Anfügen eines Kubernetes-Clusters an einen Azure Machine Learning-Arbeitsbereich
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Sobald die Azure Machine Learning-Erweiterung auf AKS oder einem Arc Kubernetes-Cluster bereitgestellt ist, können Sie den Kubernetes-Cluster dem Azure Machine Learning-Arbeitsbereich anfügen und Computeziele erstellen, die von ML-Experten verwendet werden sollen.
Voraussetzungen
Das Anfügen eines Kubernetes-Clusters an den Azure Machine Learning-Arbeitsbereich kann viele verschiedene Szenarios flexibel unterstützen. Beispiele dafür sind freigegebene Szenarios mit mehreren Anhängen, Modelltrainingsskripte, die auf Azure-Ressourcen zugreifen, sowie die Authentifizierungskonfiguration des Arbeitsbereichs.
Multi-Anfügungen und Workloadisolation
Ein Cluster zu einem Arbeitsbereich, wodurch mehrere Computeziele erstellt werden
- Sie können den gleichen Kubernetes-Cluster mehrfach an denselben Arbeitsbereich anfügen und mehrere Computeziele für verschiedene Projekte/Teams/Workloads erstellen.
Ein Cluster zu mehreren Arbeitsbereichen
- Für denselben Kubernetes-Cluster können Sie ihn auch an mehrere Arbeitsbereiche anfügen, und diese Arbeitsbereiche können sich denselben Kubernetes-Cluster teilen.
Wenn Sie verschiedene Computeziele für verschiedene Projekte/Teams planen, können Sie den vorhandenen Kubernetes-Namespace in Ihrem Cluster für das Computeziel angeben, um zwischen verschiedenen Teams/Projekten die Workload zu isolieren.
Wichtig
Der Namespace, den Sie beim Anfügen des Clusters an den Azure Machine Learning-Arbeitsbereich angeben möchten, sollte vorgängig in Ihrem Cluster erstellt werden.
Sicherer Zugriff auf Azure-Ressourcen aus einem Trainingsskript
Wenn Sie von Ihrem Trainingsskript aus sicher auf Azure-Ressourcen zugreifen müssen, können Sie während des Anfügens eine verwaltete Identität für das Kubernetes-Computeziel angeben.
An einen Arbeitsbereich mit benutzerseitig zugewiesener verwalteter Identität anfügen
Ein Azure Machine Learning-Arbeitsbereich verfügt standardmäßig über eine systemseitig zugewiesene verwaltete Identität für den Zugriff auf Azure Machine Learning-Ressourcen. Die Schritte werden ausgeführt, wenn die systemseitig zugewiesene Standardeinstellung aktiviert ist.
Wenn andererseits eine benutzerseitig zugewiesene verwaltete Identität bei der Erstellung des Azure Machine Learning-Arbeitsbereichs angegeben wird, müssen der verwalteten Identität die folgenden Rollenzuweisungen manuell gewährt werden, bevor das Compute angefügt wird.
| Name der Azure-Ressource | Zuzuweisende Rollen | BESCHREIBUNG |
|---|---|---|
| Azure Relay | Azure Relay-Besitzer | Gilt nur für Kubernetes-Cluster mit Arc-Unterstützung. Azure Relay wird nicht für AKS-Cluster ohne Verbindung mit Arc erstellt. |
| Kubernetes: Azure Arc oder Azure Kubernetes Service | Leser Mitwirkender für Kubernetes-Erweiterungen Azure Kubernetes Service-Clusteradministrator |
Gilt sowohl für Kubernetes-Cluster mit Arc-Unterstützung als auch für AKS-Cluster. |
| Azure Kubernetes Service | Mitwirkender | Nur für AKS-Cluster erforderlich, die das Feature „Vertrauenswürdiger Zugriff“ verwenden. Der Arbeitsbereich nutzt eine benutzerseitig zugewiesene verwaltete Identität. Ausführlichere Informationen finden Sie unter AzureML-Zugriff auf AKS-Cluster mit speziellen Konfigurationen. |
Tipp
Die Azure Relay-Ressource wird während der Erweiterungsbereitstellung unter derselben Ressourcengruppe wie der Kubernetes-Cluster mit Arc-Unterstützung erstellt.
