Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Azure CLI-ML-Erweiterung v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Ihr MLflow-Modell auf einem Onlineendpunkt für den Echtzeitrückschluss bereitstellen. Wenn Sie Ihr MLflow-Modell für einen Onlineendpunkt bereitstellen, müssen Sie weder ein Bewertungsskript noch eine Umgebung angeben. Diese Funktion wird als Bereitstellung ohne Code bezeichnet.
Bei einer Bereitstellung ohne Code übernimmt Azure Machine Learning diese Aufgaben:
- Installiert Python-Pakete, die Sie in einer Datei "conda.yaml" auflisten, dynamisch. Daher werden Abhängigkeiten während der Containerlaufzeit installiert.
- Stellt ein MLflow-Basisimage oder eine kuratierte Umgebung bereit, die die folgenden Elemente enthält:
- Das
azureml-inference-server-http-Paket - Das
mlflow-skinny-Paket - Ein Bewertungsskript für Rückschlüsse
- Das
Prerequisites
Ein Azure-Abonnement. Wenn Sie noch kein Azure-Abonnement haben, erstellen Sie ein kostenloses Konto, bevor Sie beginnen.
Ein Benutzerkonto mit mindestens einer der folgenden rollenbasierten Azure-Zugriffssteuerungsrollen (Azure RBAC):
- Eine Besitzerrolle für den Azure Machine Learning-Arbeitsbereich
- Mitwirkenderrolle für den Azure Machine Learning-Arbeitsbereich
- Eine benutzerdefinierte Rolle mit
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*Berechtigungen
Weitere Informationen finden Sie unter Verwalten des Zugriffs auf Azure Machine Learning-Arbeitsbereiche.
Zugriff auf Azure Machine Learning:
Installieren Sie die Azure CLI und die
ml-Erweiterung für die Azure CLI. Installationsschritte finden Sie unter Installieren und Einrichten der CLI (v2).
Informationen zum Beispiel
Das Beispiel in diesem Artikel zeigt, wie Sie ein MLflow-Modell für einen Onlineendpunkt bereitstellen, um Vorhersagen durchzuführen. In dem Beispiel wird ein MLflow-Modell verwendet, das auf dem Dataset zu Diabetes basiert. Dieses Dataset enthält 10 Basisvariablen: Alter, Geschlecht, Körpermasseindex, durchschnittlicher Blutdruck und 6 Blutserummessungen aus 442 Diabetespatienten. Es enthält auch die Reaktion von Interesse: einen quantitativen Messwert der Entwicklung der Krankheit ein Jahr nach dem Datum der Basisdaten.
Das Modell wurde mit einem scikit-learn Regressor trainiert. Alle erforderlichen Vorverarbeitungen werden als Pipeline gepackt, daher ist dieses Modell eine End-to-End-Pipeline, die von Rohdaten zu Vorhersagen geht.
Die Informationen in diesem Artikel basieren auf Codebeispielen aus dem azureml-examples -Repository. Wenn Sie das Repository klonen, können Sie die Befehle in diesem Artikel lokal ausführen, ohne YAML-Dateien und andere Dateien kopieren oder einfügen zu müssen. Verwenden Sie die folgenden Befehle, um das Repository zu klonen und zum Ordner für Ihre Codierungssprache zu wechseln:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Nachvollziehen in Jupyter Notebook
Die Schritte in diesem Artikel finden Sie im Beispielrepository unter Bereitstellen des MLflow-Modells für Onlineendpunkte.
Eine Verbindung mit Ihrem Arbeitsbereich herstellen
Stellen Sie eine Verbindung mit Ihrem Azure Machine Learning-Arbeitsbereich her:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<workspace-name> group=<resource-group-name> location=<location>
Registrieren des Modells
Nur registrierte Modelle können für Onlineendpunkte bereitgestellt werden. Die Schritte in diesem Artikel verwenden ein Modell, das für das Diabetes-Dataset trainiert wurde. In diesem Fall ist bereits eine lokale Kopie des Modells in Ihrem geklonten Repository vorhanden, daher muss das Modell nur in der Registrierung im Arbeitsbereich veröffentlicht werden. Sie können diesen Schritt überspringen, wenn das Modell, das Sie bereitstellen möchten, bereits registriert ist.
