Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Azure CLI-ML-Erweiterung v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Machine Learning-Pipelines mit der Azure CLI und Komponenten erstellen und ausführen. Sie können Pipelines erstellen, ohne Komponenten zu verwenden, aber Komponenten bieten Flexibilität und ermöglichen die Wiederverwendung. Azure Machine Learning-Pipelines können in YAML definiert und über die CLI ausgeführt werden, in Python erstellt oder im Azure Machine Learning Studio Designer über eine Drag-and-Drop-Benutzeroberfläche komponiert werden. Dieser Artikel konzentriert sich auf die CLI.
Voraussetzungen
Ein Azure-Abonnement. Wenn Sie keines haben, erstellen Sie ein kostenloses Konto, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Die Azure CLI-Erweiterung für Maschinelles Lernen, installiert und eingerichtet.
Ein Klon des Beispiel-Repositorys. Sie können diese Befehle verwenden, um das Repository zu klonen:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Empfohlene Vorablektüre
Erstellen Sie Ihre erste Pipeline mit Komponenten
Zunächst erstellen Sie eine Pipeline mit Komponenten mithilfe eines Beispiels. Auf diese Weise erhalten Sie einen ersten Eindruck davon, wie eine Pipeline und Komponente in Azure Machine Learning aussieht.
Wechseln Sie im cli/jobs/pipelines-with-components/basics Verzeichnis des azureml-examples Repositorys zum 3b_pipeline_with_data Unterverzeichnis. Es gibt drei Arten von Dateien in diesem Verzeichnis. Dies sind die Dateien, die Sie erstellen müssen, wenn Sie eine eigene Pipeline erstellen.
pipeline.yml. Diese YAML-Datei definiert die Machine Learning-Pipeline. Es beschreibt, wie eine vollständige Machine Learning-Aufgabe in einen mehrstufigen Workflow unterteilt wird. Betrachten Sie beispielsweise die einfache maschinelle Lernaufgabe, historische Daten zu verwenden, um ein Vertriebsprognosemodell zu trainieren. Möglicherweise möchten Sie einen sequenziellen Workflow erstellen, der Datenverarbeitungs-, Modellschulungs- und Modellauswertungsschritte enthält. Jeder Schritt ist eine Komponente, die über eine klar definierte Schnittstelle verfügt und unabhängig entwickelt, getestet und optimiert werden kann. Die Pipeline-YAML definiert auch, wie die untergeordneten Schritte mit anderen Schritten in der Pipeline verbunden sind. Beispielsweise generiert der Modellschulungsschritt eine Modelldatei, und die Modelldatei wird an einen Modellauswertungsschritt übergeben.
component.yml. Diese YAML-Dateien definieren die Komponenten. Sie enthalten die folgenden Informationen:
- Metadaten: Name, Anzeigename, Version, Beschreibung, Typ usw. Die Metadaten helfen beim Beschreiben und Verwalten der Komponente.
- Schnittstelle: Eingaben und Ausgaben. Beispielsweise übernimmt eine Modellschulungskomponente Schulungsdaten und die Anzahl der Epochen als Eingabe und generiert eine trainierte Modelldatei als Ausgabe. Nachdem die Schnittstelle definiert wurde, können verschiedene Teams die Komponente unabhängig entwickeln und testen.
- Befehl, Code und Umgebung: Der Befehl, Code und die Umgebung zum Ausführen der Komponente. Der Befehl ist der Shellbefehl zum Ausführen der Komponente. Der Code bezieht sich in der Regel auf ein Quellcodeverzeichnis. Die Umgebung kann eine Azure Machine Learning-Umgebung (kuratiert oder vom Kunden erstellt), Docker-Image oder Conda-Umgebung sein.
component_src. Dies sind die Quellcodeverzeichnisse für bestimmte Komponenten. Sie enthalten den Quellcode, der in der Komponente ausgeführt wird. Sie können Ihre bevorzugte Sprache verwenden, einschließlich Python, R und anderen. Der Code muss von einem Shellbefehl ausgeführt werden. Der Quellcode kann einige Eingaben aus der Shell-Befehlszeile ausführen, um zu steuern, wie dieser Schritt ausgeführt wird. Ein Trainingsschritt kann beispielsweise Schulungsdaten, die Lernrate und die Anzahl der Epochen verwenden, um den Trainingsprozess zu steuern. Das Argument eines Shellbefehls wird verwendet, um Eingaben und Ausgaben an den Code zu übergeben.
