GILT FÜR: Azure CLI ml-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie Ihr Modell für einen Onlineendpunkt bereitstellen, um es für Echtzeitrückschlüsse zu verwenden. Sie beginnen mit der Bereitstellung eines Modells auf Ihrem lokalen Computer, um eventuelle Fehler zu debuggen. Anschließend stellen Sie das Modell in Azure bereit und testen es, zeigen die Bereitstellungsprotokolle an und überwachen die Vereinbarung zum Servicelevel (SLA). Am Ende dieses Artikels verfügen Sie über einen skalierbaren HTTPS/REST-Endpunkt, den Sie für die Echtzeit-Ableitung verwenden können.
Onlineendpunkte sind Endpunkte, die für Echtzeitrückschlüsse verwendet werden. Es gibt zwei Arten von Onlineendpunkten: verwaltete Onlineendpunkte und Kubernetes-Onlineendpunkte. Weitere Informationen zu den Unterschieden finden Sie unter Verwaltete Onlineendpunkte im Vergleich zu Kubernetes-Onlineendpunkten.
Mithilfe von verwalteten Onlineendpunkten können Sie Ihre Machine Learning-Modelle so bereitstellen, dass sie sofort einsatzbereit sind. Verwaltete Onlineendpunkte arbeiten mit leistungsstarken CPU- und GPU-Computern in Azure auf skalierbare, vollständig verwaltete Weise. Verwaltete Onlineendpunkte kümmern sich um die Bereitstellung, Skalierung, Sicherung und Überwachung Ihrer Modelle. Diese Unterstützung befreit Sie vom Aufwand beim Einrichten und Verwalten der zugrunde liegenden Infrastruktur.
Im Hauptbeispiel in diesem Artikel werden verwaltete Online-Endpunkte für die Bereitstellung verwendet. Wenn Sie stattdessen Kubernetes verwenden möchten, lesen Sie bitte die Hinweise in diesem Dokument, die mit der Diskussion über verwaltete Online-Endpunkte übereinstimmen.
Voraussetzungen
GILT FÜR:Azure CLI ml-Erweiterung v2 (aktuell)
Die rollenbasierte Azure-Zugriffssteuerung (Azure RBAC) wird verwendet, um Zugriff auf Vorgänge in Azure Machine Learning zu gewähren. Für das Ausführen der Schritte in diesem Artikel muss Ihrem Benutzerkonto entweder die Rolle "Eigentümer" oder "Mitglied" für den Azure Machine Learning-Arbeitsbereich zugewiesen werden, oder eine benutzerdefinierte Rolle muss dies ermöglichen Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Wenn Sie Azure Machine Learning Studio zum Erstellen und Verwalten von Onlineendpunkten oder Bereitstellungen verwenden, benötigen Sie die zusätzliche Berechtigung Microsoft.Resources/deployments/write vom Ressourcengruppenbesitzer. Weitere Informationen finden Sie unter Verwalten des Zugriffs auf Azure Machine Learning-Arbeitsbereiche.
(Optional) Um lokal bereitzustellen, müssen Sie das Docker-Modul auf Ihrem lokalen Computer installieren. Diese Option wird dringend empfohlen , wodurch das Debuggen von Problemen erleichtert wird.
GILT FÜR: Python SDK azure-ai-ml v2 (aktuell)
Ein Azure Machine Learning-Arbeitsbereich. Schritte zum Erstellen eines Arbeitsbereichs finden Sie unter Erstellen des Arbeitsbereichs.
Das Azure Machine Learning SDK für Python v2. Verwenden Sie den folgenden Befehl, um das SDK zu installieren:
pip install azure-ai-ml azure-identity
Verwenden Sie den folgenden Befehl, um eine vorhandene Installation des SDK auf die neueste Version zu aktualisieren:
pip install --upgrade azure-ai-ml azure-identity
Weitere Informationen finden Sie in der Clientbibliothek des Azure Machine Learning-Pakets für Python.
Azure RBAC wird verwendet, um Zugriff auf Vorgänge in Azure Machine Learning zu gewähren. Für das Ausführen der Schritte in diesem Artikel muss Ihrem Benutzerkonto entweder die Rolle "Eigentümer" oder "Mitglied" für den Azure Machine Learning-Arbeitsbereich zugewiesen werden, oder eine benutzerdefinierte Rolle muss dies ermöglichen Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Weitere Informationen finden Sie unter Verwalten des Zugriffs auf Azure Machine Learning-Arbeitsbereiche.
(Optional) Um lokal bereitzustellen, müssen Sie das Docker-Modul auf Ihrem lokalen Computer installieren. Diese Option wird dringend empfohlen , wodurch das Debuggen von Problemen erleichtert wird.
Bevor Sie die Schritte in diesem Artikel ausführen, stellen Sie sicher, dass Sie über die folgenden Voraussetzungen verfügen:
Die Azure CLI und die CLI-Erweiterung für maschinelles Lernen werden in diesen Schritten verwendet, aber sie sind nicht der Hauptfokus. Sie werden mehr als Hilfsprogramme verwendet, um Vorlagen an Azure zu übergeben und den Status von Vorlagenbereitstellungen zu überprüfen.
- Azure RBAC wird verwendet, um Zugriff auf Vorgänge in Azure Machine Learning zu gewähren. Für das Ausführen der Schritte in diesem Artikel muss Ihrem Benutzerkonto entweder die Rolle "Eigentümer" oder "Mitglied" für den Azure Machine Learning-Arbeitsbereich zugewiesen werden, oder eine benutzerdefinierte Rolle muss dies ermöglichen
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Weitere Informationen finden Sie unter Verwalten des Zugriffs auf einen Azure Machine Learning-Arbeitsbereich.
Stellen Sie sicher, dass genügend VM-Kontingent für die Bereitstellung zugewiesen ist. Azure Machine Learning reserviert 20% Ihrer Computeressourcen zum Ausführen von Upgrades in einigen VM-Versionen. Wenn Sie beispielsweise 10 Instanzen in einer Bereitstellung anfordern, müssen Sie für jede Anzahl von Kernen für die VM-Version ein Kontingent von 12 haben. Wenn Sie diese zusätzlichen Computeressourcen nicht bereitstellen, tritt ein Fehler auf. Einige VM-Versionen sind von der zusätzlichen Kontingentreservierung ausgenommen. Weitere Informationen zur Kontingentzuweisung finden Sie unter Kontingentzuweisung für VMs für die Bereitstellung.
Alternativ können Sie das Kontingent aus dem freigegebenen Azure Machine Learning-Kontingentpool für einen begrenzten Zeitraum verwenden. Azure Machine Learning bietet einen Pool freigegebener Kontingente, aus dem Benutzer in verschiedenen Regionen auf ein Kontingent zugreifen können, um Tests für eine begrenzte Zeit durchzuführen (abhängig von der Verfügbarkeit).
Wenn Sie das Studio verwenden, um Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- oder Deci-DeciLM-Modelle (aus dem Modellkatalog) auf einem verwalteten Onlineendpunkt bereitzustellen, ermöglicht Azure Machine Learning Ihnen für eine kurze Zeit den Zugriff auf diesen freigegebenen Kontingentpool, um Tests durchzuführen. Weitere Informationen zum freigegebenen Kontingentpool finden Sie unter freigegebenes Azure Machine Learning-Kontingent.
Vorbereiten Ihres Systems
Festlegen von Umgebungsvariablen
Wenn Sie die Standardeinstellungen für die Azure-Befehlszeilenschnittstelle noch nicht festgelegt haben, speichern Sie Ihre Standardeinstellungen. Um zu vermeiden, dass Sie die Werte für Ihr Abonnement, Ihren Arbeitsbereich und Ihre Ressourcengruppe mehrfach eingeben müssen, führen Sie den folgenden Code aus:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Klonen des Beispielrepositorys
Um diesem Artikel zu folgen, klonen Sie zuerst das azureml-examples-Repository, und wechseln Sie dann in das azureml-examples/cli-Verzeichnis des Repositorys.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Verwenden Sie --depth 1, um nur den neuesten Commit in das Repository zu klonen, wodurch die Zeit für den Abschluss des Vorgangs verkürzt wird.
Die Befehle in diesem Lernprogramm befinden sich in den Dateien deploy-local-endpoint.sh und deploy-managed-online-endpoint.sh im Cli-Verzeichnis . Die YAML-Konfigurationsdateien befinden sich im Unterverzeichnis endpoints/online/managed/sample/.
Hinweis
Die YAML-Konfigurationsdateien für Kubernetes-Onlineendpunkte befinden sich in den Endpunkten/online/kubernetes/ subdirectory.
Klonen des Beispielrepositorys
Um die Schulungsbeispiele auszuführen, klonen Sie zuerst das Azureml-Beispiele-Repository, und wechseln Sie dann in das azureml-examples/sdk/python/endpoints/online/managed directory:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Verwenden Sie --depth 1, um nur den neuesten Commit in das Repository zu klonen, wodurch die Zeit für den Abschluss des Vorgangs verkürzt wird.
Die Informationen in diesem Artikel stammen aus dem Notebook online-endpoints-simple-deployment.ipynb. Es enthält denselben Inhalt wie dieser Artikel, wobei die Reihenfolge der Codes leicht abweicht.
Herstellen einer Verbindung mit einem Azure Machine Learning-Arbeitsbereich
Der Arbeitsbereich ist die Ressource der obersten Ebene für Azure Machine Learning. Es bietet einen zentralen Ort für die Arbeit mit allen Artefakten, die Sie erstellen, wenn Sie Azure Machine Learning verwenden. In diesem Abschnitt stellen Sie eine Verbindung mit dem Arbeitsbereich her, in dem Sie Bereitstellungsaufgaben ausführen. Öffnen Sie Ihr online-endpoints-simple-deployment.ipynb-Notizbuch, um den Anweisungen zu folgen.
Importieren Sie die erforderlichen Bibliotheken.
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Hinweis
Wenn Sie den Kubernetes-Onlineendpunkt verwenden, importieren Sie die Klassen KubernetesOnlineEndpoint und KubernetesOnlineDeployment aus der azure.ai.ml.entities Bibliothek.
Konfigurieren Sie Arbeitsbereichsdetails und rufen Sie einen Handle für den Arbeitsbereich ab.
