Abfragen und Vergleichen von Experimenten und Ausführungen mit MLflow
Experimente und Jobs (oder Ausführungen) in Azure Machine Learning können mithilfe von MLflow abgefragt werden. Sie müssen kein bestimmtes SDK installieren, um die Vorgänge innerhalb eines Trainingsauftrags zu verwalten. Dadurch wird ein nahtloserer Übergang zwischen lokalen Ausführungen und der Cloud ermöglicht, da cloudspezifische Abhängigkeiten entfernt werden. In diesem Artikel werden Sie erfahren, wie Sie Experimente und Ausführungen in Ihrem Arbeitsbereich mit Azure Machine Learning und dem MLflow-SDK in Python abfragen und vergleichen.
MLflow ermöglicht Folgendes:
- Erstellen, Abfragen, Löschen und Suchen nach Experimenten in einem Arbeitsbereich
- Abfragen, Löschen und Suchen nach Ausführungen in einem Arbeitsbereich.
- Nachverfolgen und Abrufen von Metriken, Parametern, Artefakten und Modellen aus Ausführungen
Unter Supportmatrix für die Abfrage von Ausführungen und Experimenten in Azure Machine Learning finden Sie einen detaillierten Vergleich zwischen MLflow (Open Source) und MLflow (mit Azure Machine Learning verbunden).
Hinweis
Das Azure Machine Learning Python SDK v2 bietet keine nativen Protokollierungs- oder Nachverfolgungsfunktionen. Dies gilt nicht nur für die Protokollierung, sondern auch für die Abfrage der protokollierten Metriken. Verwenden Sie stattdessen MLflow zum Verwalten von Experimenten und Ausführungen. In diesem Artikel wird erläutert, wie Sie mit MLflow Experimente und Ausführungen in Azure Machine Learning verwalten.
Sie können Experimente und Ausführungen auch abfragen und durchsuchen, indem Sie die REST-API für MLflow verwenden. Ein Beispiel zur Nutzung finden Sie unter Verwenden von MLflow REST mit Azure Machine Learning.
Voraussetzungen
Installieren Sie das MLflow SDK-Paket
mlflowund das Azure Machine Learning-Plug-Inazureml-mlflowfür MLflow:pip install mlflow azureml-mlflowTipp
Sie können auch das Paket
mlflow-skinnyverwenden. Dabei handelt es sich um ein abgespecktes MLflow-Paket ohne SQL-Speicher, Server, Benutzeroberfläche oder Data Science-Abhängigkeiten.mlflow-skinnywird für diejenigen empfohlen, die in erster Linie die Funktionen für Nachverfolgung und Protokollierung benötigen und nicht sämtliche Features von MLflow (einschließlich Bereitstellungen) importieren möchten.Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen eines Arbeitsbereichs finden Sie unter Tutorial: Erstellen von Ressourcen für maschinelles Lernen. Überprüfen Sie, welche Zugriffsberechtigungen Sie benötigen, um Ihre MLflow-Vorgänge in Ihrem Arbeitsbereich auszuführen.
Wenn Sie eine Remotenachverfolgung durchführen, d. h. eine Nachverfolgung von Experimenten, die außerhalb von Azure Machine Learning ausgeführt werden, konfigurieren Sie MLflow so, dass auf den Nachverfolgungs-URI Ihres Azure Machine Learning-Arbeitsbereichs verwiesen wird. Weitere Informationen zum Herstellen einer Verbindung zwischen MLflow und dem Arbeitsbereich finden Sie unter Konfigurieren von MLflow für Azure Machine Learning.
Abfrage- und Suchexperimente
Verwenden Sie MLflow, um in Ihrem Arbeitsbereich nach Experimenten zu suchen. Hierzu folgende Beispiele:
Abrufen aller aktiven Experimente:
mlflow.search_experiments()Hinweis
In Legacyversionen von MLflow (<2.0) verwenden Sie stattdessen die Methode
mlflow.list_experiments().Abrufen aller Experimente, einschließlich der archivierten:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)Abrufen eines bestimmten Experiments anhand des Namens:
mlflow.get_experiment_by_name(experiment_name)Abrufen eines bestimmten Experiments anhand der ID:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
Experimente suchen
Mit der search_experiments()-Methode, die seit MLflow 2.0 verfügbar ist, können Sie mit filter_string nach Experimenten suchen, die den Kriterien entsprechen.
