Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Tutorial erfahren Sie, wie Sie ein Klassifizierungsmodell mit No-Code-AutoML (automatisiertes maschinelles Lernen) trainieren, indem Sie in Azure Machine Learning Studio Azure Machine Learning verwenden. Dieses Klassifizierungsmodell sagt vorher, ob ein Kunde Festgeld bei einer Bank anlegt.
Mit automatisiertem ML können Sie zeitintensive Aufgaben automatisieren. Beim automatisierten maschinellen Lernen werden viele Kombinationen von Algorithmen und Hyperparametern schnell durchlaufen, um basierend auf einer von Ihnen ausgewählten Erfolgsmetrik das beste Modell zu ermitteln.
In diesem Tutorial schreiben Sie keinen Code. Sie verwenden die Studioschnittstelle, um das Training durchzuführen. Dabei lernen Sie Folgendes:
- Erstellen eines Azure Machine Learning-Arbeitsbereichs
- Ausführen eines automatisierten Machine Learning-Experiments
- Untersuchen der Modelldetails
- Bereitstellen des empfohlenen Modells
Voraussetzungen
Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen.
Laden Sie die Datendatei bank+marketing.zip herunter. Wir verwenden die bank-full.csv Datei. In der Spalte y ist angegeben, ob ein Kunde Festgeld angelegt hat. Sie wird später als Zielspalte für Vorhersagen in diesem Tutorial festgelegt.
Hinweis
Dieses Bank Marketing-Dataset wird unter der Creative Commons Attribution 4.0 International License zur Verfügung gestellt. Dieses Dataset ist als Teil der UCI Machine Learning-Datenbank verfügbar.
Moro, S., P. Rita und P. Cortez. 2014. Bankmarketing. UCI Machine Learning Repository. https://doi.org/10.24432/C5K306.
Erstellen eines Arbeitsbereichs
Ein Azure Machine Learning-Arbeitsbereich ist eine grundlegende Cloudressource zum Experimentieren, Trainieren und Bereitstellen von Machine Learning-Modellen. Er verknüpft Ihr Azure-Abonnement und Ihre Ressourcengruppe mit einem einfach nutzbaren Objekt im Dienst.
Führen Sie die folgenden Schritte aus, um einen Arbeitsbereich zu erstellen und das Tutorial fortzusetzen.
Melden Sie sich bei Azure Machine Learning Studio an.
Wählen Sie Create workspace (Arbeitsbereich erstellen) aus.
Geben Sie die folgenden Informationen an, um den neuen Arbeitsbereich zu konfigurieren:
Feld BESCHREIBUNG Arbeitsbereichname Geben Sie einen eindeutigen Namen ein, der Ihren Arbeitsbereich identifiziert. Namen müssen in der Ressourcengruppe eindeutig sein. Verwenden Sie einen Namen, der leicht zu merken ist und sich von den von anderen Benutzern erstellten Arbeitsbereichen unterscheidet. Für den Namen des Arbeitsbereichs wird die Groß-/Kleinschreibung nicht beachtet. Abonnement Wählen Sie das gewünschte Azure-Abonnement aus. Ressourcengruppe Verwenden Sie eine vorhandene Ressourcengruppe in Ihrem Abonnement, oder geben Sie einen Namen ein, um eine neue Ressourcengruppe zu erstellen. Eine Ressourcengruppe enthält verwandte Ressourcen für eine Azure-Lösung. Die Rolle Mitwirkender oder Besitzer ist für die Verwendung einer vorhandenen Ressourcengruppe erforderlich. Weitere Informationen finden Sie unter Zugriff auf einen Azure Machine Learning-Arbeitsbereich verwalten. Region Wählen Sie die Azure-Region aus, die Ihren Benutzern und den Datenressourcen am nächsten ist, um Ihren Arbeitsbereich zu erstellen. Klicken Sie auf Erstellen, um den Arbeitsbereich zu erstellen.
Weitere Informationen zu Azure-Ressourcen finden Sie unter Erstellen eines Arbeitsbereichs.
Weitere Möglichkeiten zum Erstellen eines Arbeitsbereichs in Azure finden Sie unter Verwalten von Azure Machine Learning-Arbeitsbereichen im Portal oder mit dem Python SDK (v2).
