Was ist Designer (v1) in Azure Machine Learning?
Der Azure Machine Learning-Designer ist eine Drag & Drop-Schnittstelle, die zum Trainieren und Bereitstellen von Modellen in Azure Machine Learning Studio verwendet wird. In diesem Artikel werden die Aufgaben beschrieben, die Sie im Designer ausführen können.
Wichtig
Designer in Azure Machine Learning unterstützt zwei Typen von Pipelines, die klassische vorgefertigte (v1) oder benutzerdefinierte (v2) Komponenten verwenden. Die beiden Komponententypen sind innerhalb von Pipelines nicht kompatibel, und Designer v1 ist nicht mit CLI v2 und SDK v2 kompatibel. Dieser Artikel gilt für Pipelines, die klassische vorgefertigte (v1) Komponenten verwenden.
Klassische vorgefertigte Komponenten (v1) umfassen typische Aufgaben der Datenverarbeitung und des maschinellen Lernens wie beispielsweise Regression und Klassifizierung. Azure Machine Learning unterstützt weiterhin die vorhandenen klassischen vorgefertigten Komponenten, aber es werden keine neuen vorgefertigten Komponenten hinzugefügt. Außerdem unterstützt die Bereitstellung von klassischen vordefinierten Komponenten (v1) keine verwalteten Onlineendpunkte (v2).
Mit benutzerdefinierten Komponenten (v2) können Sie Ihren eigenen Code als Komponente umschließen und so die gemeinsame Nutzung von Arbeitsbereichen und die nahtlose Erstellung über die Schnittstellen von Azure Machine Learning Studio, CLI v2 und SDK v2 ermöglichen. Am besten werden benutzerdefinierte Komponenten für neue Projekte verwendet, da sie mit Azure Machine Learning v2 kompatibel sind und weiterhin neue Updates erhalten. Weitere Informationen zu benutzerdefinierten Komponenten und Designer (v2) finden Sie unter Azure Machine Learning-Designer (v2).
Das folgende animierte GIF zeigt, wie Sie eine Pipeline im Designer visuell erstellen können, indem Sie Ressourcen ziehen und ablegen und sie verbinden.

Informationen zu den im Designer verfügbaren Komponenten finden Sie in der Referenz zu Algorithmen und Komponenten. Informationen zu den ersten Schritten mit dem Designer finden Sie unter Tutorial: Trainieren eines Regressionsmodells ohne Code.
Trainieren und Bereitstellen des Modells
Der Designer verwendet Ihren Azure Machine Learning-Arbeitsbereich, um gemeinsame Ressourcen wie die folgenden zu organisieren:
- Pipelines
- Daten
- Computeressourcen
- Registrierte Modelle
- Veröffentlichte Pipelineaufträge
- Echtzeitendpunkte
Das folgende Diagramm veranschaulicht, wie Sie den Designer verwenden können, um einen End-to-End-Workflow für maschinelles Lernen zu erstellen. Sie können Modelle trainieren, testen und bereitstellen, alles in der Designer-Schnittstelle.
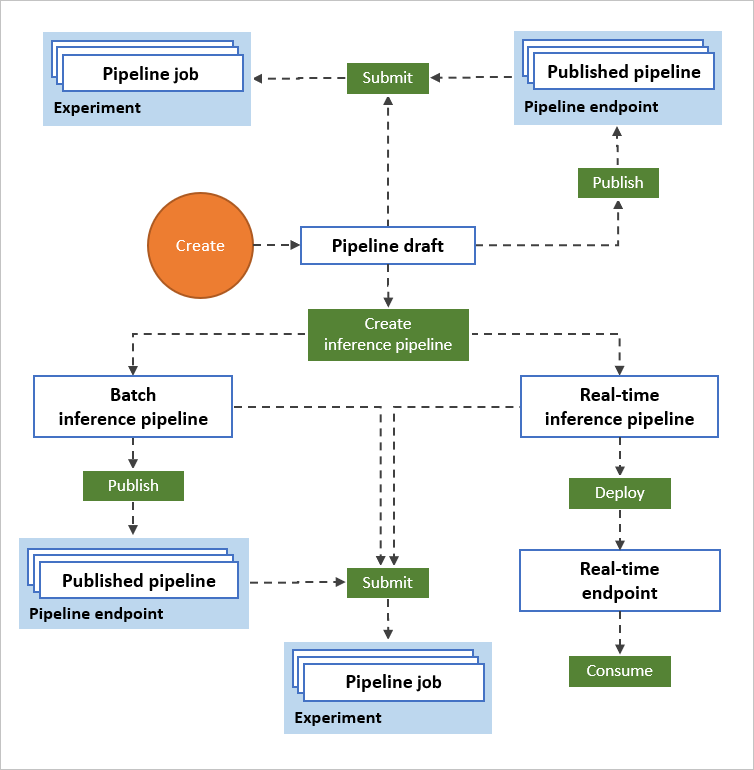
- Ziehen Sie Datenressourcen und Komponenten per Drag & Drop auf den visuellen Designer-Canvas, und verbinden Sie die Komponenten, um einen Pipelineentwurf zu erstellen.