Um eine Verbindung mit einem Arbeitsbereich herzustellen, benötigen Sie diese Bezeichnerparameter: ein Abonnement, eine Ressourcengruppe und einen Arbeitsbereichsnamen. Sie verwenden diese Details in MLClient von azure.ai.ml, um Zugriff auf den erforderlichen Azure Machine Learning-Arbeitsbereich zu erhalten. In diesem Beispiel wird die Azure-Standardauthentifizierung verwendet.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Wenn Sie Git auf Ihrem lokalen Computer installiert haben, können Sie der Anleitung zum Klonen des Beispielrepositorys folgen. Folgen Sie andernfalls den Anweisungen zum Herunterladen von Dateien aus dem Beispielrepository.
Klonen des Beispielrepositorys
Um diesem Artikel zu folgen, klonen Sie zuerst das azureml-examples Repository und wechseln Sie dann in das Verzeichnis azureml-examples/cli/endpoints/online/model-1.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Verwenden Sie --depth 1, um nur den neuesten Commit in das Repository zu klonen, wodurch die Zeit für den Abschluss des Vorgangs verkürzt wird.
Herunterladen von Dateien aus dem Beispielrepository
Wenn Sie das Beispielrepository geklont haben, verfügt Ihr lokaler Computer bereits über Kopien der Dateien für dieses Beispiel, und Sie können mit dem nächsten Abschnitt fortfahren. Wenn Sie das Repository nicht geklont haben, laden Sie es auf Ihren lokalen Computer herunter.
- Wechseln Sie zum Beispiel-Repository (azureml-examples).
- Wechseln Sie zur <> Schaltfläche "Code " auf der Seite, und wählen Sie dann auf der Registerkarte " Lokal " die Option "ZIP herunterladen" aus.
- Suchen Sie den Ordner /cli/endpoints/online/model-1/model-1/model und die Datei /cli/endpoints/online/model-1/onlinescoring/score.py.
Festlegen von Umgebungsvariablen
Legen Sie die folgenden Umgebungsvariablen fest, damit Sie sie in den Beispielen in diesem Artikel verwenden können. Ersetzen Sie die Werte durch Ihre Azure-Abonnement-ID, die Azure-Region, in der sich Ihr Arbeitsbereich befindet, die Ressourcengruppe, die den Arbeitsbereich enthält, und den Namen des Arbeitsbereichs:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Ein paar Vorlagenbeispiele erfordern das Hochladen von Dateien in Azure Blob Storage für Ihren Arbeitsbereich. In den folgenden Schritten wird der Arbeitsbereich abgefragt, und diese Informationen werden in den in den Beispielen verwendeten Umgebungsvariablen gespeichert:
Abrufen eines Zugriffstokens:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Festlegen der REST-API-Version:
API_VERSION="2022-05-01"
Abrufen der Speicherinformationen:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
Klonen des Beispielrepositorys
Um diesem Artikel zu folgen, klonen Sie zuerst das Azureml-Beispielrepository, und wechseln Sie dann in das Verzeichnis "azureml-examples ":
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Verwenden Sie --depth 1, um nur den neuesten Commit in das Repository zu klonen, wodurch die Zeit für den Abschluss des Vorgangs verkürzt wird.
Definieren des Endpunkts
Um einen Onlineendpunkt zu definieren, geben Sie den Endpunktnamen und den Authentifizierungsmodus an. Weitere Informationen zu verwalteten Onlineendpunkten finden Sie unter "Online-Endpunkte".
Festlegen eines Endpunktnamens
Führen Sie den folgenden Befehl aus, um einen Endpunktnamen festzulegen. Ersetzen Sie <YOUR_ENDPOINT_NAME> durch einen Namen, der innerhalb der Azure-Region eindeutig ist. Weitere Informationen zu den Benennungsregeln finden Sie unter Endpunktgrenzwerte.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Der folgende Ausschnitt zeigt die Datei endpoints/online/managed/sample/endpoint.yml:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Die Referenz für das YAML-Endpunktformat wird in der folgenden Tabelle beschrieben. Informationen zum Angeben dieser Attribute finden Sie in der YaML-Referenz für den Onlineendpunkt. Informationen zu Grenzwerten im Zusammenhang mit verwalteten Endpunkten finden Sie unter Azure Machine Learning-Onlineendpunkte und Batchendpunkte.
| Schlüssel |
BESCHREIBUNG |
$schema |
(Optional) Das YAML-Schema. Sie können das Schema aus dem vorherigen Codeschnipsel in einem Browser anzeigen, um sich alle verfügbaren Optionen in der YAML-Datei anzusehen. |
name |
Der Name des Endpunkts. |
auth_mode |
Verwenden Sie key für schlüsselbasierte Authentifizierung.
Verwenden Sie aml_token für die tokenbasierte Azure Machine Learning-Authentifizierung.
Verwenden Sie aad_token für die tokenbasierte Microsoft Entra-Authentifizierung (Preview).
Weitere Informationen zur Authentifizierung finden Sie unter Authentifizieren von Clients für Onlineendpunkte. |
Definieren Sie zuerst den Namen des Onlineendpunkts, und konfigurieren Sie dann den Endpunkt.
Ersetzen Sie <YOUR_ENDPOINT_NAME> den Namen durch einen namen, der in der Azure-Region eindeutig ist, oder verwenden Sie die Beispielmethode, um einen zufälligen Namen zu definieren. Löschen Sie unbedingt die Methode, die Sie nicht verwenden. Weitere Informationen zu den Benennungsregeln finden Sie unter Endpunktgrenzwerte.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
Der vorherige Code verwendet key für die schlüsselbasierte Authentifizierung. Um die tokenbasierte Azure Machine Learning-Authentifizierung zu verwenden, verwenden Sie aml_token. Verwenden Sie für die tokenbasierte Microsoft Entra-Authentifizierung (Preview) aad_token. Weitere Informationen zur Authentifizierung finden Sie unter Authentifizieren von Clients für Onlineendpunkte.
Wenn Sie die Bereitstellung in Azure über Studio durchführen, erstellen Sie einen Endpunkt und eine Bereitstellung, die sie diesem hinzufügen. Zu diesem Zeitpunkt werden Sie aufgefordert, Namen für den Endpunkt und die Bereitstellung anzugeben.
Festlegen eines Endpunktnamens
Führen Sie zum Festlegen des Endpunktnamens den folgenden Befehl aus, um einen zufälligen Namen zu generieren. Er muss in der Azure-Region eindeutig sein. Weitere Informationen zu den Benennungsregeln finden Sie unter Endpunktgrenzwerte.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
Um den Endpunkt und die Bereitstellung zu definieren, verwendet dieser Artikel die Azure Resource Manager-Vorlagen (ARM-Vorlagen) online-endpoint.json und online-endpoint-deployment.json. Informationen zur Verwendung der Vorlagen zum Definieren eines Onlineendpunkts und einer Bereitstellung finden Sie im Abschnitt "Bereitstellen in Azure ".
Definieren der Bereitstellung
Eine Einrichtung ist ein Satz von Ressourcen, die für das Hosting des Modells erforderlich sind, das die eigentliche Inferenz durchführt. In diesem Beispiel stellen Sie ein scikit-learn Modell bereit, das Regression durchführt und ein Bewertungsskript score.py verwendet, um das Modell für eine bestimmte Eingabeanforderung auszuführen.
Informationen zu den wichtigsten Attributen einer Bereitstellung finden Sie unter Onlinebereitstellungen.
Ihre Bereitstellungskonfiguration verwendet den Speicherort des Modells, das Sie bereitstellen möchten.
Der folgende Ausschnitt zeigt die Datei endpoints/online/managed/sample/blue-deployment.yml mit allen notwendigen Eingabedaten, um eine Bereitstellung zu konfigurieren.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Die datei blue-deployment.yml gibt die folgenden Bereitstellungsattribute an:
model: Gibt die Modelleigenschaften inline mithilfe des path Parameters an (wo Dateien hochgeladen werden sollen). Die CLI lädt die Modelldateien automatisch hoch und registriert das Modell mit einem automatisch generierten Namen.environment: Verwendet Inlinedefinitionen, woher Dateien hochgeladen werden sollen. Die CLI lädt die Datei "conda.yaml " automatisch hoch und registriert die Umgebung. Später verwendet die Bereitstellung zum Erstellen der Umgebung den Parameter image für das Basisimage. In diesem Beispiel ist es mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Die conda_file Abhängigkeiten werden über dem Basisimage installiert.code_configuration: Lädt die lokalen Dateien, z. B. die Python-Quelle für das Bewertungsmodell, aus der Entwicklungsumgebung während der Bereitstellung hoch.
Weitere Informationen zum YAML-Schema finden Sie in der YaML-Referenz zum Onlineendpunkt.
Hinweis
So verwenden Sie Kubernetes-Endpunkte anstelle von verwalteten Onlineendpunkten als Computeziel:
- Erstellen Sie Ihren Kubernetes-Cluster, und fügen Sie ihn mithilfe von Azure Machine Learning Studio als Computeziel an Ihren Azure Machine Learning-Arbeitsbereich an.
- Verwenden Sie den Endpunkt YAML , um Kubernetes anstelle des verwalteten Endpunkts YAML als Ziel zu verwenden. Sie müssen den YAML-Code bearbeiten, um den Wert von
compute in den Namen Ihres registrierten Computeziels zu ändern. Sie können diese deployment.yaml verwenden, die andere Eigenschaften enthält, die für eine Kubernetes-Bereitstellung gelten.
Alle Befehle, die in diesem Artikel für verwaltete Onlineendpunkte verwendet werden, gelten auch für Kubernetes-Endpunkte, mit Ausnahme der folgenden Funktionen, die nicht für Kubernetes-Endpunkte gelten:
Verwenden Sie den folgenden Code, um eine Bereitstellung zu konfigurieren:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Model: Gibt die Modelleigenschaften inline mithilfe des path Parameters an (wo Dateien hochgeladen werden sollen). Das SDK lädt die Modelldateien automatisch hoch und registriert das Modell mit einem automatisch generierten Namen.Environment: Verwendet Inlinedefinitionen, woher Dateien hochgeladen werden sollen. Das SDK lädt automatisch die Datei "conda.yaml " hoch und registriert die Umgebung. Später verwendet die Bereitstellung zum Erstellen der Umgebung den Parameter image für das Basisimage. In diesem Beispiel ist es mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Die conda_file Abhängigkeiten werden über dem Basisimage installiert.CodeConfiguration: Lädt die lokalen Dateien, z. B. die Python-Quelle für das Bewertungsmodell, aus der Entwicklungsumgebung während der Bereitstellung hoch.
Weitere Informationen zur Definition der Onlinebereitstellung finden Sie unter "OnlineDeployment Class".
Wenn Sie in Azure bereitstellen, erstellen Sie einen Endpunkt und fügen ihm ein Deployment hinzu. Zu diesem Zeitpunkt werden Sie aufgefordert, Namen für den Endpunkt und die Bereitstellung anzugeben.