Sie erstellen nun eine Pipeline mithilfe des 3b_pipeline_with_data Beispiels. Jede Datei wird in den folgenden Abschnitten weiter erläutert.
Listen Sie zunächst Ihre verfügbaren Computeressourcen mithilfe des folgenden Befehls auf:
az ml compute list
Wenn er nicht vorhanden ist, erstellen Sie einen Cluster namens cpu-cluster, indem Sie diesen Befehl ausführen:
Hinweis
Überspringen Sie diesen Schritt, um serverloses Rechnen zu verwenden.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Erstellen Sie nun einen Pipelineauftrag, der in der datei pipeline.yml definiert ist, indem Sie den folgenden Befehl ausführen. Das Computeziel wird in der „pipeline.yml“-Datei als azureml:cpu-cluster referenziert. Wenn Ihr Computeziel einen anderen Namen verwendet, denken Sie daran, ihn in der „pipeline.yml“-Datei zu aktualisieren.
az ml job create --file pipeline.yml
Sie sollten ein JSON-Wörterbuch mit Informationen zum Pipelineauftrag erhalten, einschließlich:
| Schlüssel | BESCHREIBUNG |
|---|---|
name |
Der GUID-basierte Name des Auftrags |
experiment_name |
Der Name, unter dem Aufträge in Studio organisiert werden |
services.Studio.endpoint |
Eine URL zum Überwachen und Überprüfen des Pipelineauftrags |
status |
Der Status des Auftrags. Er wird an diesem Punkt wahrscheinlich Preparing sein. |
Wechseln Sie zur services.Studio.endpoint URL, um eine Visualisierung der Pipeline anzuzeigen:
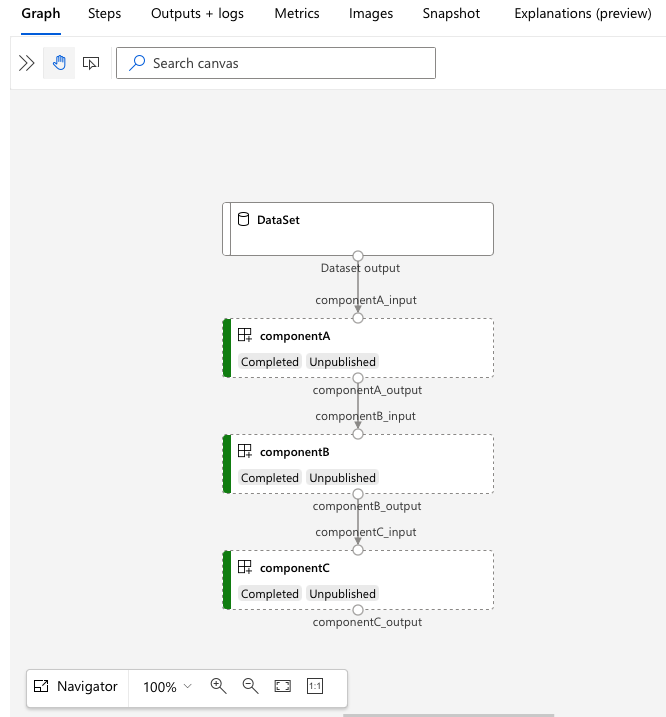
Verstehen der Pipelinedefinitions-YAML
Nun sehen Sie sich die Pipelinedefinition in der Datei 3b_pipeline_with_data/pipeline.yml an.
Hinweis
Um serverloses Computing zu verwenden, ersetzen Sie in dieser Datei default_compute: azureml:cpu-cluster durch default_compute: azureml:serverless.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
In der folgenden Tabelle werden die am häufigsten verwendeten Felder des YaML-Pipelineschemas beschrieben. Weitere Informationen finden Sie im vollständigen YAML-Schema für Pipelines.