- Übermitteln Sie einen Pipelineauftrag, der die Computeressourcen in Ihrem Azure Machine Learning-Arbeitsbereich verwendet.
- Konvertieren Ihrer Trainingspipelines in die Rückschlusspipelines
- Veröffentlichen Sie Ihre Pipelines an einem REST-Pipelineendpunkt, um neue Pipelines zu übermitteln, die mit unterschiedlichen Parametern und Datenressourcen ausgeführt werden.
- Veröffentlichen einer Trainingspipeline, um beim Ändern von Parametern und Datenressourcen eine einzelnen Pipeline zum Trainieren mehrerer Modelle nochmal zu verwenden
- Veröffentlichen einer Batchrückschlusspipeline, um Vorhersage zu neuen Daten zu treffen, indem ein zuvor trainiertes Modell verwendet wird
- Bereitstellen einer Echtzeit-Rückschlusspipeline an einem Onlineendpunkt, um in Echtzeit Vorhersagen zu neuen Daten zu treffen.
Daten
Eine Datenressource für maschinelles Lernen erleichtert Ihnen den Zugriff auf Ihre Daten und die Arbeit damit. Der Designer enthält mehrere Beispieldatenressourcen, mit denen Sie experimentieren können. Sie können bei Bedarf weitere Datenressourcen registrieren.
Komponenten
Eine Komponente ist ein Algorithmus, den Sie auf Ihren Daten ausführen können. Der Designer besteht aus mehreren Komponenten, die von Dateneingangsfunktionen bis zu Trainings-, Bewertungs- und Validierungsprozessen reichen.
Eine Komponente kann Parameter enthalten, die Sie zum Konfigurieren der internen Algorithmen der Komponente verwenden. Wenn Sie eine Komponente auf dem Canvas auswählen, werden die Parameter und andere Einstellungen der Komponente in einem Eigenschaftenbereich rechts neben dem Canvas angezeigt. Sie können die Parameter ändern und die Computeressourcen für einzelne Komponenten in diesem Bereich festlegen.
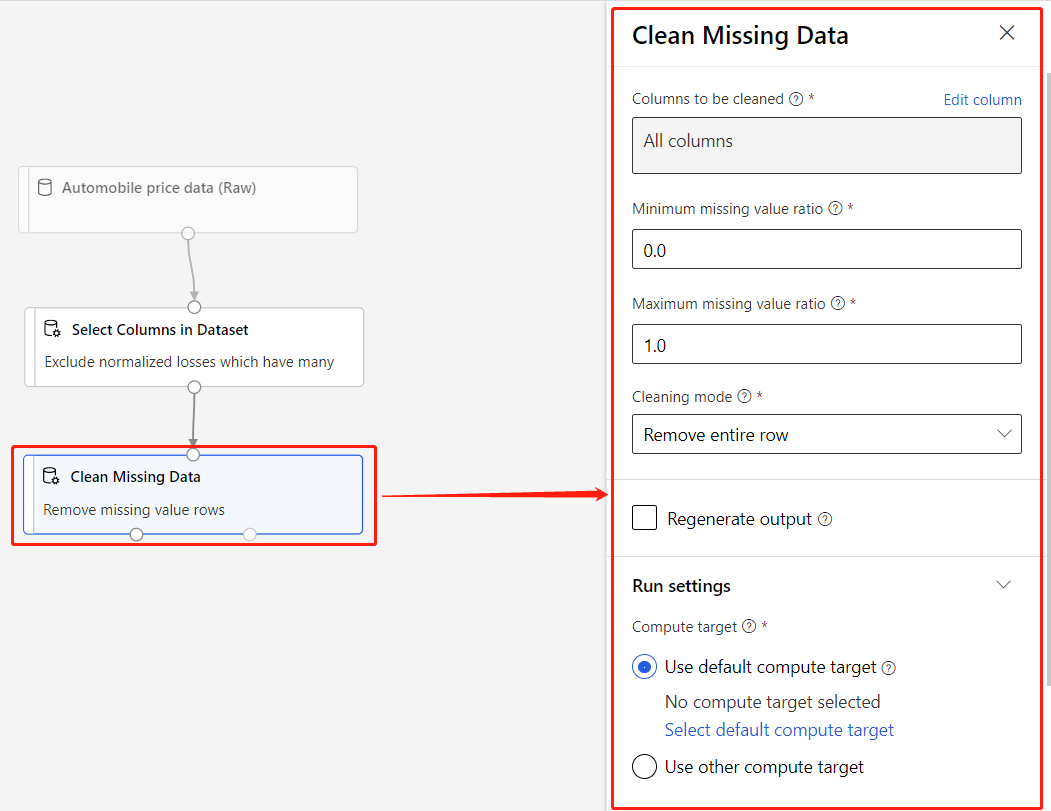
Weitere Informationen zur Bibliothek der verfügbaren Algorithmen des maschinellen Lernens finden Sie in der Referenz zu Algorithmen und Komponenten. Hilfe bei der Auswahl eines Algorithmus finden Sie unter Azure Machine Learning – Cheat Sheet für Algorithmen.