Abrufen mehrerer Experimente basierend auf ihren IDs:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )Abrufen aller Experimente, die nach einer bestimmten Zeit erstellt wurden:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")Abrufen aller Experimente mit einem bestimmten Tag:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
Abfrage- und Suchausführungen
MLflow ermöglicht die Suche innerhalb eines beliebigen Experiments und auch in mehreren Experimenten gleichzeitig. Die Methode mlflow.search_runs() akzeptiert die Argumente experiment_ids und experiment_name, um anzugeben, nach welchen Experimenten Sie suchen möchten. Sie können auch search_all_experiments=True angeben, wenn Sie alle Experimente im Arbeitsbereich durchsuchen möchten:
Nach Experimentname:
mlflow.search_runs(experiment_names=[ "my_experiment" ])Nach Experiment-ID:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])Suchen in allen Experimenten im Arbeitsbereich:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
Beachten Sie, dass experiment_ids die Bereitstellung einer Reihe von Experimenten unterstützt, sodass Sie bei Bedarf mehrere Experimente durchsuchen können. Das kann nützlich sein, wenn Sie Ausführungen desselben Modells vergleichen möchten, falls es in verschiedenen Experimenten protokolliert wird (z. B. von verschiedenen Personen oder verschiedenen Projektiterationen).
Wichtig
Wenn experiment_ids, experiment_names oder search_all_experiments nicht angegeben sind, sucht MLflow standardmäßig im derzeit aktiven Experiment. Sie können das aktive Experiment mithilfe von mlflow.set_experiment() festlegen.
Standardmäßig gibt MLflow die Daten im Pandas-Format Dataframe zurück. Das ist für die Weiterverarbeitung der Ausführungsanalyse praktisch. Zurückgegebene Daten enthalten Spalten mit:
- Grundlegenden Informationen zur Ausführung.
- Parametern mit dem Spaltennamen
params.<parameter-name>. - Metriken (jeweils zuletzt protokollierter Wert) mit dem Spaltennamen
metrics.<metric-name>.
Alle Metriken und Parameter werden auch beim Abfragen von Ausführungen zurückgegeben. Für Metriken, die mehrere Werte enthalten (z. B. eine Verlustkurve oder eine PR-Kurve), wird jedoch nur der letzte Wert der Metrik zurückgegeben. Wenn Sie alle Werte einer bestimmten Metrik abrufen möchten, wird die mlflow.get_metric_history-Methode verwendet. Ein Beispiel finden Sie unter Abrufen von Parametern und Metriken aus einer Ausführung.
Sortieren von Ausführungen
Standardmäßig werden Experimente absteigend nach start_time sortiert. Dies ist der Zeitpunkt, zu dem das Experiment in Azure Machine Learning in die Warteschlange eingereiht wurde. Sie können diese Standardeinstellung jedoch mithilfe des Parameters order_by ändern.
Festlegen der Reihenfolge der Ausführungen nach Attributen, z. B.
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])Legen Sie die Reihenfolge der Ausführungen fest und schränken Sie die Ergebnisse ein. Im folgenden Beispiel wird die letzte einzelne Ausführung im Experiment zurückgegeben:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])Reihenfolge der Ausführungen nach dem Attribut
duration:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])Tipp
attributes.durationist nicht in MLflow-OSS vorhanden, wird aber der Einfachheit halber in Azure Machine Learning bereitgestellt.Reihenfolge der Ausführung nach Metrikwerten:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)Warnung
Das Verwenden von
order_bymit Ausdrücken, diemetrics.*,params.*odertags.*im Parameterorder_byenthalten, wird derzeit nicht unterstützt. Verwenden Sie stattdessen dieorder_values-Methode von Pandas wie im Beispiel dargestellt.
