswertungsmetriken für das Modell anzeigen. Basierend auf den Auswertungsmetriken können Sie entscheiden, ob Sie das Modell mithilfe Ihrer eigenen Trainingsdaten optimieren möchten. Darüber hinaus können Sie entscheiden, ob Sie das Modell registrieren und an einem Endpunkt bereitstellen möchten.
Auswerten mithilfe von codebasierten Stichproben
Um Benutzern den Einstieg in die Modellauswertung zu erleichtern, haben wir Stichproben (sowohl Python-Notebooks als auch CLI-Stichproben) in den Auswertungsstichproben im Git-Repository „azureml-examples“ veröffentlicht. Jede Modellkarte enthält auch Links zu Auswertungsstichproben für die entsprechenden Aufgaben
Optimieren von Basismodellen mithilfe Ihrer eigenen Trainingsdaten
Um die Modellleistung in Ihrer Workload zu verbessern, sollten Sie ein Basismodell mithilfe Ihrer eigenen Trainingsdaten optimieren. Sie können diese Basismodelle entweder mithilfe der Einstellungen zum Optimieren in Studio oder mithilfe der verknüpften codebasierten Stichproben von der Modellkarte ganz einfach optimieren.
Optimierung mithilfe des Studios
Sie können das Formular mit den Optimierungseinstellungen aufrufen, indem Sie auf der Modellkarte eines beliebigen Basismodells auf die Schaltfläche Optimieren klicken.
Optimierungseinstellungen:
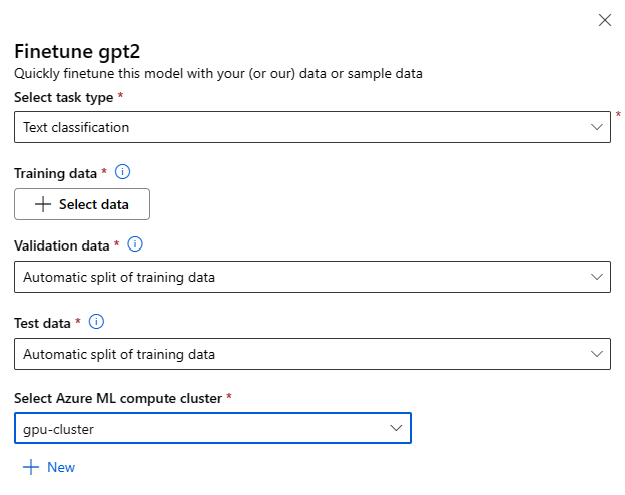
Typ der Optimierungsaufgabe
- Jedes vortrainierte Modell aus dem Modellkatalog kann für eine bestimmte Reihe von Aufgaben (z. B. Textklassifizierung, Tokenklassifizierung, Beantwortung von Fragen) optimiert werden. Wählen Sie in der Dropdownliste die Aufgabe aus, die Sie verwenden möchten.
Trainingsdaten
Übergeben Sie die Trainingsdaten, die Sie zum Optimieren Ihres Modells verwenden möchten. Sie können entweder eine lokale Datei (im JSONL-, CSV- oder TSV-Format) hochladen oder ein vorhandenes registriertes Dataset aus Ihrem Arbeitsbereich auswählen.
Nachdem Sie das Dataset ausgewählt haben, müssen Sie die Spalten aus Ihren Eingabedaten auf der Grundlage des für die Aufgabe benötigten Schemas zuordnen. Ordnen Sie z. B. die Spaltennamen zu, die den Schlüsseln „Satz“ und „Bezeichnung“ für Textklassifizierung entsprechen.

- Validierungsdaten: Übergeben Sie die Daten, die Sie zum Überprüfen Ihres Modells verwenden möchten. Wenn Sie Automatische Aufteilung auswählen, wird eine automatische Aufteilung der Trainingsdaten für die Validierung reserviert. Alternativ können Sie ein anderes Validierungsdataset bereitstellen.
- Testdaten: Übergeben Sie die Testdaten, die Sie zum Auswerten Ihres optimierten Modells verwenden möchten. Wenn Sie Automatische Aufteilung auswählen, wird eine automatische Aufteilung der Trainingsdaten für den Test reserviert.