Erstellen eines Auftrags für automatisiertes maschinelles Lernen
Sie führen die folgenden Schritte zum Einrichten und Ausführen des Experiments in Azure Machine Learning Studio unter https://ml.azure.com aus. Machine Learning Studio ist eine konsolidierte Weboberfläche, die Tools für maschinelles Lernen zur Durchführung von Data Science-Szenarien für Datenwissenschaftler aller Qualifikationsstufen umfasst. Studio wird in Internet Explorer-Browsern nicht unterstützt.
Wählen Sie Ihr Abonnement und den erstellten Arbeitsbereich aus.
Wählen Sie im Navigationsbereich Erstellen>Automatisiertes maschinelles Lernen aus.
Wenn Sie in diesem Tutorial zum ersten Mal ein Experiment für automatisiertes ML ausführen, werden eine leere Liste und Links zur Dokumentation angezeigt.
Wählen Sie Neuer automatisierter ML-Auftrag aus.
Wählen Sie in Trainingsmethode die Option Automatisch trainieren aus, und wählen Sie dann Konfigurierungsauftrag starten aus.
Wählen Sie unter Standardeinstellungen die Option Neu erstellen aus, und geben Sie dann für Experimentname den Wert my-1st-automl-experiment ein.
Wählen Sie Weiter aus, um Ihr Dataset zu laden.

Erstellen und Laden eines Datasets als Datenressource
Laden Sie vor dem Konfigurieren Ihres Experiments die Datendatei in Form einer Azure Machine Learning-Datenressource in Ihren Arbeitsbereich hoch. In diesem Tutorial können Sie sich eine Datenressource als Ihr Dataset für den Auftrag für automatisiertes maschinelles Lernen vorstellen. Dadurch wird die ordnungsgemäße Formatierung der Daten für Ihr Experiment sichergestellt.
Wählen Sie in Vorgangsart und Daten unter Vorgangsart auswählen die Option Klassifizierung aus.
Wählen Sie unter Daten auswählen die Option Erstellen aus.
Geben Sie Ihrer Datenressource im Formular Datentyp einen Namen, und geben Sie optional eine Beschreibung an.
Wählen Sie als Typ die Option Tabellarisch aus. Die Schnittstelle für automatisiertes ML unterstützt derzeit nur TabularDatasets.
Wählen Sie Weiter aus.
Wählen Sie im Formular Datenquelle die Option Aus lokalen Dateien aus. Wählen Sie Weiter aus.
Wählen Sie im Formular Zieltyp den Standarddatenspeicher aus, der bei der Erstellung Ihres Arbeitsbereichs automatisch eingerichtet wurde: workspaceblobstore. Hier laden Sie Ihre Datendatei hoch, um sie für Ihren Arbeitsbereich verfügbar zu machen.
Wählen Sie Weiter aus.
Wählen Sie in der Datei- oder Ordnerauswahl die Option Dateien oder Ordner hochladen>Dateien hochladen aus.
Wählen Sie auf dem lokalen Computer die Datei bankmarketing_train.csv aus. Sie haben diese Datei als Voraussetzung heruntergeladen.
Wählen Sie Weiter aus.
Nach Abschluss des Uploads wird der Bereich Datenvorschau basierend auf dem Dateityp aufgefüllt.
Überprüfen Sie im Formular Einstellungen die Werte für Ihre Daten. Wählen Sie Weiteraus.
Feld BESCHREIBUNG Wert für das Tutorial Dateiformat Definiert das Layout und den Typ der in einer Datei gespeicherten Daten. Durch Trennzeichen getrennt Trennzeichen Mindestens ein Zeichen zum Angeben der Grenze zwischen separaten, unabhängigen Regionen in Nur-Text- oder anderen Datenströmen. Semikolon Codieren Gibt an, welche Bit-zu-Zeichen-Schematabelle verwendet werden soll, um Ihr Dataset zu lesen. UTF-8 Spaltenüberschriften Gibt an, wie die Header des Datasets, sofern vorhanden, behandelt werden. Alle Dateien weisen dieselben Header auf. Zeilen überspringen Gibt an, wie viele Zeilen im Dataset übersprungen werden. Keine Das Formular Schema ermöglicht eine weitere Konfiguration der Daten für dieses Experiment. Wählen Sie für dieses Beispiel den Umschalter für das Feature day_of_week aus, um es nicht einzuschließen. Wählen Sie Weiter aus.