Filtern von Ausführungen
Sie können auch nach einer Ausführung mit einer bestimmten Kombination in den Hyperparametern suchen. Verwenden Sie dazu den Parameter filter_string. Verwenden Sie params, um auf die Parameter der Ausführung zuzugreifen, metrics, um auf Metriken zuzugreifen, die bei der Ausführung protokolliert wurden, und attributes, um auf Ausführungsinformationen zuzugreifen. MLflow unterstützt Ausdrücke, die mit dem AND-Schlüsselwort verbunden sind (OR wird von der Syntax nicht unterstützt):
Suchausführungen basierend auf dem Wert eines Parameters:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")Warnung
Nur die Operatoren
=,likeund!=werden zum Filtern vonparametersunterstützt.Suchausführungen basierend auf dem Wert einer Metrik:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")Suchausführungen mit einem bestimmten Tag:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")Suchausführungen, die von einem bestimmten Benutzer erstellt wurden:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")Suchen Sie nach fehlerhaften Ausführungen. Mögliche Werte finden Sie unter Filterausführungen nach Status:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")Suchausführungen, die nach einer bestimmten Zeit erstellt wurden:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")Tipp
Werte für den Schlüssel
attributessollten immer Zeichenfolgen sein und daher zwischen Anführungszeichen codiert werden.Suchen Sie nach Ausführungen, die länger als eine Stunde dauern:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")Tipp
attributes.durationist nicht in MLflow-OSS vorhanden, wird aber der Einfachheit halber in Azure Machine Learning bereitgestellt.Suchen Sie nach Ausführungen mit der ID in einer bestimmten Gruppe:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
Filtern von Ausführungen nach Status
Beim Filtern von Ausführungen nach Status verwendet MLflow eine andere Konvention, um die verschiedenen möglichen Status einer Ausführung im Vergleich zu Azure Machine Learning zu benennen. In der folgenden Tabelle sind die möglichen Werte aufgeführt:
| Status des Azure Machine Learning-Auftrags | attributes.status von MLflow |
Bedeutung |
|---|---|---|
| Nicht begonnen | Scheduled |
Der Auftrag/die Ausführung wurde von Azure Machine Learning empfangen. |
| Warteschlange | Scheduled |
Das Ausführen des Auftrags/der Ausführung ist geplant, wurde aber noch nicht gestartet. |
| Wird vorbereitet | Scheduled |
Der Auftrag oder die Ausführung wurde noch nicht gestartet, aber eine Computeressource wurde für ihre Ausführung zugewiesen und bereitet die Umgebung und ihre Eingaben vor. |
| Wird ausgeführt | Running |
Der Auftrag/die Ausführung wird derzeit aktiv ausgeführt. |
| Abgeschlossen | Finished |
Der Auftrag oder die Ausführung wurde ohne Fehler abgeschlossen. |
| Fehler | Failed |
Der Auftrag oder die Ausführung wurde mit Fehlern abgeschlossen. |
| Storniert | Killed |
Der Auftrag oder die Ausführung wurde vom Benutzer abgebrochen oder vom System beendet. |
Beispiel:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
Abrufen von Metriken, Parametern, Artefakten und Modellen
Die Methode search_runs gibt ein Pandas-Element (Dataframe) zurück, das standardmäßig eine begrenzte Menge an Informationen enthält. Sie können Python-Objekte nach Bedarf abrufen, was möglicherweise hilfreich ist, um Details zu ihnen zu erhalten. Verwenden Sie den Parameter output_format, um zu steuern, wie die Ausgabe zurückgegeben wird:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
Auf Details kann dann über das info-Mitglied zugegriffen werden. Das folgende Beispiel zeigt, wie die run_id abgerufen wird:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
Abrufen von Parametern und Metriken aus einer Ausführung
Wenn Ausführungen mit output_format="list" zurückgegeben werden, können Sie einfach mithilfe des Schlüssels data auf Parameter zugreifen:
last_run.data.params
Auf dieselbe Weise können Sie Metriken abfragen:
last_run.data.metrics
Für Metriken, die mehrere Werte enthalten (z. B. eine Verlustkurve oder eine PR-Kurve), wird nur der letzte protokollierte Wert der Metrik zurückgegeben. Wenn Sie alle Werte einer bestimmten Metrik abrufen möchten, wird die mlflow.get_metric_history-Methode verwendet. Für diese Methode müssen Sie MlflowClient verwenden:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
Abrufen von Artefakten aus einer Ausführung
MLflow kann jedes von einer Ausführung protokollierte Artefakt abfragen. Auf Artefakte kann nicht mithilfe des Ausführungsobjekts selbst zugegriffen werden. Stattdessen sollte der MLflow-Client verwendet werden:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
Die vorherige Methode listet alle Artefakte auf, die in der Ausführung protokolliert sind. Sie verbleiben jedoch im Artefaktspeicher (Azure Machine Learning-Speicher). Verwenden Sie zum Herunterladen beliebiger Artefakte die Methode download_artifact:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
Hinweis
In Legacyversionen von MLflow (<2.0) verwenden Sie stattdessen die Methode MlflowClient.download_artifacts().