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

Was, wenn Ihr Modell innerhalb einer Ausführung protokolliert wurde?
Wenn Ihr Modell innerhalb eines Laufs protokolliert wurde, können Sie es direkt registrieren.
Um das Modell zu registrieren, müssen Sie den Speicherort kennen:
- Wenn Sie das MLflow-Feature
autologverwenden, hängt der Pfad zum Modell vom Modelltyp und Framework ab. Überprüfen Sie die Auftragsausgabe, um den Namen des Modellordners zu identifizieren. Dieser Ordner enthält eine Datei mit dem Namen MLModel. - Wenn Sie die
log_modelMethode zum manuellen Protokollieren Ihrer Modelle verwenden, übergeben Sie den Pfad zum Modell als Argument an diese Methode. Wenn Sie das Modell mitmlflow.sklearn.log_model(my_model, "classifier")protokollieren, istclassifierder Pfad, auf dem das Modell gespeichert wird.
Sie können die Azure Machine Learning CLI v2 verwenden, um ein Modell aus der Schulungsauftragsausgabe zu erstellen. Der folgende Code verwendet die Artefakte eines Auftrags mit der ID $RUN_ID, um ein Modell namens $MODEL_NAMEzu registrieren.
$MODEL_PATH ist der Pfad, den der Auftrag zum Speichern des Modells verwendet.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH

Bereitstellen eines MLflow-Modells an einem Onlineendpunkt
Verwenden Sie den folgenden Code, um den Namen und den Authentifizierungsmodus des Endpunkts zu konfigurieren, für den Sie das Modell bereitstellen möchten:
Legen Sie einen Endpunktnamen fest, indem Sie den folgenden Befehl ausführen. Ersetzen Sie
YOUR_ENDPOINT_NAMEzuerst durch einen eindeutigen Namen.export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Um Ihren Endpunkt zu konfigurieren, erstellen Sie eine YAML-Datei namens create-endpoint.yaml, die die folgenden Zeilen enthält:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keyErstellen des Endpunkts:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlKonfigurieren Sie die Bereitstellung. Eine Bereitstellung ist ein Satz von Ressourcen, die für das Hosting des Modells erforderlich sind, das das eigentliche Rückschließen durchführt.
Erstellen Sie eine YAML-Datei namens sklearn-deployment.yaml, die die folgenden Zeilen enthält:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Note
Die automatische Generierung der
scoring_scriptundenvironmentwird nur für diePyFuncModellvariante unterstützt. Informationen zur Verwendung einer anderen Modellvariante finden Sie unter Anpassen von Bereitstellungen von MLflow-Modellen.Erstellen der Bereitstellung:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficaz ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficWeisen Sie den gesamten Datenverkehr der Bereitstellung zu. Bisher verfügt der Endpunkt über genau eine Bereitstellung, es ist ihm aber kein Datenverkehr zugewiesen.
Dieser Schritt ist in der Azure CLI nicht erforderlich, wenn Sie das
--all-traffic-Flag während der Erstellung verwenden. Wenn Sie den Datenverkehr ändern müssen, können Sie denaz ml online-endpoint update --trafficBefehl verwenden. Weitere Informationen zum Aktualisieren des Datenverkehrs finden Sie unter Progressives Aktualisieren des Datenverkehrs.Aktualisieren Sie die Endpunktkonfiguration:
Dieser Schritt ist in der Azure CLI nicht erforderlich, wenn Sie das
--all-traffic-Flag während der Erstellung verwenden. Wenn Sie den Datenverkehr ändern müssen, können Sie denaz ml online-endpoint update --trafficBefehl verwenden. Weitere Informationen zum Aktualisieren des Datenverkehrs finden Sie unter Progressives Aktualisieren des Datenverkehrs.