| Schlüssel | BESCHREIBUNG |
|---|---|
type |
Erforderlich. Der Auftragstyp. Er muss für Pipelineaufträge pipeline sein. |
display_name |
Der Anzeigename des Pipelineauftrags in der Studio-Benutzeroberfläche. Bearbeitbar in der Studio-Benutzeroberfläche. Er muss nicht für alle Aufträge im Arbeitsbereich eindeutig sein. |
jobs |
Erforderlich. Ein Wörterbuch der einzelnen Aufträge, die als Schritte innerhalb der Pipeline ausgeführt werden sollen. Diese Aufträge werden als untergeordnete Aufträge des übergeordneten Pipelineauftrags betrachtet. In der aktuellen Version sind die unterstützten Auftragstypen in der Pipeline command und sweep. |
inputs |
Ein Wörterbuch der Eingaben für den Pipelineauftrag. Der Schlüssel ist ein Name für die Eingabe im Kontext des Auftrags, und der Wert ist der Eingabewert. Auf diese Pipelineeingaben kann mithilfe des Ausdrucks ${{ parent.inputs.<input_name> }} durch die Eingaben eines einzelnen Schrittauftrags in der Pipeline verwiesen werden. |
outputs |
Ein Wörterbuch der Ausgabekonfigurationen des Pipelineauftrags. Der Schlüssel ist ein Name für die Ausgabe im Kontext des Auftrags, und der Wert ist die Ausgabekonfiguration. Auf diese Pipelineausgaben kann mithilfe des Ausdrucks ${{ parents.outputs.<output_name> }} durch die Ausgaben eines einzelnen Schrittauftrags in der Pipeline verwiesen werden. |
Das 3b_pipeline_with_data Beispiel enthält eine dreistufige Pipeline.
- Die drei Schritte sind unter
jobsdefiniert. Alle drei Schritte sind vom Typcommand. Jede Schrittdefinition befindet sich in einer entsprechendencomponent*.ymlDatei. Die YAML-Komponentendateien werden im verzeichnis 3b_pipeline_with_data angezeigt.componentA.ymlwird im nächsten Abschnitt beschrieben. - Diese Pipeline verfügt über Eine Datenabhängigkeit, die in realen Pipelines üblich ist. Komponente A übernimmt Dateneingaben aus einem lokalen Ordner unter
./data(Zeilen 18-21) und übergibt die Ausgabe an Komponente B (Zeile 29). Die Ausgabe von Komponente A kann als${{parent.jobs.component_a.outputs.component_a_output}}bezeichnet werden. -
default_computedefiniert die Standardberechnung für die Pipeline. Wenn eine Komponente injobseine andere Berechnung definiert, werden die komponentenspezifischen Einstellungen berücksichtigt.

Lesen und Schreiben von Daten in einer Pipeline
Ein häufiges Szenario ist das Lesen und Schreiben von Daten in einer Pipeline. In Azure Machine Learning verwenden Sie dasselbe Schema zum Lesen und Schreiben von Daten für alle Arten von Aufträgen (Pipelineaufträge, Befehlsaufträge und Aufräumen von Aufträgen). Im Folgenden finden Sie Beispiele für die Verwendung von Daten in Pipelines für häufige Szenarien:
- Lokale Daten
- Webdatei mit einer öffentlichen URL
- Azure Machine Learning-Datenspeicher und -Pfad
- Azure Machine Learning-Datenressource
Grundlegendes zur Komponentendefinitions-YAML
Dies ist die componentA.yml-Datei , ein Beispiel für YAML, das eine Komponente definiert:
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Diese Tabelle definiert die am häufigsten verwendeten Felder von Komponenten-YAML. Weitere Informationen finden Sie im vollständigen YAML-Schema für Komponenten.