Pipelines
Eine Pipeline besteht aus Datenressourcen und analytischen Komponenten, die Sie verbinden. Pipelines helfen Ihnen, Ihre Arbeit wiederzuverwenden und Ihre Projekte zu organisieren.
Pipelines bieten viele Verwendungsmöglichkeiten. Sie können Pipelines erstellen, die:
- Ein einzelnes Modell trainieren.
- Mehrerer Modelle trainieren.
- Vorhersagen in Echtzeit oder im Batch erstellen.
- Nur Daten bereinigen.
Pipelineentwürfe
Wenn Sie eine Pipeline im Designer bearbeiten, wird der Fortschritt als Pipelineentwurfgespeichert. Sie können einen Pipeline-Entwurf jederzeit bearbeiten, indem Sie Komponenten hinzufügen oder entfernen, Computeziele konfigurieren oder Parameter festlegen.
Eine gültige Pipeline weist die folgenden Merkmale auf:
- Datenressourcen können nur mit Komponenten verbunden werden.
- Komponenten können nur eine Verbindung mit Datenressourcen oder anderen Komponenten herstellen.
- Alle Eingangsanschlüsse für Komponenten müssen in irgendeiner Weise mit dem Datenfluss verbunden sein.
- Alle erforderlichen Parameter für jede Komponente müssen eingestellt werden.
Wenn Sie bereit sind, Ihren Pipelineentwurf auszuführen, speichern Sie die Pipeline und übermitteln einen Pipelineauftrag.
Pipelineaufgaben
Jedes Mal, wenn Sie eine Pipeline ausführen, werden die Konfiguration der Pipeline und ihre Ergebnisse in Ihrem Arbeitsbereich als Pipelineauftrag gespeichert. Pipelineaufträge werden in Experimenten gruppiert, um den Auftragsverlauf zu organisieren.
Sie können zu jedem Pipelineauftrag zurückkehren, um ihn zur Problembehandlung oder Überwachung zu überprüfen. Klonen Sie einen Pipelineauftrag, um einen neuen Pipelineentwurf zur Bearbeitung zu erstellen.
Computeressourcen
Computeziele sind an Ihren Azure Machine Learning-Arbeitsbereich in Azure Machine Learning Studio angefügt. Verwenden Sie Computeressourcen aus Ihrem Arbeitsbereich, um Ihre Pipeline auszuführen und Ihre bereitgestellten Modelle als Onlineendpunkte oder Pipelineendpunkte für Batchrückschlüsse zu hosten. Die unterstützten Computeziele sind die Folgenden:
| Computeziel | Training | Bereitstellung |
|---|---|---|
| Azure Machine Learning Compute | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
Bereitstellen
Für das Echtzeit-Rückschließen müssen Sie eine Pipeline als Onlineendpunkt bereitstellen. Der Onlineendpunkt erstellt eine Schnittstelle zwischen einer externen Anwendung und Ihrem Bewertungsmodell. Der Endpunkt basiert auf REST, einer gängigen Architektur für Webprogrammierungsprojekte. Durch den Aufruf eines Onlineendpunkts werden Vorhersageergebnisse in Echtzeit an die Anwendung zurückgegeben.
Für einen Aufruf eines Onlineendpunkts übergeben Sie den API-Schlüssel, der beim Bereitstellen des Endpunkts erstellt wurde. Onlineendpunkte müssen in einem AKS-Cluster bereitgestellt werden. Informationen dazu, wie Sie Ihr Modell bereitstellen, finden Sie unter Tutorial: Bereitstellen eines Machine Learning-Modells mit dem Designer.
Veröffentlichen
Sie können eine Pipeline auch in einem Pipelineendpunkt veröffentlichen. Ähnlich wie bei einem Onlineendpunkt ermöglicht Ihnen ein Pipelineendpunkt das Übermitteln von neuen Pipelineaufträgen aus externen Anwendungen mithilfe von REST-Aufrufen. Mit einem Pipelineendpunkt können Sie jedoch keine Daten in Echtzeit senden oder empfangen.
Veröffentlichte Pipelineendpunkte sind flexibel und können verwendet werden, um Modelle zu trainieren oder erneut zu trainieren, Batchrückschlüsse durchzuführen oder neue Daten zu verarbeiten. Sie können mehrere Pipelines in einem einzigen Pipelineendpunkt veröffentlichen und angeben, welche Pipelineversion ausgeführt werden soll.
Eine veröffentlichte Pipeline wird auf den Rechenressourcen ausgeführt, die Sie im Pipeline-Entwurf für jede Komponente definieren. Der Designer erstellt dasselbe PublishedPipeline-Objekt wie das SDK.
Zugehöriger Inhalt
- Lernen Sie die Grundlagen von Predictive Analytics und maschinellem Lernen kennen mit dem Tutorial: Vorhersagen des Automobilpreises mit dem Designer.
- Erfahren Sie, wie Sie vorhandene Designer-Beispiele ändern, um sie an Ihre Anforderungen anzupassen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für