Abrufen von Modellen aus einer Ausführung
Modelle können auch in der Ausführung protokolliert und dann direkt daraus abgerufen werden. Um ein Modell abzurufen, müssen Sie den Pfad zum Artefakt kennen, in dem es gespeichert ist. Mit der Methode list_artifacts kann nach Artefakten gesucht werden, die ein Modell darstellen, da MLflow-Modelle immer Ordner sind. Sie können ein Modell herunterladen, indem Sie den Pfad angeben, in dem das Modell mithilfe der download_artifact-Methode gespeichert wird:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
Anschließend können Sie das Modell aus den heruntergeladenen Artefakten mithilfe der typischen Funktion load_model im variantenspezifischen Namespace laden. Im folgenden Beispiel wird xgboost verwendet:
model = mlflow.xgboost.load_model(model_local_path)
MLflow ermöglicht es Ihnen auch, beide Vorgänge gleichzeitig auszuführen und das Modell in einer einzigen Anweisung herunterzuladen und zu laden. MLflow lädt das Modell in einen temporären Ordner herunter und lädt es von dort aus. Die Methode load_model gibt mithilfe eines URI-Formats an, wo das Modell abgerufen werden muss. Beim Laden eines Modells aus einer Ausführung sieht die URI-Struktur wie folgt aus:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
Tipp
Informationen zum Abfragen und Laden von Modellen, die in der Modellregistrierung registriert sind, finden Sie unter Verwalten von Modellregistrierungen in Azure Machine Learning mit MLflow.
Abrufen von untergeordneten (geschachtelten) Ausführungen
MLflow unterstützt das Konzept von untergeordneten (geschachtelten) Ausführungen. Diese Ausführungen sind nützlich, wenn Sie nachzuverfolgende Trainingsroutinen unabhängig vom Haupttrainingsprozess ausgliedern müssen. Prozesse für die Hyperparameteroptimierung oder Azure Machine Learning-Pipelines sind typische Beispiele für Aufträge, die mehrere untergeordnete Ausführungen generieren. Sie können alle untergeordneten Ausführungen einer bestimmten Ausführung mithilfe des Eigenschaftentags mlflow.parentRunId abfragen, das die Ausführungs-ID der übergeordneten Ausführung enthält.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