| Schlüssel | BESCHREIBUNG |
|---|---|
name |
Erforderlich. Der Name der Komponente. Er muss im Azure Machine Learning-Arbeitsbereich eindeutig sein. Er muss mit einem Kleinbuchstaben beginnen. Kleinbuchstaben, Zahlen und Unterstriche (_) sind zulässig. Die maximale Länge beträgt 255 Zeichen. |
display_name |
Der Anzeigename der Komponente in der Studio-Benutzeroberfläche. Er muss innerhalb des Arbeitsbereichs nicht eindeutig sein. |
command |
Erforderlich. Der auszuführende Befehl. |
code |
Der lokale Pfad zum Quellcodeverzeichnis, das hochgeladen und für die Komponente verwendet werden soll. |
environment |
Erforderlich. Die Umgebung, die zum Ausführen der Komponente verwendet wird. |
inputs |
Ein Wörterbuch mit Komponenteneingaben. Der Schlüssel ist ein Name für die Eingabe im Kontext der Komponente, und der Wert ist die Komponenteneingabedefinition. Sie können mithilfe des ${{ inputs.<input_name> }} Ausdrucks auf Eingaben im Befehl verweisen. |
outputs |
Ein Wörterbuch der Komponentenausgänge. Der Schlüssel ist ein Name für die Ausgabe im Kontext der Komponente, und der Wert ist die Komponentenausgabedefinition. Sie können im Befehl auf Ausgaben verweisen, indem Sie den Ausdruck ${{ outputs.<output_name> }} verwenden. |
is_deterministic |
Gibt an, ob das Ergebnis des vorherigen Auftrags wiederverwendet werden soll, wenn sich die Komponenteneingaben nicht ändern. Der Standardwert ist true. Diese Einstellung wird auch standardmäßig als Wiederverwendung bezeichnet. Das übliche Szenario, wenn auf false festgelegt, besteht darin, das erneute Laden von Daten aus dem Cloud-Speicher oder von einer URL zu erzwingen. |
Im Beispiel in 3b_pipeline_with_data/componentA.yml verfügt Komponente A über eine Dateneingabe und eine Datenausgabe, die mit anderen Schritten in der übergeordneten Pipeline verbunden werden kann. Alle Dateien im code Abschnitt in der Komponente YAML werden beim Übermitteln des Pipelineauftrags in Azure Machine Learning hochgeladen. In diesem Beispiel werden dateien unter ./componentA_src hochgeladen. (Zeile 16 in componentA.yml.) Sie können den hochgeladenen Quellcode in der Studio-Benutzeroberfläche sehen: Doppelklicken Sie auf den ComponentA-Schritt im Diagramm, und wechseln Sie zur Registerkarte "Code ", wie im folgenden Screenshot gezeigt. Sie können sehen, dass es sich um ein „Hello World“-Skript handelt, das nur eine einfache Ausgabe vornimmt sowie das aktuelle Datum mit Uhrzeit in den componentA_output-Pfad schreibt. Die Komponente übernimmt Eingaben und stellt die Ausgabe über die Befehlszeile bereit. Es wird in hello.py über argparsebehandelt.

Eingabe und Ausgabe
Eingabe und Ausgabe definieren die Schnittstelle einer Komponente. Eingabe- und Ausgabewerte können Literalwerte (vom Typ string, , number, integeroder boolean) oder ein Objekt sein, das ein Eingabeschema enthält.
Objekteingaben (vom Typ uri_file, uri_folder, , mltable, mlflow_modeloder custom_model) können eine Verbindung mit anderen Schritten im übergeordneten Pipelineauftrag herstellen, um Daten/Modelle an andere Schritte zu übergeben. Im Pipelinediagramm wird die Objekttypeingabe als Verbindungspunkt gerendert.
Literalwerteingaben (string, number, integer, boolean) sind die Parameter, die Sie zur Laufzeit an die Komponente übergeben können. Sie können einen Standardwert von Literaleingaben im default Feld hinzufügen. Für number- und integer-Typen können Sie auch Mindest- und Höchstwerte hinzufügen, indem Sie die min und max Felder verwenden. Wenn der Eingabewert kleiner als das Minimum oder mehr als das Maximum ist, schlägt die Pipeline bei der Überprüfung fehl. Die Überprüfung erfolgt, bevor Sie einen Pipeline-Auftrag übermitteln, was Zeit sparen kann. Die Validierung funktioniert für die CLI, das Python SDK und die Designer-Benutzeroberfläche. Der folgende Screenshot zeigt ein Überprüfungsbeispiel in der Designer-Benutzeroberfläche. Ebenso können Sie zulässige Werte in enum Feldern definieren.

Wenn Sie einer Komponente eine Eingabe hinzufügen möchten, müssen Sie an drei Stellen Bearbeitungen vornehmen:
- Das
inputsFeld in der Komponente YAML. - Das
commandFeld in der Komponente YAML. - Im Quellcode der Komponente zum Verarbeiten der Befehlszeileneingabe.
Diese Speicherorte sind mit grünen Feldern im vorherigen Screenshot gekennzeichnet.