- Compute: Geben Sie den Azure Machine Learning Compute-Cluster an, den Sie für die Optimierung des Modells verwenden möchten. Die Optimierung muss in der GPU-Compute-Instanz erfolgen. Bei der Optimierung wird empfohlen, Compute-SKUs mit A100/V100-GPUs zu verwenden. Stellen Sie sicher, dass Sie über ein ausreichendes Computekontingent für die Compute-SKUs verfügen, die Sie verwenden möchten.
- Wählen Sie im Formular für die Optimierung Fertig stellen aus, um Ihren Optimierungsauftrag zu übermitteln. Nach Abschluss des Auftrags können Sie Auswertungsmetriken für das optimierte Modell anzeigen. Anschließend können Sie das vom Optimierungsauftrag ausgegebene optimierte Modell registrieren und dieses Modell an einem Endpunkt für Rückschlüsse bereitstellen.
Optimieren mithilfe von codebasierten Stichproben
Derzeit unterstützt Azure Machine Learning die Optimierung von Modellen für die folgenden Sprachaufgaben:
- Textklassifizierung
- Tokenklassifizierung
- Fragen und Antworten
- Zusammenfassung
- Sprachübersetzung
Um Benutzer*innen einen schnellen Einstieg in die Optimierung zu ermöglichen, haben wir Stichproben (sowohl Python-Notebooks als auch CLI-Stichproben) für jede Aufgabe in Stichproben zur Optimierung im Git-Repository „azureml-examples“ veröffentlicht. Jede Modellkarte enthält auch Links zu Optimierungsstrichproben für unterstützte Optimierungsaufgaben.
Bereitstellen von Basismodellen für Rückschlussendpunkte
Sie können Basismodelle (sowohl vortrainierte Modelle aus dem Modellkatalog als auch optimierte Modelle, sobald sie in Ihrem Arbeitsbereich registriert sind) für einen Endpunkt bereitstellen, der dann für Rückschlüsse verwendet werden kann. Die Bereitstellung für Echtzeitendpunkte und Batchendpunkte wird unterstützt. Sie können diese Modelle entweder mithilfe des Assistenten für die Bereitstellung der Benutzeroberfläche oder mithilfe der von der Modellkarte verknüpften codebasierten Stichproben bereitstellen.
Bereitstellen mithilfe von Studio
Sie können das Formular „Benutzeroberfläche bereitstellen“ aufrufen, indem Sie die Schaltfläche Bereitstellen auf der Modellkarte eines beliebigen Basismodells auswählen und entweder den Echtzeitendpunkt oder Batchendpunkt auswählen

Bereitstellungseinstellungen
Da das Bewertungsskript und die Umgebung automatisch im Basismodell enthalten sind, müssen Sie nur die zu verwendende SKU für virtuelle Computer, die Anzahl der Instanzen und den Endpunktnamen für die Bereitstellung angeben.
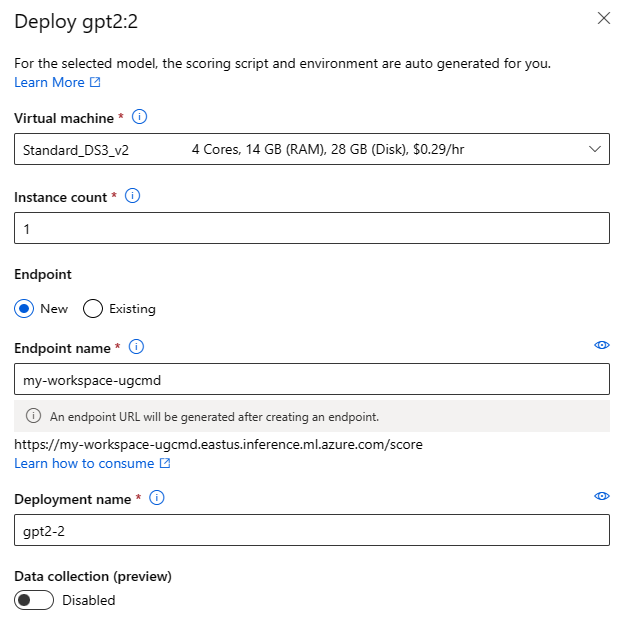
Freigegebenes Kontingent
Wenn Sie ein Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- oder Deci-DeciLM-Modell aus dem Modellkatalog bereitstellen, aber nicht über genügend Kontingent für die Bereitstellung verfügen, können Sie mit Azure Machine Learning Kontingent aus einem freigegebenen Kontingentpool für einen begrenzten Zeitraum verwenden. Weitere Informationen zum gemeinsamen Kontingent finden Sie unter Gemeinsames Kontingent für Azure Machine Learning.