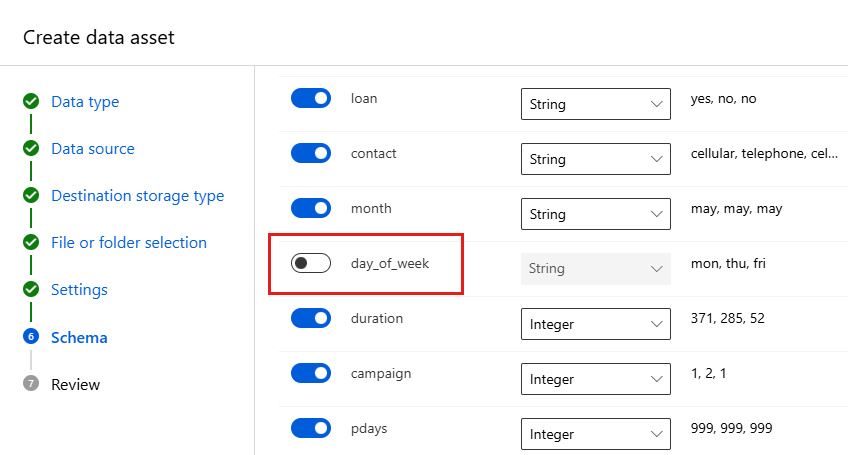
Überprüfen Sie im Formular Überprüfen die angezeigten Informationen, und wählen Sie dann Erstellen aus.
Wählen Sie dann Ihr Dataset aus der Liste aus.
Überprüfen Sie die Daten, indem Sie die Datenressource auswählen und die Registerkarte Vorschau anzeigen. Stellen Sie sicher, dass sie nicht day_of_week enthält, und wählen Sie Schließen aus.
Wählen Sie Weiter aus, um zu den Aufgabeneinstellungen zu gelangen.
Auftrag konfigurieren
Nach dem Laden und Konfigurieren Ihrer Daten können Sie Ihr Experiment einrichten. Dieses Setup umfasst Experimententwurfsaufgaben, etwa das Auswählen der Größe Ihrer Compute-Umgebung und das Angeben der Spalte, die Sie vorhersagen möchten.
Füllen Sie das Formular Aufgabeneinstellungen wie folgt aus:
Wählen Sie y (String) als Zielspalte aus, also als den vorherzusagenden Wert. Diese Spalte gibt an, ob der Kunde eine Termineinlage bei der Bank gezeichnet hat.
Klicken Sie auf Zusätzliche Konfigurationseinstellungen anzeigen, und füllen Sie die Felder wie folgt aus. Mit diesen Einstellungen können Sie den Trainingsauftrag besser steuern. Andernfalls werden die Standardwerte auf Basis der Experimentauswahl und -daten angewendet.
Zusätzliche Konfigurationen BESCHREIBUNG Wert für das Tutorial Primary metric (Primäre Metrik) Auswertungsmetrik, die zur Messung des Machine Learning-Algorithmus verwendet wird. AUCWeighted Explain best model (Bestes Modell erläutern) Zeigt automatisch die Erklärbarkeit für das beste Modell an, das durch automatisiertes ML erstellt wurde. Aktivieren Blockierte Modelle Algorithmen, die Sie aus den Trainingsauftrag ausschließen möchten. Keine Wählen Sie Speichern aus.
Unter Überprüfen und Testen:
- Wählen Sie als Validierungstyp die Option k-fache Kreuzvalidierung aus.
- Wählen Sie für Anzahl der Kreuzvalidierungen den Wert 2 aus.
Wählen Sie Weiter aus.
Wählen Sie Computecluster als Computetyp aus.
Ein Computeziel ist eine lokale oder cloudbasierte Ressourcenumgebung, in der Ihr Trainingsskript ausgeführt oder Ihre Dienstbereitstellung gehostet wird. Für dieses Experiment können Sie entweder cloudbasiertes serverloses Computing (Vorschau) ausprobieren oder eine eigene cloudbasierte Computeressource erstellen.
Hinweis
Um serverloses Computing zu verwenden, aktivieren Sie die Previewfunktion, wählen Sie Serverlos aus, und überspringen Sie den Rest dieses Schritts.
Um ein eigenes Computeziel zu erstellen, wählen Sie in Compute-Typ auswählen die Option Computecluster- aus, um Ihr Computeziel zu konfigurieren.