Grundlegendes zum Bewertungsskript
Das Format des Bewertungsskripts für Onlineendpunkte entspricht dem Format, das in der vorherigen Version der CLI und im Python SDK verwendet wurde.
Das in code_configuration.scoring_script angegebene Bewertungsskript muss über eine init()-Funktion und eine run()-Funktion verfügen.
Das Bewertungsskript muss über eine init()-Funktion und eine run()-Funktion verfügen.
Das Bewertungsskript muss über eine init()-Funktion und eine run()-Funktion verfügen.
Das Bewertungsskript muss über eine init()-Funktion und eine run()-Funktion verfügen. In diesem Artikel wird die datei score.py verwendet.
Wenn Sie eine Vorlage für die Bereitstellung verwenden, müssen Sie zuerst die Bewertungsdatei in Blob Storage hochladen und dann registrieren:
Der folgende Code verwendet den Azure CLI-Befehl az storage blob upload-batch zum Hochladen der Bewertungsdatei:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
Der folgende Code verwendet eine Vorlage, um den Code zu registrieren:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
In diesem Beispiel wird die score.py Datei aus dem Repository verwendet, das Sie geklont oder zuvor heruntergeladen haben:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
Die init()-Funktion wird aufgerufen, wenn der Container initialisiert oder gestartet wird. Die Initialisierung erfolgt in der Regel kurz nach dem Erstellen oder Aktualisieren der Bereitstellung. Die init Funktion ist der Ort zum Schreiben von Logik für globale Initialisierungsvorgänge wie das Zwischenspeichern des Modells im Arbeitsspeicher (wie in dieser score.py Datei dargestellt).
Die run() Funktion wird jedes Mal aufgerufen, wenn der Endpunkt aufgerufen wird. Sie führt die tatsächliche Bewertung und Vorhersage durch. In dieser score.py Datei extrahiert die run() Funktion Daten aus einer JSON-Eingabe, ruft die Methode des predict() Scikit-Learn-Modells auf und gibt dann das Vorhersageergebnis zurück.
Lokales Bereitstellen und Debuggen mithilfe eines lokalen Endpunkts
Es wird dringend empfohlen , den Endpunkt lokal auszuführen, um Ihren Code und Ihre Konfiguration zu überprüfen und zu debuggen, bevor Sie sie in Azure bereitstellen. Das Azure CLI und Python SDK unterstützen lokale Endpunkte und Bereitstellungen, aber Azure Machine Learning Studio und ARM-Vorlagen sind nicht vorhanden.
Um lokal bereitzustellen, muss das Docker-Modul installiert und ausgeführt werden. Die Docker-Engine wird in der Regel gestartet, wenn der Computer gestartet wird. Wenn dies nicht der Fall ist, können Sie die Problembehandlung für die Docker-Engine durchführen.
Sie können das Azure Machine Learning-Ableitungs-HTTP-Server-Python-Paket verwenden, um Ihr Bewertungsskript lokal ohne Docker Engine zu debuggen. Das Debuggen mit dem Ableitungsserver hilft Ihnen beim Debuggen des Bewertungsskripts, bevor Sie es für lokale Endpunkte bereitstellen, sodass Sie debuggen können, ohne dass sie von den Bereitstellungscontainerkonfigurationen betroffen sind.
Weitere Informationen zum lokalen Debuggen von Onlineendpunkten vor der Bereitstellung in Azure finden Sie unter Online-Endpunktdebugging.
Lokales Bereitstellen des Modells
Erstellen Sie zuerst einen Endpunkt. Optional können Sie diesen Schritt für einen lokalen Endpunkt überspringen. Sie können die Bereitstellung direkt (nächster Schritt) erstellen, wodurch wiederum die erforderlichen Metadaten erstellt werden. Die lokale Bereitstellung von Modellen ist für Entwicklungs- und Testzwecke nützlich.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
Das Studio unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Die Vorlage unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Erstellen Sie nun eine Bereitstellung mit dem Namen blue unter dem Endpunkt.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
Das --local-Flag weist die CLI an, den Endpunkt in der Docker-Umgebung bereitzustellen.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
Das local=True-Flag weist das SDK an, den Endpunkt in der Docker-Umgebung bereitzustellen.
Das Studio unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Die Vorlage unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Überprüfen Sie, ob die lokale Bereitstellung erfolgreich war.
Überprüfen Sie den Bereitstellungsstatus, um festzustellen, ob das Modell ohne Fehler bereitgestellt wurde:
az ml online-endpoint show -n $ENDPOINT_NAME --local
Die Ausgabe sollte in etwa dem folgenden JSON-Code entsprechen. Der provisioning_state Parameter ist Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
Die Methode gibt die Entität zurückManagedOnlineEndpoint. Der provisioning_state Parameter ist Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
Das Studio unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Die Vorlage unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Die folgende Tabelle enthält die möglichen Werte für provisioning_state:
| Wert |
BESCHREIBUNG |
Creating |
Die Ressource wird erstellt. |
Updating |
Die Ressource wird aktualisiert. |
Deleting |
Die Ressource wird gelöscht. |
Succeeded |
Der Erstellungs- oder Aktualisierungsvorgang war erfolgreich. |
Failed |
Fehler beim Erstellen, Aktualisieren oder Löschen. |
Aufrufen des lokalen Endpunkts zum Bewerten von Daten mit Ihrem Modell
Rufen Sie den Endpunkt auf, um das Modell mithilfe des Befehls invoke und der Übergabe von in einer JSON-Datei gespeicherten Abfrageparametern zu bewerten:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Wenn Sie einen REST-Client (z. B. curl) verwenden möchten, müssen Sie über den Bewertungs-URI verfügen. Führen Sie az ml online-endpoint show --local -n $ENDPOINT_NAME aus, um den Bewertungs-URI abzurufen. Suchen Sie in den zurückgegebenen Daten das Attribut scoring_uri.
Rufen Sie den Endpunkt auf, um das Modell mithilfe des Befehls invoke und der Übergabe von in einer JSON-Datei gespeicherten Abfrageparametern zu bewerten.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Wenn Sie einen REST-Client (z. B. curl) verwenden möchten, müssen Sie über den Bewertungs-URI verfügen. Führen Sie den folgenden Code aus, um den Bewertungs-URI abzurufen. Suchen Sie in den zurückgegebenen Daten das Attribut scoring_uri.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
Das Studio unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Die Vorlage unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Überprüfen der Protokolle hinsichtlich der Ausgaben des Aufrufvorgangs
Im Beispiel score.py Datei protokolliert die run() Methode einige Ausgaben in der Konsole.
Sie können diese Ausgabe mit dem Befehl get-logs anzeigen:
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
Sie können diese Ausgabe mit der Methode get_logs anzeigen:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
Das Studio unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Die Vorlage unterstützt keine lokalen Endpunkte. Schritte zum lokalen Testen des Endpunkts finden Sie auf den Registerkarten Azure CLI oder Python.
Bereitstellen Ihres Onlineendpunkts in Azure
Stellen Sie als nächstes Ihren Onlineendpunkt in Azure bereit. Als bewährte Vorgehensweise für die Produktion wird empfohlen, das Modell und die Umgebung, die Sie in Ihrem Bereitstellungsprozess verwenden, zu registrieren.
Registrieren Ihres Modells und Ihrer Umgebung
Es wird empfohlen, Ihr Modell und Ihre Umgebung vor der Bereitstellung in Azure zu registrieren, damit Sie ihre registrierten Namen und Versionen während der Bereitstellung angeben können. Nachdem Sie Ihre Ressourcen registriert haben, können Sie sie wiederverwenden, ohne sie jedes Mal hochladen zu müssen, wenn Sie Bereitstellungen erstellen. Diese Praxis erhöht die Reproduzierbarkeit und Rückverfolgbarkeit.
Anders als bei der Bereitstellung in Azure können Sie bei der lokalen Bereitstellung keine registrierten Modelle und Umgebungen verwenden. Stattdessen verwendet die lokale Bereitstellung lokale Modelldateien und verwendet Umgebungen nur mit lokalen Dateien.
Für die Bereitstellung in Azure können Sie entweder lokale oder registrierte Ressourcen (Modelle und Umgebungen) verwenden. In diesem Abschnitt des Artikels werden für die Bereitstellung in Azure registrierte Ressourcen verwendet, aber Sie haben auch die Möglichkeit, stattdessen lokale Ressourcen zu verwenden. Ein Beispiel für eine Bereitstellungskonfiguration, die lokale Dateien hochlädt, die für die lokale Bereitstellung verwendet werden, finden Sie unter Konfigurieren einer Bereitstellung.
Um das Modell und die Umgebung zu registrieren, verwenden Sie das Formular model: azureml:my-model:1 oder environment: azureml:my-env:1.
Für die Registrierung können Sie die YAML-Definitionen von model und environment in separate YAML-Dateien im endpunkte/online/verwaltet/beispiel Ordner extrahieren und die Befehle az ml model create und az ml environment create verwenden. Führen Sie az ml model create -h und az ml environment create -h aus, um mehr über diese Befehle zu erfahren.
Erstellen Sie eine YAML-Definition für das Modell. Benennen Sie die Datei model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Registrieren des Modells:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Erstellen Sie eine YAML-Definition für die Umgebung. Benennen Sie die Datei environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Registrieren Sie die Umgebung:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Weitere Informationen zum Registrieren Ihres Modells als Ressource finden Sie unter Registrieren eines Modells mithilfe der Azure CLI oder python SDK. Weitere Informationen zum Erstellen einer Umgebung finden Sie unter Erstellen einer benutzerdefinierten Umgebung.
Registrieren eines Modells:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Registrieren Sie die Umgebung:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Informationen zum Registrieren Ihres Modells als Ressource, damit Sie während der Bereitstellung den registrierten Namen und die Version angeben können, finden Sie unter Registrieren eines Modells mithilfe des Azure CLI oder Python SDK.
Weitere Informationen zum Erstellen einer Umgebung finden Sie unter Erstellen einer benutzerdefinierten Umgebung.
Registrieren des Modells
Eine Modellregistrierung ist eine logische Entität im Arbeitsbereich, die eine einzelne Modelldatei oder ein Verzeichnis mit mehreren Dateien enthalten kann. Als bewährte Methode für die Produktion registrieren Sie das Modell und die Umgebung. Bevor Sie den Endpunkt und die Bereitstellung in diesem Artikel erstellen, registrieren Sie den Modellordner, der das Modell enthält.