Bereitstellen mithilfe von codebasierten Stichproben
Um Benutzern einen schnellen Einstieg in die Bereitstellung und den Rückschluss zu ermöglichen, haben wir Beispiele in den Stichproben zu Rückschlüssen im Git-Repository „azureml-examples“ veröffentlicht. Die veröffentlichten Stichproben umfassen Python-Notebooks und CLI-Stichproben. Jede Modellkarte enthält auch Links zu Stichproben für Echtzeit- und Batchrückschlüsse.
Importieren von Basismodellen
Wenn Sie ein Open Source-Modell verwenden möchten, das nicht im Modellkatalog enthalten ist, können Sie das Modell aus Hugging Face in Ihren Azure Machine Learning-Arbeitsbereich importieren. Hugging Face ist eine Open Source-Bibliothek für die linguistische Datenverarbeitung (Natural Language Processing, NLP), die vortrainierte Modelle für gängige NLP-Aufgaben bereitstellt. Derzeit unterstützt der Modellimport das Importieren von Modellen für die folgenden Aufgaben, sofern das Modell die im Notebook für den Modellimport aufgeführten Anforderungen erfüllt:
- Füllmaske
- Tokenklassifizierung
- Beantworten von Fragen
- Zusammenfassung
- Textgenerierung
- Textklassifizierung
- Verschiebung
- Bildklassifizierung
- Text-zu-Bild
Hinweis
Modelle von Hugging Face unterliegen den Lizenzbedingungen von Drittanbietern, die auf der Detailseite des Hugging Face-Modells verfügbar sind. Es liegt in Ihrer Verantwortung, die Lizenzbedingungen des Modells einzuhalten.