Füllen Sie das Formular für den virtuellen Computer aus, um Ihre Compute-Instanz einzurichten. Wählen Sie Neuaus.
Feld BESCHREIBUNG Wert für das Tutorial Standort Ihre Region, von der aus Sie die VM ausführen möchten USA, Westen 2 Stufe der VM Wählen Sie aus, welche Priorität ihr Experiment aufweisen soll. Dediziert Typ des virtuellen Computers Wählen Sie den VM-Typ für Ihre Compute-Umgebung aus. CPU (Zentralprozessor) Größe des virtuellen Computers Wählen Sie die Größe für Ihren Computes aus. Eine Liste der empfohlenen Größen wird auf der Grundlage Ihrer Daten und des Experimenttyps bereitgestellt. Standard_DS12_V2 Wählen Sie Weiter aus, um zum Formular Erweiterte Einstellungen zu wechseln.
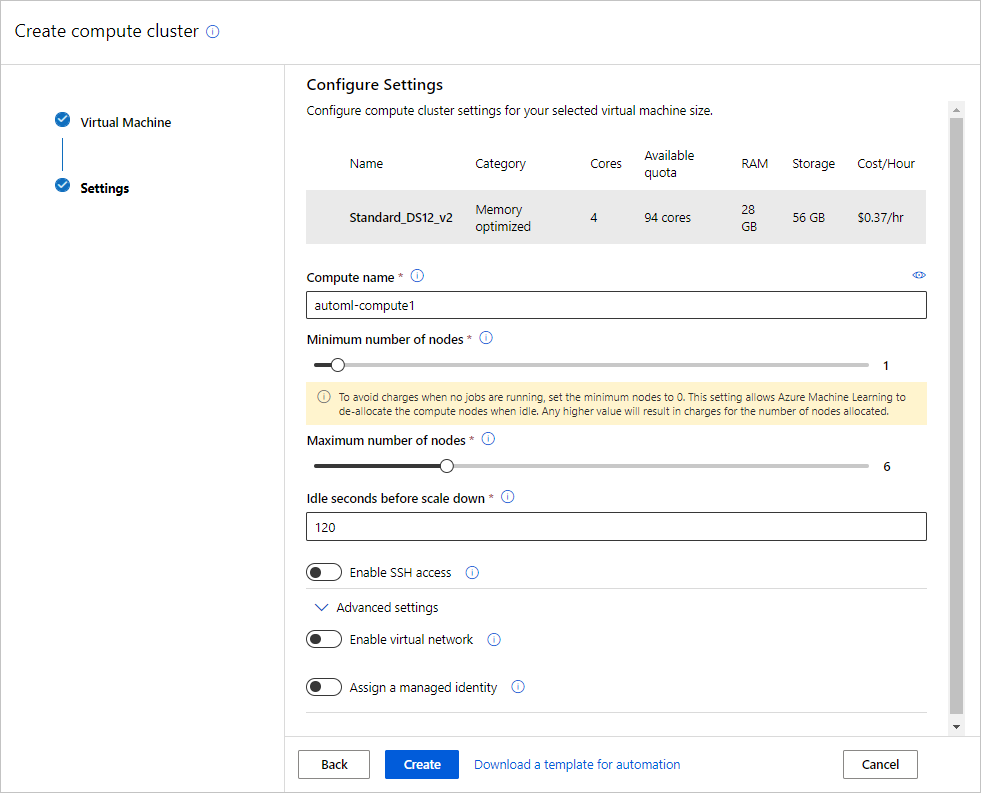
Feld BESCHREIBUNG Wert für das Tutorial Computename Ein eindeutiger Name, der Ihren Computekontext identifiziert. automl-compute Min/Max nodes (Min./Max. Knoten) Um ein Datenprofil zu erstellen, müssen Sie mindestens einen Knoten angeben. Min. Knoten: 1
Max. Knoten: 6Leerlauf in Sekunden vor dem Herunterskalieren Leerlaufzeit vor dem automatischen Herunterskalieren des Clusters auf die minimale Knotenanzahl 120 (Standardwert) Erweiterte Einstellungen Einstellungen zum Konfigurieren und Autorisieren eines virtuellen Netzwerks für Ihr Experiment Keine Klicken Sie auf Erstellen.
Das Erstellen einer Berechnung kann einige Minuten dauern.
Wählen Sie nach der Erstellung in der Liste Ihr neues Computeziel aus. Wählen Sie Weiter aus.