Vergleichen von Aufträgen und Modellen in Azure Machine Learning Studio (Vorschau)
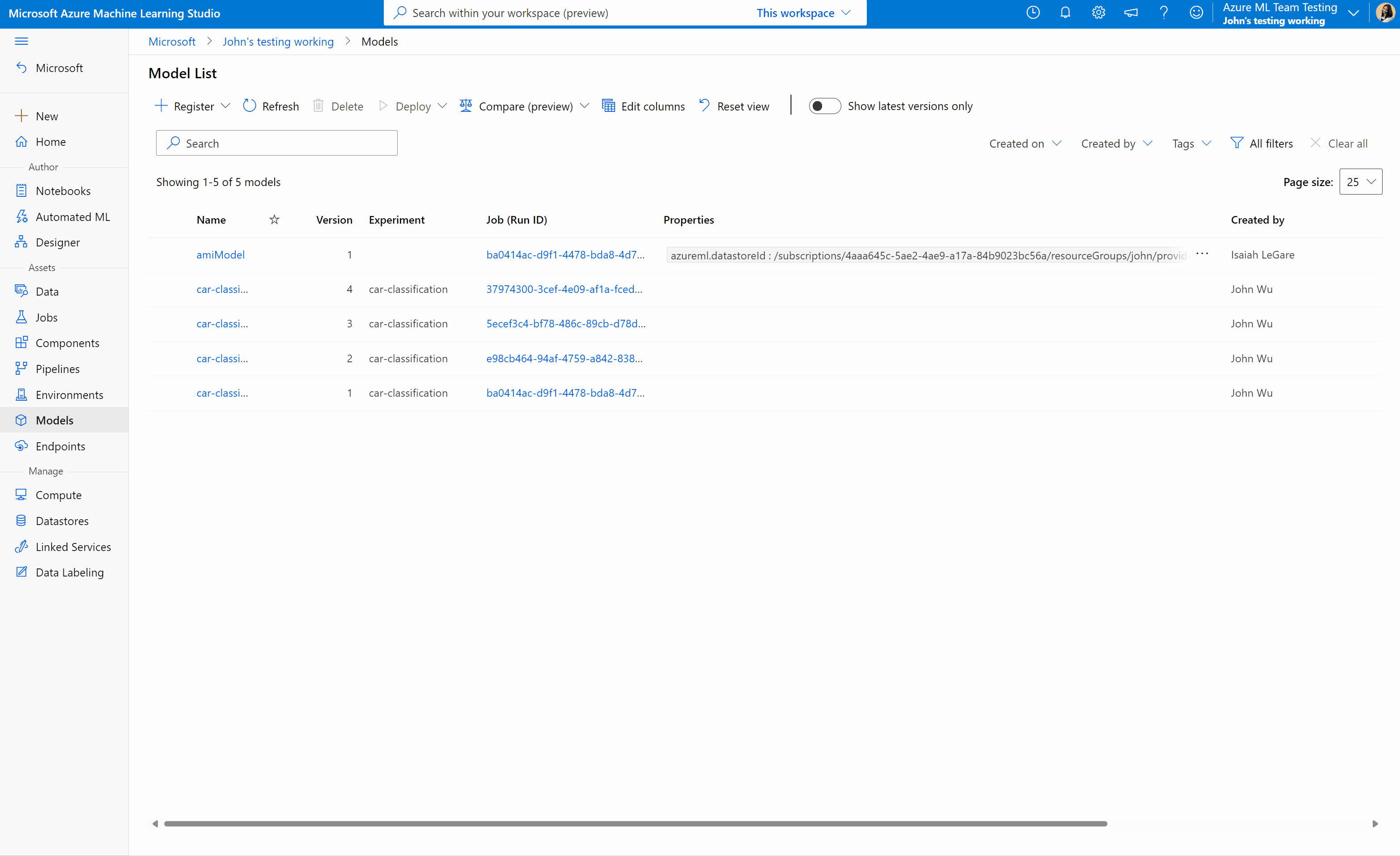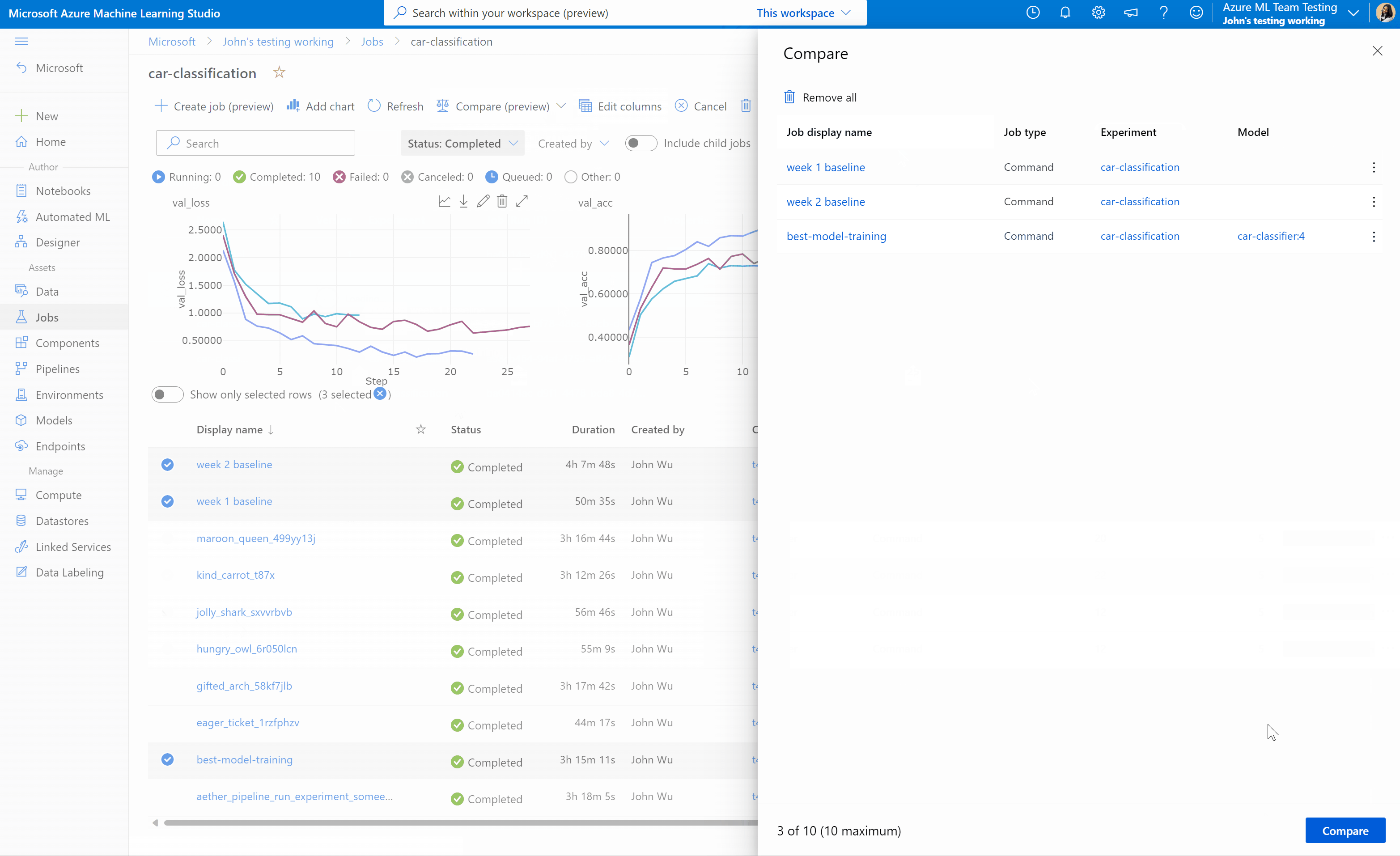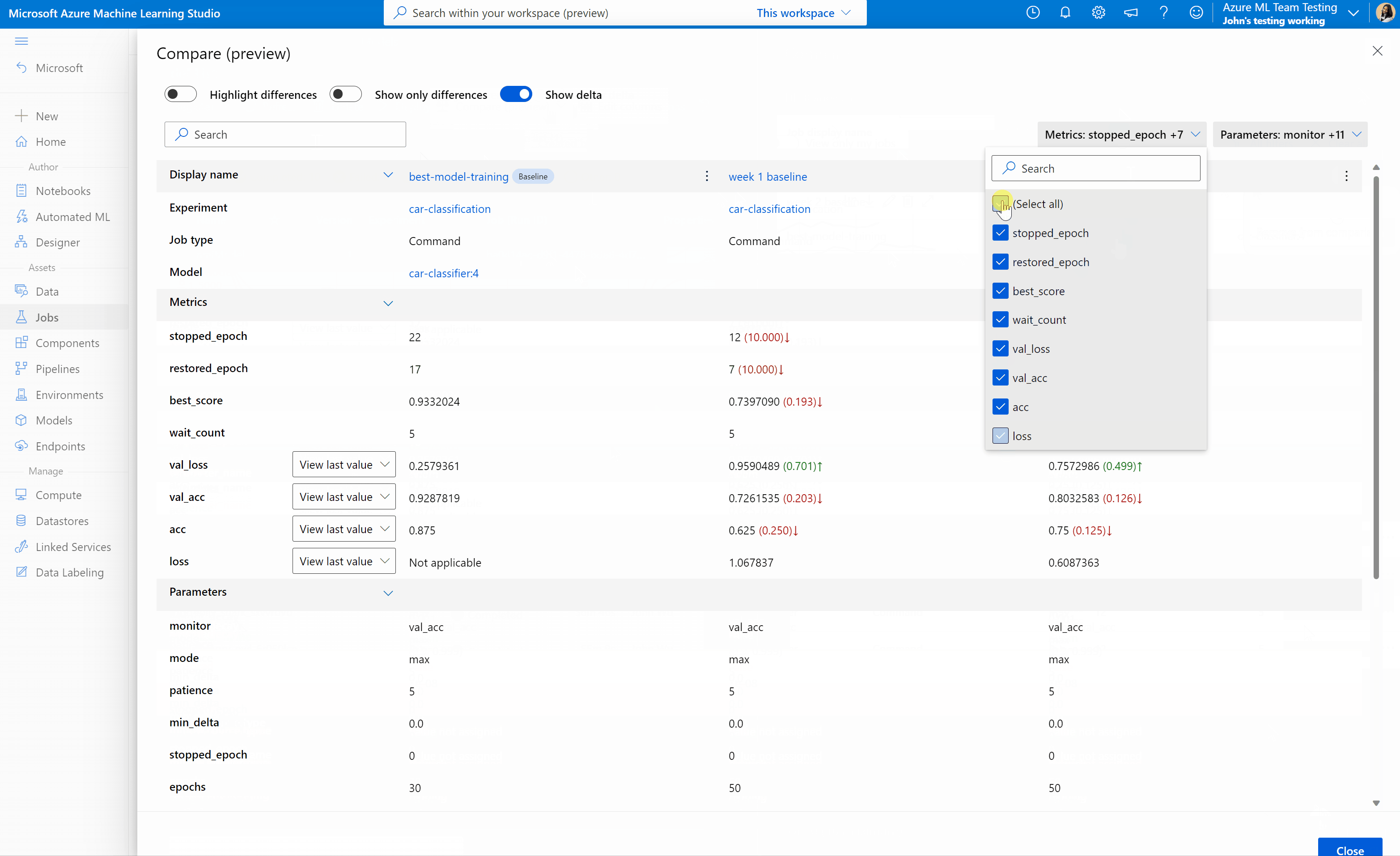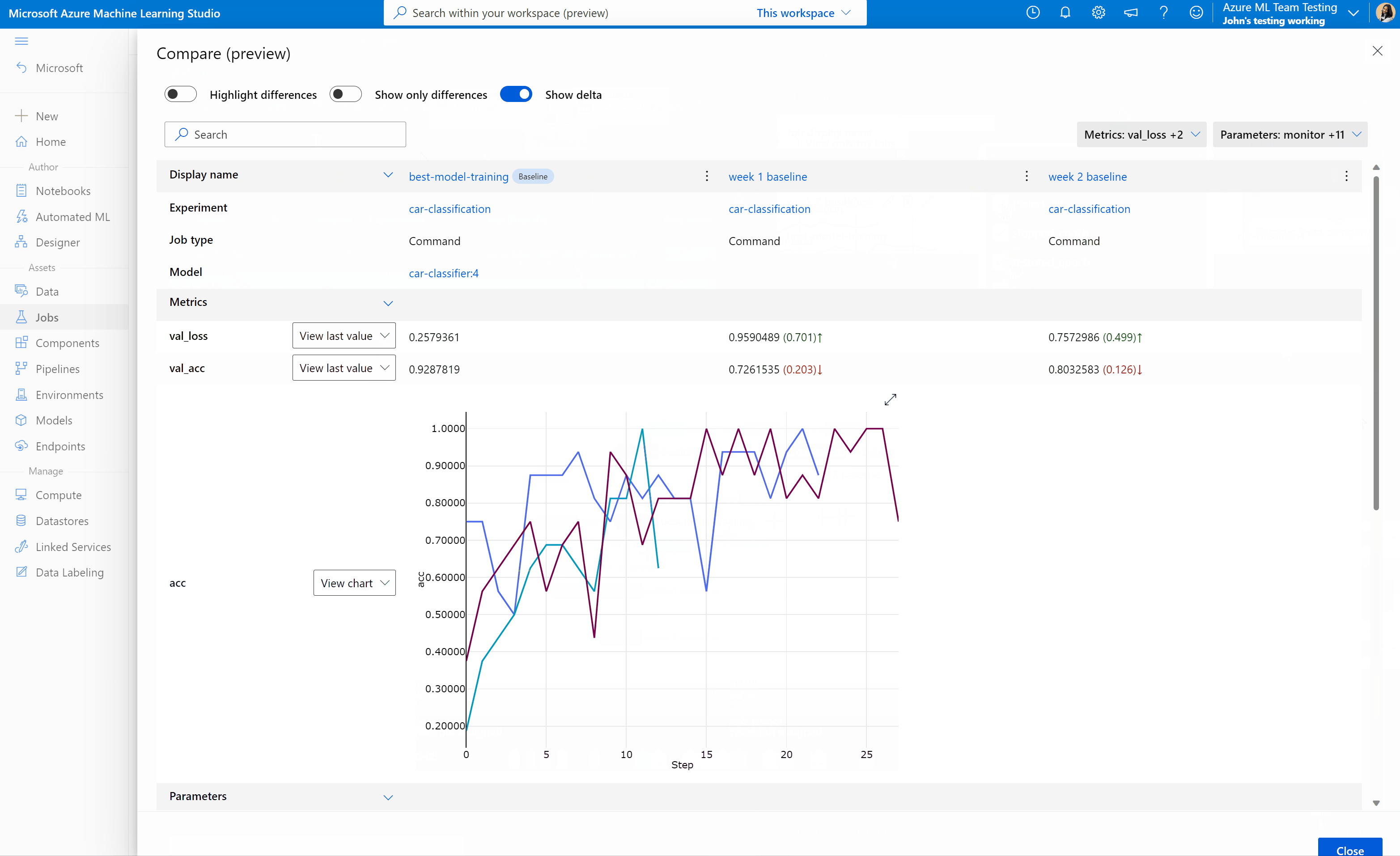
Um die Qualität Ihrer Aufträge und Modelle in Azure Machine Learning Studio zu vergleichen und zu bewerten, verwenden Sie den Vorschaubereich, um das Feature zu aktivieren. Nach der Aktivierung können Sie die Parameter, Metriken und Tags der von Ihnen ausgewählten Aufträge und/oder Modelle vergleichen.
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Die Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In den Notebooks „MLflow mit Azure Machine Learning“ werden die in diesem Artikel vorgestellten Konzepte weiter erläutert und demonstriert.