Endpoint aufrufen
Wenn Ihre Bereitstellung bereit ist, können Sie sie für Anforderungen verwenden. Eine Möglichkeit zum Testen der Bereitstellung ist die Verwendung der integrierten Aufruffunktion in Ihrem Bereitstellungsclient. Im Beispiel-Repository enthält die datei sample-request-sklearn.json den folgenden JSON-Code. Sie können sie als Beispielanforderungsdatei für die Bereitstellung verwenden.
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Note
In dieser Datei wird der Schlüssel input_data anstelle von inputs verwendet, den der MLflow-Dienst verwendet. Azure Machine Learning erfordert ein anderes Eingabeformat, um die Swagger-Verträge für die Endpunkte automatisch generieren zu können. Weitere Informationen zu erwarteten Eingabeformaten finden Sie unter Bereitstellung im integrierten MLflow-Server im Vergleich zur Bereitstellung in Azure Machine Learning-Inferencing-Server.
Senden Sie eine Anforderung an den Endpunkt:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Die Antwort sollte dem folgenden Text ähneln:
[
11633.100167144921,
8522.117402884991
]
Important
Für die MLflow-Bereitstellung ohne Code wird das Testen über lokale Endpunkte derzeit nicht unterstützt.
Anpassen von MLflow-Modellimplementierung
Sie müssen kein Bewertungsskript in der Bereitstellungsdefinition eines MLflow-Modells für einen Onlineendpunkt angeben. Sie können jedoch ein Bewertungsskript angeben, wenn Sie Ihren Ableitungsprozess anpassen möchten.
In der Regel möchten Sie die Bereitstellung des MLflow-Modells in den folgenden Fällen anpassen:
- Das Modell verfügt über keine
PyFunc-Variante. - Sie müssen die Art und Weise, wie Sie das Modell ausführen, anpassen. Sie müssen z. B.
mlflow.<flavor>.load_model()verwenden, um mit einer bestimmten Variante das Modell zu laden. - Sie müssen in Ihrer Bewertungsroutine Vorverarbeitung oder Postverarbeitung durchführen, da das Modell diese Verarbeitung nicht tut.
- Die Ergebnisse des Modells lassen sich nicht gut in Tabellenform darstellen. Die Ausgabe ist beispielsweise ein Tensor, der ein Bild darstellt.
Important
Wenn Sie ein Bewertungsskript für eine MLflow-Modellbereitstellung angeben, müssen Sie auch die Umgebung angeben, in der die Bereitstellung ausgeführt wird.
Bereitstellen eines benutzerdefinierten Bewertungsskripts
Führen Sie die Schritte in den folgenden Abschnitten aus, um ein MLflow-Modell bereitzustellen, das ein benutzerdefiniertes Bewertungsskript verwendet.
Identifizieren des Modellordners
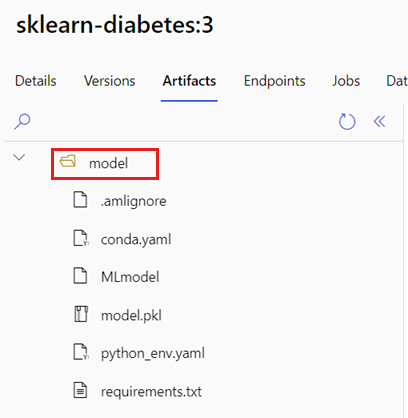
Identifizieren Sie den Ordner, der Ihr MLflow-Modell enthält, indem Sie die folgenden Schritte ausführen:
Navigieren Sie zu Azure Machine Learning Studio.
Navigieren Sie zum Abschnitt Modelle.
Wählen Sie das Modell aus, das Sie bereitstellen möchten, und wechseln Sie zur Registerkarte Artefakte.
Notieren Sie sich den angezeigten Ordner. Wenn Sie ein Modell registrieren, geben Sie diesen Ordner an.