Gehen Sie wie folgt vor, um das Beispielmodell zu registrieren:
Wechseln Sie zum Azure Machine Learning-Studio.
Wählen Sie im linken Bereich die Seite "Modelle " aus.
Wählen Sie "Registrieren" und dann "Aus lokalen Dateien" aus.
Wählen Sie für den Modelltyp "Nicht angegeben" aus.
Wählen Sie "Durchsuchen" und dann " Ordner durchsuchen" aus.
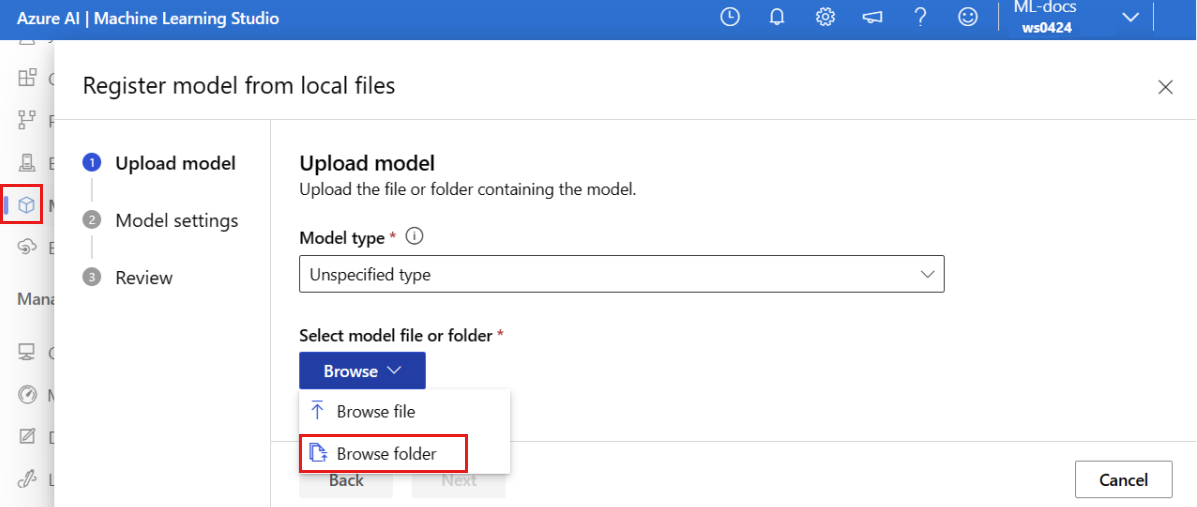
Wählen Sie den Ordner \azureml-examples\cli\endpoints\online\model-1\model aus der lokalen Kopie des Repositorys aus, die Sie zuvor geklont oder heruntergeladen haben. Wenn Sie dazu aufgefordert werden, wählen Sie "Hochladen" aus, und warten Sie, bis der Upload abgeschlossen ist.
Wählen Sie "Weiter" aus.
Geben Sie einen Anzeigenamen für das Modell ein. Bei den Schritten in diesem Artikel wird davon ausgegangen, dass das Modell benannt model-1ist.
Wählen Sie "Weiter" und dann " Registrieren " aus, um die Registrierung abzuschließen.
Weitere Informationen zum Arbeiten mit registrierten Modellen finden Sie unter Arbeiten mit registrierten Modellen.
Erstellen und registrieren der Umgebung
Wählen Sie im linken Bereich die Seite "Umgebungen" aus.
Wählen Sie die Registerkarte "Benutzerdefinierte Umgebungen " und dann " Erstellen" aus.
Geben Sie auf der Seite "Einstellungen " einen Namen ein, z. B. "my-env " für die Umgebung.
Wählen Sie für Umgebungsquelle auswählen die Option Vorhandenes Docker-Image mit optionaler Conda-Quelle verwenden aus.
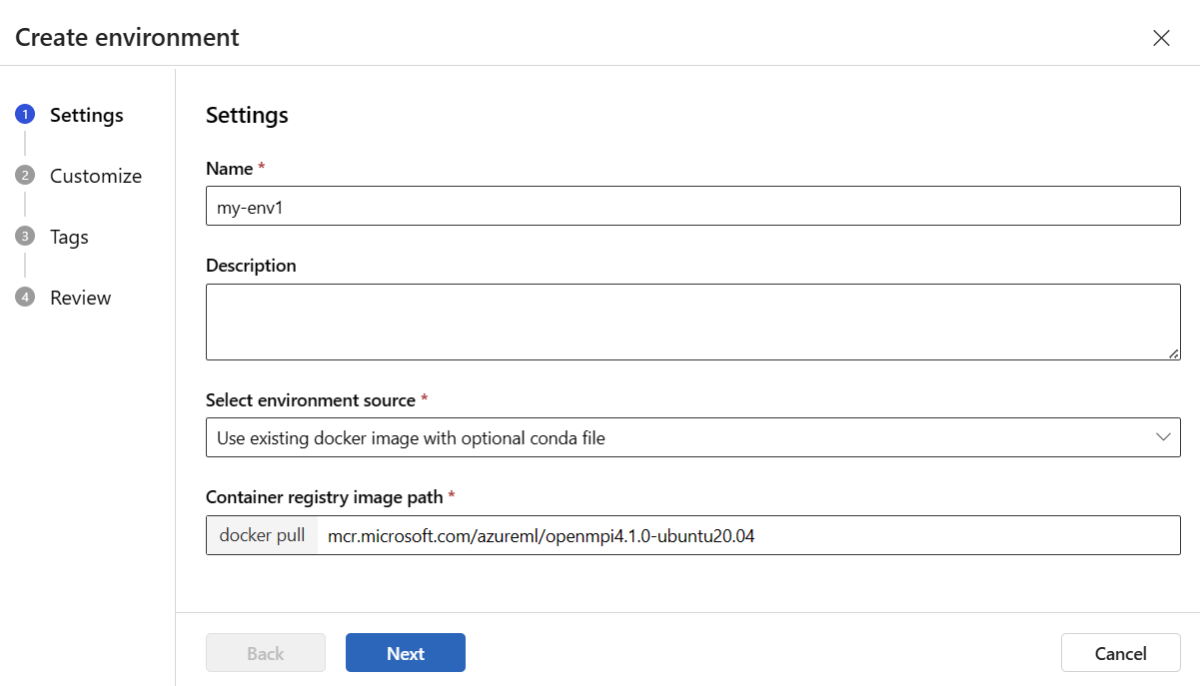
Wählen Sie "Weiter" aus, um zur Seite "Anpassen" zu wechseln.
Kopieren Sie den Inhalt der Datei "\azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml " aus dem Repository, das Sie geklont oder zuvor heruntergeladen haben.
Fügen Sie den Inhalt in das Textfeld ein.
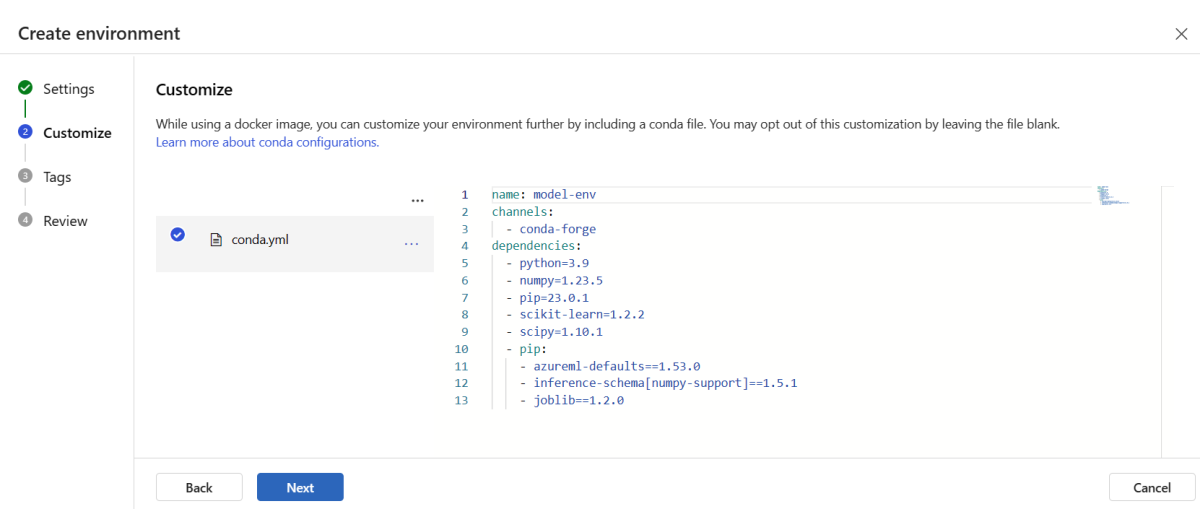
Wählen Sie "Weiter" aus, bis Sie zur Seite " Erstellen " gelangen, und wählen Sie dann "Erstellen" aus.
Weitere Informationen zum Erstellen einer Umgebung im Studio finden Sie unter Erstellen einer Umgebung.
Um das Modell mithilfe einer Vorlage zu registrieren, müssen Sie zuerst die Modelldatei in Blob Storage hochladen. Im folgenden Beispiel wird der Befehl az storage blob upload-batch verwendet, um eine Datei in den Standardspeicher für Ihren Arbeitsbereich hochzuladen:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
Verwenden Sie nach dem Hochladen der Datei die Vorlage, um eine Modellregistrierung zu erstellen. Im folgenden Beispiel enthält der Parameter modelUri den Pfad zum Modell:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
Teil der Umgebung ist eine Conda-Datei, die die Modellabhängigkeiten angibt, die zum Hosten des Modells erforderlich sind. Im folgenden Beispiel wird veranschaulicht, wie der Inhalt der Conda-Datei in Umgebungsvariablen eingelesen wird:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
Im folgenden Beispiel wird veranschaulicht, wie die Vorlage zum Registrieren der Umgebung verwendet wird. Der Inhalt der Conda-Datei aus dem vorherigen Schritt wird mithilfe des condaFile Parameters an die Vorlage übergeben:
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Wichtig
Wenn Sie eine benutzerdefinierte Umgebung für Ihre Bereitstellung definieren, stellen Sie sicher, dass das azureml-inference-server-http Paket in der Conda-Datei enthalten ist. Dieses Paket ist unerlässlich, damit der Ableitungsserver ordnungsgemäß funktioniert. Wenn Sie mit der Erstellung Ihrer eigenen benutzerdefinierten Umgebung nicht vertraut sind, verwenden Sie eine unserer kuratierten Umgebungen, z. B. minimal-py-inference (für benutzerdefinierte Modelle, die mlflow nicht verwenden) oder mlflow-py-inference (für Modelle, die mlflow verwenden). Sie finden diese kuratierten Umgebungen auf der Registerkarte "Umgebungen " Ihrer Instanz von Azure Machine Learning Studio.