- Trainieren und Nachverfolgen eines Klassifizierers mit MLflow: Hier erfahren Sie, wie Sie Experimente mithilfe von MLflow nachverfolgen, Modelle protokollieren und mehrere Varianten in Pipelines kombinieren können.
- Verwalten von Experimenten und Ausführungen mit MLflow: Hier wird veranschaulicht, wie Sie Experimente, Ausführungen, Metriken, Parameter und Artefakte aus Azure Machine Learning mithilfe von MLflow abfragen.
Unterstützungsmatrix zum Abfragen von Ausführungen und Experimenten
Das MLflow SDK macht mehrere Methoden zum Abrufen von Ausführungen verfügbar, einschließlich Optionen, mit denen gesteuert werden kann, was zurückgegeben wird und wie. In der folgenden Tabelle erfahren Sie, welche dieser Methoden derzeit in MLflow unterstützt wird, wenn sie mit Azure Machine Learning verbunden ist:
| Funktion | Von MLflow unterstützt | Unterstützt durch Azure Machine Learning |
|---|---|---|
| Sortieren von Ausführungen nach Attributen | ✓ | ✓ |
| Sortieren von Ausführungen nach Metriken | ✓ | 1 |
| Sortieren von Ausführungen nach Parametern | ✓ | 1 |
| Sortieren von Ausführungen nach Tags | ✓ | 1 |