Hinweis
- Wenn die Rollenberechtigung „Mitwirkender bei der Kubernetes-Erweiterung“ nicht verfügbar ist, schlägt die Clusteranlage mit dem Fehler „Erweiterung nicht installiert“ fehl.
- Wenn die Rollenberechtigung „Azure Kubernetes Service-Clusteradministrator“ nicht verfügbar ist, schlägt die Clusteranlage mit dem Fehler „interner Server“ fehl.
Anfügen eines Kubernetes-Clusters an einen Azure Machine Learning-Arbeitsbereich
Wir unterstützen zwei Möglichkeiten zum Anfügen eines Kubernetes-Clusters an einen Azure Machine Learning-Arbeitsbereich, entweder mithilfe der Azure CLI oder der Studio-Benutzeroberfläche.
Die folgenden CLI v2-Befehle zeigen, wie Sie einen AKS-Cluster und einen Kubernetes-Cluster mit Azure Arc-Unterstützung anfügen und diesen als Computeziel mit aktivierter verwalteter Identität verwenden.
AKS-Cluster
az ml compute attach --resource-group <resource-group-name> --workspace-name <workspace-name> --type Kubernetes --name k8s-compute --resource-id "/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedclusters/<cluster-name>" --identity-type SystemAssigned --namespace <Kubernetes namespace to run Azure Machine Learning workloads> --no-wait
Arc Kubernetes-Cluster
az ml compute attach --resource-group <resource-group-name> --workspace-name <workspace-name> --type Kubernetes --name amlarc-compute --resource-id "/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.Kubernetes/connectedClusters/<cluster-name>" --user-assigned-identities "subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<identity-name>" --no-wait
Stellen Sie das --type-Argument auf Kubernetes ein. Verwenden Sie das identity_type-Argument, um verwaltete SystemAssigned- oder UserAssigned-Identitäten zu aktivieren.