Ihre Bereitstellungskonfiguration verwendet das registrierte Modell, das Sie bereitstellen möchten, und Ihre registrierte Umgebung.
Verwenden Sie die registrierten Ressourcen (Modell und Umgebung) in Ihrer Definition für die Bereitstellung. Der folgende Codeschnipsel zeigt die Datei endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml mit allen erforderlichen Eingaben zum Konfigurieren einer Bereitstellung:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Verwenden Sie zum Konfigurieren einer Bereitstellung das registrierte Modell und die registrierte Umgebung:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Wenn Sie in Studio die Bereitstellung durchführen, erstellen Sie einen Endpunkt und eine Bereitstellung, die sie diesem hinzufügen. Zu diesem Zeitpunkt werden Sie aufgefordert, Namen für den Endpunkt und die Bereitstellung einzugeben.
Verwenden verschiedener CPU- und GPU-Instanztypen und -images
Sie können die CPU- oder GPU-Instanztypen und -Images in Ihrer Bereitstellungsdefinition sowohl für die lokale Bereitstellung als auch für die Bereitstellung in Azure angeben.
Ihre Bereitstellungsdefinition in der Datei blue-deployment-with-registered-assets.yml hat eine universelle Instanz vom Typ Standard_DS3_v2 und das Nicht-GPU-Docker-Image mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest verwendet. Für GPU-Compute wählen Sie eine GPU-Computetypversion und ein GPU-Docker-Image aus.
Unterstützte allgemeine und GPU-Instanztypen finden Sie in der SKU-Liste verwalteter Onlineendpunkte. Eine Liste der CPU- und GPU-Basisimages von Azure Machine Learning finden Sie unter Azure Machine Learning-Basisimages.
Sie können die CPU- oder GPU-Instanztypen und -Images in Ihrer Bereitstellungskonfiguration sowohl für die lokale Bereitstellung als auch für die Bereitstellung in Azure angeben.
Zuvor haben Sie eine Bereitstellung konfiguriert, die eine allgemeine Typ Standard_DS3_v2-Instanz und ein Nicht-GPU-Docker-Image mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest verwendet hat. Für GPU-Compute wählen Sie eine GPU-Computetypversion und ein GPU-Docker-Image aus.
Unterstützte allgemeine und GPU-Instanztypen finden Sie in der SKU-Liste verwalteter Onlineendpunkte. Eine Liste der CPU- und GPU-Basisimages von Azure Machine Learning finden Sie unter Azure Machine Learning-Basisimages.
Die vorherige Registrierung der Umgebung gibt ein Docker-Image mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 ohne GPU an, indem der Wert mithilfe des Parameters an die dockerImage übergeben wird. Geben Sie für eine GPU-Berechnung einen Wert für ein GPU-Docker-Image für die Vorlage an (verwenden Sie den dockerImage Parameter), und geben Sie eine GPU-Berechnungs-Typversion für die online-endpoint-deployment.json Vorlage an (verwenden Sie den skuName Parameter).
Unterstützte allgemeine und GPU-Instanztypen finden Sie in der SKU-Liste verwalteter Onlineendpunkte. Eine Liste der CPU- und GPU-Basisimages von Azure Machine Learning finden Sie unter Azure Machine Learning-Basisimages.
Stellen Sie als nächstes Ihren Onlineendpunkt in Azure bereit.
In Azure bereitstellen
Erstellen Sie den Endpunkt in der Azure-Cloud:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Erstellen Sie die Bereitstellung mit dem Namen blue unter dem Endpunkt:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
Die Bereitstellungserstellung kann bis zu 15 Minuten dauern, je nachdem, ob die zugrunde liegende Umgebung bzw. das zugrunde liegende Image zum ersten Mal erstellt wird. Nachfolgende Bereitstellungen, die dieselbe Umgebung verwenden, werden schneller verarbeitet.
Wenn Sie es vorziehen, Ihre CLI-Konsole nicht zu blockieren, können Sie das Flag --no-wait an den Befehl anhängen. Diese Option stoppt jedoch die interaktive Anzeige des Bereitstellungsstatus.
Das Flag --all-traffic im Code az ml online-deployment create, der zum Erstellen der Bereitstellung verwendet wird, ordnet 100 % des Endpunktdatenverkehrs der neu erstellten blauen Bereitstellung zu. Die Verwendung dieses Flags ist für Entwicklungs- und Testzwecke hilfreich, aber für die Produktion sollten Sie den Datenverkehr über einen expliziten Befehl an die neue Bereitstellung weiterleiten. Verwenden Sie z. B. az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Erstellen des Endpunkts:
Mithilfe des zuvor definierten endpoint Parameters und des zuvor erstellten MLClient Parameters können Sie nun den Endpunkt im Arbeitsbereich erstellen. Dieser Befehl startet die Endpunkterstellung und gibt eine Bestätigungsantwort zurück, während die Endpunkterstellung fortgesetzt wird.
ml_client.online_endpoints.begin_create_or_update(endpoint)
Erstellen Sie die Bereitstellung:
Mit dem zuvor definierten Parameter blue_deployment_with_registered_assets und dem zuvor erstellten Parameter MLClient können Sie nun die Bereitstellung im Arbeitsbereich erstellen. Dieser Befehl startet die Bereitstellungserstellung und gibt eine Bestätigungsantwort zurück, während die Bereitstellungserstellung fortgesetzt wird.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Wenn Sie Ihre Python-Konsole nicht blockieren möchten, können Sie den Parametern das Flag no_wait=True hinzufügen. Diese Option stoppt jedoch die interaktive Anzeige des Bereitstellungsstatus.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Erstellen eines verwalteten Onlineendpunkts und einer Bereitstellung
Verwenden Sie Studio, um direkt in Ihrem Browser einen verwalteten Onlineendpunkt zu erstellen. Beim Erstellen eines verwalteten Onlineendpunkts in Studio müssen Sie eine erste Bereitstellung definieren. Es ist nicht möglich, einen leeren verwalteten Onlineendpunkt zu erstellen.
Eine Möglichkeit zum Erstellen eines verwalteten Onlineendpunkts im Studio befindet sich auf der Seite "Modelle ". Bei dieser Methode kann ein Modell auch ganz einfach einer bereits vorhandenen verwalteten Onlinebereitstellung hinzugefügt werden. So stellen Sie das Modell mit dem Namen model-1 bereit, das Sie zuvor im Abschnitt "Modell und Umgebung registrieren" registriert haben:
Wechseln Sie zum Azure Machine Learning-Studio.
Wählen Sie im linken Bereich die Seite "Modelle " aus.
Wählen Sie das Modell mit dem Namen "Model-1" aus.
Wählen Sie Bereitstellen>Echtzeitendpunkt aus.
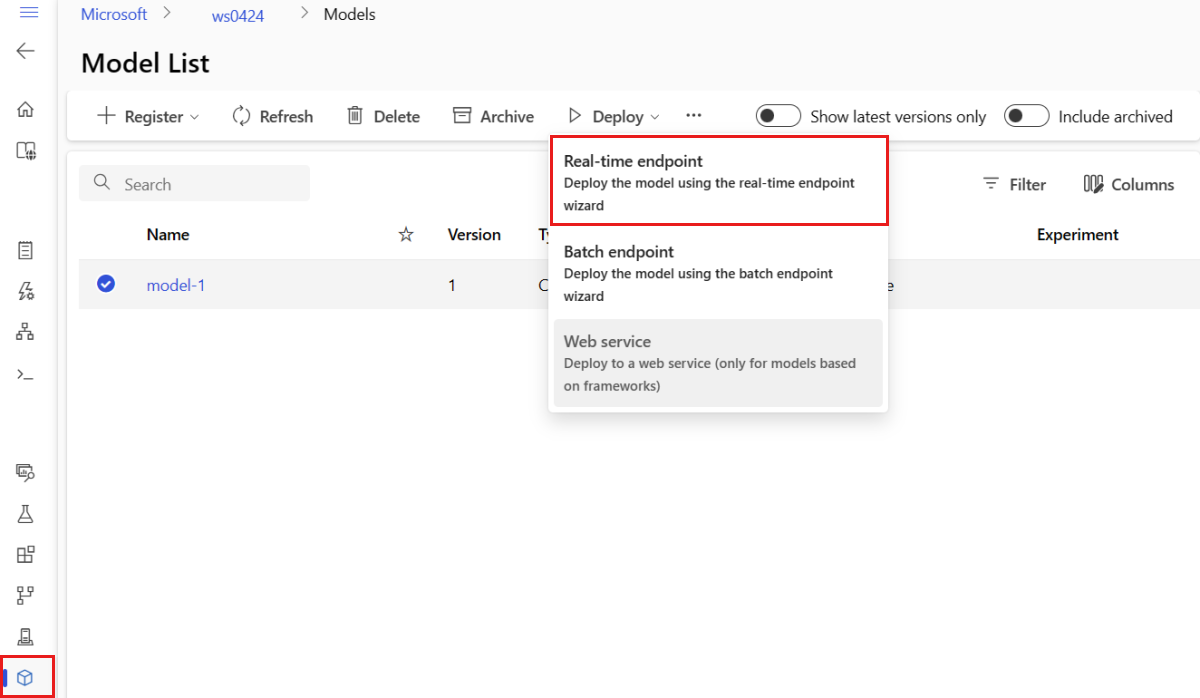
Daraufhin wird ein Fenster geöffnet, in dem Sie Details zu Ihrem Endpunkt angeben können.
