Tutorial: Erstellen von Produktionspipelines für maschinelles Lernen
GILT FÜR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Hinweis
Ein Tutorial, das SDK v1 zum Erstellen einer Pipeline verwendet, finden Sie unter Tutorial: Erstellen einer Azure Machine Learning Pipeline für die Bildklassifizierung.
Der Kern einer Machine Learning-Pipeline besteht darin, eine vollständige Machine Learning-Aufgabe in einen mehrstufigen Workflow zu unterteilen. Jeder Schritt ist eine gut handhabbare Komponente, die individuell entwickelt, optimiert, konfiguriert und automatisiert werden kann. Schritte werden über gut definierte Schnittstellen miteinander verbunden. Der Azure Machine Learning-Pipelinedienst orchestriert automatisch alle Abhängigkeiten zwischen den Schritten der Pipeline. Die Nutzen der Verwendung einer Pipeline sind standardisierte MLOps-Praxis, skalierbare Teamzusammenarbeit, Trainingseffizienz und Kostenreduzierung. Weitere Informationen zu den Nutzen von Pipelines finden Sie unter Was sind Azure Machine Learning-Pipelines.
In diesem Tutorial verwenden Sie Azure Machine Learning, um ein produktionsbereites Projekt für maschinelles Lernen zu erstellen. Dazu verwenden Sie das Azure Machine Learning Python-SDK v2.
Dies bedeutet, dass Sie das Azure Machine Learning Python-SDK für Folgendes nutzen können:
- Abrufen eines Handles für Ihren Azure Machine Learning-Arbeitsbereich
- Erstellen von Azure Machine Learning-Datenressourcen
- Erstellen wiederverwendbarer Azure Machine Learning-Komponenten
- Erstellen, Validieren und Ausführen von Azure Machine Learning-Pipelines
Während diesem Tutorial erstellen Sie eine Azure Machine Learning-Pipeline, um ein Modell für die Kreditausfallvorhersage zu trainieren. Die Pipeline besteht aus zwei Schritten:
- Datenaufbereitung
- Trainieren und Registrieren des trainierten Modells
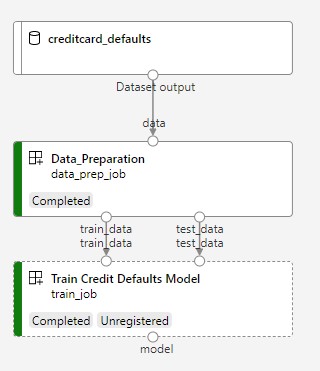
Das nächste Bild zeigt eine einfache Pipeline, wie Sie diese im Azure-Studio nach der Übermittlung sehen werden.
Die beiden ersten Schritte sind die Datenaufbereitung und das Training.
Dieses Video zeigt Ihnen, wie Sie mit Azure Machine Learning Studio loslegen, um den Schritten des Tutorials folgen zu können. Das Video zeigt, wie Sie ein Notebook erstellen, eine Computeinstanz erstellen und das Notebook klonen. Die Schritte sind in den folgenden Abschnitten beschrieben.
Voraussetzungen
-
Um Azure Machine Learning verwenden zu können, benötigen Sie zuerst einen Arbeitsbereich. Wenn Sie noch keinen haben, schließen Sie Erstellen von Ressourcen, die Sie für die ersten Schritte benötigen ab, um einen Arbeitsbereich zu erstellen, und mehr über dessen Verwendung zu erfahren.
-
Melden Sie sich bei Studio an, und wählen Sie Ihren Arbeitsbereich aus, falls dieser noch nicht geöffnet ist.
Schließen Sie das Tutorial Hochladen, Abrufen und Untersuchen Ihrer Daten ab, um das Datenobjekt zu erstellen, das Sie in diesem Tutorial benötigen. Stellen Sie sicher, dass Sie den gesamten Code ausführen, um das anfängliche Datenobjekt zu erstellen. Untersuchen Sie die Daten, und überarbeiten Sie sie, wenn Sie möchten. Sie benötigen jedoch nur die anfänglichen Daten in diesem Tutorial.
-
Öffnen oder erstellen Sie ein neues Notebook in Ihrem Arbeitsbereich:
- Erstellen Sie ein neues Notebook, wenn Sie Code in Zellen kopieren/einfügen möchten.
- Alternativ öffnen Sie die Datei tutorials/get-started-notebooks/quickstart.ipynb im Abschnitt Beispiele des Studios. Wählen Sie dann Klonen aus, um das Notebook zu Ihren Dateien hinzuzufügen. (Erfahren Sie, wo Beispiele zu finden sind.)
Festlegen Ihres Kernels
Erstellen Sie auf der oberen Leiste über Ihrem geöffneten Notizbuch eine Compute-Instanz, falls Sie noch keine besitzen.

Wenn die Compute-Instanz beendet wurde, wählen Sie Compute starten aus, und warten Sie, bis sie ausgeführt wird.

Stellen Sie sicher, dass der Kernel rechts oben
Python 3.10 - SDK v2ist. Falls nicht, wählen Sie diesen Kernel in der Dropdownliste aus.
Wenn Sie ein Banner mit dem Hinweis sehen, dass Sie authentifiziert werden müssen, wählen Sie Authentifizieren aus.



Wichtig
Der Rest dieses Tutorials enthält Zellen des Tutorial-Notebooks. Kopieren Sie in Ihr neues Notebook, und fügen Sie es ein, oder wechseln Sie jetzt zum Notebook, falls Sie es geklont haben.
Einrichten der Pipelineressourcen
Das Azure Machine Learning-Framework kann über die CLI, das Python SDK oder die Studio-Schnittstelle verwendet werden. In diesem Beispiel verwenden Sie das Azure Machine Learning Python-SDK v2 zum Erstellen einer Pipeline.
Vor dem Erstellen der Pipeline benötigen Sie die folgenden Ressourcen:
- Die Datenressource für das Training
- Die Softwareumgebung zum Ausführen der Pipeline
- Eine Computeressource für die Ausführung des Auftrags
Erstellen eines Handles für den Arbeitsbereich
Bevor wir uns genauer mit dem Code befassen, benötigen Sie eine Möglichkeit, um auf Ihren Arbeitsbereich zu verweisen. Sie erstellen „ml_client“ als Handle für den Arbeitsbereich. Anschließend verwenden Sie ml_client zum Verwalten von Ressourcen und Aufträgen.
Geben Sie in der nächsten Zelle Ihre Abonnement-ID, den Namen der Ressourcengruppe und den Namen des Arbeitsbereichs ein. So finden Sie diese Werte:
- Wählen Sie auf der oben rechts angezeigten Azure Machine Learning Studio-Symbolleiste den Namen Ihres Arbeitsbereichs aus.
- Kopieren Sie den Wert für Arbeitsbereich, Ressourcengruppe und Abonnement-ID in den Code.
- Sie müssen einen Wert kopieren, den Bereich schließen und einfügen und den Vorgang dann für den nächsten wiederholen.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Hinweis
Beim Erstellen von MLClient wird keine Verbindung mit dem Arbeitsbereich hergestellt. Die Clientinitialisierung erfolgt verzögert, d. h., es wird abgewartet, bis das erste Mal ein Aufruf erforderlich ist (dies geschieht in der nächsten Codezelle).
Überprüfen Sie die Verbindung durch einen Anruf bei ml_client. Da Sie den Arbeitsbereich zum ersten Mal aufrufen, werden Sie möglicherweise aufgefordert, sich zu authentifizieren.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Zugreifen auf das registrierte Datenobjekt
Beginnen Sie mit den Daten, die Sie zuvor in Tutorial registriert haben: Hochladen, Zugreifen und Erkunden Ihrer Daten in Azure Machine Learning.
- Azure Machine Learning verwendet ein
Data-Objekt, um eine wiederverwendbare Datendefinition zu registrieren und Daten innerhalb einer Pipeline zu nutzen.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Erstellen einer Auftragsumgebung für Pipelineschritte
Bis zu diesem Zeitpunkt haben Sie eine Entwicklungsumgebung auf der Compute-Instance, Ihrem Entwicklungsrechner, erstellt. Sie benötigen außerdem eine Umgebung, die Sie für Schritt in der Pipeline verwenden können. Jeder Schritt kann über eine eigene Umgebung verfügen, oder Sie können einige gemeinsame Umgebungen für mehrere Schritte verwenden.
In diesem Beispiel erstellen Sie eine Conda-Umgebung für Ihre Aufträge, indem Sie eine Conda-YAML-Datei verwenden. Zunächst erstellen Sie ein Verzeichnis, in dem die Datei gespeichert wird.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Jetzt erstellen Sie die Datei im Abhängigkeitsverzeichnis.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Die Spezifikation enthält einige übliche Pakete, die Sie in Ihrer Pipeline verwenden (numpy, pip), zusammen mit einigen Azure Machine Learning-spezifischen Paketen (azureml-mlflow).
Die Azure Machine Learning-Pakete sind für die Ausführung von Azure Machine Learning-Aufträgen nicht zwingend erforderlich. Durch das Hinzufügen dieser Pakete können Sie jedoch mit Azure Machine Learning interagieren, um Metriken zu protokollieren und Modelle zu registrieren, alles innerhalb des Azure Machine Learning-Auftrags. Sie verwenden sie später in diesem Tutorial im Trainingsskript.
Verwenden Sie die YAML-Datei, um diese benutzerdefinierte Umgebung in Ihrem Arbeitsbereich zu erstellen und zu registrieren:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Erstellen der Trainingspipeline
Nun, da Sie über alle für die Ausführung Ihrer Pipeline benötigten Ressourcen verfügen, können Sie die Pipeline selbst erstellen.
Azure Machine Learning-Pipelines sind wiederverwendbare ML-Workflows, die normalerweise aus mehreren Komponenten bestehen. Der typische Lebenszyklus einer Komponente lautet wie folgt:
- Die YAML-Spezifikation der Komponente wird geschrieben oder mit
ComponentMethodprogrammgesteuert erstellt. - Sie können die Komponente optional mit einem Namen und einer Version für Ihren Arbeitsbereich registrieren, damit sie wiederverwendet und gemeinsam genutzt werden kann.
- Die Komponente wird über den Pipelinecode geladen.
- Implementieren Sie die Pipeline unter Verwendung der Eingaben, Ausgaben und Parameter der Komponente.
- Die Pipeline wird übermittelt.
Es gibt zwei Möglichkeiten, eine Komponente zu erstellen: programmgesteuert und YAML-Definition. In den nächsten beiden Abschnitten erfahren Sie, wie Sie eine Komponente auf beide Arten erstellen. Sie können entweder die beiden Komponenten erstellen, indem Sie beide Optionen ausprobieren, oder Ihre bevorzugte Methode auswählen.
Hinweis
In diesem Tutorial verwenden wir der Einfachheit halber die gleiche Compute-Instanz für alle Komponenten. Sie können jedoch unterschiedliche Computes für jede Komponente festlegen, z. B. durch Hinzufügen einer Zeile wie train_step.compute = "cpu-cluster". Ein Beispiel für das Erstellen einer Pipeline mit unterschiedlichen Computes für jede Komponente finden Sie unter Einfache Pipelineaufträge im Tutorial zur Cifar-10-Pipeline.
Erstellen von Komponente 1: Datenaufbereitung (anhand einer programmgesteuerten Definition)
Lassen Sie uns mit der Erstellung der ersten Komponente beginnen. Diese Komponente sorgt für die Vorverarbeitung der Daten. Die Aufgabe zur Vorverarbeitung wird in der Python-Datei data_prep.py ausgeführt.
Erstellen Sie zunächst einen Quellordner für die data_prep-Komponente:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Dieses Skript übernimmt die einfache Aufgabe, die Daten in Trainings- und Testdatasets aufzuteilen. Azure Machine Learning stellt Datasets als Ordner für die Compute-Instanzen bereit. Daher haben wir die Hilfsfunktion select_first_file für den Zugriff auf die Datendatei im bereitgestellten Eingabeordner erstellt.
MLFlow wird verwendet, um während unserer Pipelineausführung die Parameter und Metriken zu protokollieren.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Da Sie nun über ein Skript verfügen, das die gewünschte Aufgabe ausführen kann, erstellen Sie daraus eine Azure Machine Learning-Komponente.
Verwenden Sie die universelle CommandComponent, die Befehlszeilenaktionen ausführen kann. Diese Befehlszeilenaktion kann direkt Systembefehle aufrufen oder ein Skript ausführen. Die Eingaben/Ausgaben werden mittels ${{ ... }}-Notation an der Befehlszeile angegeben.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Optional können Sie die Komponente zur späteren Wiederverwendung im Arbeitsbereich registrieren.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Erstellen von Komponente 2: Training (mithilfe der YAML-Definition)
Die zweite Komponente, die Sie erstellen, erfasst die Trainings- und Testdaten, trainiert ein strukturbasiertes Modell und gibt das Ausgabemodell zurück. Verwenden Sie die Protokollierungsfunktionen von Azure Machine Learning, um den Lernfortschritt aufzuzeichnen und zu visualisieren.
Sie haben Ihre erste Komponente mithilfe der CommandComponent-Klasse erstellt. Diesmal verwenden Sie die YAML-Definition, um die zweite Komponente zu definieren. Jede Methode hat ihre Vorzüge. Eine YAML-Definition kann im Code eingecheckt werden und würde eine lesbare Verlaufsnachverfolgung ermöglichen. Die programmgesteuerte Methode mit Verwendung von CommandComponent kann durch die integrierte Klassendokumentation und die Codevervollständigung einfacher sein.
Erstellen Sie das Verzeichnis für diese Komponente:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Erstellen Sie das Trainingsskript im Verzeichnis:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Wie Sie in diesem Trainingsskript sehen können, wird die Modelldatei gespeichert und im Arbeitsbereich registriert, sobald das Modell trainiert wurde. Jetzt können Sie das registrierte Modell in Rückschlussendpunkten verwenden.
Als Umgebung für diesen Schritt verwenden Sie eine der integrierten (kuratierten) Azure Machine Learning-Umgebungen. Das Tag azureml weist das System an, den Namen in kuratierten Umgebungen zu suchen.
Erstellen Sie zunächst die YAML-Datei, die die Komponente beschreibt:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Erstellen und registrieren Sie jetzt die Komponente. Durch die Registrierung können Sie diese in anderen Pipelines wiederverwenden. Außerdem kann jeder andere Benutzer, der Zugriff auf Ihren Arbeitsbereich hat, die registrierte Komponente verwenden.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Erstellen der Pipeline aus Komponenten
Nun, da Ihre beiden Komponenten definiert und registriert sind, können Sie mit der Implementierung der Pipeline beginnen.
Hier verwenden Sie Eingabedaten, das Aufteilungsverhältnis und den registrierten Modellnamen als Eingabevariablen. Anschließend rufen Sie die Komponenten auf und verbinden sie über ihre Eingabe-/Ausgabebezeichner. Auf die Ausgabe für jeden Schritt kann mithilfe der .outputs-Eigenschaft zugegriffen werden.
Die von load_component() zurückgegebenen Python-Funktionen funktionieren wie jede reguläre Python-Funktion, die wir innerhalb einer Pipeline zum Aufrufen der einzelnen Schritte verwenden.
Um die Pipeline zu codieren, verwenden Sie einen spezifischen @dsl.pipeline-Decorator, der die Azure Machine Learning-Pipelines identifiziert. Im Decorator können wir die Pipelinebeschreibung und Standardressourcen wie Compute- und Speicherinstanzen angeben. Wie eine Python-Funktion können auch Pipelines Eingaben verwenden. Anschließend können Sie mehrere Instanzen einer einzelnen Pipeline mit unterschiedlichen Eingaben erstellen.
Hier haben wir Eingabedaten, Aufteilungsverhältnis und registrierter Modellname als Eingabevariablen verwendet. Anschließend rufen wir die Komponenten auf und verbinden sie über ihre Eingabe-/Ausgabebezeichner. Auf die Ausgabe für jeden Schritt kann mithilfe der .outputs-Eigenschaft zugegriffen werden.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Verwenden Sie nun Ihre Pipelinedefinition, um eine Pipeline mit Ihrem Dataset, dem gewünschten Aufteilungsverhältnis und dem von Ihnen gewählten Namen für Ihr Modell zu instanziieren.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Übermitteln des Auftrags
Jetzt ist es an der Zeit, den Auftrag zur Ausführung in Azure Machine Learning zu übermitteln. Dieses Mal verwenden Sie create_or_update auf ml_client.jobs.
Hier übergeben Sie auch einen Experimentnamen. Ein Experiment ist ein Container für alle Iterationen, die für ein bestimmtes Projekt ausgeführt werden. Alle mit demselben Experimentnamen übermittelten Aufträge werden nebeneinander in Azure Machine Learning Studio aufgelistet.
Nach Abschluss des Vorgangs registriert die Pipeline als Ergebnis des Trainings ein Modell in Ihrem Arbeitsbereich.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Sie können den Fortschritt Ihrer Pipeline verfolgen, indem Sie den in der vorherigen Zelle generierten Link verwenden. Wenn Sie diesen Link zum ersten Mal auswählen, sehen Sie möglicherweise, dass die Pipeline noch ausgeführt wird. Sobald sie abgeschlossen ist, können Sie die Ergebnisse jeder Komponente untersuchen.
Doppelklicken Sie auf die Komponente Trainieren des Kreditausfallmodells.
Es gibt zwei wichtige Ergebnisse, die Sie über das Training sehen wollen:
Zeigen Sie Ihre Protokolle an:
- Wählen Sie die Registerkarte Ausgaben+Protokolle aus.
- Öffnen Sie die Ordner für
user_logs>std_log.txtDieser Abschnitt zeigt die Skriptausführung „stdout“.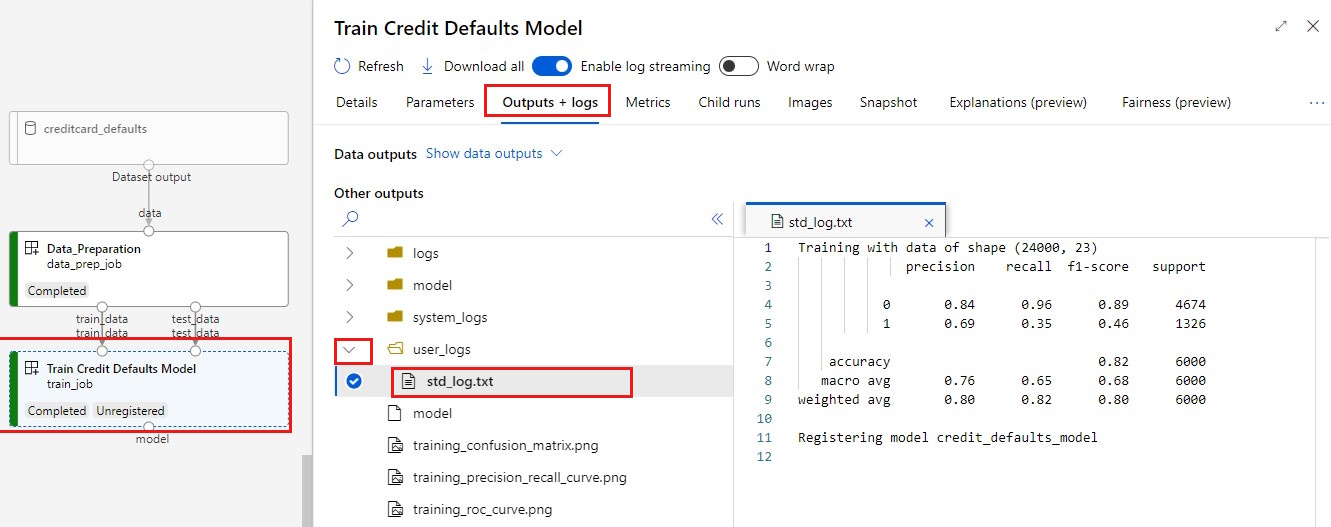
Anzeigen Ihrer Metriken: Wählen Sie die Registerkarte Metriken aus. Dieser Abschnitt zeigt verschiedene protokollierte Metriken an. In diesem Beispiel Über „mlflow
autologging“ wurden automatisch die Trainingsmetriken aufgezeichnet.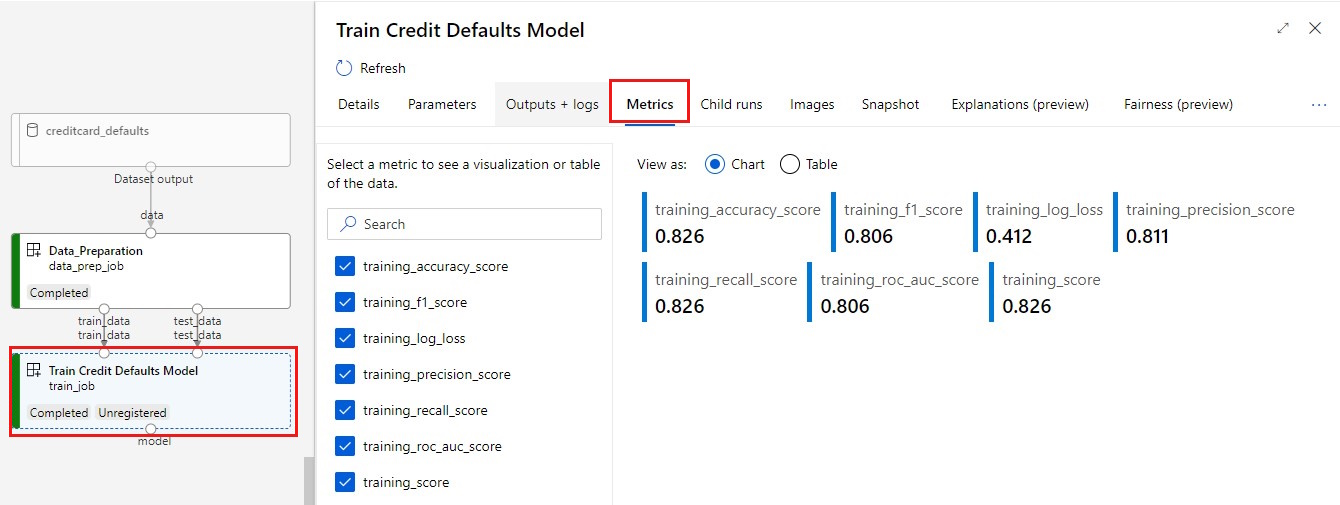


Bereitstellen des Modells als Onlineendpunkt
Informationen zum Bereitstellen Ihres Modells auf einem Onlineendpunkt finden Sie im Tutorial: Bereitstellen eines Modells als Onlineendpunkt.
Bereinigen von Ressourcen
Wenn Sie nun mit dem anderen Tutorials fortfahren möchten, springen Sie zu Nächste Schritte.
Beenden der Compute-Instanz
Wenn Sie die Compute-Instanz jetzt nicht verwenden möchten, beenden Sie sie:
- Wählen Sie im Studio im linken Navigationsbereich Compute aus.
- Wählen Sie auf den oberen Registerkarten Compute-Instanzen aus.
- Wählen Sie in der Liste die Compute-Instanz aus.
- Wählen Sie auf der oberen Symbolleiste Beenden aus.
Löschen aller Ressourcen
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Wählen Sie ganz links im Azure-Portal Ressourcengruppen aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie die Option Ressourcengruppe löschen.
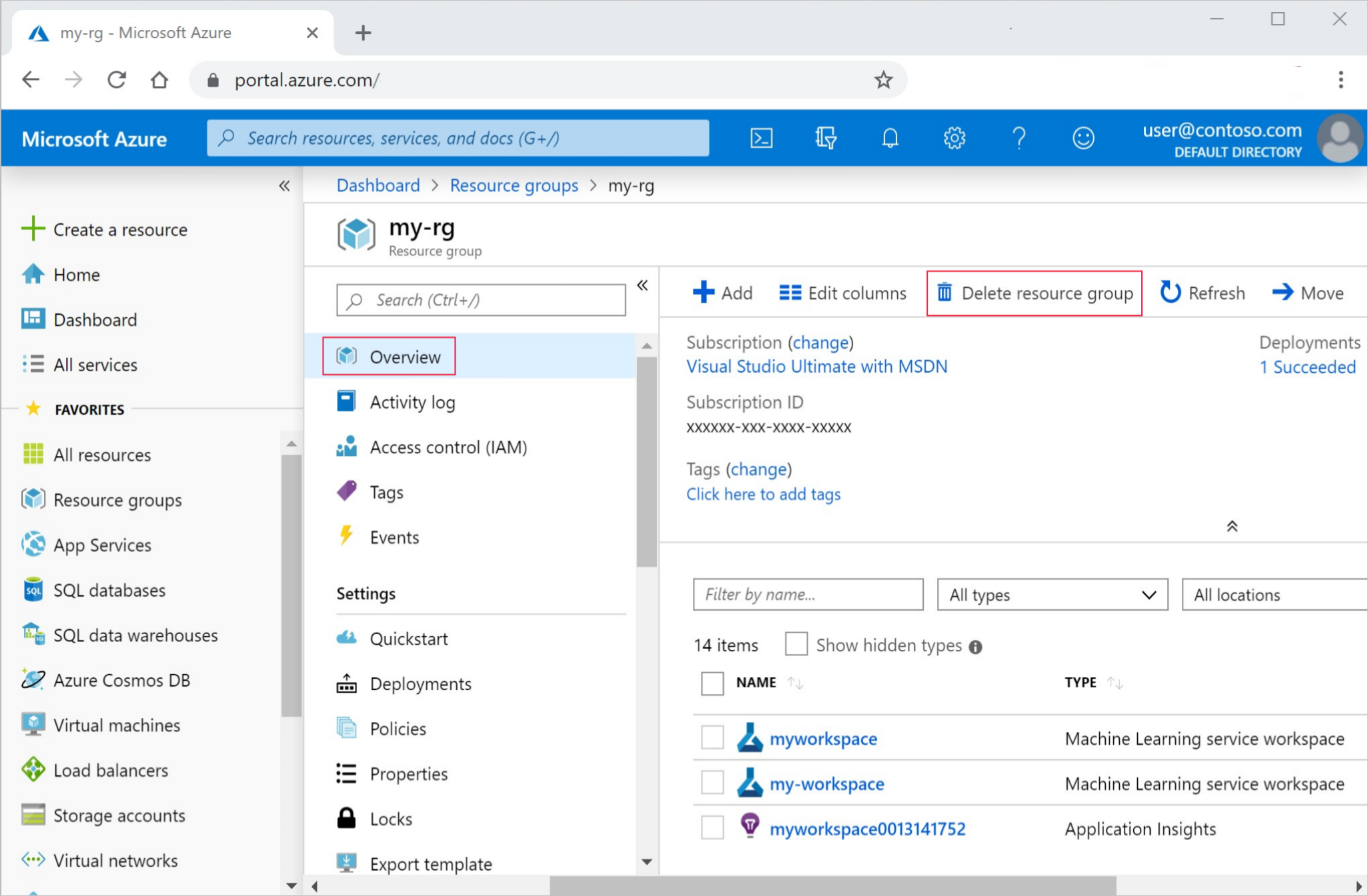
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Nächste Schritte
Erfahren Sie, wie Sie Pipeline-Jobs für maschinelles Lernen planen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für