Sie können oben rechts im Modellkatalog die Schaltfläche Importieren auswählen, um das Notebook für den Modellimport zu verwenden.
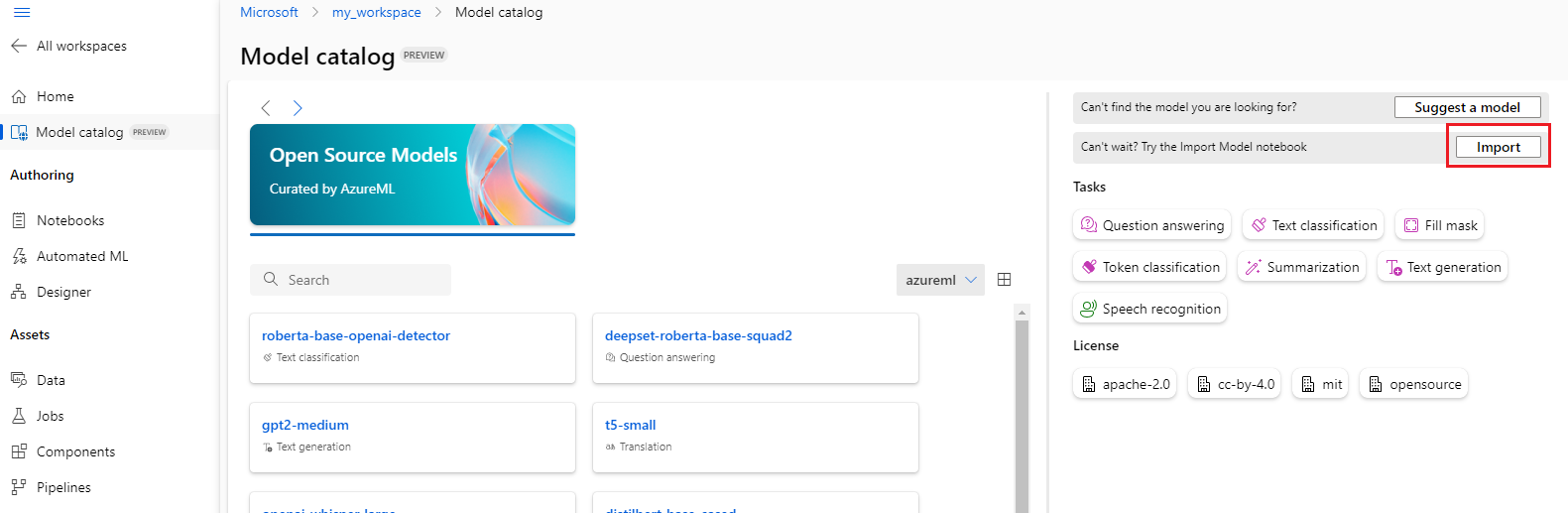
Das Notebook für den Modellimport ist auch hier im Git-Repository „azureml-examples“ enthalten.
Um das Modell zu importieren, müssen Sie die MODEL_ID des Modells angeben, das Sie aus Hugging Face importieren möchten. Durchsuchen Sie Modelle im Hugging Face-Hub, und identifizieren Sie das zu importierende Modell. Stellen Sie sicher, dass der Aufgabentyp des Modells zu den unterstützten Aufgabentypen gehört. Kopieren Sie die Modell-ID, die im URI der Seite verfügbar ist oder mithilfe des Kopiersymbols neben dem Modellnamen kopiert werden kann. Weisen Sie sie der Variablen „MODEL_ID“ im Notebook für den Modellimport zu. Beispiel:
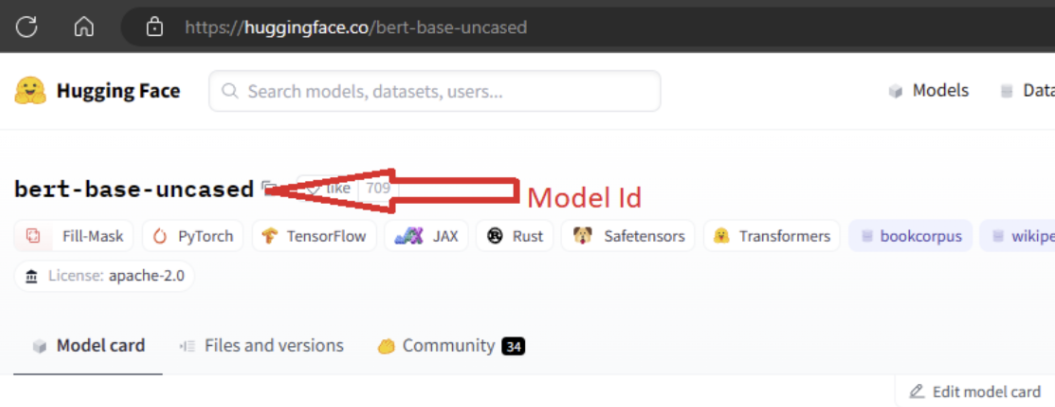
Sie müssen eine Compute-Instanz bereitstellen, damit der Modellimport ausgeführt werden kann. Das Ausführen des Modellimports führt dazu, dass das angegebene Modell aus Hugging Face importiert und in Ihrem Azure Machine Learning-Arbeitsbereich registriert wird. Anschließend können Sie dieses Modell optimieren oder es für Rückschlüsse auf einem Endpunkt bereitstellen.
Weitere Informationen
- Erkunden Sie den Modellkatalog in Azure Machine Learning Studio. Sie benötigen einen Azure Machine Learning-Arbeitsbereich, um den Katalog erkunden zu können.
- Erkunden des Modellkatalogs und von Sammlungen