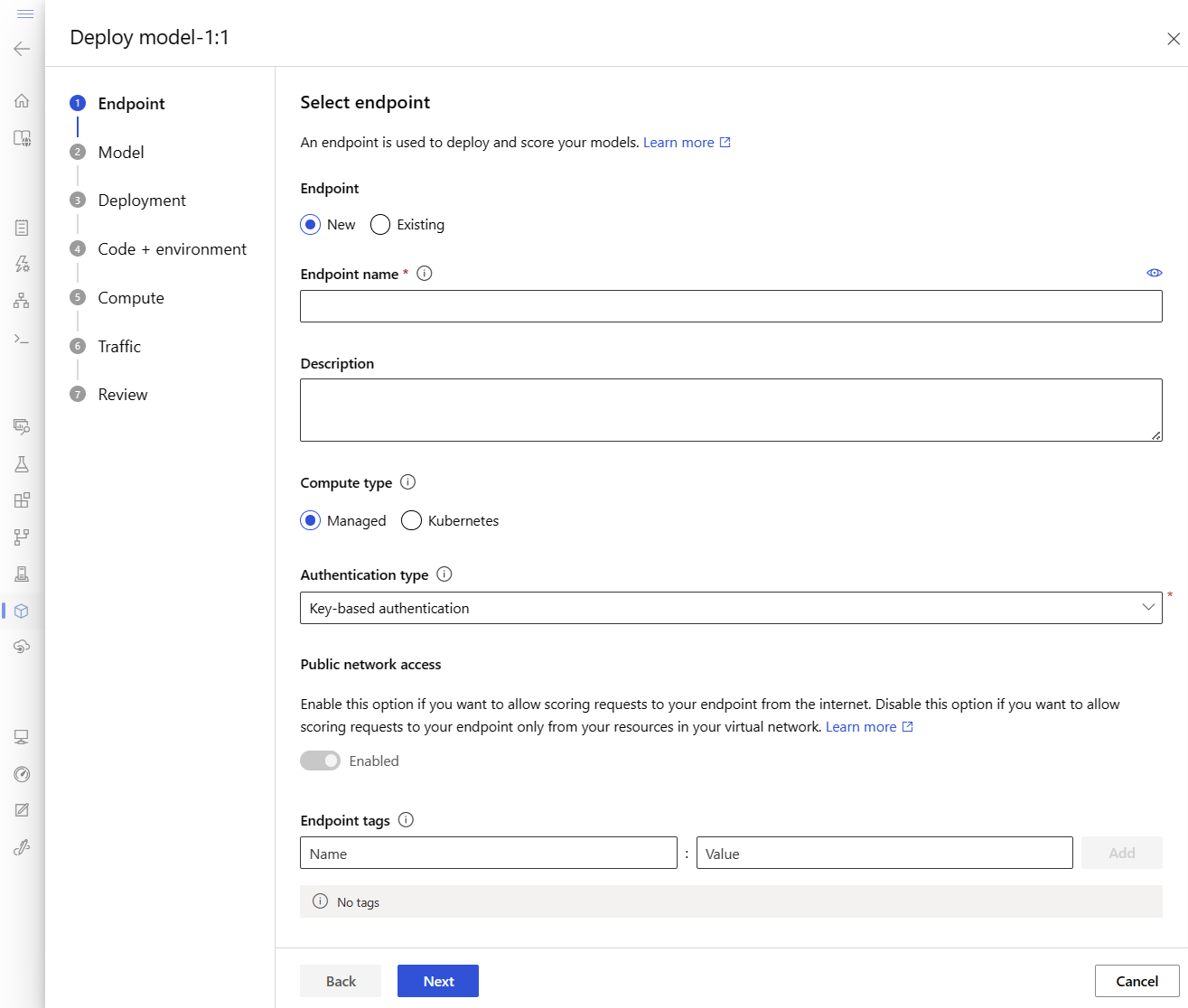
Geben Sie einen Endpunktnamen ein, der in der Azure-Region eindeutig ist. Weitere Informationen zu den Benennungsregeln finden Sie unter Endpunktgrenzwerte.
Belassen Sie die Standardauswahl: Verwaltet für den Rechenleistungstyp.
Behalten Sie die Standardauswahl bei: Schlüsselbasierte Authentifizierung für den Authentifizierungstyp. Weitere Informationen zur Authentifizierung finden Sie unter Authentifizieren von Clients für Onlineendpunkte.
Wählen Sie "Weiter" aus, bis Sie zur Seite "Bereitstellung" gelangen. Schalten Sie die Diagnose von Application Insights auf "Enabled " um, sodass Sie Diagramme der Aktivitäten Ihres Endpunkts später im Studio anzeigen und Metriken und Protokolle mithilfe von Application Insights analysieren können.
Wählen Sie "Weiter" aus, um zur Seite "Code + Umgebung " zu wechseln. Wählen Sie die folgenden Optionen:
- Wählen Sie ein Bewertungsskript für das Inferencing aus: durchsuchen und wählen Sie die Datei \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py aus dem Repository aus, das Sie geklont oder zuvor heruntergeladen haben.
- Abschnitt "Umgebung auswählen ": Wählen Sie "Benutzerdefinierte Umgebungen " und dann die " my-env:1"- Umgebung aus, die Sie zuvor erstellt haben.
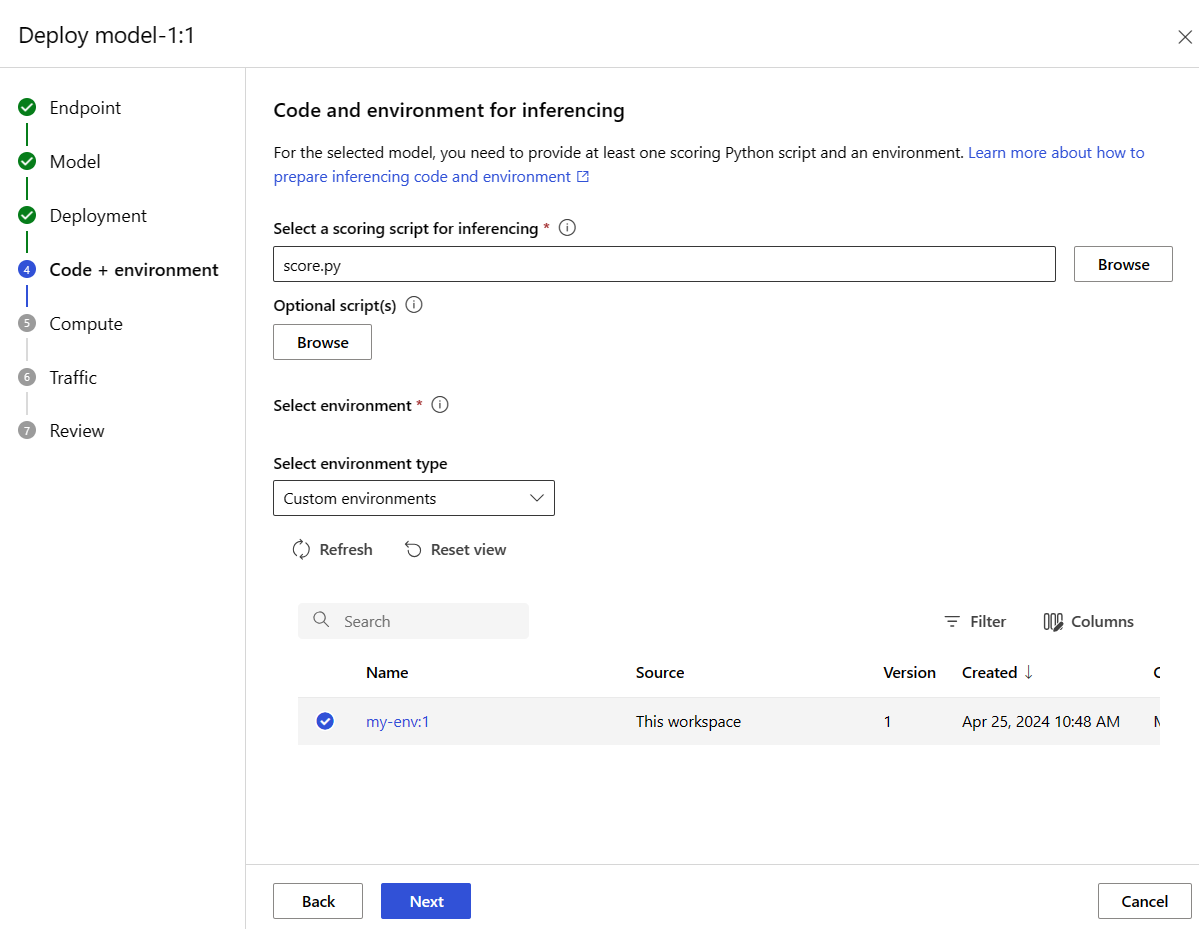
Wählen Sie "Weiter" aus, und akzeptieren Sie die Standardwerte, bis Sie aufgefordert werden, die Bereitstellung zu erstellen.
Überprüfen Sie Ihre Bereitstellungseinstellungen, und wählen Sie "Erstellen" aus.
Alternativ können Sie einen verwalteten Onlineendpunkt über die Seite "Endpunkte " im Studio erstellen.
Wechseln Sie zum Azure Machine Learning-Studio.
Wählen Sie im linken Bereich die Seite "Endpunkte " aus.
Wählen Sie +Erstellen aus.
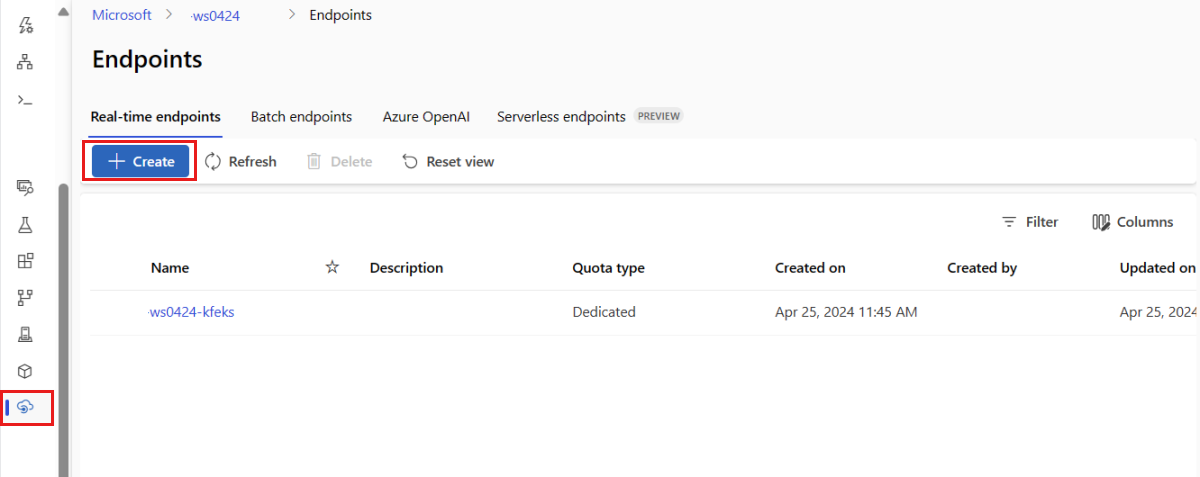
Daraufhin wird ein Fenster geöffnet, in dem Sie Ihr Modell auswählen und Details zu Ihrem Endpunkt und zu Ihrer Bereitstellung angeben können. Geben Sie Einstellungen für Ihren Endpunkt und Ihre Bereitstellung ein, wie zuvor beschrieben, und wählen Sie dann "Erstellen" aus, um die Bereitstellung zu erstellen.