Wählen Sie Trainingsauftrag übermitteln aus, um das Experiment auszuführen. Wenn die Vorbereitung des Experiments beginnt, wird der Bildschirm Übersicht geöffnet, auf dem am oberen Rand der Status angezeigt wird. Dieser Status wird während des Experimentausführung entsprechend aktualisiert. Außerdem werden in Studio Benachrichtigungen angezeigt, die Sie über den Status Ihres Experiments informieren.

Wichtig
Die Vorbereitung des Experiments nimmt 10 –15 Minuten in Anspruch. Sobald es ausgeführt wird, dauert jede Iteration mindestens zwei bis drei Minuten.
In einer Produktionsumgebung würden Sie in dieser Zeit wahrscheinlich eine kurze Pause machen. Für dieses Tutorial empfehlen wir jedoch, schon während der Ausführung der weiteren Algorithmen mit der Untersuchung der getesteten Algorithmen auf der Registerkarte Modelle zu beginnen.
Untersuchen von Modellen
Navigieren Sie zur Registerkarte Modelle + untergeordnete Aufträge, um die getesteten Algorithmen (Modelle) anzuzeigen. Standardmäßig werden die Modelle vom Auftrag nach ihrem Abschluss anhand der Metrikbewertung sortiert. In diesem Tutorial steht das Modell, das für die ausgewählte AUCWeighted-Metrik die höchste Bewertung erhält, ganz oben in der Liste.
Während Sie auf den Abschluss aller Experimentmodelle warten, können Sie den Algorithmusnamen eines abgeschlossenen Modells auswählen und sich die zugehörigen Leistungsdetails ansehen. Wählen Sie die Registerkarte Übersicht und dann Metriken aus, um Informationen zu dem Auftrag zu erhalten.
Die folgende Animation zeigt die Eigenschaften, Metriken und Leistungsdiagramme des ausgewählten Modells.

Anzeigen von Modellerklärungen
Während Sie darauf warten, dass die Modelle abgeschlossen werden, können Sie anhand der Modellerklärungen ermitteln, welche Datenfeatures (Rohdaten oder verarbeitete Daten) die Vorhersagen eines bestimmten Modells beeinflusst haben.
Diese Modellerklärungen können bei Bedarf generiert werden. Das Modellerklärungsdashboard, das Teil der Registerkarte Erklärungen (Vorschau) ist, fasst diese Erklärungen zusammen.
So generieren Sie Modellerklärungen:
Wählen Sie in den Navigationslinks oben auf der Seite den Auftragsnamen aus, um zum Bildschirm Modelle zurückzukehren.
Wählen Sie die Registerkarte Modelle + untergeordnete Aufträge aus.
Wählen Sie für dieses Tutorial das erste Modell MaxAbsScaler, LightGBM aus.
Wählen Sie Modell erklären aus. Auf der rechten Seite wird der Bereich Modell erklären angezeigt.
Wählen Sie Ihren Computetyp aus, und wählen Sie dann die Instanz oder den Cluster aus (automl-compute), den Sie zuvor erstellt haben. Dieser Computevorgang initiiert einen untergeordneten Auftrag, um die Modellerklärungen zu generieren.
Klicken Sie auf Erstellen. Eine grüne Erfolgsmeldung wird angezeigt.
Hinweis
Die Erklärbarkeitsauftrag dauert ca. zwei bis fünf Minuten.
Wählen Sie Erklärungen (Vorschau) aus. Diese Registerkarte wird nach Abschluss der Erklärbarkeitsausführung aufgefüllt.
Erweitern Sie den Bereich auf der linken Seite. Wählen Sie unter Features die Zeile aus, die raw enthält.
Wählen Sie die Registerkarte Aggregierte Featurerelevanz aus. Dieses Diagramm zeigt, welche Datenfeatures die Vorhersagen des ausgewählten Modells beeinflusst haben.
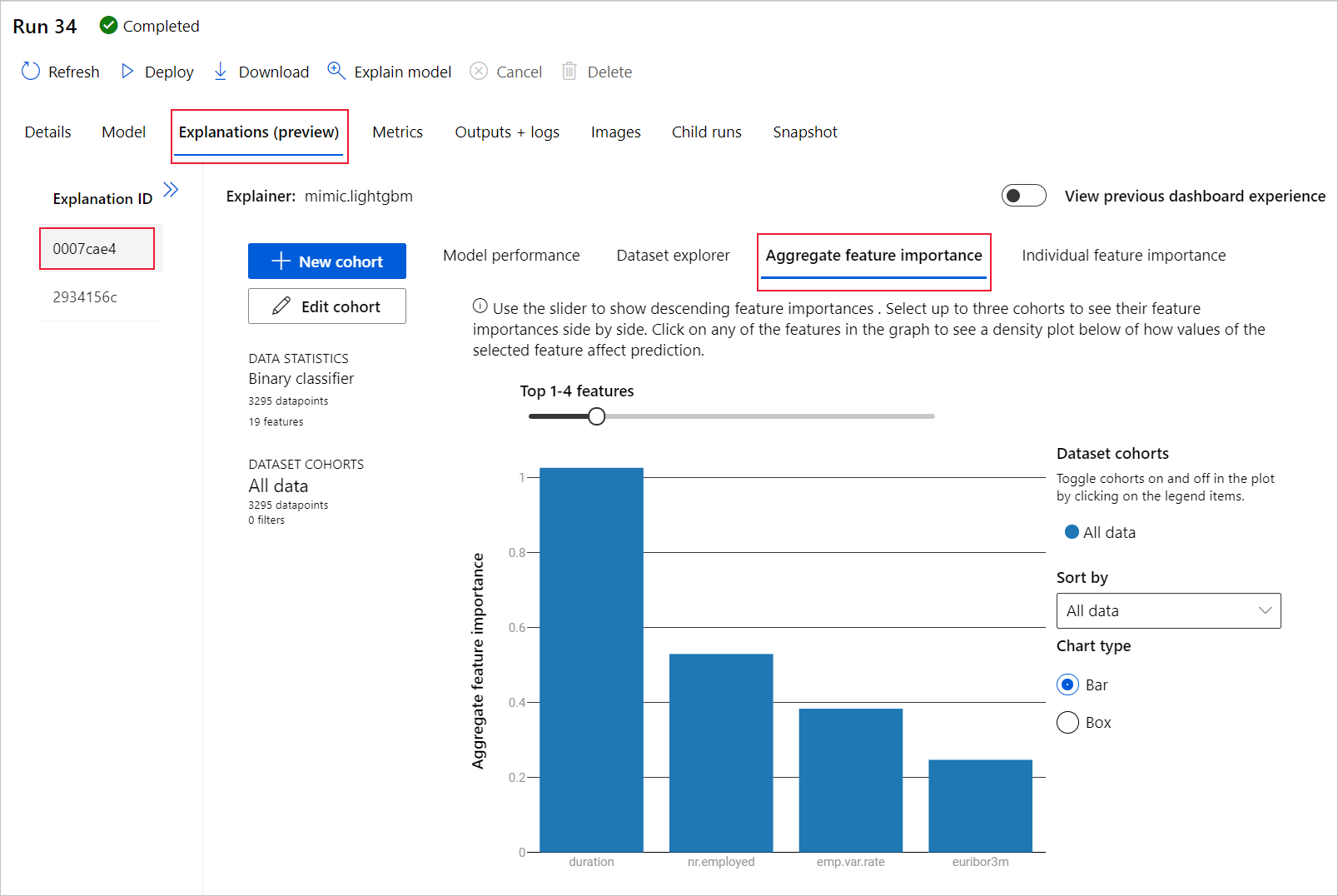
In diesem Beispiel hatte offenbar die Dauer den größten Einfluss auf die Vorhersagen des Modells.

Bereitstellen des besten Modells
Über die Oberfläche für automatisiertes maschinelles Lernen können Sie in wenigen Schritten das beste Modell als Webdienst bereitstellen. Bei der Bereitstellung handelt es sich um die Integration des Modells, sodass neue Daten vorhergesagt und potenzielle Verkaufschancen identifiziert werden können. In diesem Experiment bedeutet Bereitstellung in einem Webdienst, dass das Finanzinstitut nun über eine iterative und skalierbare Weblösung zur Identifizierung potenzieller Festgeldkunden verfügt.
Überprüfen Sie, ob die Ausführung des Experiments beendet ist. Navigieren Sie dazu zurück zur Seite mit dem übergeordneten Auftrag, indem Sie oben auf dem Bildschirm den Auftrag auswählen. Oben links auf dem Bildschirm wird der Status Abgeschlossen angezeigt.
Wenn die Ausführung des Experiments abgeschlossen ist, wird die Seite Details mit dem Abschnitt Zusammenfassung des besten Modells aufgefüllt. Aus diesem Experimentkontext geht VotingEnsemble basierend auf der AUCWeighted-Metrik als bestes Modell hervor.
Stellen Sie dieses Modell bereit. Die Bereitstellung dauert bis zu 20 Minuten. Der Bereitstellungsprozess umfasst mehrere Schritte, einschließlich der Registrierung des Modells, der Erstellung von Ressourcen und der Konfiguration dieser Ressourcen für den Webdienst.
Wählen Sie VotingEnsemble aus, um die modellspezifische Seite zu öffnen.
Wählen Sie Bereitstellen>Webdienst aus.
Füllen Sie den Bereich Modell bereitstellen wie folgt aus:
Feld Wert Name my-automl-deploy BESCHREIBUNG „Meine erste Bereitstellung eines automatisierten Machine Learning-Experiments“ Computetyp Auswählen der Azure Container-Instanz Authentifizierung aktivieren Deaktivieren Sie diese Option. Use custom deployment assets (Benutzerdefinierte Bereitstellungsressourcen verwenden) Deaktivieren Sie diese Option. Dadurch wird die automatische Erstellung der Standardtreiberdatei (Bewertungsskript) und der Umgebungsdatei ermöglicht. In diesem Beispiel werden die im Menü Erweitert angegebenen Standardwerte verwendet.
Klicken Sie auf Bereitstellen.
Im oberen Bereich des Bildschirms Auftrag wird eine grüne Erfolgsmeldung angezeigt. Im Bereich Modellzusammenfassung wird unter Bereitstellungsstatus eine Statusmeldung angezeigt. Wählen Sie von Zeit zu Zeit die Option Aktualisieren, um den Status der Bereitstellung zu überprüfen.
Sie haben einen einsatzfähigen Webdienst, mit dem Vorhersagen generiert werden können.
Fahren Sie mit den Verwandten Inhalten fort, um weitere Informationen zur Verwendung Ihres neuen Webdiensts zu erhalten, und testen Sie Ihre Vorhersagen mithilfe der integrierten Azure Machine Learning-Unterstützung von Power BI.
Bereinigen von Ressourcen
Bereitstellungsdateien sind größer als Daten- und Experimentdateien, sodass ihre Speicherung teurer ist. Wenn Sie den Arbeitsbereich und die Experimentdateien beibehalten möchten, löschen Sie nur die Bereitstellungsdateien, um die Kosten für Ihr Konto zu minimieren. Löschen Sie andernfalls die gesamte Ressourcengruppe, wenn Sie keine der Dateien weiter verwenden möchten.
Löschen der Bereitstellungsinstanz
Löschen Sie nur die Bereitstellungsinstanz aus Azure Machine Learning unter https://ml.azure.com/..
Wechseln Sie zu Azure Machine Learning. Navigieren Sie zu Ihrem Arbeitsbereich, und wählen Sie unter dem Bereich Ressourcen die Option Endpunkte aus.
Wählen Sie die zu löschende Bereitstellung aus, und klicken Sie auf Delete (Löschen).
Wählen Sie Proceed (Fortfahren) aus.
Löschen der Ressourcengruppe
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Geben Sie im Azure-Portal den Suchbegriff Ressourcengruppen in das Suchfeld ein, und wählen Sie in den Ergebnissen die entsprechende Option aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie auf der Seite Übersicht die Option Ressourcengruppe löschen aus.
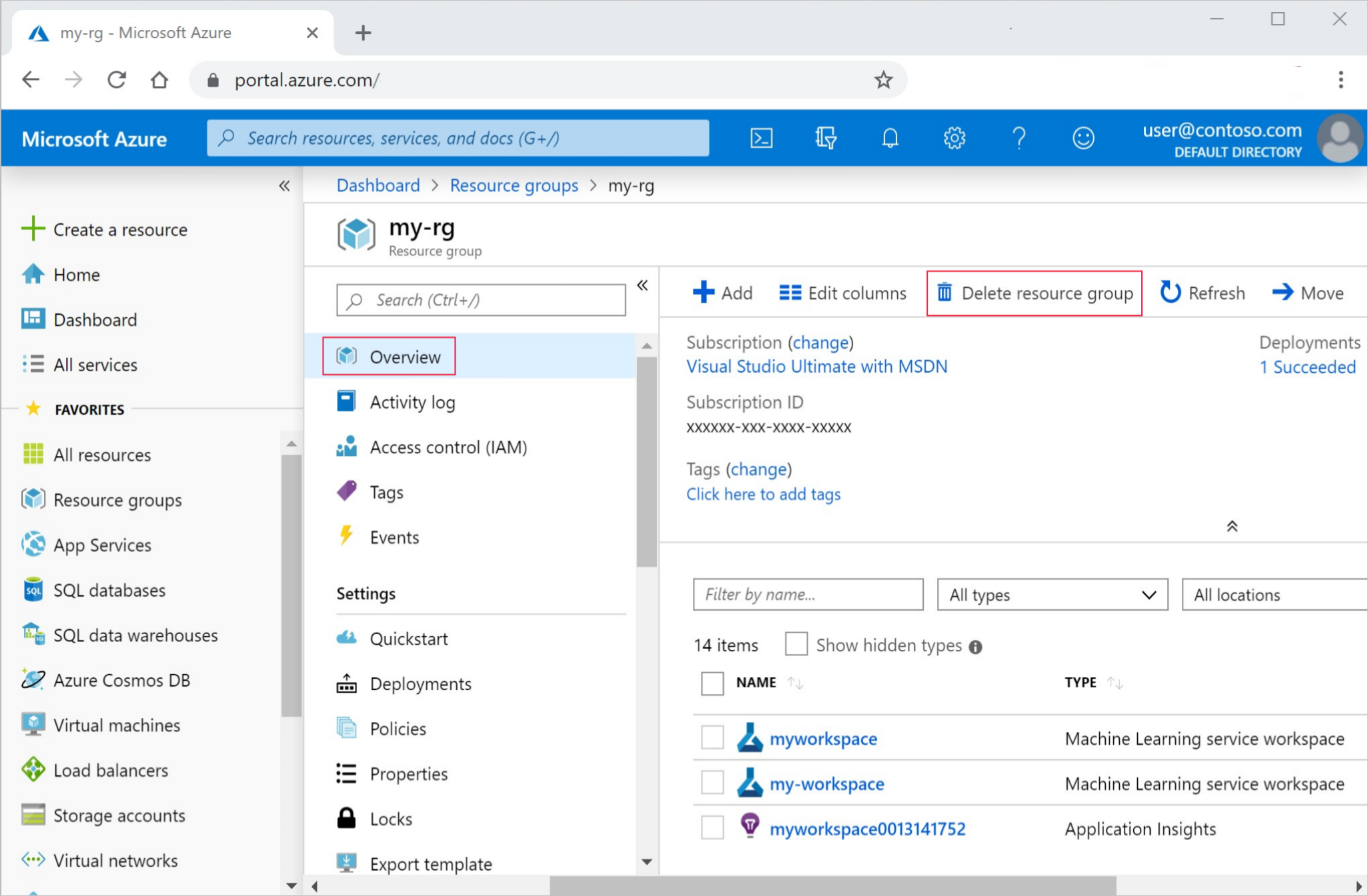
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Verwandte Inhalte
In diesem Tutorial zum automatisierten maschinellen Lernen haben Sie über die Oberfläche für automatisiertes maschinelles Lernen von Azure Machine Learning ein Klassifizierungsmodell erstellt und bereitgestellt. Weitere Informationen und nächste Schritte finden Sie in diesen Ressourcen:
- Weitere Informationen zu automatisiertem Machine Learning.
- Weitere Informationen zu Klassifizierungsmetriken und Diagrammen: Artikel Auswerten der Ergebnisse von Experimenten des automatisierten maschinellen Lernens.
- Weitere Informationen finden Sie unter Einrichten von AutoML für NLP.
Probieren Sie auch automatisiertes maschinelles Lernen für diese anderen Modelltypen aus:
- Ein No-Code-Beispiel für die Vorhersage finden Sie im Tutorial: Nachfrageprognose mit automatisiertem maschinellem Lernen ohne Schreiben von Code in Azure Machine Learning Studio.
- Ein erstes Codebeispiel eines Objekterkennungsmodells finden Sie im Tutorial: Trainieren eines Objekterkennungsmodells mit automatisierter ML und Python.