| Filtern von Ausführungen nach Attributen | ✓ | ✓ |
| Filtern von Ausführungen nach Metriken | ✓ | ✓ |
| Filtern von Ausführungen nach Metriken mit Sonderzeichen (Mit Escapezeichen) | ✓ | |
| Filtern von Ausführungen nach Parametern | ✓ | ✓ |
| Filtern von Ausführungen nach Tags | ✓ | ✓ |
Filtern von Ausführungen mit numerischen Vergleichsoperatoren (Metriken), einschließlich =, !=, >, >=, < und <= |
✓ | ✓ |
Filtern von Ausführungen mit Vergleichsoperatoren für Zeichenfolgen (Parameter, Tags und Attribute): = und != |
✓ | ✓2 |
Filtern von Ausführungen mit Vergleichsoperatoren für Zeichenfolgen (Parameter, Tags und Attribute): LIKE/ILIKE |
✓ | ✓ |
Filtern von Ausführungen mit Vergleichsoperatoren AND |
✓ | ✓ |
Filtern von Ausführungen mit Vergleichsoperatoren OR |
||
| Umbenennen von Experimenten | ✓ |
Hinweis
- 1 Im Abschnitt Sortieren von Ausführungen finden Sie Anweisungen und Beispiele dazu, wie Sie die gleiche Funktionalität in Azure Machine Learning erreichen können.
- 2
!=für Tags, die nicht unterstützt werden.