Verwenden Sie die Vorlage, um einen Onlineendpunkt zu erstellen:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Stellen Sie das Modell nach der Erstellung des Endpunkts auf dem Endpunkt bereit:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Informationen zum Debuggen von Fehlern in Ihrer Bereitstellung finden Sie unter "Problembehandlung bei Onlineendpunktbereitstellungen".
Überprüfen des Status des Onlineendpunkts
Verwenden Sie den Befehl show, um Informationen für den Endpunkt und die Bereitstellung im provisioning_state anzuzeigen:
az ml online-endpoint show -n $ENDPOINT_NAME
Listen Sie alle Endpunkte im Arbeitsbereich in einem Tabellenformat mit dem Befehl list auf:
az ml online-endpoint list --output table
Überprüfen Sie den Status des Endpunkts, um festzustellen, ob das Modell ohne Fehler bereitgestellt wurde:
ml_client.online_endpoints.get(name=endpoint_name)
Listen Sie alle Endpunkte im Arbeitsbereich in einem Tabellenformat mit der Methode list auf:
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
Die Methode gibt eine Liste (einen Iterator) von ManagedOnlineEndpoint-Entitäten zurück.
Sie können weitere Informationen erhalten, indem Sie weitere Parameter angeben. Geben Sie beispielsweise die Liste der Endpunkte wie eine Tabelle aus:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Anzeigen von verwalteten Onlineendpunkten
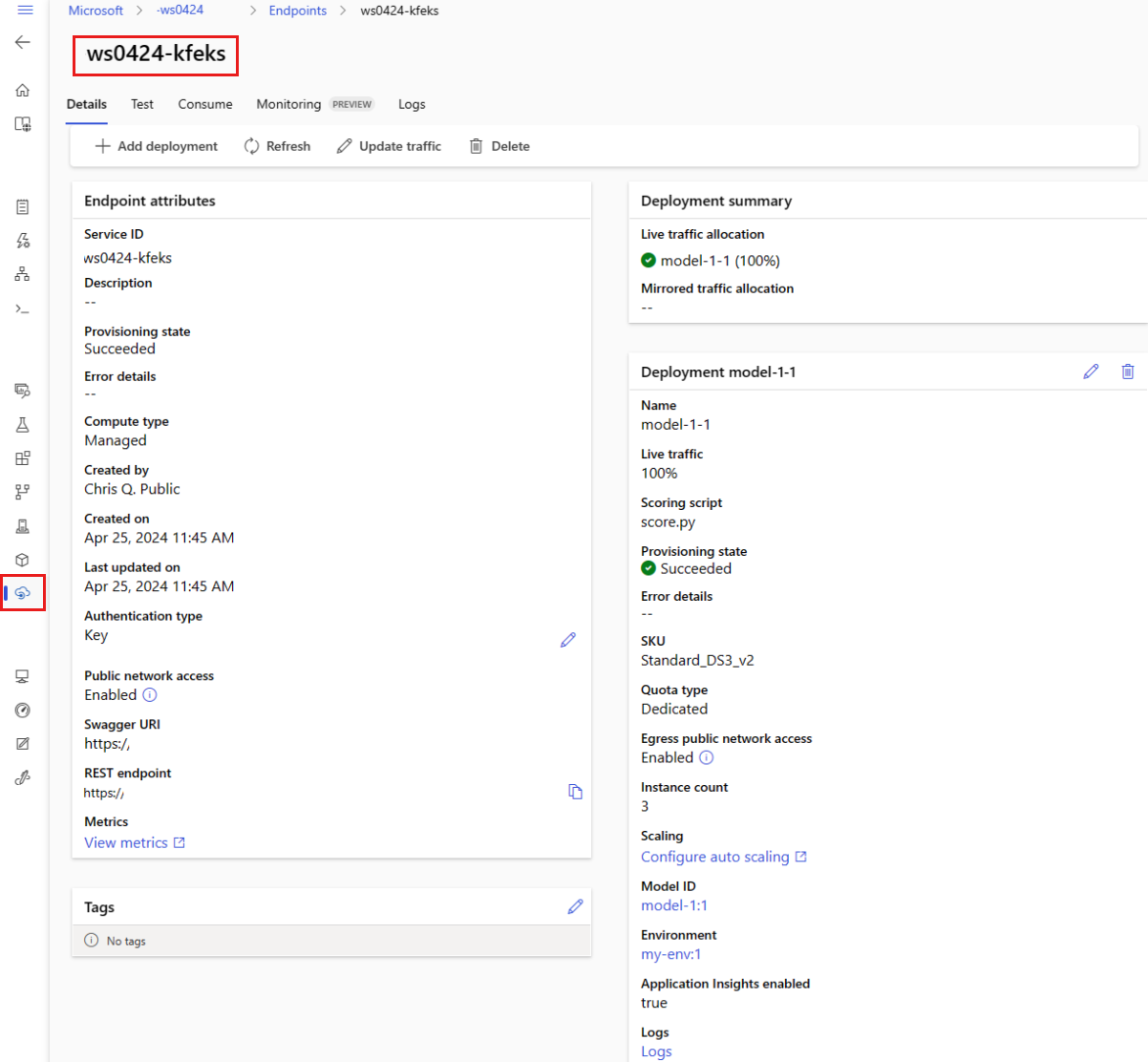
Sie können alle verwalteten Onlineendpunkte auf der Seite "Endpunkte " anzeigen. Wechseln Sie zur Seite " Details " des Endpunkts, um wichtige Informationen zu finden, z. B. den Endpunkt-URI, Status, Testtools, Aktivitätsmonitore, Bereitstellungsprotokolle und Beispielnutzungscode.
Wählen Sie im linken Bereich Endpunkte aus, um eine Liste aller Endpunkte im Arbeitsbereich anzuzeigen.
(Optional) Erstellen Sie einen Filter nach Computetyp , um nur verwaltete Computetypen anzuzeigen.
Wählen Sie einen Endpunktnamen aus, um die Detailseite des Endpunkts anzuzeigen.
Vorlagen sind nützlich für die Bereitstellung von Ressourcen, sie können jedoch nicht zum Auflisten, Anzeigen oder Aufrufen von Ressourcen verwendet werden. Verwenden Sie die Azure CLI, das Python-SDK oder das Studio, um diese Vorgänge auszuführen. Der folgende Code verwendet die Azure CLI.
Verwenden Sie den show Befehl, um Informationen im provisioning_state Parameter für den Endpunkt und die Bereitstellung anzuzeigen:
az ml online-endpoint show -n $ENDPOINT_NAME
Listen Sie alle Endpunkte im Arbeitsbereich in einem Tabellenformat mit dem Befehl list auf:
az ml online-endpoint list --output table
Überprüfen des Status der Onlinebereitstellung
Überprüfen Sie die Protokolle, um zu prüfen, ob das Modell ohne Fehler bereitgestellt wurde.
Verwenden Sie den folgenden CLI-Befehl, um die Protokollausgabe für einen Container anzuzeigen:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Standardmäßig werden Protokolle per Pull vom Rückschlussservercontainer abgerufen. Um Protokolle aus dem Container für den Speicherinitialisierer anzuzeigen, fügen Sie das --container storage-initializer-Flag hinzu. Weitere Informationen zu Bereitstellungsprotokollen finden Sie unter Abrufen von Containerprotokollen.
Sie können die Protokollausgabe mit der Methode get_logs anzeigen:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Standardmäßig werden Protokolle per Pull vom Rückschlussservercontainer abgerufen. Um Protokolle aus dem Container für den Speicherinitialisierer anzuzeigen, fügen Sie die container_type="storage-initializer"-Option hinzu. Weitere Informationen zu Bereitstellungsprotokollen finden Sie unter Abrufen von Containerprotokollen.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Um die Protokollausgabe anzuzeigen, wählen Sie die Registerkarte "Protokolle " auf der Seite des Endpunkts aus. Wenn Sie über mehrere Bereitstellungen in Ihrem Endpunkt verfügen, verwenden Sie die Dropdown-Liste, um die Bereitstellung mit dem Protokoll, das Sie sehen möchten, auszuwählen.
Standardmäßig werden Protokolle per Pull vom Rückschlussserver abgerufen. Um Protokolle aus dem Container für den Speicherinitialisierer abzurufen, verwenden Sie die Azure CLI oder das Python-SDK. (Details finden Sie auf der jeweiligen Registerkarte). Die Protokolle des Speicherinitialisierungs-Containers enthalten Informationen dazu, ob das Herunterladen der Code- und Modelldaten in den Container erfolgreich war. Weitere Informationen zu Bereitstellungsprotokollen finden Sie unter Abrufen von Containerprotokollen.
Vorlagen sind nützlich für die Bereitstellung von Ressourcen, sie können jedoch nicht zum Auflisten, Anzeigen oder Aufrufen von Ressourcen verwendet werden. Verwenden Sie die Azure CLI, das Python-SDK oder das Studio, um diese Vorgänge auszuführen. Der folgende Code verwendet die Azure CLI.
Verwenden Sie den folgenden CLI-Befehl, um die Protokollausgabe für einen Container anzuzeigen:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Standardmäßig werden Protokolle per Pull vom Rückschlussservercontainer abgerufen. Um Protokolle aus dem Container für den Speicherinitialisierer anzuzeigen, fügen Sie das --container storage-initializer-Flag hinzu. Weitere Informationen zu Bereitstellungsprotokollen finden Sie unter Abrufen von Containerprotokollen.
Aufrufen des Endpunkts zum Bewerten von Daten mit Ihrem Modell
Verwenden Sie entweder den Befehl invoke oder einen REST-Client Ihrer Wahl, um den Endpunkt aufzurufen und einige Daten zu bewerten:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Rufen Sie den Schlüssel ab, der für die Authentifizierung beim Endpunkt verwendet wird:
Sie können steuern, welche Microsoft Entra-Sicherheitsprinzipale den Authentifizierungsschlüssel abrufen können, indem Sie diese einer benutzerdefinierten Rolle zuweisen, die Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action und Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action zulässt. Weitere Informationen zum Verwalten der Autorisierung für Arbeitsbereiche finden Sie unter Verwalten des Zugriffs auf einen Azure Machine Learning-Arbeitsbereich.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Verwenden Sie curl, um Daten zu bewerten.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Beachten Sie, dass Sie die Befehle show und get-credentials verwenden, um die Authentifizierungsanmeldeinformationen abzurufen. Beachten Sie außerdem, dass Sie das --query Flag verwenden, um nur die attribute zu filtern, die erforderlich sind. Weitere Informationen zum --query Flag finden Sie unter Azure CLI-Befehlsausgabe abfragen.