Wichtig
--user-assigned-identities ist nur für verwaltete UserAssigned-Identitäten erforderlich. Sie können zwar eine Liste mit durch Kommas getrennten und vom Benutzer verwalteten Identitäten bereitstellen, es wird jedoch nur die erste Identität verwendet, wenn Sie Ihren Cluster anfügen.
Die Computeanfügung erstellt den Kubernetes-Namespace nicht automatisch und überprüft auch nicht, ob der Kubernetes-Namespace vorhanden ist. Sie müssen überprüfen, ob der angegebene Namespace in Ihrem Cluster vorhanden ist. Andernfalls werden alle Azure Machine Learning-Workloads, die an diese Compute-Instanz übermittelt werden, zu Fehlern führen.
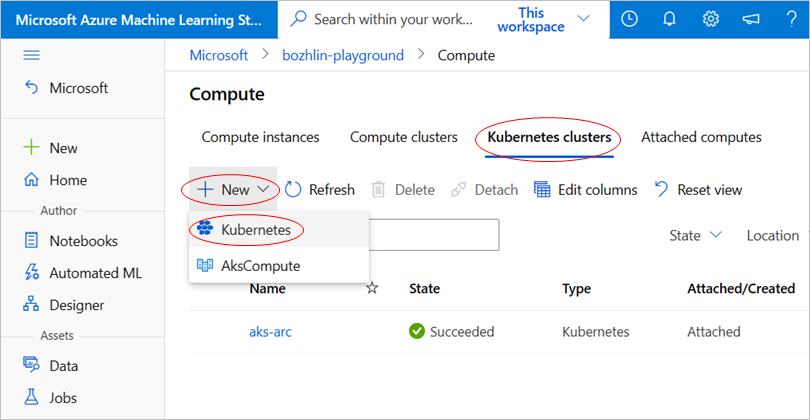
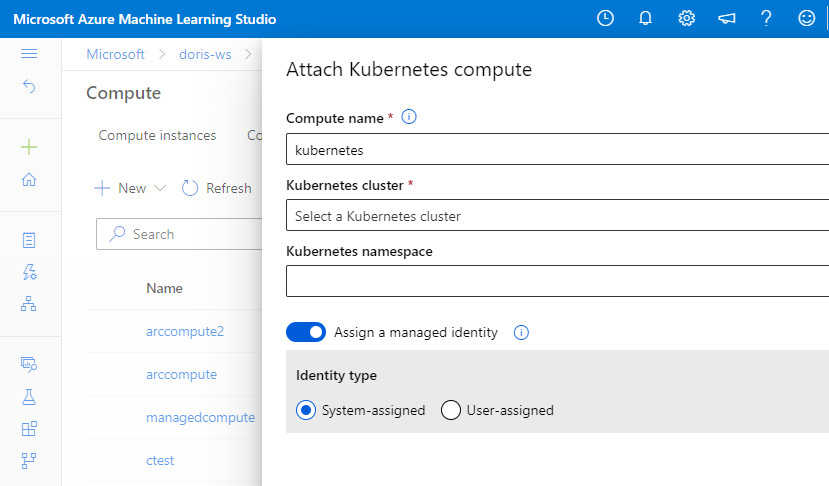
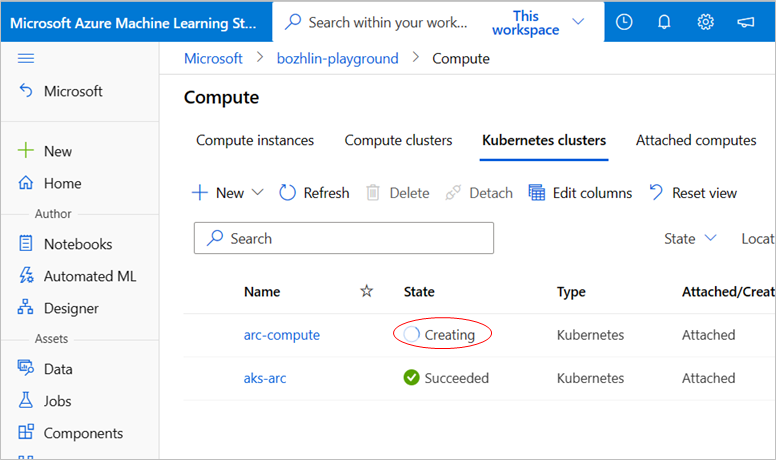
Zuweisen einer verwalteten Identität zum Computeziel
Eine typische Herausforderung für Entwickler stellt die Verwaltung von Geheimnissen und Berechtigungsnachweisen dar, die zum Absichern der Kommunikation zwischen verschiedenen Komponenten einer Lösung verwendet werden. Dank verwalteter Identitäten müssen Entwickler keine Anmeldeinformationen mehr verwalten.
Um auf Azure Container Registry (ACR) für ein Docker-Image und ein Speicherkonto für Trainingsdaten zuzugreifen, verbinden Sie eine Kubernetes-Computeressource mit einer systemseitig oder benutzerseitig zugewiesenen verwalteten Identität.
Zuweisen einer verwalteten Identität
Sie können der Computeressource eine verwaltete Identität zuweisen, wenn Sie die Computeressource anfügen.
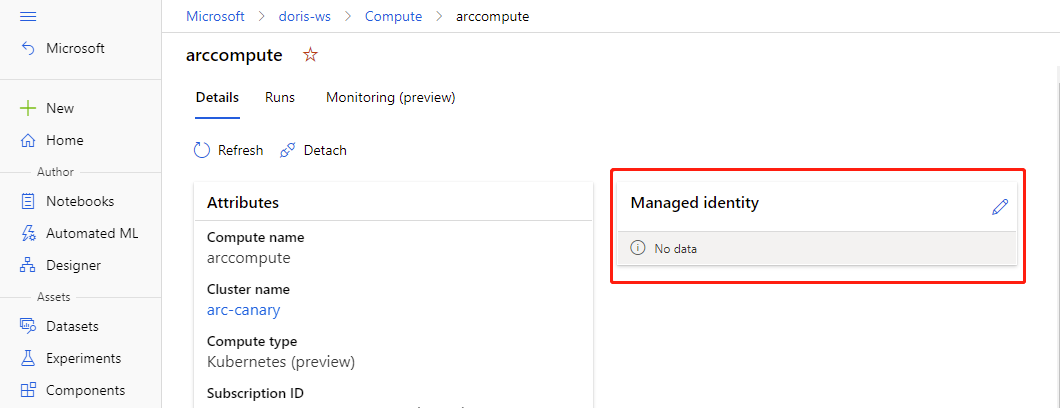
Wenn die Computeressource bereits angefügt wurde, können Sie die Einstellungen zur Verwendung einer verwalteten Identität in Azure Machine Learning Studio aktualisieren.
- Navigieren Sie zu Azure Machine Learning Studio. Wählen Sie Compute > Angefügte Computeressource und anschließend Ihre angefügte Computeressource aus.
- Klicken Sie auf das Stiftsymbol, um die verwaltete Identität zu bearbeiten.
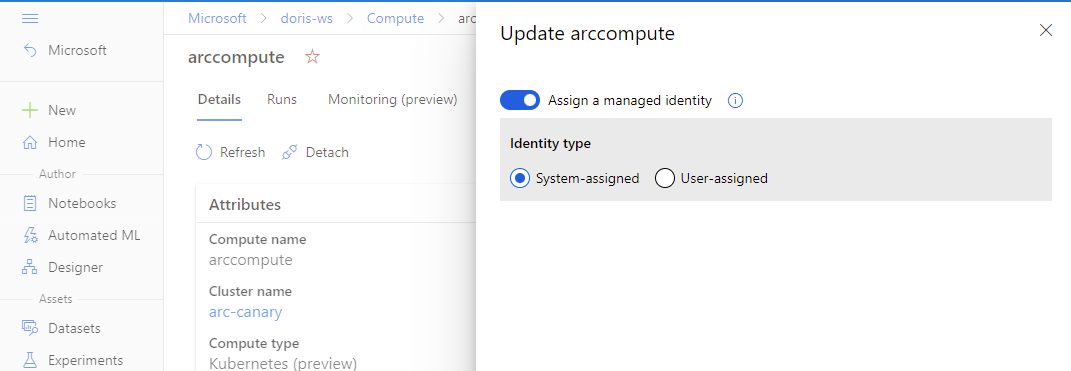
Zuweisen von Azure-Rollen zu einer verwalteten Identität
Azure bietet verschiedene Möglichkeiten, einer verwalteten Identität Rollen zuzuweisen.
- Verwenden des Azure-Portals zum Zuweisen von Rollen
- Verwenden der Azure CLI zum Zuweisen von Rollen
- Verwenden von Azure PowerShell zum Zuweisen von Rollen
Wenn Sie die Rollenzuweisung im Azure-Portal vornehmen und über eine systemseitig zugewiesene verwaltete Identität, einen Benutzer, Gruppenprinzipal oder Dienstprinzipal verfügen, können Sie mit der Option Mitglieder auswählen nach dem Identitätsnamen suchen. Der Identitätsname muss wie folgt formatiert werden: <workspace name>/computes/<compute target name>.
Wenn Sie über eine benutzerseitig zugewiesene verwaltete Identität verfügen, wählen Sie Verwaltete Identität aus, um nach der Zielidentität zu suchen.
Sie können mithilfe von Managed Identity Images aus Azure Container Registry abrufen. Gewähren Sie der verwalteten Identität der Computeressource die Rolle AcrPull. Weitere Informationen finden Sie unter Azure Container Registry: Rollen und Berechtigungen.
Sie können eine verwaltete Identität verwenden, um auf Azure Blob zuzugreifen:
- Für einen reinen Lesezugriff sollte der verwalteten Identität der Computeressource die Rolle Storage-Blobdatenleser zugewiesen werden.
- Für Schreibvorgänge sollte der verwalteten Identität der Computeressource die Rolle Mitwirkender an Storage-Blobdaten zugewiesen werden.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für