Weitere Informationen zu Eingaben und Ausgaben finden Sie unter Verwalten von Eingaben und Ausgaben für Komponenten und Pipelines.
Umgebungen
Die Umgebung ist die Umgebung, in der die Komponente ausgeführt wird. Es kann sich um eine Azure Machine Learning-Umgebung (kuratiert oder benutzerdefiniert), ein Docker-Image oder eine Conda-Umgebung handeln. Sehen Sie sich die folgenden Beispiele an:
-
Registrierte Azure Machine Learning-Umgebungsressource. Auf die Umgebung wird in der Komponente mit
azureml:<environment-name>:<environment-version>Syntax verwiesen. - Öffentliches Docker-Image.
- Conda-Datei. Die Conda-Datei muss zusammen mit einem Basisimage verwendet werden.
Registrieren einer Komponente für die Wiederverwendung und Freigabe
Obwohl einige Komponenten für eine bestimmte Pipeline spezifisch sind, kommt der eigentliche Vorteil von Komponenten aus der Wiederverwendung und dem Austausch. Sie können eine Komponente in Ihrem Machine Learning-Arbeitsbereich registrieren, um sie für die Wiederverwendung verfügbar zu machen. Registrierte Komponenten unterstützen die automatische Versionsverwaltung, sodass Sie die Komponente aktualisieren können, aber sicherstellen, dass Pipelines, die eine ältere Version erfordern, weiterhin funktionieren.
Wechseln Sie im Azureml-Beispielrepository zum cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components Verzeichnis.
Verwenden Sie zum Registrieren einer Komponente den Befehl az ml component create:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Nachdem diese Befehle zum Abschluss ausgeführt wurden, können Sie die Komponenten im Studio unter "Ressourcenkomponenten>" sehen:

Wählen Sie eine Komponente aus. Ausführliche Informationen zu jeder Version der Komponente werden angezeigt.
Auf der Registerkarte "Details werden grundlegende Informationen wie der Komponentenname, wer sie erstellt hat, und die Version angezeigt. Es gibt bearbeitbare Felder für Tags und Beschreibungen. Sie können Tags verwenden, um Suchstichwörter hinzuzufügen. Das Beschreibungsfeld unterstützt die Markdown-Formatierung. Sie sollten sie verwenden, um die Funktionalität und grundlegende Verwendung Ihrer Komponente zu beschreiben.
Auf der Registerkarte "Aufträge " wird der Verlauf aller Aufträge angezeigt, die die Komponente verwenden.
Verwenden registrierter Komponenten in einer YAML-Datei für einen Pipelineauftrag
Sie werden jetzt 1b_e2e_registered_components als Beispiel verwenden, um zu zeigen, wie man registrierte Komponenten in Pipeline YAML nutzt. Wechseln Sie zum 1b_e2e_registered_components Verzeichnis, und öffnen Sie die pipeline.yml Datei. Die Schlüssel und Werte in den Feldern inputs und outputs ähneln den bereits erläuterten Elementen. Der einzige signifikante Unterschied ist der Wert des Felds component in den jobs.<job_name>.component-Einträgen. Der component Wert befindet sich in der Form azureml:<component_name>:<component_version>. Die train-job Definition gibt beispielsweise an, dass die neueste Version der registrierten Komponente my_train verwendet werden soll:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Verwalten von Komponenten
Sie können Komponentendetails überprüfen und Komponenten mithilfe von CLI v2 verwalten. Verwenden Sie az ml component -h, um detaillierte Anweisungen zu Komponentenbefehlen zu erhalten. In der folgenden Tabelle sind alle verfügbaren Befehle aufgeführt. Weitere Beispiele finden Sie in der Azure CLI-Referenz.
| Befehl | BESCHREIBUNG |
|---|---|
az ml component create |
Erstellen Sie eine Komponente. |
az ml component list |
Listet die Komponenten in einem Arbeitsbereich auf. |
az ml component show |
Zeigen Sie die Details einer Komponente an. |
az ml component update |
Aktualisieren einer Komponente. Nur einige Felder (Beschreibung, display_name) unterstützen das Update. |
az ml component archive |
Archiviere einen Komponentencontainer. |
az ml component restore |
Stellen Sie eine archivierte Komponente wieder her. |
Nächster Schritt
- Testen Sie das BEISPIEL für die CLI v2-Komponente