Erstellen eines Bewertungsskripts
Das folgende Bewertungsskript, score.py, stellt ein Beispiel für die Durchführung der Ableitung mit einem MLflow-Modell bereit. Sie können dieses Skript an Ihre Anforderungen anpassen oder die einzelnen Komponenten entsprechend Ihrem Szenario ändern. Beachten Sie, dass der Ordnername, den Sie zuvor identifiziert haben, modelin der init() Funktion enthalten ist.
import logging
import os
import json
import mlflow
from io import StringIO
from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json
def init():
global model
global input_schema
# "model" is the path of the mlflow artifacts when the model was registered. For automl
# models, this is generally "mlflow-model".
model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model")
model = mlflow.pyfunc.load_model(model_path)
input_schema = model.metadata.get_input_schema()
def run(raw_data):
json_data = json.loads(raw_data)
if "input_data" not in json_data.keys():
raise Exception("Request must contain a top level key named 'input_data'")
serving_input = json.dumps(json_data["input_data"])
data = infer_and_parse_json_input(serving_input, input_schema)
predictions = model.predict(data)
result = StringIO()
predictions_to_json(predictions, result)
return result.getvalue()
Warning
MLflow 2.0-Empfehlung: Das Beispielbewertungsskript funktioniert mit MLflow 1.X und MLflow 2.X. Die erwarteten Eingabe- und Ausgabeformate für diese Versionen können jedoch variieren. Überprüfen Sie die Umgebungsdefinition, um festzustellen, welche MLflow-Version Sie verwenden. MLflow 2.0 wird nur in Python 3.8 und höheren Versionen unterstützt.
Erstellen einer Umgebung
Der nächste Schritt besteht darin, eine Umgebung zu erstellen, in der Sie das Bewertungsskript ausführen können. Da das Modell ein MLflow-Modell ist, werden die Conda-Anforderungen auch im Modellpaket angegeben. Weitere Informationen zu den Dateien, die in einem MLflow-Modell enthalten sind, finden Sie im MLmodel-Format. Sie erstellen die Umgebung mithilfe der Conda-Abhängigkeiten aus der Datei. Sie müssen jedoch auch das azureml-inference-server-http Paket einschließen, das für Onlinebereitstellungen in Azure Machine Learning erforderlich ist.
Sie können eine Conda-Definitionsdatei mit dem Namen "conda.yaml" erstellen, die die folgenden Zeilen enthält:
channels:
- conda-forge
dependencies:
- python=3.12
- pip
- pip:
- mlflow
- scikit-learn==1.7.0
- cloudpickle==3.1.1
- psutil==7.0.0
- pandas==2.3.0
- azureml-inference-server-http
name: mlflow-env
Note
Der dependencies Abschnitt dieser Conda-Datei enthält das azureml-inference-server-http Paket.
Verwenden Sie diese Conda-Abhängigkeitsdatei, um die Umgebung zu erstellen:
Die Umgebung wird inline in der Bereitstellungskonfiguration erstellt.
Erstellen der Bereitstellung
Erstellen Sie im Ordner "Endpunkte/online/ncd" eine Bereitstellungskonfigurationsdatei deployment.yml, die die folgenden Zeilen enthält:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: sklearn-diabetes-custom
endpoint_name: my-endpoint
model: azureml:sklearn-diabetes@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04
conda_file: sklearn-diabetes/environment/conda.yaml
code_configuration:
code: sklearn-diabetes/src
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
Erstellen der Bereitstellung:
az ml online-deployment create -f endpoints/online/ncd/deployment.yml


Verarbeiten von Anforderungen
Wenn die Bereitstellung abgeschlossen ist, können Sie Anforderungen stellen. Eine Möglichkeit zum Testen der Bereitstellung ist die Verwendung der invoke Methode mit einer Beispielanforderungsdatei wie der folgenden Datei, sample-request-sklearn.json:
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Senden Sie eine Anforderung an den Endpunkt:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Die Antwort sollte dem folgenden Text ähneln:
{
"predictions": [
1095.2797413413252,
1134.585328803727
]
}
Warning
MLflow 2.0-Empfehlung: In MLflow 1.X enthält die Antwort nicht den predictions Schlüssel.
Bereinigen von Ressourcen
Wenn Sie den Endpunkt nicht mehr benötigen, löschen Sie die zugehörigen Ressourcen:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes