Erstellen und Ausführen von Machine Learning-Pipelines mit Komponenten und Azure Machine Learning Studio
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Azure CLI-ML-Erweiterung v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Machine Learning-Pipelines mit Azure Machine Learning Studio und Komponenten erstellen und ausführen. Sie können Pipelines ohne Komponenten erstellen, aber Komponenten bieten eine höhere Flexibilität und bessere Möglichkeiten zur Wiederverwendung. Azure Machine Learning-Pipelines können in YAML definiert und über die Befehlszeilenschnittstelle ausgeführt, in Python erstellt oder im Azure Machine Learning Studio-Designer mit einer Drag & Drop-Benutzeroberfläche erstellt werden. Dieses Dokument konzentriert sich auf die Designer-Benutzeroberfläche von Azure Machine Learning Studio.
Voraussetzungen
Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Ein Azure Machine Learning-Arbeitsbereich Erstellen von Arbeitsbereichsressourcen.
Installieren und Einrichten der Azure CLI-Erweiterung für Machine Learning.
Klonen Sie das Beispielrepository:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Hinweis
Der Designer unterstützt zwei Komponententypen: klassisch vorkonfigurierte Komponenten (v1) und benutzerdefinierten Komponenten (v2). Diese beiden Komponententypen sind NICHT kompatibel.
Klassische vorkonfigurierte Komponenten bieten vordefinierte Komponenten, die vor allem für die Datenverarbeitung und für herkömmliche Machine Learning-Aufgaben wie Regression und Klassifizierung genutzt werden. Klassische vordefinierte Komponenten werden weiterhin unterstützt, aber es werden keine neuen Komponenten hinzugefügt. Außerdem unterstützt die Bereitstellung von klassischen vordefinierten Komponenten (v1) keine verwalteten Onlineendpunkte (v2).
Benutzerdefinierte Komponenten ermöglichen es Ihnen, Ihren eigenen Code als Komponente bereitzustellen. Er unterstützen die arbeitsbereichsübergreifende Freigabe und die reibungslose Dokumenterstellung über Studio-, CLI v2- und SDK v2-Schnittstellen.
Für neue Projekte wird dringend empfohlen, eine benutzerdefinierte Komponente zu verwenden, die mit AzureML V2 kompatibel ist und weiterhin neue Updates erhält.
Dieser Artikel gilt für benutzerdefinierte Komponenten.
Registrieren der Komponente in Ihrem Arbeitsbereich