Führen Sie get-logs erneut aus, um die Aufrufprotokolle anzuzeigen.
Mithilfe des zuvor erstellten Parameters MLClient erhalten Sie ein Handle für den Endpunkt. Anschließend können Sie den Endpunkt mithilfe des invoke Befehls mit den folgenden Parametern aufrufen:
endpoint_name: Der Name des Endpunkts.request_file: Datei mit Anforderungsdaten.deployment_name: Name der spezifischen Bereitstellung, die in einem Endpunkt getestet werden soll.
Senden Sie eine Beispielanforderung mithilfe einer JSON-Datei .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
Verwenden Sie die Registerkarte " Test " auf der Detailseite des Endpunkts, um Ihre verwaltete Onlinebereitstellung zu testen. Geben Sie eine Beispieleingabe ein, und zeigen Sie die Ergebnisse an.
Wählen Sie auf der Detailseite des Endpunkts die Registerkarte " Test " aus.
Verwenden Sie die Dropdownliste, um die Bereitstellung auszuwählen, die Sie testen möchten.
Geben Sie eine Beispieleingabe ein.
Wählen Sie "Testen" aus.
Vorlagen sind nützlich für die Bereitstellung von Ressourcen, sie können jedoch nicht zum Auflisten, Anzeigen oder Aufrufen von Ressourcen verwendet werden. Verwenden Sie die Azure CLI, das Python-SDK oder das Studio, um diese Vorgänge auszuführen. Der folgende Code verwendet die Azure CLI.
Verwenden Sie entweder den Befehl invoke oder einen REST-Client Ihrer Wahl, um den Endpunkt aufzurufen und einige Daten zu bewerten:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Optional) Aktualisieren der Bereitstellung
Wenn Sie den Code, das Modell oder die Umgebung aktualisieren möchten, aktualisieren Sie die YAML-Datei. Führen Sie anschließend den Befehl az ml online-endpoint update aus.
Wenn Sie die Instanzenanzahl (zum Skalieren der Bereitstellung) zusammen mit anderen Modelleinstellungen (z. B. Code, Modell oder Umgebung) in einem einzigen update Befehl aktualisieren, wird der Skalierungsvorgang zuerst ausgeführt. Die anderen Updates werden als Nächstes angewendet. Es eine bewährte Methode, diese Vorgänge in einer Produktionsumgebung separat durchzuführen.
Informationen zur Funktionsweise von update:
Öffnen Sie die Datei online/model-1/onlinescoring/score.py.
Ändern Sie die letzte Zeile der init()-Funktion: Fügen Sie nach logging.info("Init complete") einfach logging.info("Updated successfully") hinzu.
Speichern Sie die Datei .
Führen Sie den folgenden Befehl aus:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
Das Aktualisieren mithilfe von YAML ist deklarativ. Das heißt, Änderungen im YAML werden in den zugrunde liegenden Ressourcen des Ressourcen-Managers (Endpunkte und Bereitstellungen) widergespiegelt. Ein deklarativer Ansatz erleichtert GitOps: Alle Änderungen an Endpunkten und Bereitstellungen (auch instance_count) durchlaufen yaML.
Sie können generische Updateparameter wie den --set Parameter mit dem CLI-Befehl update verwenden, um Attribute in Ihrem YAML außer Kraft zu setzen oder bestimmte Attribute festzulegen, ohne sie in der YAML-Datei zu übergeben. Die Verwendung von --set für einzelne Attribute ist besonders in Entwicklungs- und Testszenarien nützlich. Sie können das Flag instance_count verwenden, um z. B. den --set instance_count=2-Wert für die erste Bereitstellung hochzuskalieren. Da der YAML jedoch nicht aktualisiert wird, erleichtert diese Technik GitOps nicht.
Die Angabe der YAML-Datei ist nicht obligatorisch. Wenn Sie z. B. unterschiedliche Parallelitätseinstellungen für eine bestimmte Bereitstellung testen möchten, können Sie etwa az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4versuchen. Dieser Ansatz behält alle vorhandenen Konfigurationen bei, aktualisiert jedoch nur die angegebenen Parameter.
Da Sie die init() Funktion geändert haben, die beim Erstellen oder Aktualisieren des Endpunkts ausgeführt wird, wird die Meldung Updated successfully in den Protokollen angezeigt. Rufen Sie die Protokolle ab, indem Sie Folgendes ausführen:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Der Befehl update funktioniert auch mit lokalen Bereitstellungen. Verwenden Sie denselben az ml online-deployment update-Befehl mit dem Flag --local.
Wenn Sie den Code, das Modell oder die Umgebung aktualisieren möchten, aktualisieren Sie die Konfiguration, und führen Sie dann die Methode ausMLClientonline_deployments.begin_create_or_update, um eine Bereitstellung zu erstellen oder zu aktualisieren.
Wenn Sie die Instanzanzahl (zum Skalieren der Bereitstellung) zusammen mit anderen Modelleinstellungen (z. B. Code, Modell oder Umgebung) in einer einzigen begin_create_or_update Methode aktualisieren, wird der Skalierungsvorgang zuerst ausgeführt. Anschließend werden die anderen Updates angewendet. Es eine bewährte Methode, diese Vorgänge in einer Produktionsumgebung separat durchzuführen.
Informationen zur Funktionsweise von begin_create_or_update:
Öffnen Sie die Datei online/model-1/onlinescoring/score.py.
Ändern Sie die letzte Zeile der init()-Funktion: Fügen Sie nach logging.info("Init complete") einfach logging.info("Updated successfully") hinzu.
Speichern Sie die Datei .
Führen Sie die Methode aus:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Da Sie die init() Funktion geändert haben, die beim Erstellen oder Aktualisieren des Endpunkts ausgeführt wird, wird die Meldung Updated successfully in den Protokollen angezeigt. Rufen Sie die Protokolle ab, indem Sie Folgendes ausführen:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Die Methode begin_create_or_update funktioniert auch mit lokalen Bereitstellungen. Verwenden Sie dieselbe Methode mit dem Flag local=True.
Derzeit können Sie Aktualisierungen nur für die Instanzanzahl einer Bereitstellung vornehmen. Befolgen Sie die unten angegebene Anleitung, um eine einzelne Bereitstellung hoch- oder herunterzuskalieren, indem Sie die Anzahl von Instanzen anpassen:
- Öffnen Sie die Seite " Details " des Endpunkts, und suchen Sie die Karte für die Bereitstellung, die Sie aktualisieren möchten.
- Wählen Sie das Bearbeitungssymbol (Stiftsymbol) neben dem Namen der Bereitstellung aus.
- Aktualisieren Sie die Anzahl der Instanzen, welche der Bereitstellung zugeordnet sind. Wählen Sie zwischen Standard - oder Zielauslastung für den Skalierungstyp der Bereitstellung aus.
- Wenn Sie "Standard" auswählen, können Sie auch einen numerischen Wert für die Anzahl der Instanzen angeben.
- Wenn Sie "Zielnutzung" auswählen, können Sie Werte angeben, die für Parameter verwendet werden sollen, wenn Sie die Bereitstellung automatisch skalieren.
- Wählen Sie "Aktualisieren" aus, um die Aktualisierung der Instanzenanzahl für Ihre Bereitstellung abzuschließen.
Zurzeit gibt es keine Option, die Bereitstellung mithilfe einer ARM-Vorlage zu aktualisieren.
Hinweis
Das Update für die Bereitstellung in diesem Abschnitt ist ein Beispiel für ein direktes rollierendes Update.
- Für einen verwalteten Onlineendpunkt wird die Bereitstellung auf die neue Konfiguration mit jeweils 20 % der Knoten aktualisiert. Das heißt, wenn die Bereitstellung über 10 Knoten verfügt, werden jeweils 2 Knoten aktualisiert.
- Bei einem Kubernetes-Onlineendpunkt erstellt das System iterativ eine neue Bereitstellungsinstanz mit der neuen Konfiguration und löscht die alte.
- Für die Produktionsverwendung sollten Sie die blaugrüne Bereitstellung in Betracht ziehen, die eine sicherere Alternative zum Aktualisieren eines Webdiensts bietet.
Die automatische Skalierung führt automatisch die richtige Menge an Ressourcen aus, um die Last für Ihre Anwendung zu bewältigen. Verwaltete Onlineendpunkte unterstützen die automatische Skalierung durch Integration in das Feature "Automatische Skalierung von Azure Monitor". Informationen zum Konfigurieren der automatischen Skalierung finden Sie unter AutoScale Online-Endpunkte.
(Optional) Überwachen der SLA mit Azure Monitor
Um Metriken anzuzeigen und Warnungen basierend auf Ihrem SLA festzulegen, führen Sie die Schritte aus, die unter "Überwachen von Onlineendpunkten" beschrieben werden.
(Optional) Integrieren mit Log Analytics
Der get-logs Befehl für die CLI oder die get_logs Methode für das SDK stellt nur die letzten hundert Zeilen von Protokollen aus einer automatisch ausgewählten Instanz bereit. Log Analytics bietet jedoch eine Möglichkeit, Protokolle dauerhaft zu speichern und zu analysieren. Weitere Informationen zur Verwendung der Protokollierung finden Sie unter Verwenden von Protokollen.
Löschen des Endpunkts und der Bereitstellung
Verwenden Sie den folgenden Befehl, um den Endpunkt und alle zugrunde liegenden Bereitstellungen zu löschen:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Verwenden Sie den folgenden Befehl, um den Endpunkt und alle zugrunde liegenden Bereitstellungen zu löschen:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Wenn Sie den Endpunkt und die Bereitstellung nicht verwenden werden, löschen Sie sie. Wenn Sie den Endpunkt löschen, werden auch alle zugrunde liegenden Bereitstellungen gelöscht.
- Wechseln Sie zum Azure Machine Learning-Studio.
- Wählen Sie im linken Bereich die Seite "Endpunkte " aus.
- Wählen Sie einen Endpunkt aus.
- Wählen Sie "Löschen" aus.
Alternativ können Sie einen verwalteten Onlineendpunkt direkt löschen, indem Sie auf der Seite mit den Endpunktdetails das Symbol "Löschen" auswählen.
Verwenden Sie den folgenden Befehl, um den Endpunkt und alle zugrunde liegenden Bereitstellungen zu löschen:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Zugehöriger Inhalt