Um eine Pipeline mit Komponenten der Benutzeroberfläche zu erstellen, müssen Sie zunächst Komponenten in Ihrem Arbeitsbereich registrieren. Sie können die Benutzeroberfläche, die CLI oder das SDK verwenden, um Komponenten in Ihrem Arbeitsbereich zu registrieren, sodass Sie die Komponente innerhalb des Arbeitsbereichs freigeben und wiederverwenden können. Registrierte Komponenten unterstützen die automatische Versionsverwaltung. Dadurch können Sie die Komponente aktualisieren und gleichzeitig sicherstellen, dass Pipelines, die eine ältere Version erfordern, weiterhin funktionieren.
Das folgende Beispiel verwendet die Benutzeroberfläche, um Komponenten zu registrieren, und die Quelldateien der Komponente befinden sich im Verzeichnis cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components des azureml-examples-Repositorys. Zunächst müssen Sie das Repository lokal klonen.
Navigieren Sie in Ihrem Azure Machine Learning-Arbeitsbereich zur Seite Komponenten, und wählen Sie Neue Komponente aus. Eine der beiden Formatvorlagenseiten wird angezeigt:
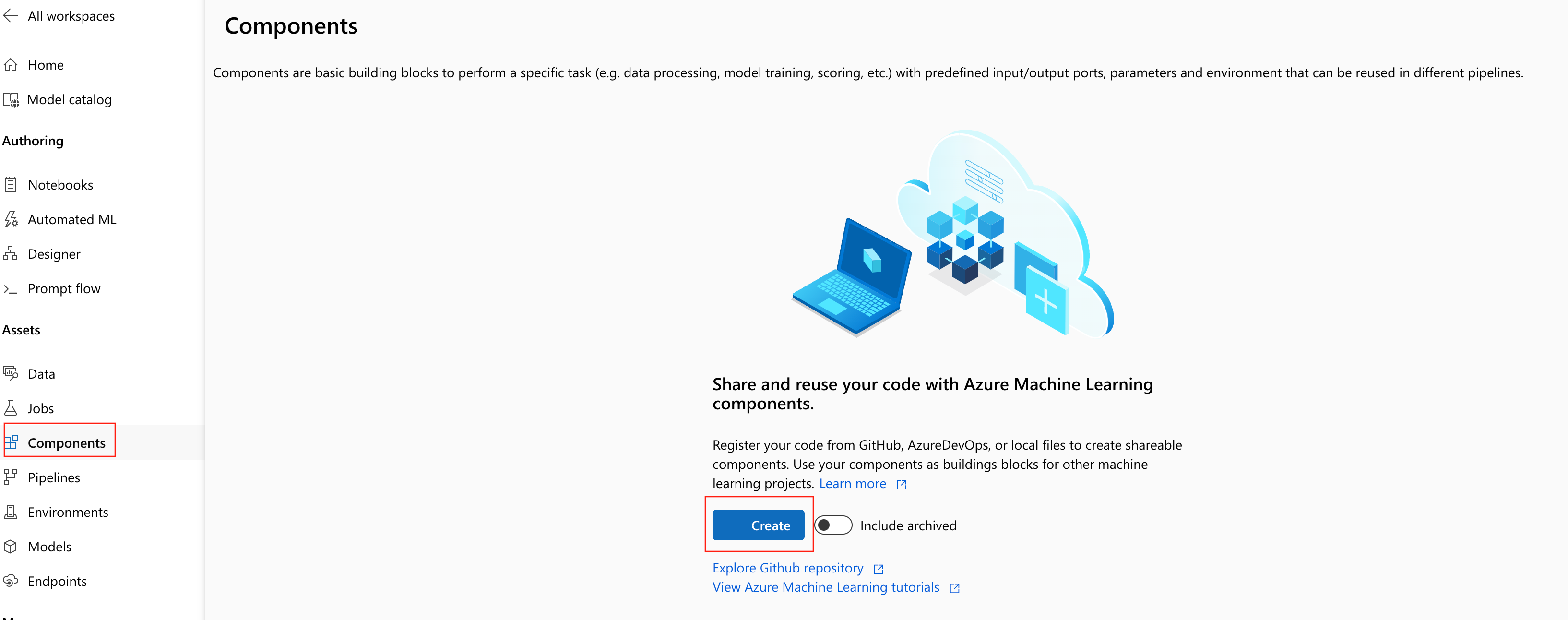
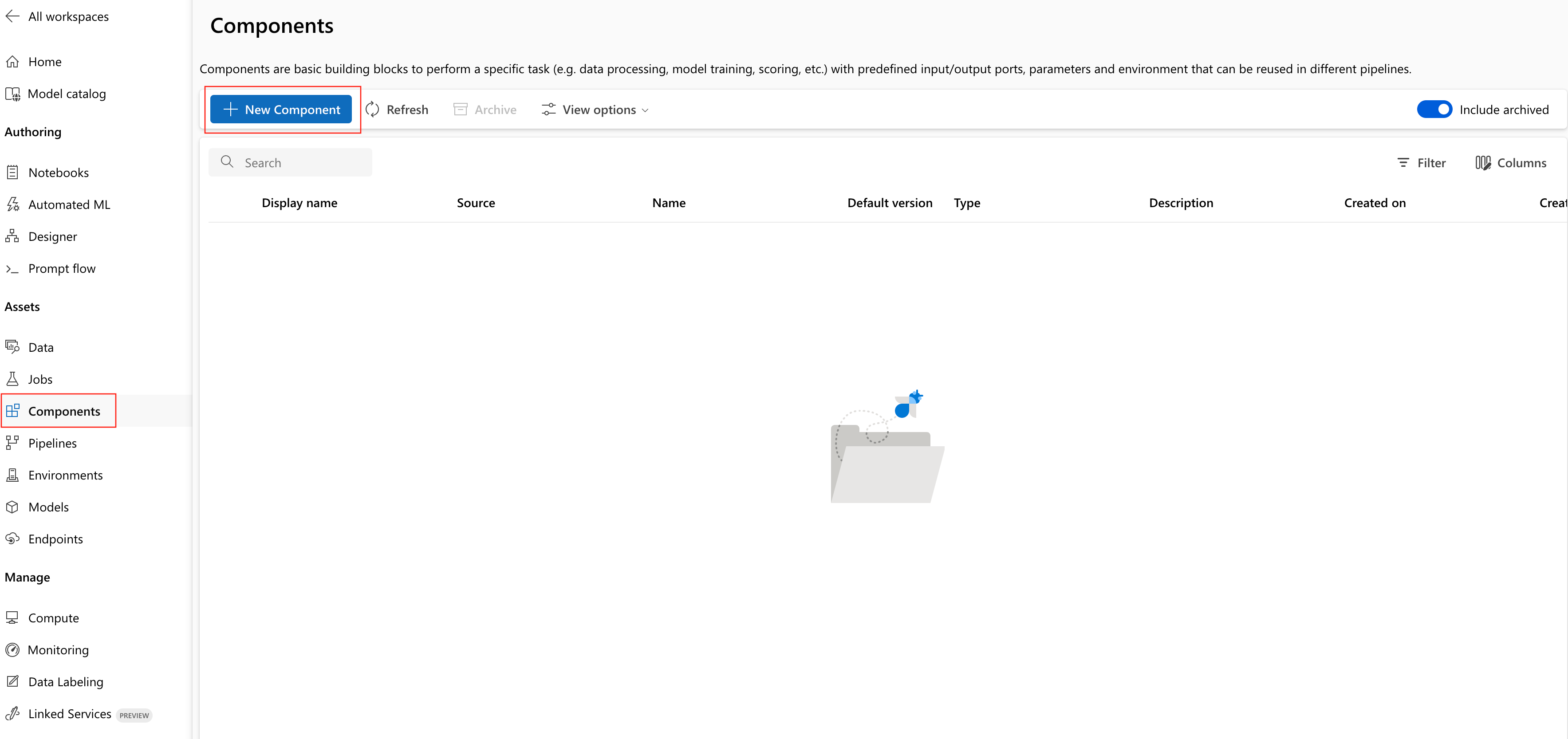


In diesem Beispiel wird train.ymlim Verzeichnis „1b_e2e_registered_components“ verwendet. Die YAML-Datei definiert Namen, Typ, Schnittstelle einschließlich Eingaben und Ausgaben, Code, Umgebung und Befehl dieser Komponente. Der Code dieser Komponente train.py befindet sich im Ordner ./train_src, in dem die Ausführungslogik dieser Komponente beschrieben wird. Weitere Informationen zum Komponentenschema finden Sie in der YAML-Schemareferenz der Befehlskomponente.
Hinweis
Beim Registrieren von Komponenten in der Benutzeroberfläche kann der in der YAML-Komponentendatei definierte code nur auf den aktuellen Ordner verweisen, in dem sich die YAML-Datei oder die Unterordner befinden. Dies bedeutet, dass Sie ../ nicht für code angeben können, da die Benutzeroberfläche das übergeordnete Verzeichnis nicht erkennen kann.
additional_includes kann nur auf den aktuellen Ordner oder den Unterordner verweisen.
Derzeit unterstützt die Benutzeroberfläche nur das Registrieren von Komponenten mit command Typ.
- Wählen Sie „Aus Ordner hochladen“ aus, und wählen Sie den Ordner
1b_e2e_registered_componentsaus, aus dem Sie etwas hochladen möchten. Wählen Sietrain.ymlin der Dropdownliste aus.

Wählen Sie am unteren Rand Weiter aus. Daraufhin können Sie die Details dieser Komponente bestätigen. Nachdem Sie dies bestätigt haben, wählen Sie Erstellen aus, um den Registrierungsvorgang abzuschließen.
Wiederholen Sie die obigen Schritte, um die Komponente „Scoren and Bewerten“ auch mithilfe von
score.ymlundeval.ymlzu registrieren.Nachdem Sie die drei Komponenten erfolgreich registriert haben, werden sie in der Studio-Benutzeroberfläche angezeigt.

Erstellen einer Pipeline mit einer registrierten Komponente
Erstellen Sie eine neue Pipeline im Designer. Denken Sie daran, die Option Benutzerdefiniert zu wählen.
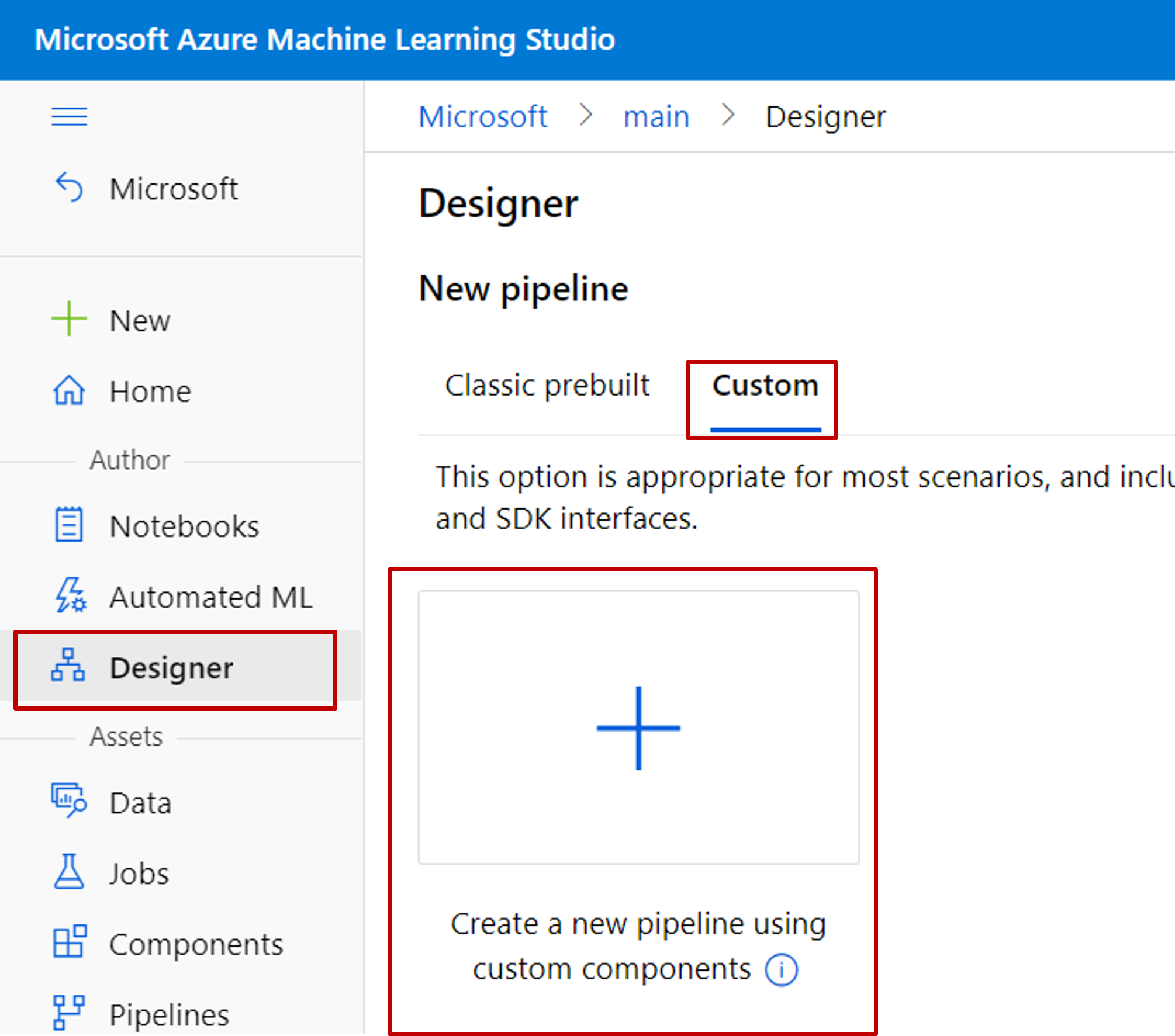
Geben Sie der Pipeline einen aussagekräftigen Namen, indem Sie das Stiftsymbol neben dem automatisch generierten Namen auswählen.

In der Designerobjektbibliothek finden Sie die Registerkarten Daten, Modell und Komponenten. Wechseln Sie zur Registerkarte Komponenten, auf der Sie die im vorherigen Abschnitt registrierten Komponenten sehen können. Wenn es zu viele Komponenten gibt, können Sie über den Komponentennamen suchen.
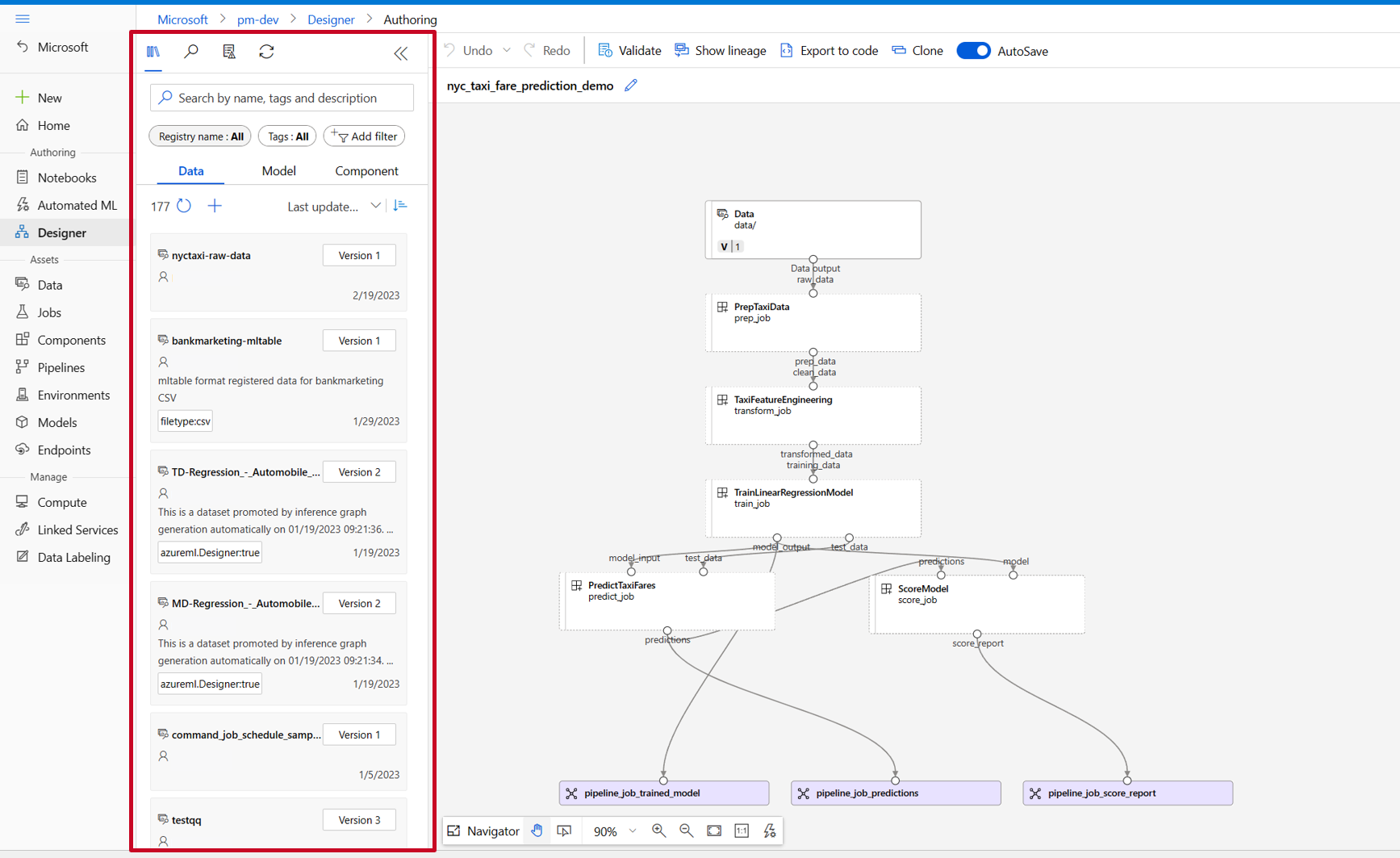
Suchen Sie die im vorherigen Abschnitt registrierten Komponenten train (Training), score (Bewertung) und eval (Auswertung), und ziehen Sie sie per Drag & Drop auf die Canvas. Standardmäßig wird die Standardversion der Komponente verwendet. Um zu einer bestimmten Version zu wechseln, doppelklicken Sie auf die Komponente, um den Komponentenbereich zu öffnen.
In diesem Beispiel verwenden wir die Beispieldaten in dem Datenordner. Registrieren Sie die Daten in Ihrem Arbeitsbereich, indem Sie das Symbol „Hinzufügen“ in der Designerressourcenbibliothek -> Registerkarte „Daten“ auswählen, „Type = Folder(uri_folder)“ festlegen und dann dem Assistenten zur Registrierung der Daten folgen. Der Datentyp muss „uri_folder“ sein, um mit der Definition der Komponente „train“ (Training) übereinzustimmen.

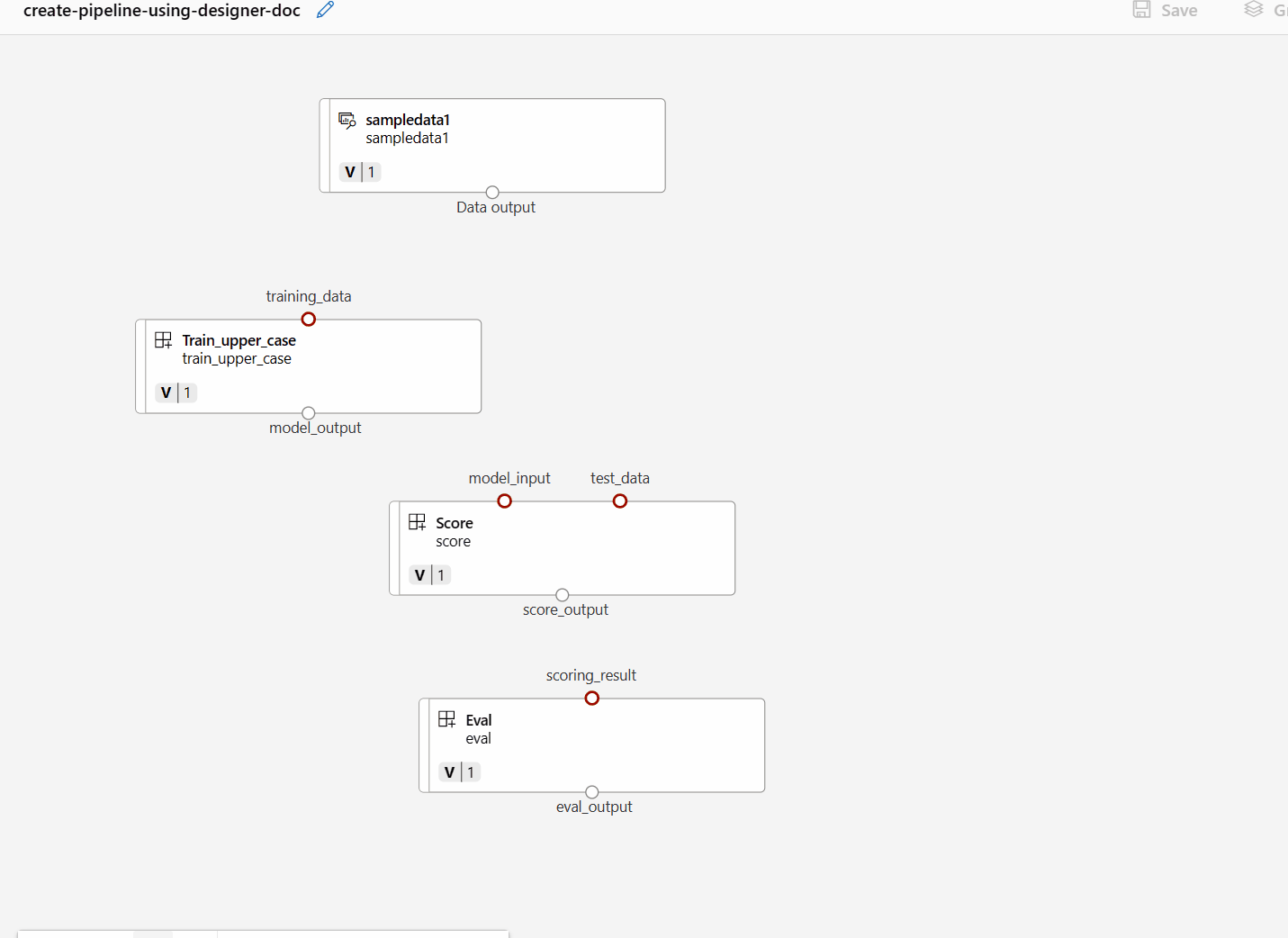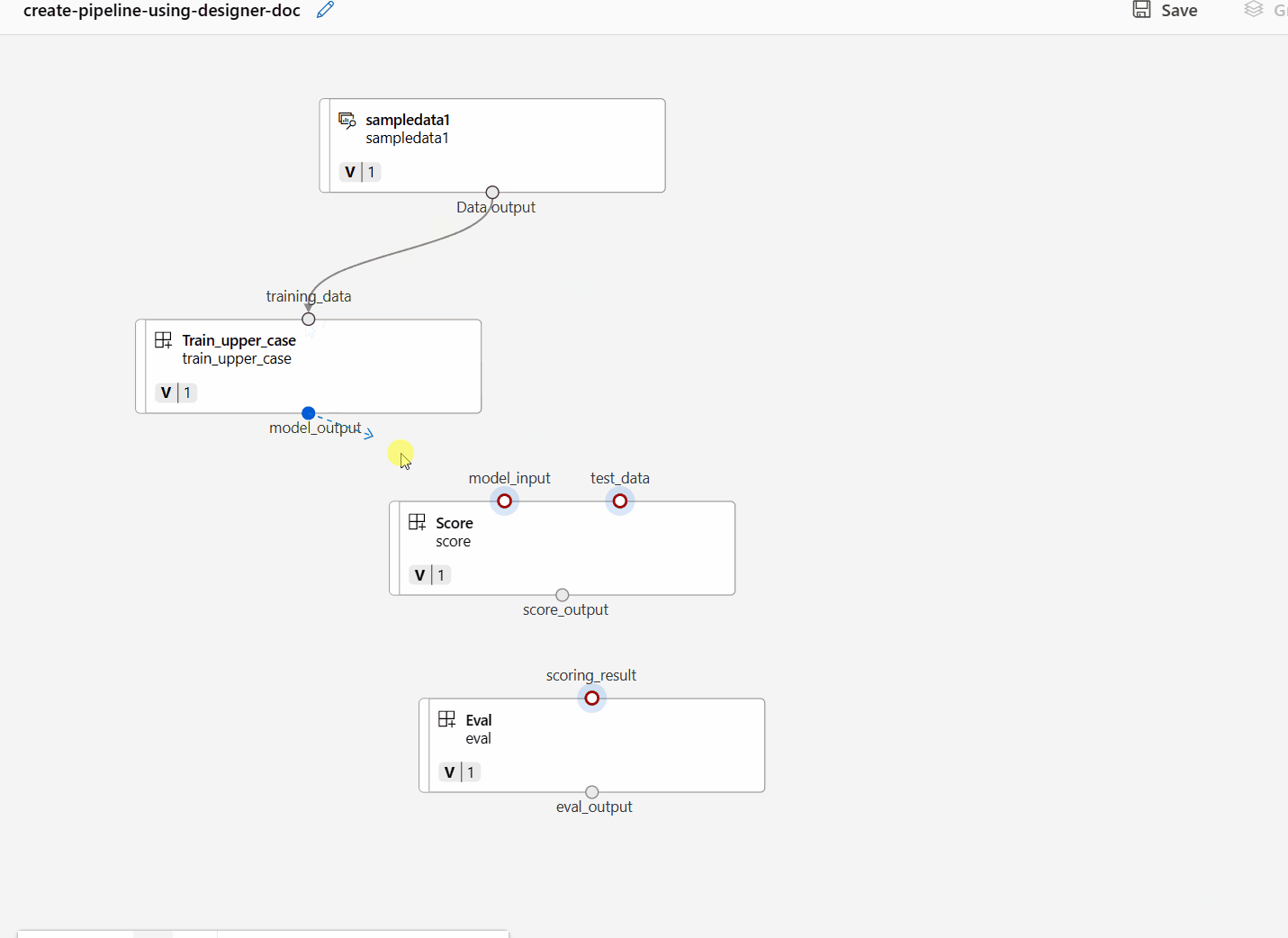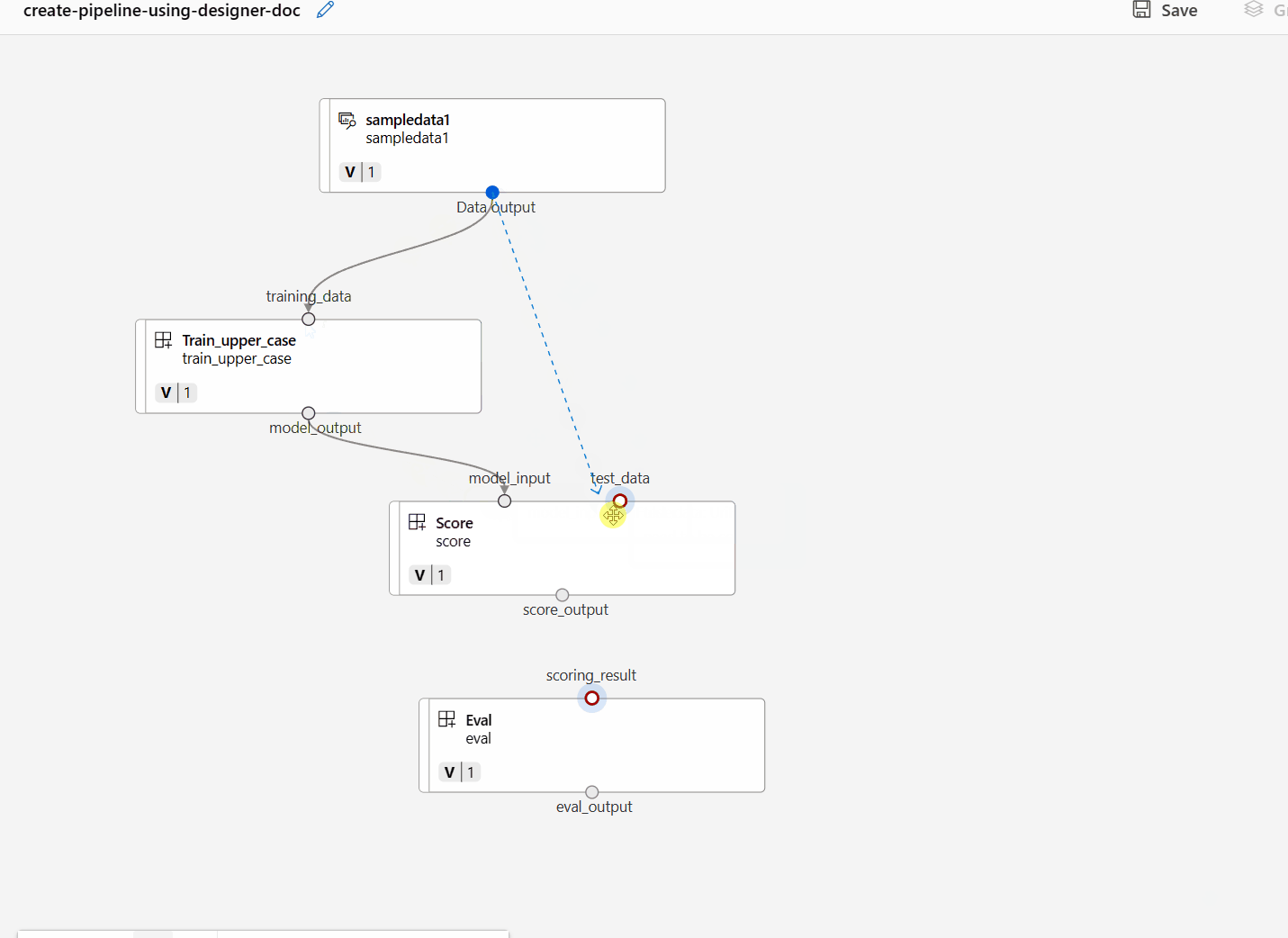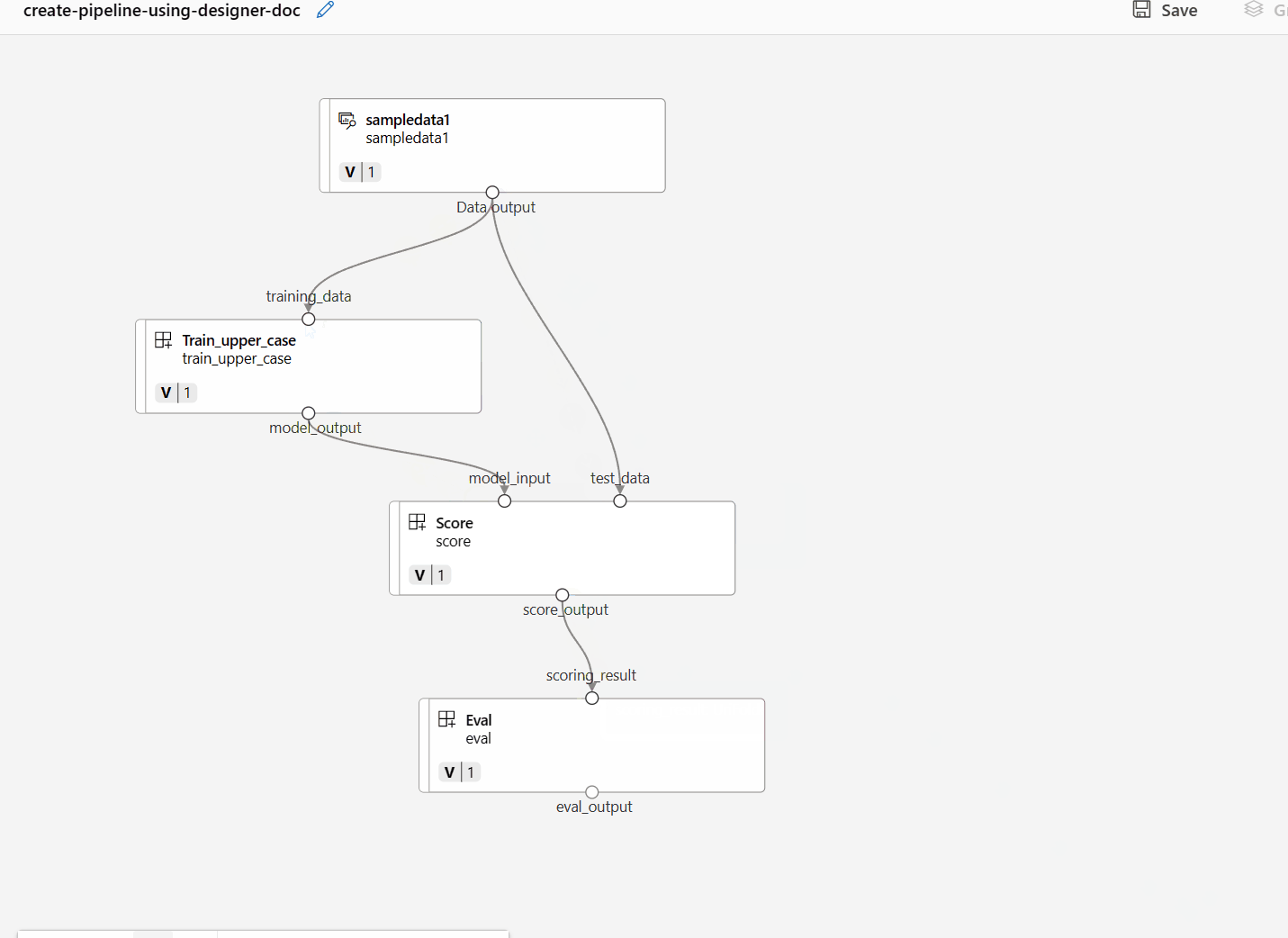
Ziehen Sie die Daten dann per Drag & Drop in die Canvas. Ihre Pipeline sollte jetzt wie im folgenden Screenshot aussehen.

Verbinden Sie die Daten und Komponenten, indem Sie Verbindungen in die Canvas ziehen.
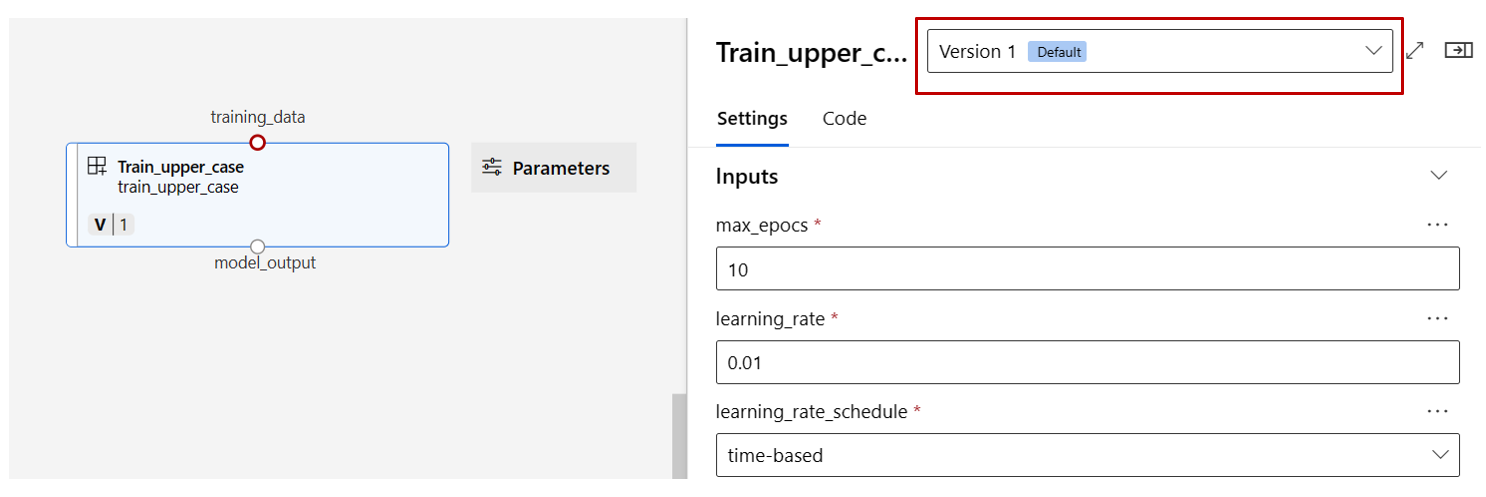
Wenn Sie auf eine Komponente doppelklicken, wird ein rechter Bereich angezeigt, in dem Sie die Komponente konfigurieren können.
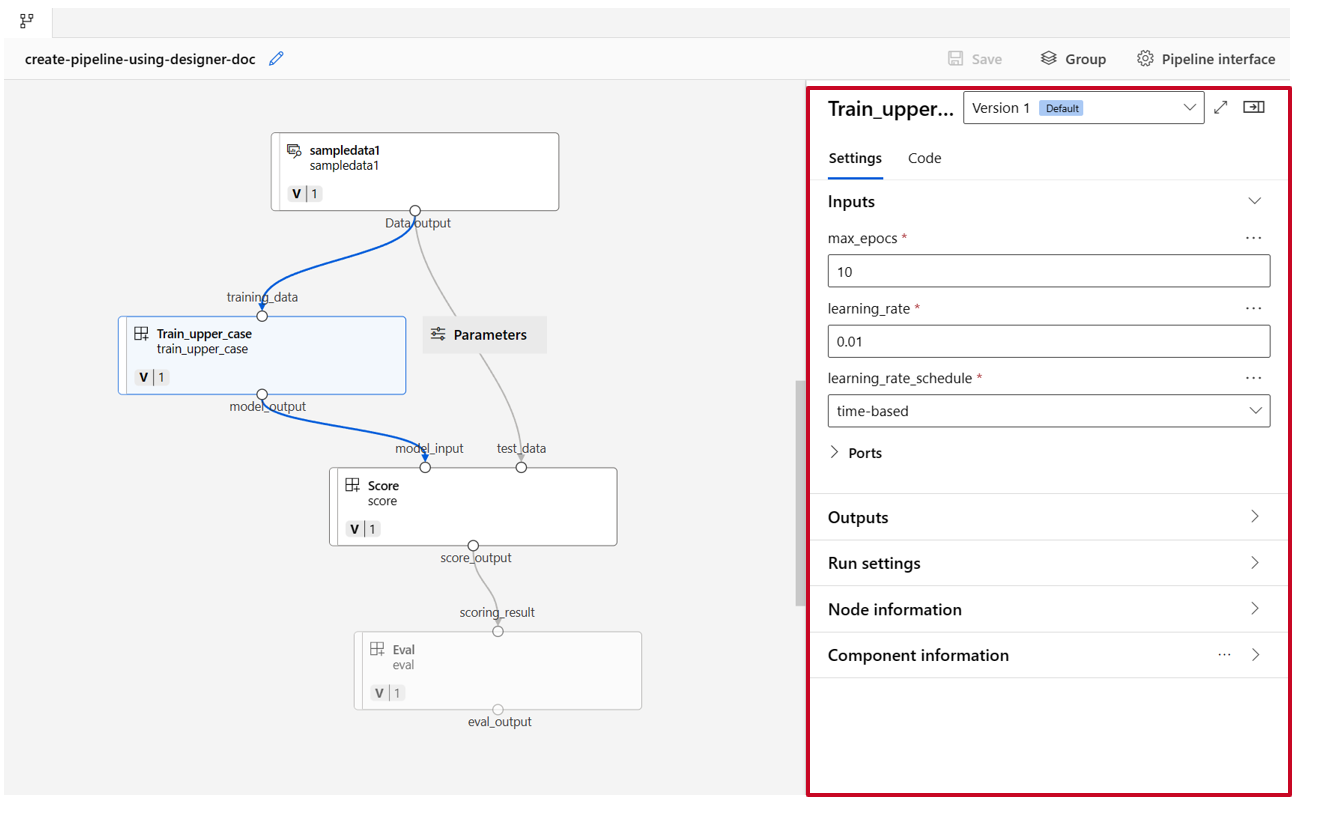
Bei Komponenten mit primitiven Eingabetypen wie Zahlen, ganzen Zahlen, Zeichenfolgen und booleschen Werten können Sie die Werte solcher Eingaben in der Detailansicht der Komponente unter dem Abschnitt Eingaben ändern.
Im rechten Bereich können Sie auch die Ausgabeeinstellungen (wo die Ausgabe der Komponente gespeichert werden soll) und die Ausführungseinstellungen (Computeziel zum Ausführen dieser Komponente) ändern.
Lassen Sie uns jetzt die max_epocs-Eingabe der train-Komponente zur Eingabe auf Pipelineebene höher stufen. Auf diese Weise können Sie dieser Eingabe jedes Mal einen anderen Wert zuweisen, bevor Sie die Pipeline übermitteln.










Hinweis
Benutzerdefinierte Komponenten und die klassischen vordefinierten Komponenten des Designers können nicht zusammen verwendet werden.
Übermitteln der Pipeline
Wählen Sie Konfigurieren und übermitteln aus, um die Pipeline zu übermitteln.

Anschließend sehen Sie eine Schritt-für-Schritt-Anleitung. Folgen Sie den Anweisungen im Assistenten, um den Pipelineauftrag zu übermitteln.

Im Schritt Grundlagen können Sie das Experiment, den Anzeigenamen des Auftrags, die Auftragsbeschreibung usw. konfigurieren.
Im Schritt Eingaben und Ausgaben können Sie die Ein- und Ausgaben konfigurieren, die auf die Pipelineebene höher gestuft werden. Im vorherigen Schritt haben wir max_epocs der Komponente train zur Pipelineeingabe höher gestuft, sodass Sie hier max_epocs sehen und einen Wert zuweisen können sollten.
In Laufzeiteinstellungen können Sie den Standarddatenspeicher und den Standardcompute der Pipeline festlegen. Es ist der Standarddatenspeicher/-compute für alle Komponenten in der Pipeline. Beachten Sie jedoch, dass das System die Einstellung auf Komponentenebene berücksichtigt, wenn Sie einen anderen Compute oder Datenspeicher für eine Komponente explizit festlegen. Andernfalls wird der Standardwert der Pipeline verwendet.
Der Schritt Überprüfen + Übermitteln ist der letzte Schritt zur Überprüfung aller Konfigurationen vor dem Übermitteln. Der Assistent merkt sich die Konfiguration vom letzten Mal, wenn Sie die Pipeline jemals übermitteln.
Nach dem Übermitteln des Pipelineauftrags wird oben eine Meldung mit einem Link zu den Auftragsdetails angezeigt. Sie können diesen Link auswählen, um die Details des Auftrags zu überprüfen.

Angeben der Identität im Pipelineauftrag
Beim Übermitteln des Pipelineauftrags können Sie die Identität für den Zugriff auf die Daten unter Run settings angeben. Die Standardidentität ist AMLToken, wodurch keine Identität verwendet wurde. Mittlerweile werden UserIdentity und Managed unterstützt. Für UserIdentity wird die Identität des Auftragsübermittlers verwendet, um auf die Eingabedaten zuzugreifen und das Ergebnis in den Ausgabeordner zu schreiben. Wenn Sie Managed angeben, verwendet das System die verwaltete Identität, um auf die Eingabedaten zuzugreifen und das Ergebnis in den Ausgabeordner zu schreiben.

Nächste Schritte
- Verwenden Sie diese Jupyter Notebooks auf GitHub, um Pipelines des maschinellen Lernens eingehender zu erkunden.
- Erfahren Sie, wie Sie die CLI v2 verwenden, um die Pipeline mithilfe von Komponenten zu erstellen.
- Erfahren Sie, wie Sie das SDK v2 verwenden, um die Pipeline mithilfe von Komponenten zu erstellen.